

python框架之Django(14)-rest_framework模块
APIView
django原生View
-
post请求
 content_type=x-www-form-urlencoded
content_type=x-www-form-urlencodedfrom django.shortcuts import render, HttpResponse from django import views class TestView(views.View): def post(self, request): print(request.POST) # <QueryDict: {'a': ['1'], 'b': ['2']}> print(request.body) # b'a=1&b=2' return HttpResponse('ok')
参数: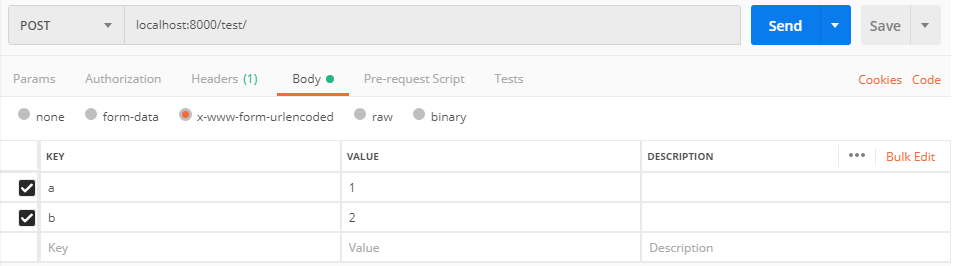 content_type=application/json
content_type=application/jsonfrom django.shortcuts import render, HttpResponse from django import views class TestView(views.View): def post(self, request): print(request.POST) # <QueryDict: {}> print(request.body) # b'{"a":1,"b":2}' return HttpResponse('ok')
-
源码
django.http.request.HttpRequest._load_post_and_files1 class HttpRequest(object): 2 def _load_post_and_files(self): 3 if self.method != 'POST': 4 self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict() 5 return 6 if self._read_started and not hasattr(self, '_body'): 7 self._mark_post_parse_error() 8 return 9 10 if self.content_type == 'multipart/form-data': 11 if hasattr(self, '_body'): 12 data = BytesIO(self._body) 13 else: 14 data = self 15 try: 16 self._post, self._files = self.parse_file_upload(self.META, data) 17 except MultiPartParserError: 18 self._mark_post_parse_error() 19 raise 20 elif self.content_type == 'application/x-www-form-urlencoded': 21 self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict() 22 else: 23 self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
查看源码第 10 行和第 20 会发现,django原生 HttpRequest 在 post 请求时,只有在 content_type 为 'multipart/form-data' 和 'application/x-www-form-urlencoded' 时,才会将body数据解析到 QueryDict (也就是我们使用的 request.POST )中。这也是上述以 content_type=application/json 的方式发送 post 请求时 request.POST 为空的原因。

rest_framework提供的APIView
-
post请求
content_type=application/jsonfrom django.shortcuts import render, HttpResponse from django import views from rest_framework.views import APIView class TestView(APIView): def post(self, request): print(request._request.body) # b'{"a":1,"b":2}' print(request.data) # {'a': 1, 'b': 2} return HttpResponse('ok')
-
源码
