
面试--问题总结
- Linux的常用命令:
-
文件管理:mkdir ,rm,cp,mv 查看当前路径:pwd
查找文本内容:grep -n "我是xxx" a.txt
重启:shoutdown -r now
关机:shoutdown -h now,init 0
切换用户:su
清屏:ctrl +l
改变文件的权限:chmod 777 a.txt
改变文件拥有者和所在用户组:chown user1 fileName
文件显示命令:more,less,tail,head,grep,cat (grep –n “查找内容” 文件名 | more)
文件搜索:find / -name man:意思是说从根目录开始搜索名称为man的文件或目录。
重定向:ls –l >a.txt 列表的内容写入文件a.txt中(覆盖写), ls –al>> aa.txt 列表的内容追加到文件aa.txt的末尾。
压缩文件:tar -zcvf a.txt
解压文件:tar -zxvf a.tar.gz
-
- 给你一个.class文件如何查看jdk的版本,打开.class文件,查看第一行:
-
2E 46 jdk1.2 2F 47 jdk1.3 30 48 jdk1.4 31 49 jdk1.5 32 50 jdk1.6 33 51 jdk1.7 34 52 jdk1.8
-
- SQL语句种limit的使用:
-
-- 前五条数据 SELECT * FROM `student` limit 5;//省略的写法 -- 前五条数据 SELECT * FROM `student` limit 0,5; -- 从第2条开始取2条数据(第2条到第3条) select * from student limit 1,2;// 1+2=总输出条数 -- 取3到5条的数据 select * from student limit 2,3; //2+3=总输出条数,从第2+1条数据算起,取3个 也就是3,4,5 -- 取10到20条的数据 select * from student limit 10,10;
select * from 表名limit 起始下标,数量(其实小标从0开始)
-
-
spring中#{}和${}的区别:
-
1. 编译过程
- #{} 是 占位符 :动态解析 -> 预编译 -> 执行
- ${} 是 拼接符 :动态解析 -> 编译 -> 执行
2. 是否自动加单引号
- #{} 对应的变量会自动加上单引号
- ${} 对应的变量不会加上单引号
3. 安全性
- #{} 能防止sql 注入
- ${} 不能防止sql 注入
4. Mybatis默认值不同
- #{} 默认值 arg0、arg1、arg2 或 0、 1
- ${} 默认值param1、param2、param3
能用 #{} 的地方就用 #{},尽量少用 ${}
表名作参数,或者order by 排序时用 ${}
传参时参数使用@Param("")注解,@Param注解的作用是给参数命名,参数命名后就能根据名字得到参数值(相当于又加了一层密),正确的将参数传入sql语句中(一般通过#{}的方式,${}会有sql注入的问题)。如下:
Role selectById(@Param("id") String id);
List<Role> selectByNameAndOrgId(@Param("name") String name, @Param("orgId") String orgId);
-
-
泛型
-
-
MySQL索引:
-
存储的数据结构是B+树,
-
主键索引和普通索引的区别是:
-
主键索引只需要查找一棵主键索引树,
-
非主键索引需要先通过非主键索引树找到对用的主键,在通过主键找到对应的一列的值
-

-
-
索引的种类:
-
根据数据库的功能,可以在数据库设计器中创建四种索引:唯一索引、非唯一索引、主键索引和聚集索引。 尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。
-
- 什么是索引,索引的定义
- 索引是帮助MySQL高效获取数据的数据结构
- 可以得出索引的本质是:数据结构
- 你可以简单的理解为:排好序的快速查找数据结构
- 数据本身之外,数据库还维护这一个满足特定算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据的基础上实现高级查找算法,这种数据结构就是索引。
- 我们平常所说的索引,如果没有特殊的指明,都是b树结构组织的索引
- 索引树,索引表:占内存
-
- ++i,会有线程安全问题,因为他不是原子操作
- Java中接口的作用:“接口+实现”最常见的优势就是实现类和接口分离,在更换实现类的时候,不用更换接口功能
- 多态就是接口的最好实践
- 程序,进程和线程:
- 程序只是一组指令的有序集合,它本身没有任何运行的含义,它只是一个静态的实体。
- 进程:指在系统中能独立运行并作为资源分配的基本单位,它是由一组机器指令、数据和堆栈等组成的,是一个能独立运行的活动实体。
- 线程:线程是进程中的一个实体,作为系统调度和分派的基本单位。Linux下的线程看作轻量级进程。
- 重写equals()方法时:

-
equals():
-
引用类型:比较的是两个对象是否时同一个同一个对象(特殊:字符比较的是两个字符的值是否相等)
-
基本数据类型:不能用来比较基本数据类型
-
-
== :
-
基本数据类型:比较两个值是否相等
-
引用类型:比较的是内存地址是否相同
-
-
对于字符串而言:equals是比较的两个字符串是否相等 ,而== 比较的是来个地址是否向等

-
版本snapshots和release的区别:一般来说snapshots版本代表正在开发中的版本,release代表比较稳定的发布版本.
