【spark】RDD创建
首先我们要建立 sparkconf 配置文件,然后通过配置文件来建立sparkcontext。
import org.apache.spark._
object MyRdd {
def main(args:Array[String]): Unit ={
//初始化配置:设置主机名和程序主类的名字
val conf = new SparkConf().setMaster("local[*]").setAppName("MyRdd");
//通过conf来创建sparkcontext
val sc = new SparkContext(conf);
}
}
然后我们通过 sparkcontext 来创建RDD
创建RDD的几种方式
1.基于程序中的集合创建RDD-作用:主要用于测试
通过 sc.parallelize(collection)方法来创建RDD
/*
* 从scala集合中创建RDD
* 计算:1+2+3+...+100
*/
val nums = List(1,2,3,4,5);//集合
val rdd = sc.parallelize(nums);//创建rdd
val sum = rdd.reduce(_+_);
println(sum);
2.基于本地文件创建RDD-作用:大数据量的测试
"file:///home/hadoop/spark-1.6.0-bin-hadoop2.6/examples/src/main/resources/people.json"3.基于HDFS创建RDD-作用:生产环境最常用的RDD创建方式
"hdfs://112.74.21.122:9000/user/hive/warehouse/hive_test"通过sc.textFile(file)方法来读取文件
/*
* 从本地文件系统创建RDD
* 计算 people.json 文件中字符总长度
*/
val rows = sc.textFile("file://")//文件地址或者HDFS文件路径
val length = rows.map(row=>row.length()).reduce(_+_)
println("total chars length:"+length)
能读取文件,当然能保存文件,我们可以把通过 sc.saveAsTextFile("file://") 把 rdd 内容保存到文件中
例如,我们保存把一个rdd保存到了/home/writeout.txt
val rdd = sc.textFile("file:///home/word.txt");
rdd.saveAsTextFile("file:///home/writeout.txt");//把rdd写入/home/writeout.txt
但是我们打开/home文件夹,发现writeout并不是txt文件而是一个文件夹,我们打开文件夹,结构如下
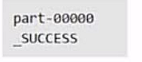
我们保存错了嘛?没有,这时正常的。part-00000代表的是分区,如果有多个分区,会有多个part-xxxxxx的文件。
如果我们要再次读取这个保存的文件并不需要一个一个分区读取,直接读取就可以了,spark会自动加载所有分区数据。
val rdd = sc.textFile("file:///home/writeout/part-00000");//我们并不用这样一个一个读取
val rdd = sc.textFile("file:///home/writeout.txt");//直接这样读取,就会自动把所有分区数据加载到rdd中
4.基于DB、NoSQL(例如HBase)、S3、基于数据流创建RDD

