


Hadoop2.8集群搭建
前言
集群的搭建需要准备三台虚拟机
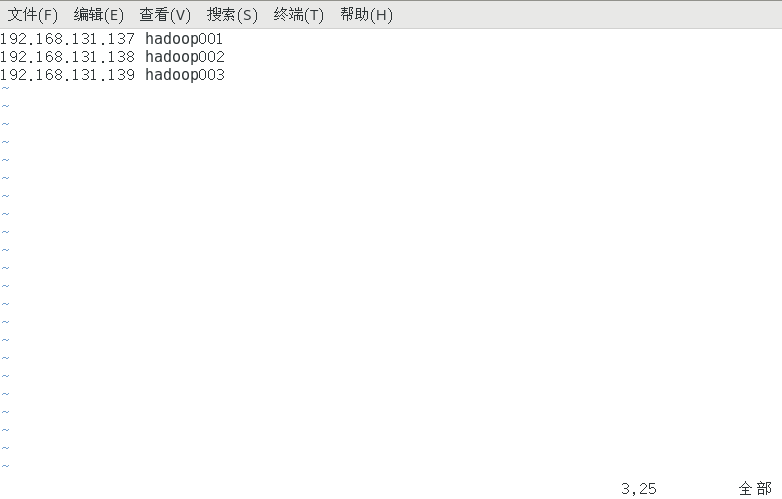
| 主机名称 | IP地址 |
|---|---|
| hadoop001 | 192.168.131.137 |
| hadoop002 | 192.168.131.138 |
| hadoop003 | 192.168.131.139 |
- Hadoop-2.8.5:链接:https://pan.baidu.com/s/128xtR4sfsiup8oJHerP75A 提取码:384h
- jdk-7u75-linux-x64.tar:链接:https://pan.baidu.com/s/1BDMM8c-6fJsU1vHlxc7OEw 提取码:f12p
一、配置主机名与网络
以下操作 三台虚拟机 都需要进行操作
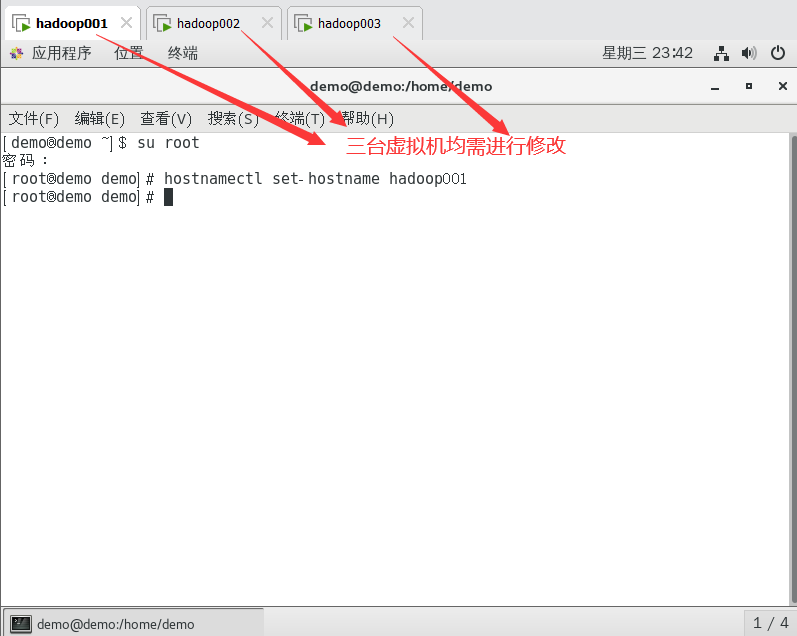
切换到root权限
复制su root
修改主机名称
复制hostnamectl set-hostname hadoop001
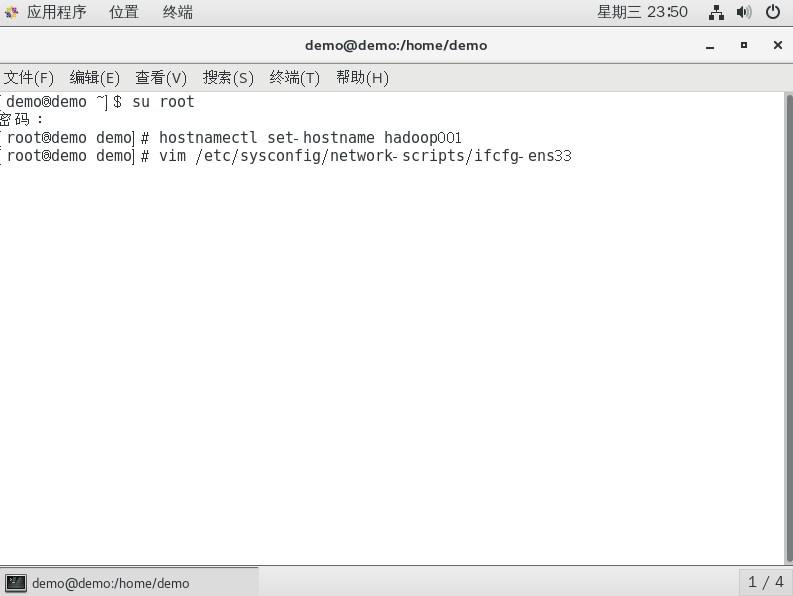
修改IP地址
复制vim /etc/sysconfig/network-scripts/ifcfg-ens33
