
MySQL高级--索引详解
- 什么是索引,索引的定义
- 索引是帮助MySQL高效获取数据的数据结构
- 可以得出索引的本质是:数据结构
- 你可以简单的理解为:排好序的快速查找数据结构
- 数据本身之外,数据库还维护这一个满足特定算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据的基础上实现高级查找算法,这种数据结构就是索引。
- 我们平常所说的索引,如果没有特殊的指明,都是b树结构组织的索引
- 索引树,索引表:占内存
- 索引的优势
- 类似于图书管建立书目索引,提高数据检索效率,降低数据库的IO成本。(由于某种查找算法)
- 通过索引列对数据进行排序,降低数据的排序成本,降低cpu的消耗。
- 索引的不足
- 实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占内存空间的
- 虽然索引大大提高了查询的速度,同时会降低更新表的速度,如对表进行更新时,不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值对变化后的索引信息
- 索引只是提高效率的一种因素,如果你的mysql有大数据量的表,我们需要花时间去研究建立最优秀的索引。
- 索引的分类
- 单值索引
- 即一个索引只包含单个列,一个表可以有多个单值索引
- 唯一索引
- 索引列的值必须唯一,可以为空值
- 复合索引
- 即一个索引包含多个列
- 基本语法
- 创建索引的规范
-
普通索引名:IDX_<table>_<column>
-
唯一索引名:UN_<table>_<column>
-
其中<table>是建立索引的表名,<column>是建立索引的字段名
-
- 创建索引:
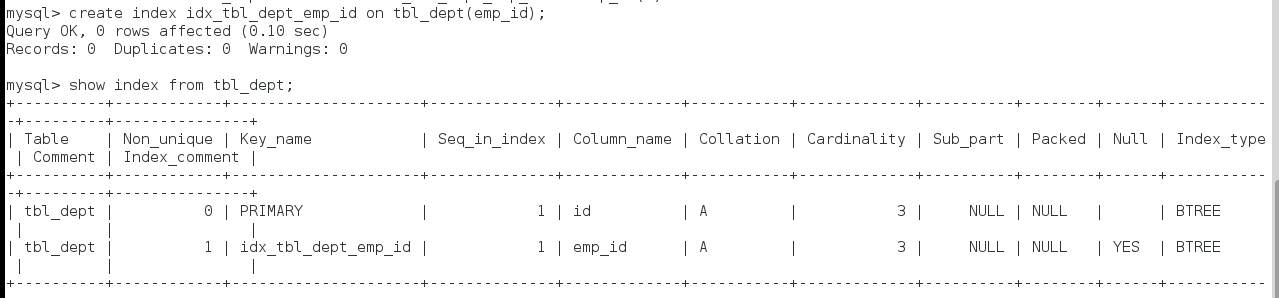
- CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
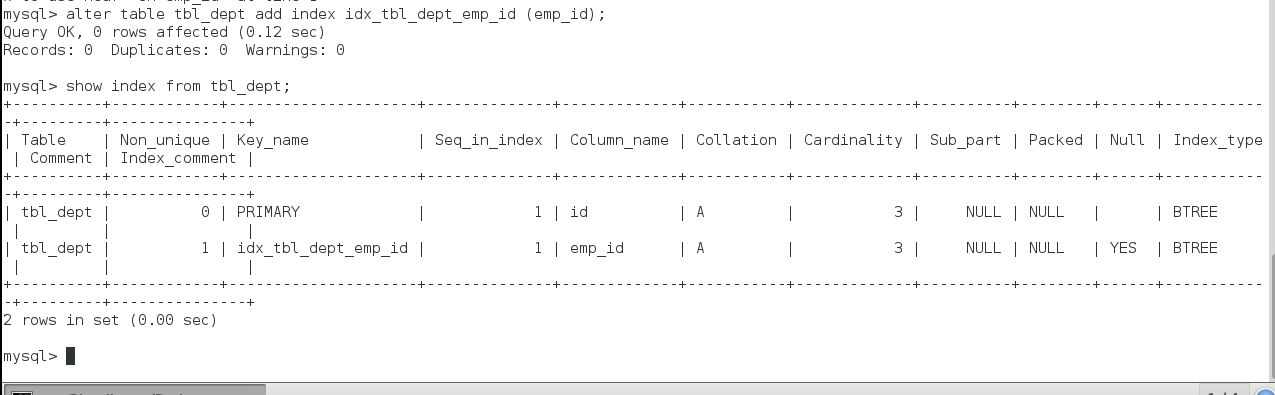
- alter mytable add [UNIQUE] INDEX [INDEXNAME] ON (clumnname(length));
- 删除索引:
- DROP INDEX [indexName] ON mytable;

- 查看索引
- SHOW INDEX FROM table_name

- 创建索引的规范
- 总计四种更改表的索引
-
ALTER TABLE tbl_ _name ADD PRIMARY KEY (column_ list): 该语句添加一-个主键,这意味着索引值必须是唯- -的, 且不能为NULL。
-
ALTER TABLE tbl_ name ADD UNIQUE index_ _name (column_ list): 这条语句创建索引的值必须是唯一-的 (除了NULL外,NULL可能会出现多次)。
-
ALTER TABLE tbl _name ADD INDEX index_ name (column lit): 添加普通索引,索引值可出现多次。
-
ALTER TABLE tb_ name ADD FULLTEXT index_ name (column list):该语句指定了索引为FULLTEXT,用于全文索引。
-
- 单值索引
- mysql索引的结构
- BTree索引
- Hash索引
- full-text全文索引
- R-Tree索引
- 适合建索引的情况
- 1.主键自动建立唯一 索引
-
2.频繁作为查询条件的字段应该创建索引
-
3.查询中与其它表关联的字段,外键关系建立索引
-
4.频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索引,加重了I0负担
-
5.Where条件里用不到的字段不创建索引
-
6.单键/组合索引的选择问题,who? (在高并发下倾向创建组合索引)
-
7.查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
-
8.查询中统计或者分组字段
- 那些情况不适合建索引
- 1.表记录太少
- 2.经常增删改的表:
- 提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件
- 3.数据重复且分布平均的表字段
- 因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。