-
springboot开启事务:
-
1 在入口类使用注解@EnableTransactionManagement开启事务:
-
在访问数据库的service方法上添加注解@Transactional即可
-
- 单例模式:
-
public class LayMan {//懒汉式单例模式 private volatile static LayMan layMan; private LayMan() { } public static LayMan getLayMan(){ if (layMan==null){ synchronized (LayMan.class){ if (layMan==null){ layMan=new LayMan(); } } } return layMan; } }
//静态内部类的形式的单例模式
class Singleton{
private Singleton() {}
private static class SingletonInstance {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonInstance.INSTANCE;
}
}
-
-
Cookie和session的区别:
-
浏览器和应用服务交互,一般都是通过 Http 协议交互的。Http 协议是无状态的,浏览器和服务器交互完数据,连接就会关闭,每一次的数据交互都要重新建立连接。
即服务器是无法辨别每次是和哪个浏览器进行数据交互的。 为了确定会话中的身份,就可以通过创建 session 或 cookie 进行标识。session 是在服务器端记录信息;cookie 是在浏览器端记录信息
session 保存的数据大小取决于服务器的程序设计,理论值可以做到不限;单个 cookie 保存的数据大小不超过4Kb,大多数浏览器限制一个站点最多20个cookie
session 可以被服务器的程序处理为 key - value 类型的任何对象;cookie 则是存在浏览器里的一段文本
session 由于存在服务器端,安全性高;浏览器的 cookie 可能被其他程序分析获取,所以安全性较低
大量用户会话服务器端保存大量 session 对服务器资源消耗较大;信息保存在 cookie 中缓解了服务器存储用信息的压力
-
-
Integer包装类的存储位置:
-
class a{ Integer i=10; // i:放在堆中,-128-127 之间指向常量池中的10
Intger i=new Integer(10); i:存放在堆中,执行堆中new出来的10
Integer i=128; i:存放在堆中,没有在静态数组范围内,会在堆中new出来 ,执行堆
public void a(){
Integer i=10; //i:放在栈中,指向常量池中的10
}这儿的IntegerCache是一个静态的Integer数组,在类加载时就将-128 到 127 的Integer对象创建了,并保存在cache数组中,一旦程序调用valueOf 方法,如果i的值是在-128 到 127 之间就直接在cache缓存数组中去取Integer对象。而不在此范围内的数值则要new到堆中了。
}
-
-
B树与B+树,红黑树:
-
B树叶子节点和非叶子节点都存放数据,每一个节点,既存放索引又存放数据本身,通过与每个几点比较,依次向下找到数据本身
-
B+数树,非叶子子节点存放的就是索引,只有叶子节点存放存放数据,且一个叶子节点可以存放多个数据,所有的叶子节点以链表的方式进行连接,(如果只是链表的连接,我们需要从链表的头部进行查找,一次往后直到找到数据,而b+树我们可以通过索引找到数据所有的范围,定位数据,加快检索速度)适用于文件系统;
-
1.MySQL的索引是用什么数据机构的?
B+树的结构
2.为什么要用B+树,而不是B树?
1.B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
B树的由于每个节点都有key和data,所以查询的时候可能不需要O(logn)的复杂度,甚至最好的情况是O(1)就可以找到数据,而B+树由于只有叶子节点保存了data,
所以必须经历O(logn)复杂度才能找到数据2. B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找:由于B+树的叶子节点的数据都是使用链表连接起来的,而且他们在磁盘里是顺序存储的,所以当读到某个值的时候,磁盘预读原理就会提前把这些数据都读进内存,使得范围查询和排序都很快
B+树可以很好的利用局部性原理,若我们访问节点 key为 50,则 key 为 55、60、62 的节点将来也可能被访问,我们可以利用磁盘预读原理提前将这些数据读入内存,减少了磁盘 IO 的次数。
当然B+树也能够很好的完成范围查询。比如查询 key 值在 50-70 之间的节点。
3.B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确:
由于B树的节点都存了key和data,而B+树只有叶子节点存data,非叶子节点都只是索引值,没有实际的数据,这就时B+树在一次IO里面,能读出的索引值更多。
从而减少查询时候需要的IO次数! 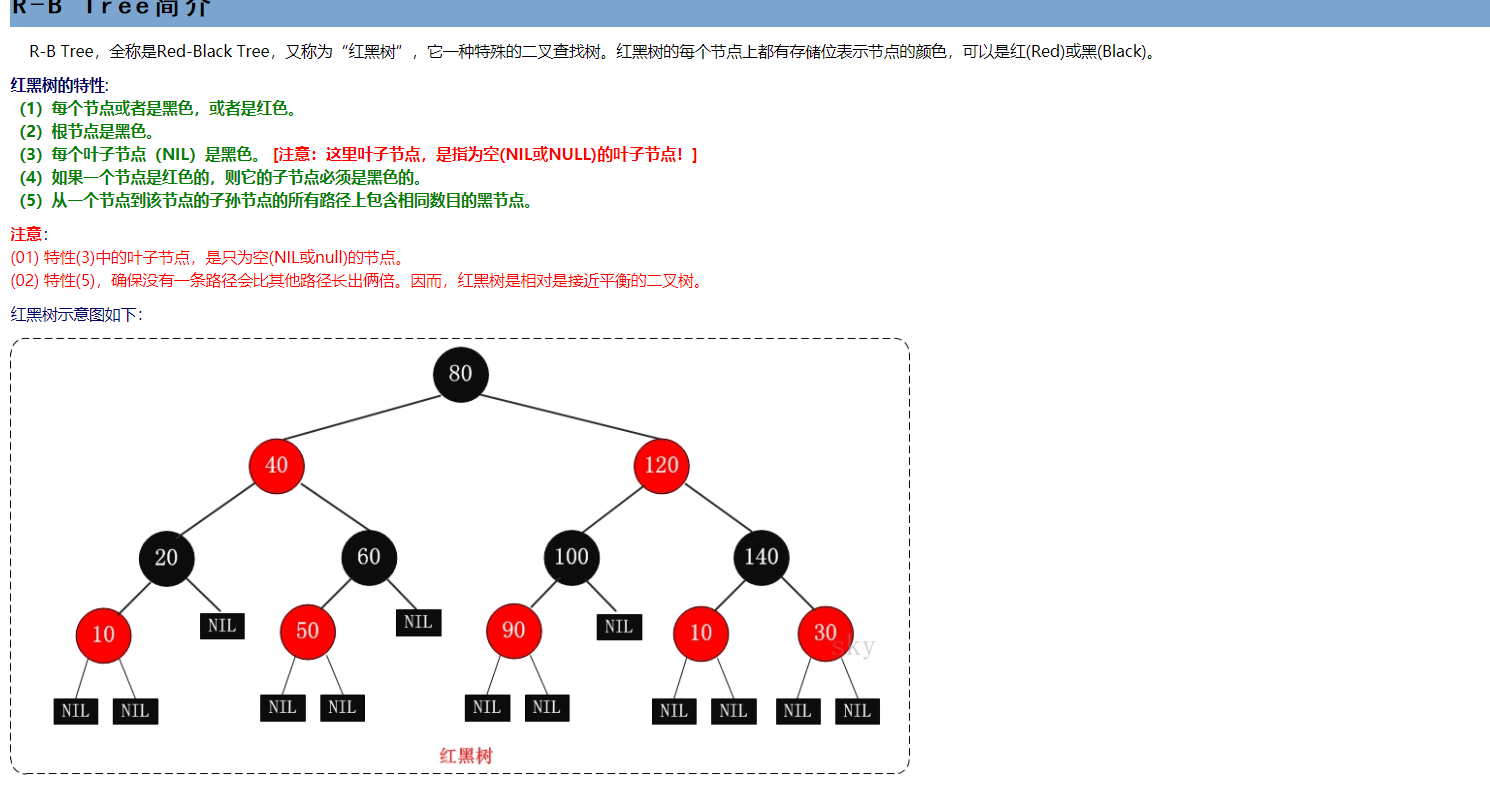
-
-
常用的注解:
-