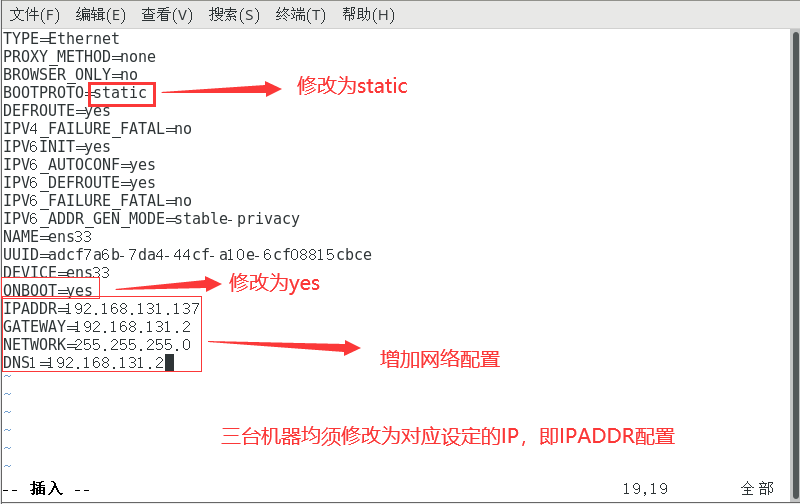
做出如下修改
复制TYPE=Ethernet PROXY_METHOD=static BROWSER_ONLY=no BOOTPROTO=dhcp DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=ens33 UUID=fa65cffc-4ad5-496b-a3bd-0c1bd3bbd600 DEVICE=ens33 ONBOOT=yes IPADDR=192.168.131.137 GATEWAY=192.168.131.2 NETWORK=255.255.255.0 DNS1=192.168.131.2
注意 IPADDR 的修改(三台虚拟机对应各自IP)
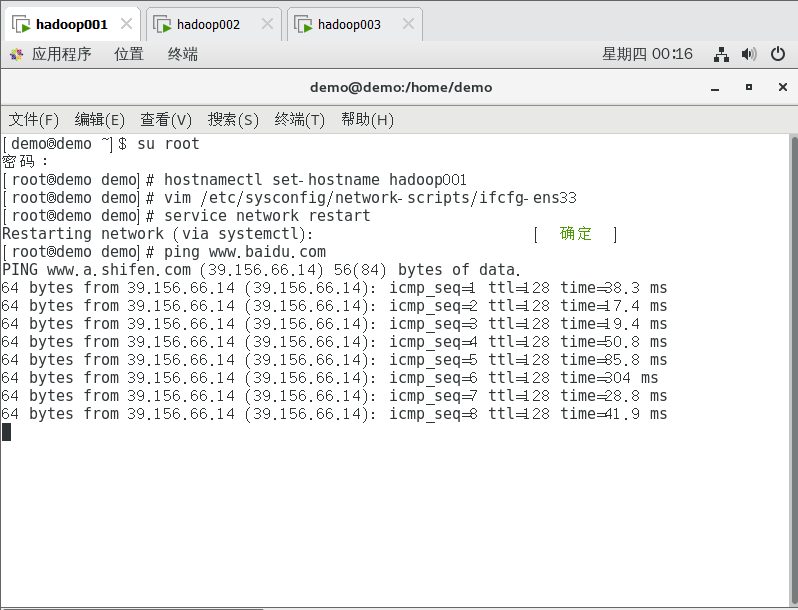
重启网卡,测试网络
复制service network restart
重启电脑
复制reboot
添加映射
复制vim /etc/hosts

在另外 两台虚拟机 重复执行上述操作
二、配置免密登录
以下操作 三台虚拟机 都需要进行操作
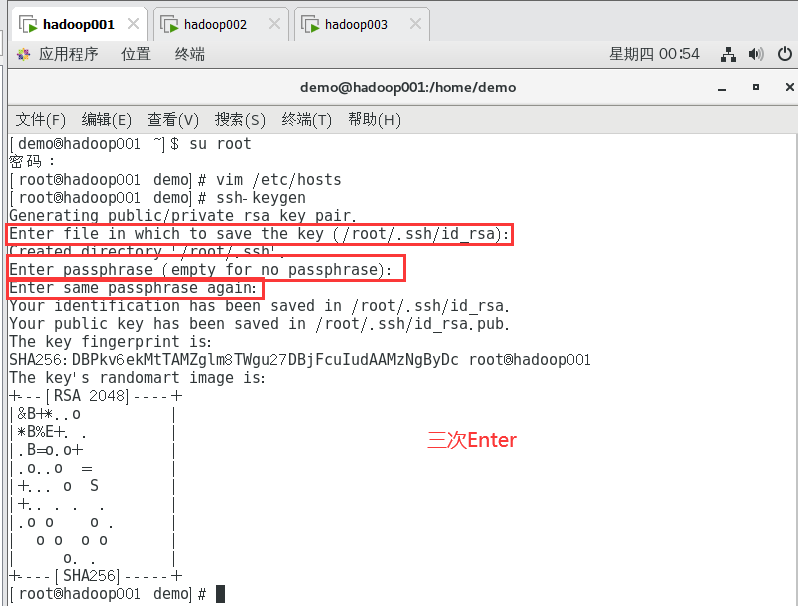
复制ssh-keygen