rest_framework.views.APIView1 class APIView(View): 2 @classmethod 3 def as_view(cls, **initkwargs): 4 if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet): 5 def force_evaluation(): 6 raise RuntimeError( 7 'Do not evaluate the `.queryset` attribute directly, ' 8 'as the result will be cached and reused between requests. ' 9 'Use `.all()` or call `.get_queryset()` instead.' 10 ) 11 cls.queryset._fetch_all = force_evaluation 12 13 view = super(APIView, cls).as_view(**initkwargs) 14 view.cls = cls 15 view.initkwargs = initkwargs 16 17 return csrf_exempt(view) 18 19 def dispatch(self, request, *args, **kwargs): 20 self.args = args 21 self.kwargs = kwargs 22 request = self.initialize_request(request, *args, **kwargs) 23 self.request = request 24 self.headers = self.default_response_headers # deprecate? 25 26 try: 27 self.initial(request, *args, **kwargs) 28 29 if request.method.lower() in self.http_method_names: 30 handler = getattr(self, request.method.lower(), 31 self.http_method_not_allowed) 32 else: 33 handler = self.http_method_not_allowed 34 35 response = handler(request, *args, **kwargs) 36 37 except Exception as exc: 38 response = self.handle_exception(exc) 39 40 self.response = self.finalize_response(request, response, *args, **kwargs) 41 return self.response
查看源码会发现, APIView 其实继承了原生 View ,并且重写了 as_view 和 dispatch 方法。而在 APIView.as_view 方法中又调用了原生 View 的 as_view 方法,而原生 View 的 as_view 方法中会调用 self.dispatch 方法,因为 APIView 对 dispatch 方法进行了重写,所以实际上是调用的 APIView.dispatch 方法(如果不了解原生 View 的执行可查看Django中CBV源码解析)。而在 22 行可以看到, request 被 self.initialize_request(request, *args, **kwargs) 方法重新赋值了,查看 initialize_request 方法:
rest_framework.views.APIView.initialize_request1 def initialize_request(self, request, *args, **kwargs): 2 parser_context = self.get_parser_context(request) 3 return Request( 4 request, 5 parsers=self.get_parsers(), 6 authenticators=self.get_authenticators(), 7 negotiator=self.get_content_negotiator(), 8 parser_context=parser_context 9 )
从第 3 行又可以看到该方法的返回值是把原生 request 传给 rest_framework.request.Request 类创建的一个实例,所以我们后续使用的 request 就都是这个实例了而不是原生 request 。继续看看这个类做了什么:
rest_framework.request.Request1 class Request(object): 2 def __init__(self, request, parsers=None, authenticators=None, 3 negotiator=None, parser_context=None): 4 assert isinstance(request, HttpRequest), ( 5 'The `request` argument must be an instance of ' 6 '`django.http.HttpRequest`, not `{}.{}`.' 7 .format(request.__class__.__module__, request.__class__.