今日总结:正则表达式解析 (供了解)
1.常用的元字符
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉子 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始(在集合字符里[^a]表示非(不匹配)的意思) |
| $ | 匹配字符串的结束 |
2.反义字符
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
3.限定字符
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
例:^\d{8,11}$ 匹配重复8-11次数字 例如:12345678,123456789,1234567890,12345678901
/^[\u4e00-\u9fa5]{2,4}$/
4.转义字符: \* 为 * \\ 为 \
5.字符分枝 用 ‘ | ’ 将不同条件分割开来,用于满足不同情况的选择。
6.字符分组
字符分组多用于将多个字符重复,主要通过使用小括号()来进行分组
形如:(\d\w){3} 重复匹配3次(\d\w)
常用于表示IP地址 形如: ((25[0-5]|2[0-4][0-9]|[0-1]\d\d)\.){3}(25[0-5]|2[0-4][0-9]|[0-1]\d\d)
解析:先把IP地址分为两部分一部分是123.123.123. 另一部分是123,又因Ip最大值为255,所以先使用分组,然后在组里边再进行选择,组里也有三部分,0-199,200-249,250-255,分别和上述的表达是对应,最后还要注意分组之后还要加上一个.,因为是元字符所以要转义故加上\. 然后再把这部分整体看做是一个组,重复三次,再加上仅有数字的一组也就是不带\.的那一组即可完成IP地址的校验
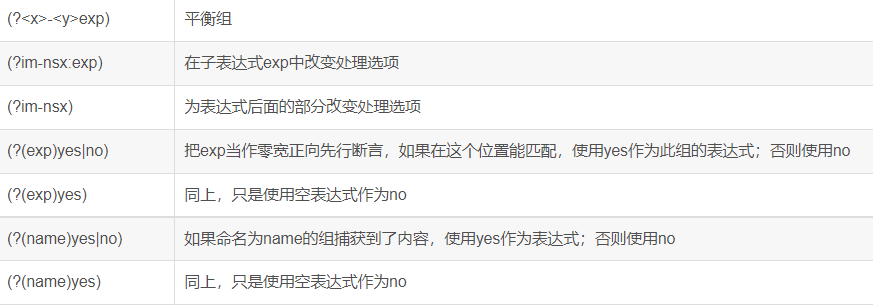
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?<name>exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (?<!exp) | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
7.懒惰匹配和贪婪匹配
贪婪匹配:正则表达式中包含重复的限定符时,通常的行为是匹配尽可能多的字符。
懒惰匹配,有时候需要匹配尽可能少的字符。
例如: a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。但是我们此时可能需要匹配的是ab这样的话就需要用到懒惰匹配了。懒惰匹配会匹配尽可能少的字符
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
8.后向引用
后向引用用于重复搜索前面某个分组匹配的文本。
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推
示例:\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。
这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成'也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b
9.零宽断言
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
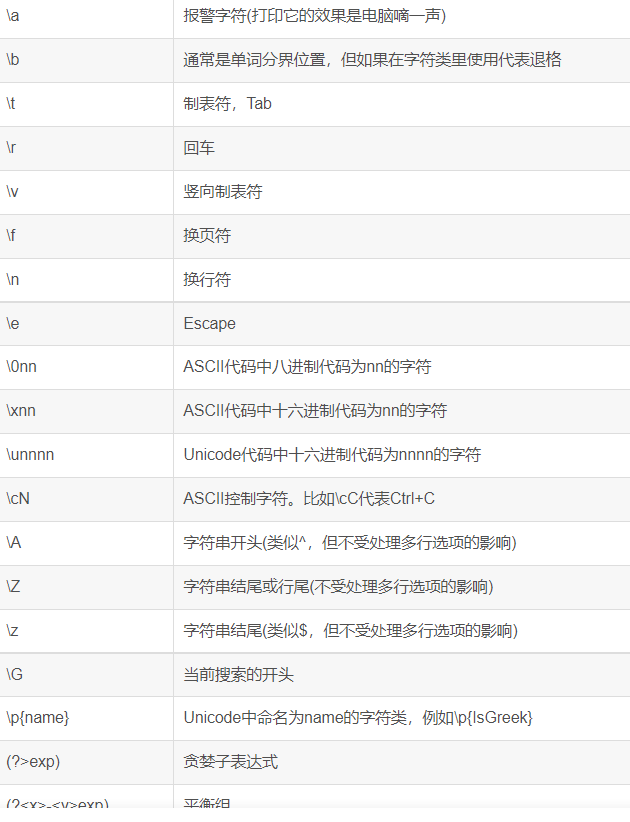
10.其他语法
.NET常用的处理选项
IgnoreCase(忽略大小写) 匹配时不区分大小写。
Multiline(多行模式) 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.)
Singleline(单行模式) 更改.的含义,使它与每一个字符匹配(包括换行符\n)。
IgnorePatternWhitespace(忽略空白) 忽略表达式中的非转义空白并启用由#标记的注释。
ExplicitCapture(显式捕获) 仅捕获已被显式命名的组。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端