输入ssh-keygen后,按照命令提示敲击“Enter”,直至命令结束
拷贝公钥
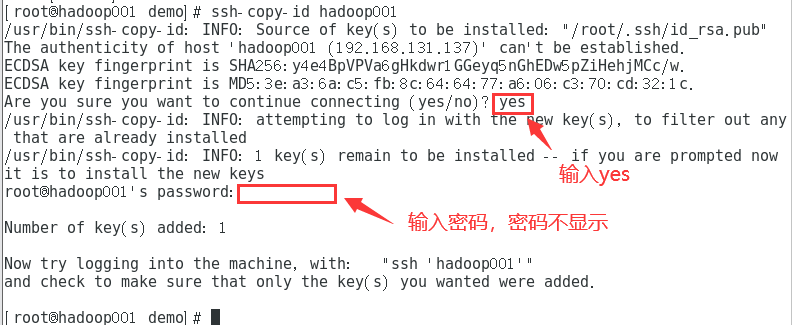
复制ssh-copy-id hadoop001
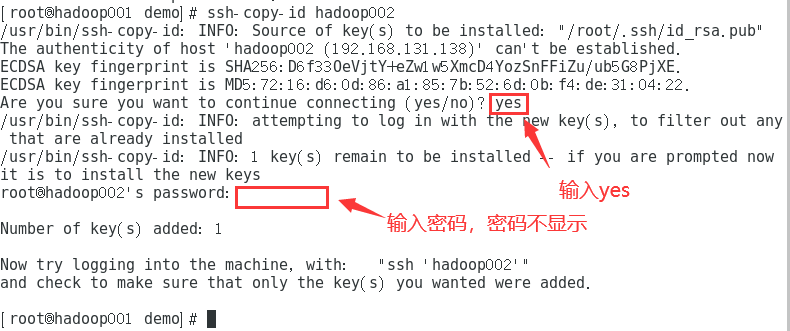
复制ssh-copy-id hadoop002
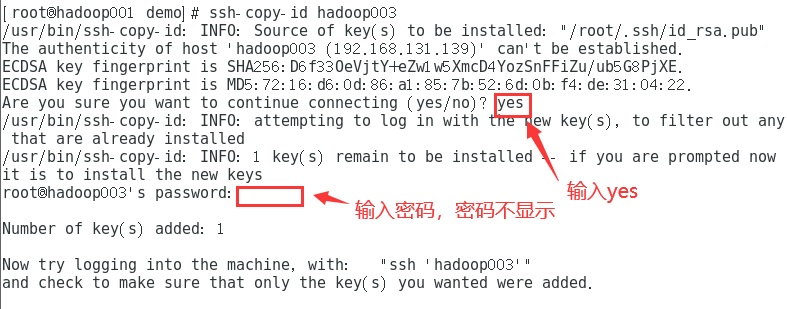
复制ssh-copy-id hadoop003
测试免密登录
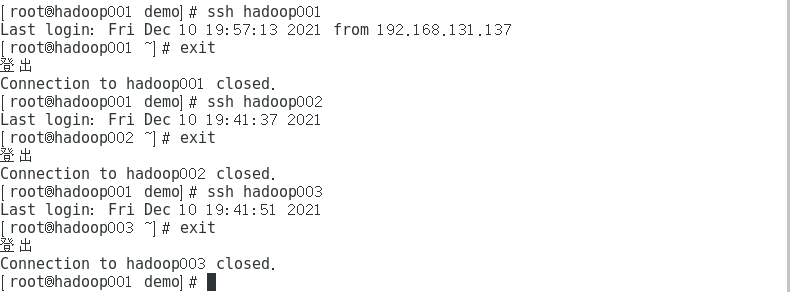
在另外 两台虚拟机 重复执行上述操作
三、安装JDK
创建目录
复制mkdir /data
上传安装包
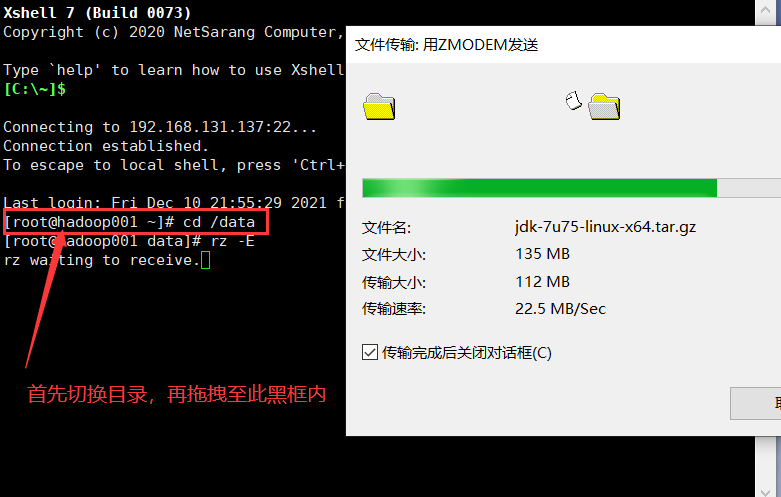
通过xshell连接hadoop001虚拟机
连接xshell后,切换至data目录,然后将jdk-7u75-linux-x64.tar.gz拖拽至xshell黑框里即可上传
复制cd /data
解压安装包
复制tar -zxvf /data/jdk-7u75-linux-x64.tar.gz -C /opt/
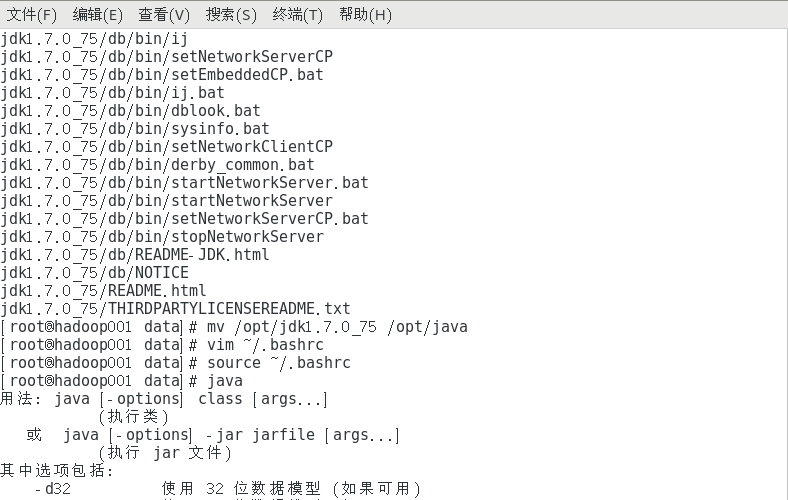
重新命名解压后的文件夹
复制mv /opt/jdk1.7.0_75 /opt/java