1.@PropertySource(value = "classpath:propertySource.properties"):引用非主配置文件,对配置类进行注入(使用@Value手动注入) 2.@ConfigurationProperties(prefix = "enable"):应用主配置文件的内容,对配置类进行自动绑定注入 3.@Component :标注的类方入容器中,成为容器中的组件 4.@Configuration:表名这个类是一个配置类(一般使用@Bean将配置类中的方法放入到容器中) 5.@EnableConfigurationProperties(test.class):开启test类(test使用了@configurationProperties注解标注)的属性绑定,这个类能与主配置文件的值匹配,同时把这个组件注册到容器中,可以是第三方的包
6.@Service
7.@Mapper,@MapperScan:mybatis的注解
8.@respository:spring的注解,标注dao层
9.@Controller
10.@responseBody:发送json数据,
11.@RequestBody:接受的是json格式的参数,与JsonObject一起使用
12.@RequestParam 接受参数
13.@PathVariable 接受路径参数 -
/** * 一。配置类中的实现注入的方式 * */ //1.@Configuration + @Bean ConfigurationBean config = run.getBean(ConfigurationBean.class); System.out.println(config); //配置类也是一个bean实例 //配置类中的@Bean方法,注入的类名默认为方法名 System.out.println(run.getBean("doConfiguration")); //2.@Cofiguration +@Import(类名.class):配置的Bean默认名字为全类名:com.model.pojo.User_Import System.out.println(run.getBean("com.model.pojo.User_Import")); //3.@Configuration +@ImportResource(配置文件.xml):注入的类名默认为与类文件名相同 System.out.println(run.getBean("User_ConfigurationImportResource")); //4.配置类:@Configuration +@EnableConfigurationProperties(需要注入的类名.class)+ // 需要注入的类:@ConfigurationProperties(prefix = "ser_EnableConfigurationProperties") //配置类中放:@Configuration +@EnableConfigurationProperties;开启属性绑定,加入到容器中 //需要配置的类中放:@ConfigurationProperties(prefix = "xxx")与配置文件属性绑定 //默认类名为配置文件enable-com.model.pojo.User_EnableConfigurationProperties System.out.println( run.getBean("enable-com.model.pojo.User_EnableConfigurationProperties")); //5.条件注入放在配置类中,用于判断这个配置类是否执行 形式:@Conditionalxxxx
/**
*
* 二。放在类中的注入方式
*
* */
//6.@Component+@Value,默认的注入名:第一个单词首字母小写后面单词首字母大写
System.out.println(run.getBean("user_Component_Value"));
//7*.@Component(将组件加入到容器)+@ConfigurationProperties(prefix = "person")(属性绑定)
// 默认加载主配置文件的配置注入到类中(非第三方的包)
//默认的注入名:第一个单词首字母小写后面单词首字母大写
System.out.println(run.getBean("user_ConfigurationProperties_Component"));
//8.@Component+@PropertySource(value="classpath:xxx.properties"), @Value("${el表达式}")
//默认加载指定的配置文件的配置文件
//默认注入容器的名字为:第一个单词首字母小写后面单词首字母大写
System.out.println(run.getBean("user_PropertySource_Value"));
总共分为两步:一,开启属性绑定+绑定配置文件 二,将组件方入到容器中
-
-
springboot接受json数据:
-
通过
@RequestBody接收json , 通过@Responsebody发送Json -