__name__) 8 ) 9 10 self._request = request 11 self.parsers = parsers or () 12 self.authenticators = authenticators or () 13 self.negotiator = negotiator or self._default_negotiator() 14 self.parser_context = parser_context 15 self._data = Empty 16 self._files = Empty 17 self._full_data = Empty 18 self._content_type = Empty 19 self._stream = Empty 20 21 if self.parser_context is None: 22 self.parser_context = {} 23 self.parser_context['request'] = self 24 self.parser_context['encoding'] = request.encoding or settings.DEFAULT_CHARSET 25 26 force_user = getattr(request, '_force_auth_user', None) 27 force_token = getattr(request, '_force_auth_token', None) 28 if force_user is not None or force_token is not None: 29 forced_auth = ForcedAuthentication(force_user, force_token) 30 self.authenticators = (forced_auth,) 31 32 @property 33 def data(self): 34 if not _hasattr(self, '_full_data'): 35 self._load_data_and_files() 36 return self._full_data 37 38 def _load_data_and_files(self): 39 if not _hasattr(self, '_data'): 40 self._data, self._files = self._parse() 41 if self._files: 42 self._full_data = self._data.copy() 43 self._full_data.update(self._files) 44 else: 45 self._full_data = self._data 46 47 if is_form_media_type(self.content_type): 48 self._request._post = self.POST 49 self._request._files = self.FILES 50 51 def _parse(self): 52 """ 53 Parse the request content, returning a two-tuple of (data, files) 54 55 May raise an `UnsupportedMediaType`, or `ParseError` exception. 56 """ 57 media_type = self.content_type 58 try: 59 stream = self.stream 60 except RawPostDataException: 61 if not hasattr(self._request, '_post'): 62 raise 63 if self._supports_form_parsing(): 64 return (self._request.POST, self._request.FILES) 65 stream = None 66 67 if stream is None or media_type is None: 68 if media_type and is_form_media_type(media_type): 69 empty_data = QueryDict('', encoding=self._request._encoding) 70 else: 71 empty_data = {} 72 empty_files = MultiValueDict() 73 return (empty_data, empty_files) 74 75 parser = self.negotiator.select_parser(self, self.parsers) 76 77 if not parser: 78 raise exceptions.UnsupportedMediaType(media_type) 79 80 try: 81 parsed = parser.parse(stream, media_type, self.parser_context) 82 except Exception: 83 self._data = QueryDict('', encoding=self._request._encoding) 84 self._files = MultiValueDict() 85 self._full_data = self._data 86 raise 87 88 try: 89 return (parsed.data, parsed.files) 90 except AttributeError: 91 empty_files = MultiValueDict() 92 return (parsed, empty_files)