配置环境变量
复制vim ~/.bashrc
在环境变量后加上如下文本
复制#java export JAVA_HOME=/opt/java export PATH=$JAVA_HOME/bin:$PATH
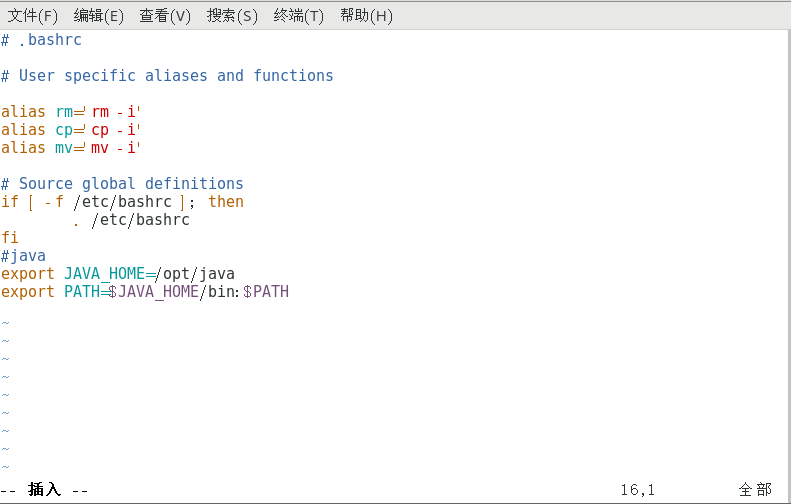
保存并且退出,然后刷新环境变量
复制source ~/.bashrc
检测环境变量配置是否生效
复制java
四、安装Hadoop
上传安装包
通过xshell连接hadoop001虚拟机
连接xshell后,切换至data目录,然后将hadoop-2.8.5.tar.gz拖拽至xshell黑框里即可上传
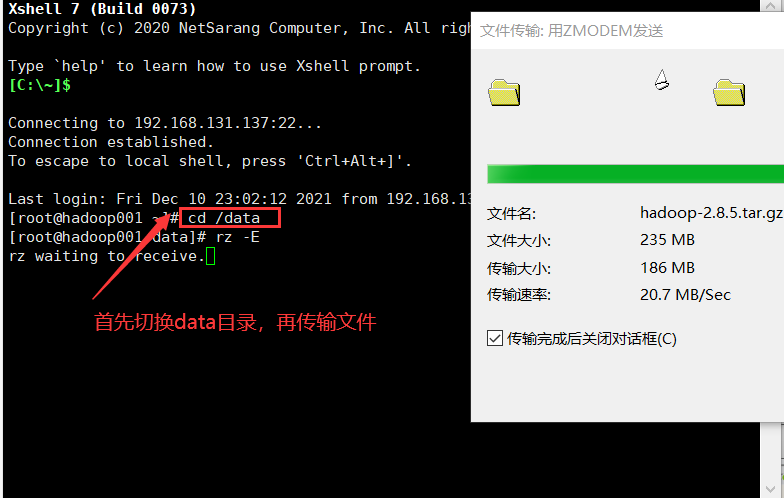
解压安装包
复制tar -zxvf /data/hadoop-2.8.5.tar.gz -C /opt/
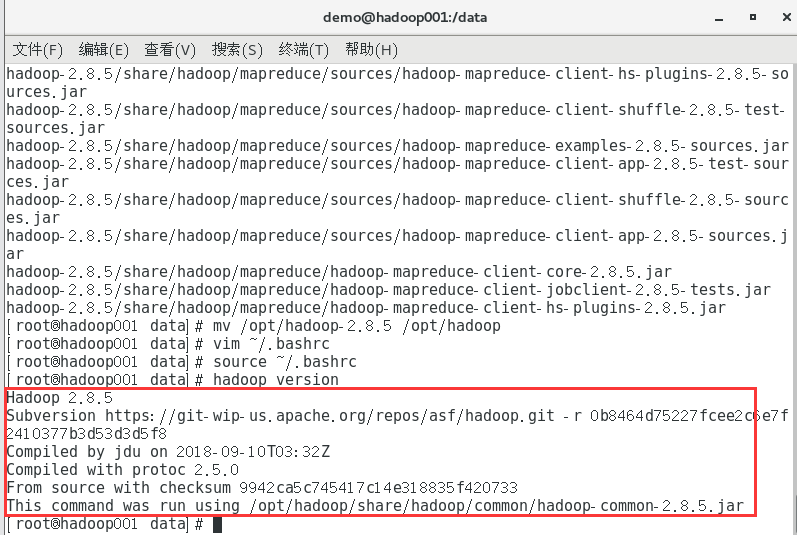
重新命名解压后的文件夹
复制mv /opt/hadoop-2.8.5 /opt/hadoop
配置环境变量
复制vim ~/.bashrc
在环境变量后加上如下文本
复制#hadoop export HADOOP_HOME=/opt/hadoop export PATH=$HADOOP_HOME/bin:$PATH