/** * 创建日期:2018年4月6日<br/> * 代码创建:黄聪<br/> * 功能描述:通过request的方式来获取到json数据<br/> * @param jsonobject 这个是阿里的 fastjson对象 * @return */ @ResponseBody @RequestMapping(value = "/json/data", method = RequestMethod.POST, produces = "application/json;charset=UTF-8") public String getByJSON(@RequestBody JSONObject jsonParam) { // 直接将json信息打印出来 System.out.println(jsonParam.toJSONString()); // 将获取的json数据封装一层,然后在给返回 JSONObject result = new JSONObject(); result.put("msg", "ok"); result.put("method", "json"); result.put("data", jsonParam); return result.toJSONString(); }
-
通过Request获取 ,通过request的对象来获取到输入流,然后将输入流的数据写入到字符串里面,最后转化为JSON对象。
-
@ResponseBody @RequestMapping(value = "/request/data", method = RequestMethod.POST, produces = "application/json;charset=UTF-8") public String getByRequest(HttpServletRequest request) { //获取到JSONObject JSONObject jsonParam = this.getJSONParam(request); // 将获取的json数据封装一层,然后在给返回 JSONObject result = new JSONObject(); result.put("msg", "ok"); result.put("method", "request"); result.put("data", jsonParam); return result.toJSONString(); } /** * 创建日期:2018年4月6日<br/> * 代码创建:黄聪<br/> * 功能描述:通过request来获取到json数据<br/> * @param request * @return */ public JSONObject getJSONParam(HttpServletRequest request){ JSONObject jsonParam = null; try { // 获取输入流 BufferedReader streamReader = new BufferedReader(new InputStreamReader(request.getInputStream(), "UTF-8")); // 写入数据到Stringbuilder StringBuilder sb = new StringBuilder(); String line = null; while ((line = streamReader.readLine()) != null) { sb.append(line); } jsonParam = JSONObject.parseObject(sb.toString()); // 直接将json信息打印出来 System.out.println(jsonParam.toJSONString()); } catch (Exception e) { e.printStackTrace(); } return jsonParam; }
-
-
@mapper和@Repository:
-
@Repository、@Service、@Controller,它们分别对应存储层Bean,业务层Bean,和展示层Bean。 如果使用@Repository则需要使用@MapperScan("xxx.xxx.xxx.mapper")进行扫描,然后生成Dao层的Bean才能被注入到Service层中。 @Mapper通过xml里面的namespace里面的接口地址,生成了Bean后注入到Service层中。相当于@Mapper=@Repository+@MapperScane 使用注解的方式开发Dao层的时候,常常会混淆这两个注解,不知道怎么添加,这里做个记录。 @Mapper: @Mapper 是 Mybatis 的注解,和 Spring 没有关系,@Repository 是 Spring 的注解,用于声明一个 Bean。(重要) 使用 Mybatis 有 XML 文件或者注解的两种使用方式,如果是使用 XML 文件的方式,我们需要在配置文件中指定 XML 的位置,这里只研究注解开发的方式。 在 Spring 程序中,Mybatis 需要找到对应的 mapper,在编译的时候动态生成代理类,实现数据库查询功能,所以我们需要在接口上添加 @Mapper 注解。
- @Mapper 一定要有,否则 Mybatis 找不到 mapper。
- @Repository 可有可无,可以消去依赖注入的报错信息。
- @MapperScan 可以替代 @Mapper。但是依然解决不了,IDE注入红线的问题。
- 最终得出答案:@Mapper和@Repository 同时使用,完美解决所有问题。
-
-
git命令:
-
初始化:git init
设置签名:git config -global user.name 张紫韩
git config - global user.email 171832195@qq.com
查看状态:git status
查看所有的版本号: git reflog
回退版本: git reset -hard HEAD 回退版本号
添加到暂存区:git add .