先看第 10 行,这里把原生 request 赋值给了当前实例的 _request 属性,也就是说,在使用 APIView 时,我们可以通过 request._request 拿到原生 request 实例。再看 33 行的 data 方法,它的返回值是 self._full_data ,而 self._full_data 的赋值是由于 35 行调用 38 行的 _load_data_and_files 方法进行的。再看 45 行 self._full_data = self._data ,而 self._data 是 40 行调用 51 行的 _parse 方法的返回值之一。而 _parse 方法的作用实际上就是通过判断不同请求的 content_type 来使用不同的解析器将数据封装成 QueryDict 返回给 request.data ,所以我们在使用 APIView时,可以通过 request.data 拿到解析后的数据。
Serializer
准备
from django.db import models class Book(models.Model): title = models.CharField(max_length=32) price = models.IntegerField() pub_date = models.DateField() publish = models.ForeignKey("Publish") authors = models.ManyToManyField("Author") def __str__(self): return self.title class Publish(models.Model): name = models.CharField(max_length=32) email = models.EmailField() def __str__(self): return self.name class Author(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() def __str__(self): return self.name
序列化的几种方式
from django.shortcuts import render, HttpResponse from test_app import models from django import views class PublishView(views.View): def get(self, request): import json obj_set = models.Publish.objects.all() list = list(obj_set.values('id', 'name')) json = json.dumps(list) return HttpResponse(json)
from django.shortcuts import render, HttpResponse from test_app import models from django import views class PublishView(views.View): def get(self, request): import json from django.forms.models import model_to_dict obj_set = models.Publish.objects.all() list = [model_to_dict(obj) for obj in obj_set] return HttpResponse(json.dumps(list))
from django.shortcuts import render, HttpResponse from test_app import models from django import views class PublishView(views.View): def get(self, request): obj_set = models.Publish.objects.all() from django.core import serializers list = serializers.serialize('json', obj_set) return HttpResponse(list)
rest_framework提供的serializers
无关联字段
from django.http import JsonResponse from test_app import models from django import views from rest_framework import serializers # 定义一个和模型对应的序列化类 里面包含要进行序列化的字段 class PublishSerializer(serializers.Serializer): name = serializers.CharField() email = serializers.CharField() class PublishView(views.View): def get(self, request): obj_list = models.Publish.objects.all() serializer = PublishSerializer(obj_list, many=True) # many默认为False,序列化单个对象,序列化列表时需要指定many=True。 print( serializer.data) # [OrderedDict([('name', '苹果出版社'), ('email', 'apple@qq.com')]), OrderedDict([('name', '橡胶出版社'), ('email', 'xj@qq.com')])] return JsonResponse(serializer.data,safe=False)