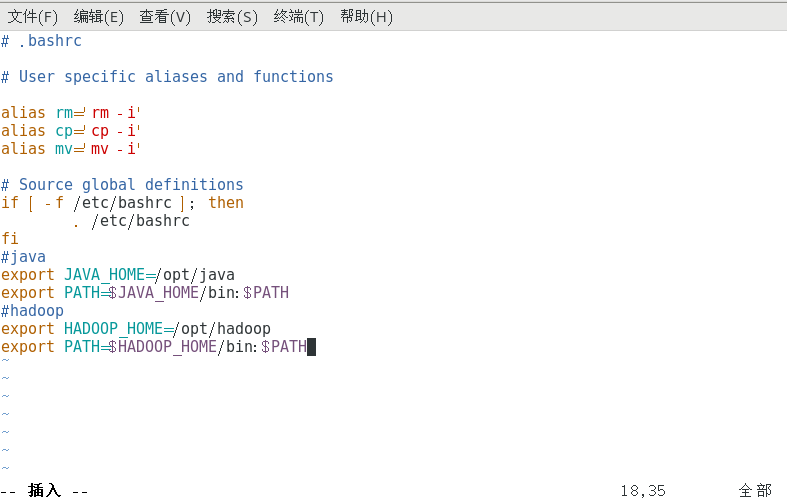
保存并且退出,然后刷新环境变量
复制source ~/.bashrc
检测环境变量配置是否生效
复制hadoop version
修改hadoop-env.sh配置文件
复制vim /opt/hadoop/etc/hadoop/hadoop-env.sh

修改core-site.xml配置文件
创建Hadoop临时文件存储文件夹
复制mkdir -p /data/tmp/hadoop/tmp
修改配置文件
复制vim /opt/hadoop/etc/hadoop/core-site.xml
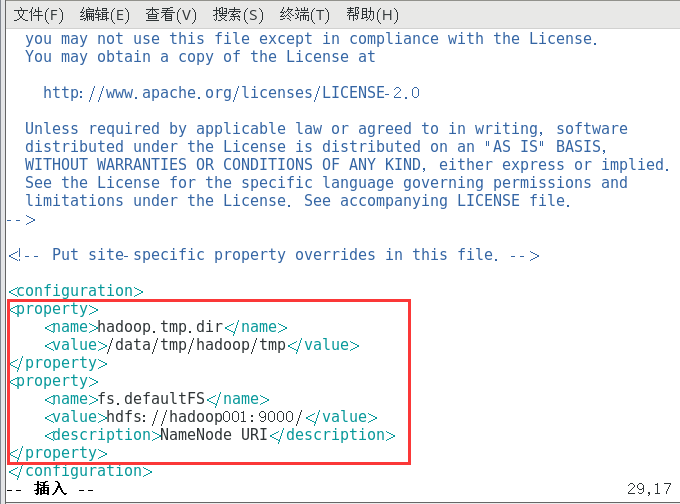
添加如下文本
复制<property> <name>hadoop.tmp.dir</name> <value>/data/tmp/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop001:9000/</value> <description>NameNode URI</description> </property>
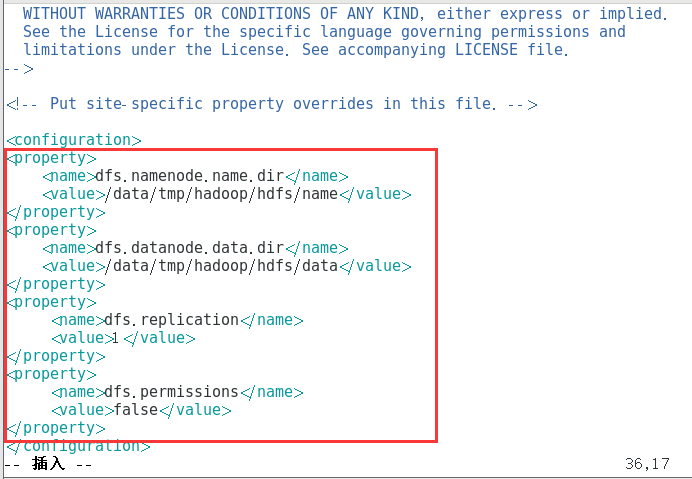