比较文件:git diff [版本号] a.txt
提交本本地仓库:git commit -m "解释" .
查看所有的分支:git branch -v
新建分支:git branch 新的分支名
切换分支:git checkout 分支名
合并分支: git merge 分支名
为远程仓库建立别名:git remote add origin 远程库访问地址
git remote -v
将本地库的内容推送到远程库中:git push master
拉去项目到本地库:git pull master
git feth origin master + git merge origin master
-
-
我们能不能自己写一个java.lang.String类,为什么:
-
可以写,但是由于相亲委派机制,我们写的这个类永远不会加载到内存中使用
-
-
四种访问修饰符:
-
public :任何地方都能访问
-
protected:在本类中,同一个包中,子类中可以进行访问,在不同的包下无法进行访问
-
默认类型:在本类中和同一个包中可以进行访问,在子类中和不同的包下无法进行访问
-
private:只有在本类中可以进行访问
-
-
static关键字:
-
static可以修饰类:静态内部类 修饰变量:静态变量/类变量 修饰方法:静态方法/类方法 静态代码块:
静态导包用法:
注解:非静态方法和可调用静态的方法和变量,静态方法不可调用非静态的方法和变量
-
-
final关键字:
-
final修饰的类(无法被继承)
final修饰的方法(无法被覆盖,重写)
final修饰的局部变量(只能赋一次值)
-
-
wati()和sleep()的区别
-
1.属于不同的类:wait()属于Object类,sleep()属于Thread类 2.是否释放锁:sleep()执行时不释放锁,wait()执行会释放锁 3.释放范围:sleep()可以使用在任何地方,wait()只能使用在同步块中 4.都会抛出异常()
-
-
MySQL常用函数:
-
数字函数:
返回x绝对值:abs(x)
返回x的y次方:pow(x,y)
返回x取余y的余数:mod(x,y)
向上取整:ceil()
向下取整:floor()
字符串函数:
字符串拼接:concat(str1,str2)
字符串反转:reverse(str)
截取字符串:substring(str,n,len)
插入字符串:insert(str,x,len,str2)
日期函数:
返回当前日期:now(),localtime(),system()
返回某个如期的年份:year(data)
返回某个如期的月:month(data)
返回某个日期的星期:week(data)
格式化日期:curdate()
条件判断函数:
expr为true,则返回x1,否则返回x2:if(expr,x1,x2)
如果v1部位null则返回v1,否则返回v2:ifnull(v1,v2)
系统函数:
返回版本信息:version()
查看连接的用户数:connection_id
查看str的字符集:charsert(str)
加密函数:
返回加密后的字符串密码:password(str)
返回一个二进制字符串形式:MD5(str)
max() min() avg()
-
-
MySQL什么时候建索引:
-
-
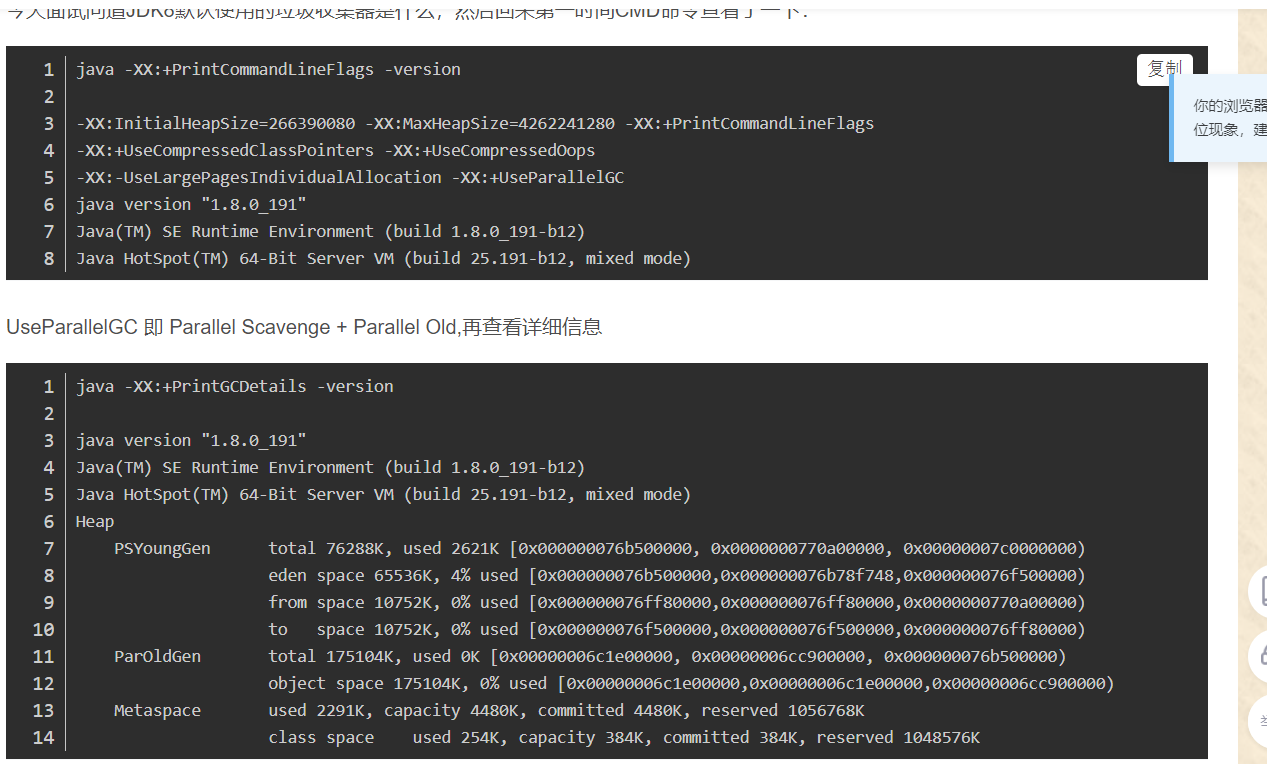
默认的垃圾回收机制:
-
jdk1.7 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
-
jdk1.8 默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
-
jdk1.9 默认垃圾收集器G1
-
-XX:+PrintCommandLineFlagsjvm参数可查看默认设置收集器类型
-
-XX:+PrintGCDetails亦可通过打印的GC日志的新生代、老年代名称判断
-
-
-
String str=""和String str=new String();
-