上面示例中使用的是之前用过的 django.http.JsonResponse ,其实 rest_framework 也对应提供了一个 rest_framework.response.Response :
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.IntegerField() pub_date = serializers.CharField() class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookSerializer(obj_list, many=True) return Response(serializer.data)
但是当我们访问时会报如下错误:
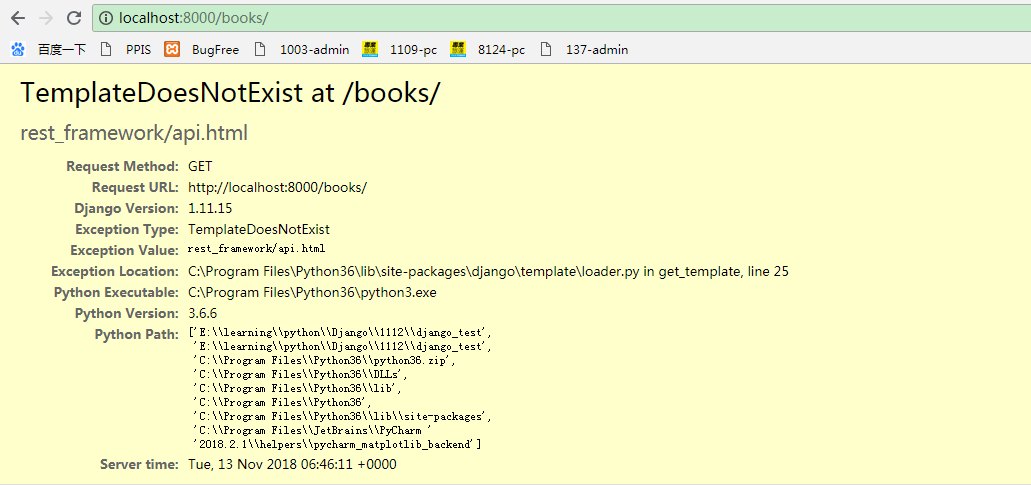
很明显是找不到文件的错误,原因是 rest_framework 本质上也是一个app,需要按照django的规则在 setting.py 中注册一下如下:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'test_app.apps.TestAppConfig', 'rest_framework' ]
再次访问 http://localhost:8000/books/ :
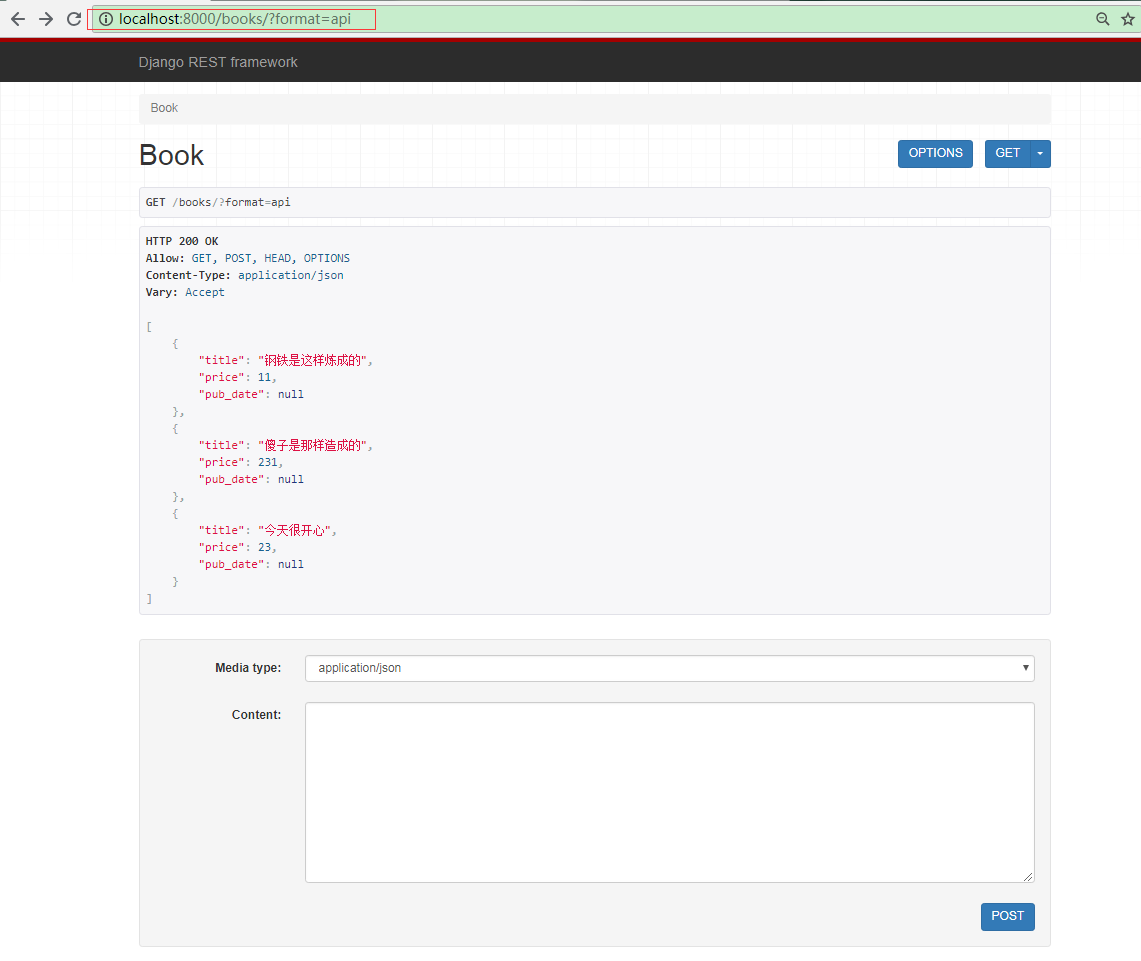
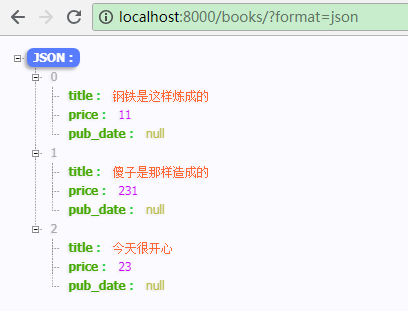
会发现浏览器会被重定向到 http://localhost:8000/books/?format=api ,这是 rest_framework 给我们提供的一个简易的请求工具页面(rest_framework 会判断当前请求来源,如果是浏览器,则重定向到格式化后的页面;如果不是,则返回原生数据),如果要原生的数据显示,修改url中 format 参数为 json 即可:
有关联字段
-
SerializerMethodField
这种方式比较灵活,可以控制外键字段,也可以控制多对多字段。
例:from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.IntegerField() pub_date = serializers.CharField() publish = serializers.SerializerMethodField() authors = serializers.SerializerMethodField() def get_publish(self, obj): return model_to_dict(obj.publish) def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookSerializer(obj_list, many=True) return Response(serializer.data)

-
source属性
当只需要外键字段的一个属性时,可使用source属性。
例:from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookSerializer(serializers.Serializer): title = serializers.CharField(max_length=32) price = serializers.IntegerField() pub_date = serializers.CharField() publish = serializers.CharField(source='publish.email') authors = serializers.SerializerMethodField() def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookSerializer(obj_list, many=True) return Response(serializer.data)

ModelSerializer
返回列表数据
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookModelSerializer(obj_list,many=True) return Response(serializer.data)

默认情况下 ModelSerializer 只会显示关联字段的 pk 值,如果需要对某些字段单独处理,直接定义字段规则即可:
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email') authors = serializers.SerializerMethodField() def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookModelSerializer(obj_list, many=True) return Response(serializer.data)