修改hdfs-site.xml配置文件
复制vim /opt/hadoop/etc/hadoop/hdfs-site.xml
添加如下文本
复制<property> <name>dfs.namenode.name.dir</name> <value>/data/tmp/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/tmp/hadoop/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property>
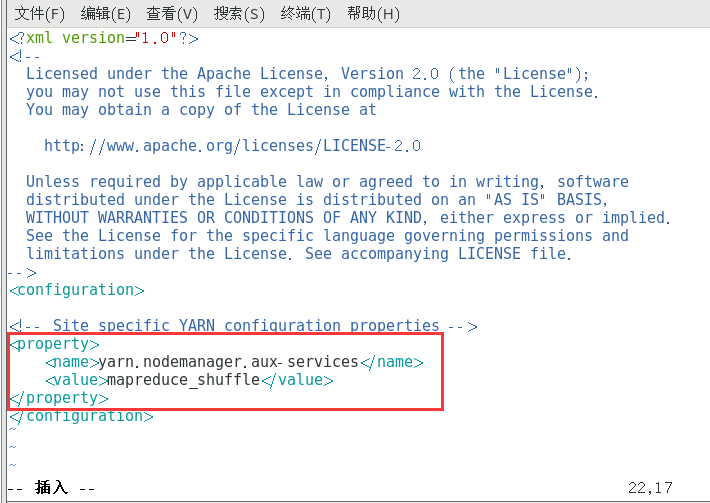
修改yarn-site.xml配置文件
复制vim /opt/hadoop/etc/hadoop/yarn-site.xml
添加如下文本
复制<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
修改mapred-site.xml.template配置文件
修改文件名
复制mv /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapred-site.xml
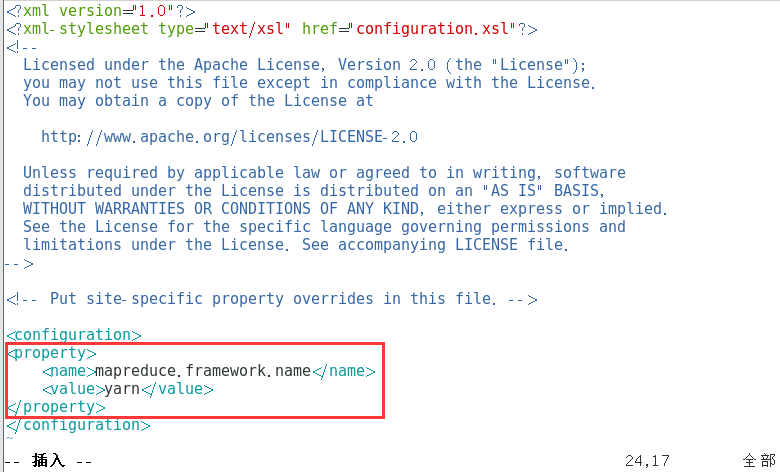
修改配置文件