String str="abc" :会产生一个对象,也可能不产生对象
在编译时,他会检查常量池是否有“abc”,如果有直接指向常量池中的“abc”,如果没有则在堆中创建一个“abc”,并使栈中的str执行常量池中的“abc”
String str=new String("abc"):
可能产生了2个对象,一个是new关键字创建的new Sring();另一个是“abc”对象,abc在一个字符串池中,s这个对象指向这个字符串池。
可能产生2个对象,就是new出来的存放在堆中
在编译过程,他会检查常量中是否又“abc”,如果有“abc”他会直接用,如果没有,则会在常量池中创建一个“abc”,再在堆中创建一个String对象,堆中的对象指向常量池中的“abc”,而栈中的引用指向堆中的字符串对象
-
-
创建线程的几种方式:
-
1.继承Thread类,重写run方法:2.实现Runnable接口,重写run方法 3.实现Callable接口, 4.线程池
-
package com.model.thread; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; /** * @Description:测试类 * @Author: 张紫韩 * @Crete 2021/8/9 16:10 * 线程实现的几种方式 */ public class ThreadDemo08 { public static void main(String[] args) { // 第一种线程实现方式 ThreadOne thread = new ThreadOne(); thread.start(); // 第二种线程实现方式 new Thread(new ThreadTwo()).start(); // 第三种线程实现方式 FutureTask<Integer> integerFutureTask = new FutureTask<Integer>(new ThreadThree()); new Thread(integerFutureTask).start(); } } class ThreadOne extends Thread{ @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println("第一种实现方式"+i); } } } class ThreadTwo implements Runnable{ @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println("第二种实现方式"+i); } } } class ThreadThree implements Callable{ @Override public Object call() throws Exception { return 67; } }
-
-
内存溢出和内存泄漏:
-
内存泄露是指:内存泄漏也称作"存储渗漏",用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元。直到程序结束。(其实说白了就是该内存空间使用完毕之后未回收)即所谓内存泄漏。
内存溢出:内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出。
-
-
泛型的应用:
-
反射种用到了泛型 集合中用到了泛型 泛型数组相互矛盾 主要有:泛型接口,泛型方法,泛型类
泛型接口:List<>
泛型类:ArrayList<>
泛型方法:泛型类在声明对象的时候,就已经定义好了能操作的数据类型,因此,在调用该类的方法时,不可避免的限定了方法的参数类型。这时,定义泛型方法就比较方便。泛型类中也可以定义泛型方法。
静态方法不可以访问类上定义的泛型,如果静态方法操作的数据类型不确定,可以将该方法定义为泛型方法。
泛型就是我们在使用某个类或者接口时(List<Sttring>,ArrayList<String>)定义是就为其指定泛型,我们在使用时就执行执行这种类型的参数了,如果我们操作其他类型的参数,他就会在编译器帮助我们指出错误
