激活函数小结
1.首先为什么要有激活函数
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。网络使用非线性激活函数后,可以增加神经网络模型的非线性因素,网络可以更加强大,表示输入输出之间非线性的复杂的任意函数映射。网络的输出层可能会使用线性激活函数,但隐含层一般都是使用非线性激活函数
2.激活函数需要具备的性质
(1) 连续并可导(允许少数点上不可导)的非线性函数. 可导的激活函数,可以直接利用数值优化的方法来学习网络参数.
(2) 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率.
(3) 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性.
3.几种常见的激活函数
3.1 Sigmoid
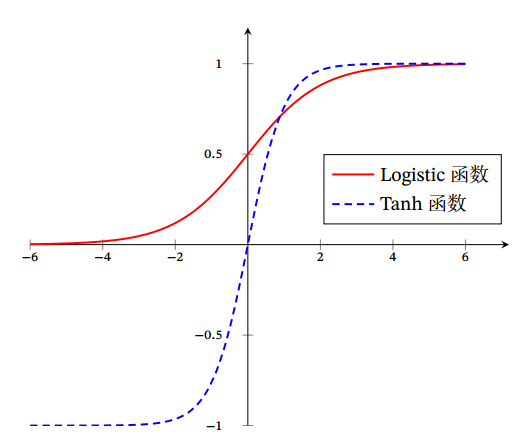
Sigmoid 型函数是指一类 S 型曲线函数, 为两端饱和函数. 常用的 Sigmoid型函数有 Logistic函数和 Tanh函数.即定义域为负无穷到正无穷,值域为0到1.
它可以将负无穷到正无穷的数映射到0,1区间内
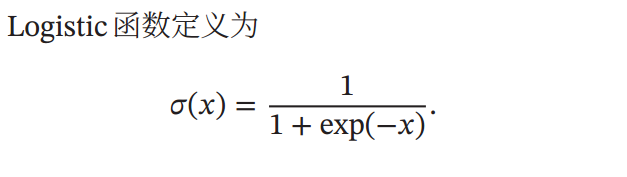
缺点:
-
-
反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练;
-
它也是一种Sigmoid函数,其定义为
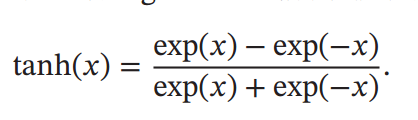
它与上面的区别就是tanh激活函数是零均值的,即
目前深度神经网络中经常使用的激活函数,
-
-
ReLU 的优点是使用ReLU 得到的SGD的收敛速度会比使用sigmoid/tanh的SGD快很多。
-
ReLU 的缺点是神经网络训练的时候很“脆弱”,很容易就会出现神经元死亡。
例如,一个非常大的梯度流过一个ReLU神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元的梯度就永远都会是0。(Dead ReLU Problem)。
-
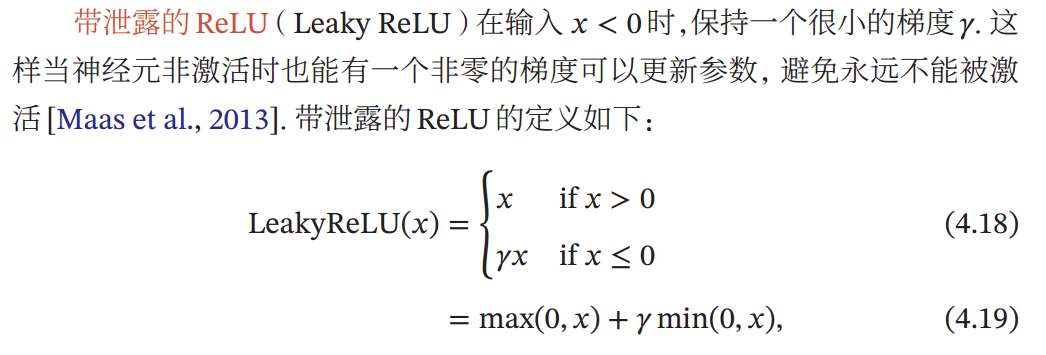

3.3.3总结
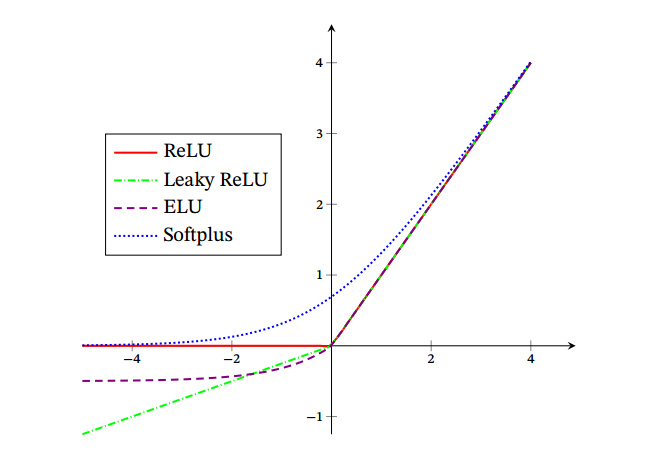
如下图,ReLu是一个单侧抑制的激活函数,而Leaky ReLu是在抑制的一侧,添加了一点梯度避免梯度死亡,ELU则是一个近似零均值化的激活函数,
softplus是ReLu的平滑版本,但也还有单侧抑制。

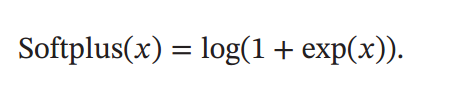

 浙公网安备 33010602011771号
浙公网安备 33010602011771号