复制vim /opt/hadoop/etc/hadoop/mapred-site.xml
添加如下文本
复制<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
修改slaves配置文件
复制vim /opt/hadoop/etc/hadoop/slaves
文件分发拷贝
复制scp -r /opt/java/ /opt/hadoop/ hadoop002:/tmp/ scp -r /opt/java/ /opt/hadoop/ hadoop003:/tmp/
五、从节点操作
以下操作 只需在另两台台虚拟机(hadoop002、hadoop003) 进行操作
移动文件夹
复制mv /tmp/java /opt/ mv /tmp/hadoop /opt/
创建数据文件夹
复制mkdir /data
配置Hadoop与JDK环境变量
复制vim ~/.bashrc
在环境变量后加上如下文本
复制#java export JAVA_HOME=/opt/java export PATH=$JAVA_HOME/bin:$PATH #hadoop export HADOOP_HOME=/opt/hadoop export PATH=$HADOOP_HOME/bin:$PATH
保存并退出,然后刷新环境变量
复制source ~/.bashrc
查看版本安装
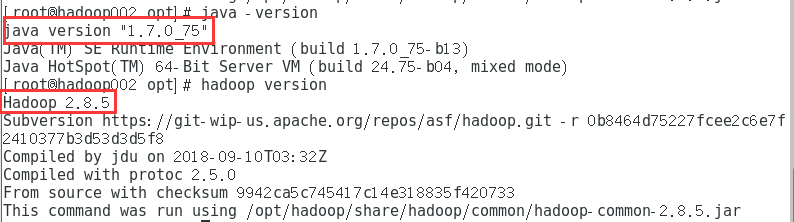
在另外 一台虚拟机(hadoop003) 重复执行上述操作
六、启动集群
切换至Hadoop安装目录
复制cd /opt/hadoop/sbin
格式化分布式文件系统
复制/opt/hadoop/bin/hadoop namenode -format
启动Hadoop,只需要在主节点(hadoop001)执行操作
复制./start-all.sh
查看启动进程
复制jps
主节点

从节点

关闭防火墙
复制systemctl stop firewalld systemctl disable firewalld.service
查看防火墙状态
复制firewall-cmd --state
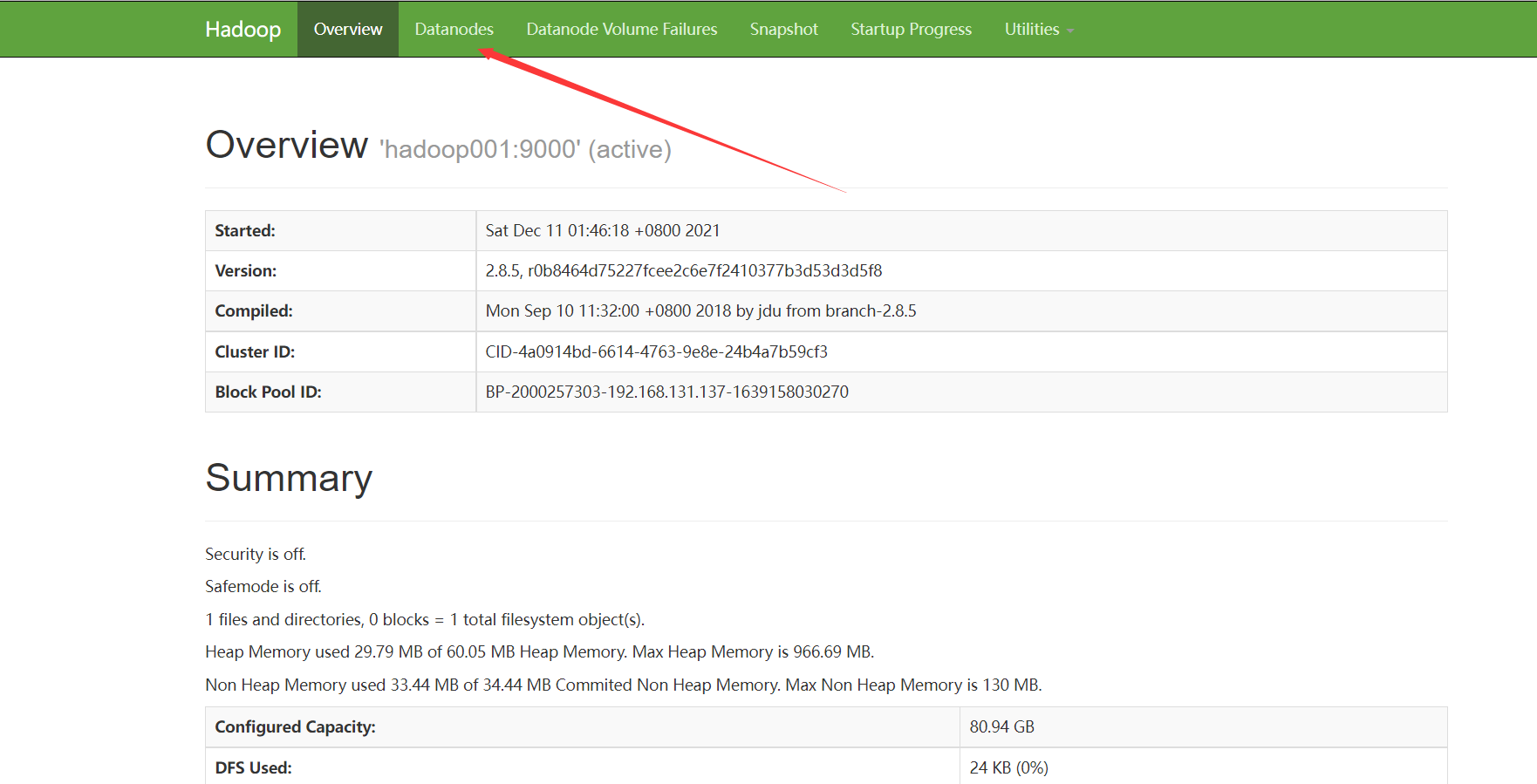
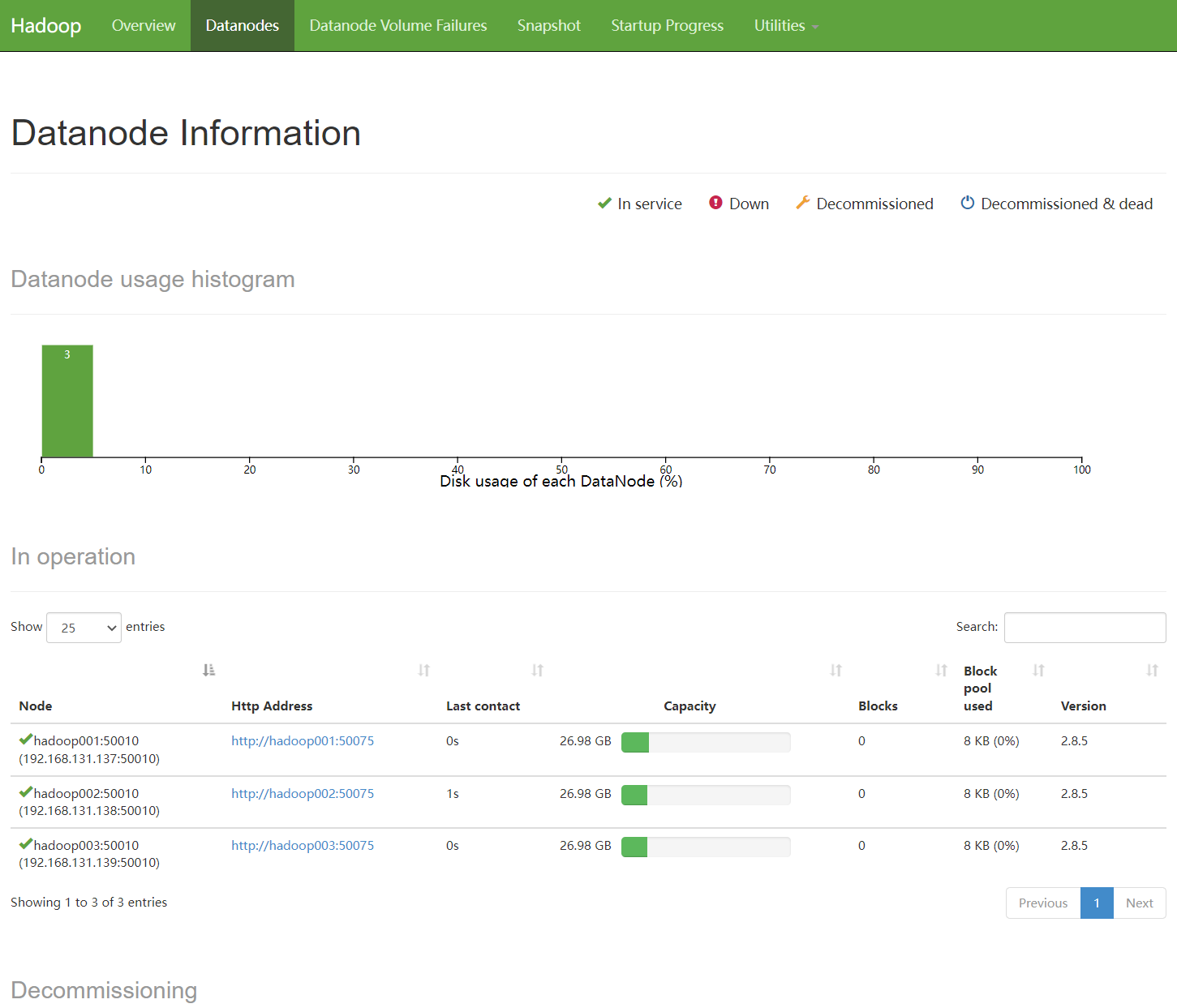
查看Web界面
192.168.131.137:50070(主节点IP:50070)
声明
本文档仅供学习交流使用,不可商用。
部分操作命令以及安装方式整理来源于网络,若有侵权请及时联系删除。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下