在遍历的时候,取出来的就是我们执行的类型的参数,而不是object类型了,消除了强制类型转换,提高了执行速度,避免了强制类型转换带来的类型转换异常
静态方法不能使用泛型,因为类加载实在我们创建的前面执行
-
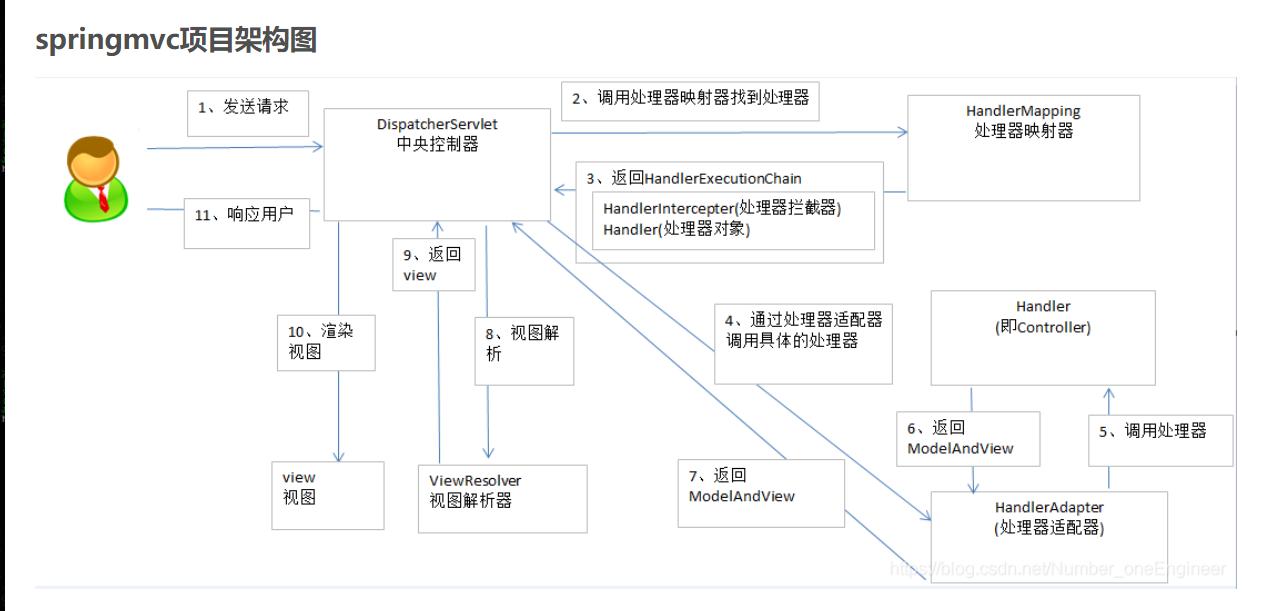
- 简单介绍一下springmvc:
-
1.发起请求到前端控制器(DispatcherServlet) 2.前端控制器请求HandlerMapping查找 Handler,可以根据xml配置、注解进行查找 3.处理器映射器HandlerMapping向前端控制器返回Handler 4.前端控制器调用处理器适配器去执行Handler 5.处理器适配器去执行Handler 6.Handler执行完成给适配器返回ModelAndView 7.处理器适配器向前端控制器返回ModelAndView,ModelAndView是springmvc框架的一个底层对象,包括 Model和view 8.前端控制器请求视图解析器去进行视图解析,根据逻辑视图名解析成真正的视图(jsp) 9.视图解析器向前端控制器返回View 10.前端控制器进行视图渲染,视图渲染将模型数据(在ModelAndView对象中)填充到request域 11.前端控制器向用户响应结果
-
什么是Mybatis:
-
官网的介绍言简意赅,从三个出发点介绍了什么是Mybatis,首先Mybatis是一个优秀的持久化框架,它支持自定义SQL查询、存储过程,和很好的一个映射。
第二点Mybatis减少了大部分JDBC的代码,避免了手动设置参数和结果集的映射。
第三点Mybatis用简单的XML配置文件或注解来配置映射关系,将接口和POJO对象映射到数据库记录中。 在使用传统JDBC时,我们往往需要写很多JDBC代码,需要自己写SQL语句以及自己装配参数,然后自己对结果集进行封装处理,而Mybatis帮我们简化了以上功能
,只需要一些配置文件(xml)或是注解的方式即可完成对数据库的查询以及结果的映射封装。
-
-
统计一个句子中单词的个数:
-
package com.model.other; import org.omg.PortableInterceptor.INACTIVE; import java.util.*; /** * @Description:测试类 * @Author: 张紫韩 * @Crete 2021/8/12 11:09 * 人人网笔试题 */ public class Test03 { public static void main(String[] args) { String str = "End of file,end.End of"; wordCount(str); } // 统计单词个数 public static void wordCount(String str) { HashMap<String, Integer> map = new HashMap<>(); String[] array = {".", " ", ","}; for (int i = 0; i < array.length; i++) { str = str.replace(array[i], ","); } String[] textArray = str.split(","); for (String s : textArray) { s = s.toLowerCase(); if (map.containsKey(s)) { Integer integer = map.get(s); map.replace(s, integer + 1); } else { map.put(s, 1); } } // 输出 int index = 0; for (String key : map.keySet()) { if (index == 0) { System.out.println("{"); } System.out.print(key + ":" + map.get(key)); index++; if (index<map.size()){ System.out.print(",\n"); } if (index == map.size()) { System.out.println("\n}"); } } // 加分项 TreeMap<Integer, String> treeMap = new TreeMap<>(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2-o1; } }); for (Map.Entry<String,Integer> entry:map.entrySet()){ treeMap.put(entry.getValue(), entry.getKey()); } for (String value: treeMap.values()){ System.out.print(value+"\t"); } } }
-
-
JDK1.8的新特性:
-
1.Lambda表达式
2.函数式接口:简单来说就是只定义了一个抽象方法的接口(Object类的public方法除外),就是函数式接口,并且还提供了注解:@FunctionalInterfac3.方法引用和构造器调用
4.Stream API
5.接口中的默认方法和静态方法
6.新时间日期API (LocalData)
-
-
Java的编码方式:
-
GBK ISO-8859-1 utf-8
-
-
接口和抽象类的区别:
-
1.Java抽象类可以提供某些方法的部分实现,而Java接口不可以(就是interface中只能定义方法,而不能有方法的实现,而在abstract class中则可以既有方法的具体实现,
又有没有具体实现的抽象方法)
2.子类执行单继承抽象类,但可以实现多个接口
3.接口中基本数据类型为static 而抽类象不是的。
4.接口是抽象类的变体,接口中所有的方法都是抽象的。而抽象类是声明方法的存在而不去实现它的类。
-
-
hasaMap解决冲突的方法:
-
如果存储的对象对多了,就有可能不同的对象所算出来的hash值是相同的,这就出现了所谓的hash冲突。学过数据结构的同学都知道,解决hash冲突的方法有很多,HashMap底层是通过链表来解决hash冲突的。
扩容机制和链表机制解决hash冲突
-
-
Linux命令
-
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,默认以空格为分隔符将每行切片,切开的部分再进行各种分析处理。
awk是行处理器,相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息 awk处理过程: 依次对每一行进行处理,然后输出
以空格位分割,输出分割后的第二行:awk -F " " '{print $2}' a.txt以:分割,打印整行:awk -F ":" '{print $0}' a.txt参数:
- -F 指定分隔符
- -f 调用脚本
- -v 定义变量
- $0 表示整个当前行
- $1 每行第一个字段
- awk '{print}' /etc/passwd == awk '{print $0}' /etc/passwd
查看文件显示行号:
vim中显示行号:set nu
显示所有行:cat -n a.txt
less a.txt
more a.txt
head -n a.txt
tail -n a.txt
-
-
学习过程中遇到的技术难题
-
再做微服务调用的过程工多个服务之间进行调用,(多个服务,多个数据库)同一个事务之中需要对不同的数据库进行多次操作,如果一个服务失败了,会造成前面执行的事务无法进行回滚,
-
违反了事务的原子性, (常见的创建订单:订单微服务创建订单,库存微服务:减少库存,用户微服务:扣除账户 ;)我们对订单进行了创建,库存进行了减少,如果着时扣除用户账户时,调用失败,会造成账单和库存事务无法进行回滚,我是使用了 springbootAlibaba的seata 对全局事务进行控制:分布式事务处理,多个服务操作,要么都成功,失败之后可以统一进行回滚
-

-