还有一种更简单的办法就是通过 depth 指定序列化时关联的深度,如下:
from api.models import * from rest_framework import serializers from rest_framework.views import APIView from api import models from rest_framework.response import Response class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' depth = 1 class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookModelSerializer(obj_list, many=True) return Response(serializer.data)

这种使用方式的一个弊端就是可能会多余返回很多冗余的字段,慎用。
新增单条数据
-
无关联字段
例:新增操作from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class PublishModelSerializer(serializers.ModelSerializer): class Meta: model = models.Publish fields = '__all__' class PublishView(APIView): def post(self, request): modelSerializer = PublishModelSerializer(data=request.data) if modelSerializer.is_valid(): modelSerializer.save() return Response(modelSerializer.data) else: return Response(modelSerializer.errors)
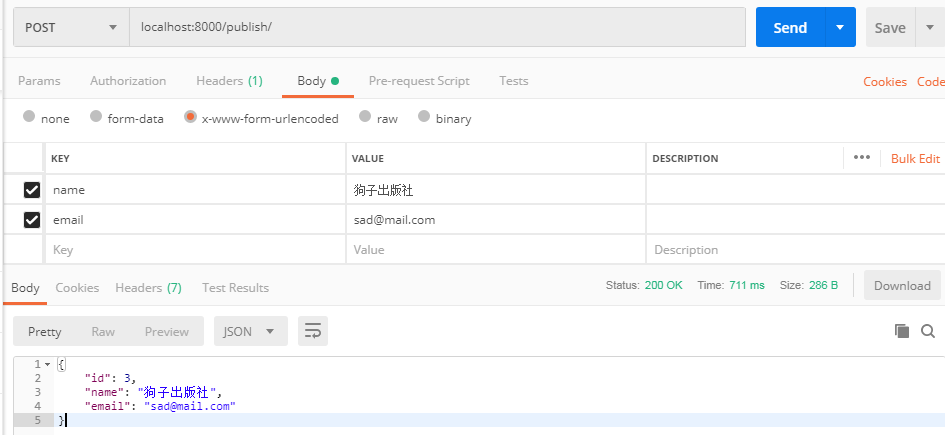
示例中输入的是正确的格式,保存成功。当输入一个不正确的邮箱格式提交,可以看到执行 modelSerializer.is_valid() 时根据model中定义的字段进行了规则校验,并通过 modelSerializer.errors 返回了错误信息。
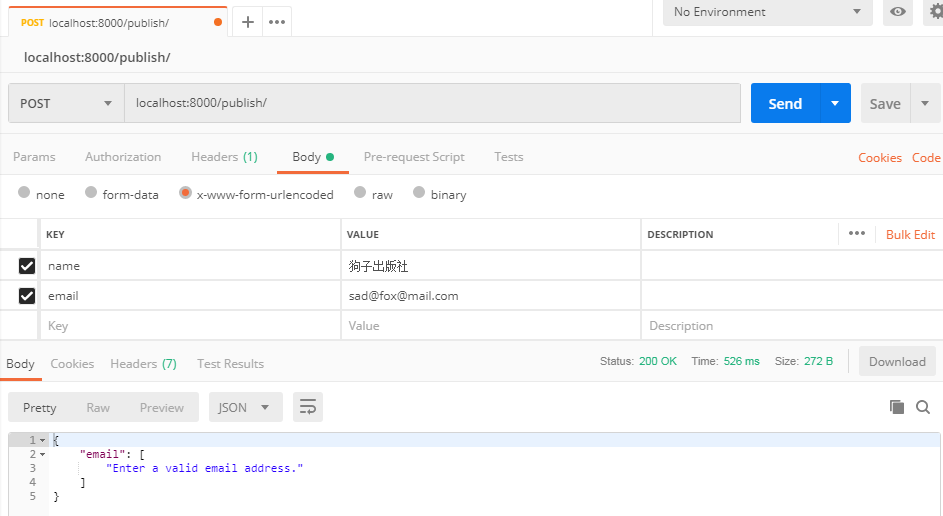
-
有关联字段
例:新增操作from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email') authors = serializers.SerializerMethodField() def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] class BookView(APIView): def get(self, request): obj_list = models.Book.objects.all() serializer = BookModelSerializer(obj_list, many=True) return Response(serializer.data) def post(self, request): modelSerializer = BookModelSerializer(data=request.data) if modelSerializer.is_valid(): modelSerializer.save() return Response(modelSerializer.data) else: return Response(modelSerializer.errors)
提交数据会出现如下报错信息:
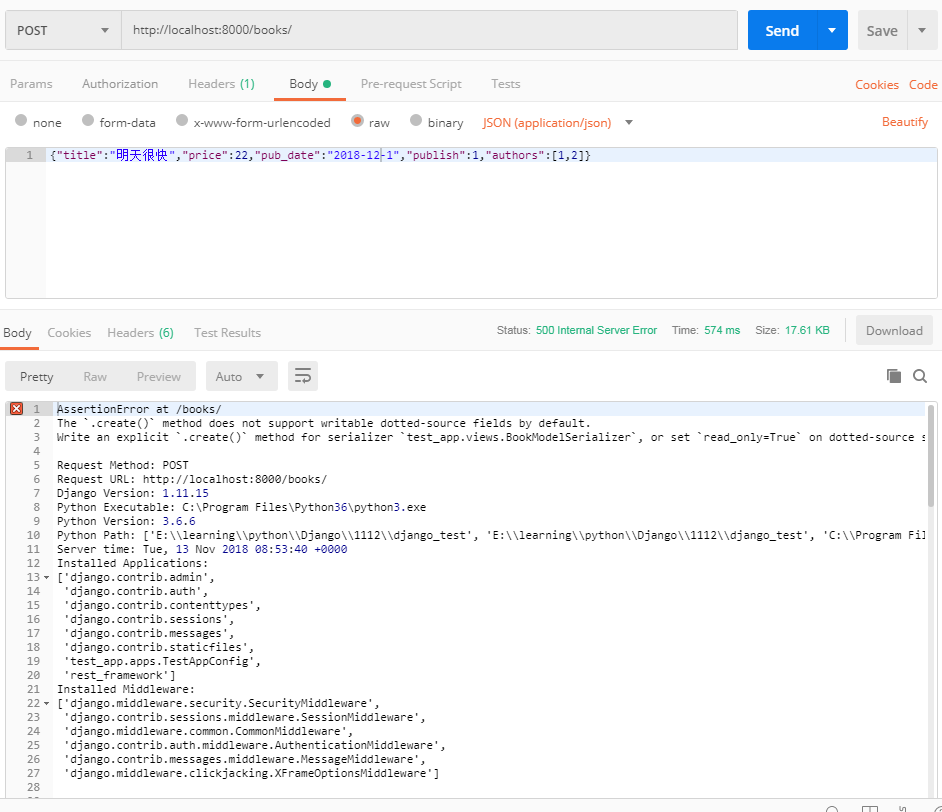
原因是在 ModelSerializer 中覆盖了对应模型的同名字段。
解决方案一:新增一个和模型中字段名不重复的字段,并设置 read_only=True (标识仅显示时使用该字段)。
方案一from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish_email = serializers.CharField(source='publish.email', read_only=True) author_list = serializers.SerializerMethodField(read_only=True) def get_author_list(self, obj): return [model_to_dict(o) for o in obj.authors.all()] class BookView(APIView): def post(self, request): modelSerializer = BookModelSerializer(data=request.data) if modelSerializer.is_valid(): modelSerializer.save() return Response(modelSerializer.data) else: return Response(modelSerializer.errors)
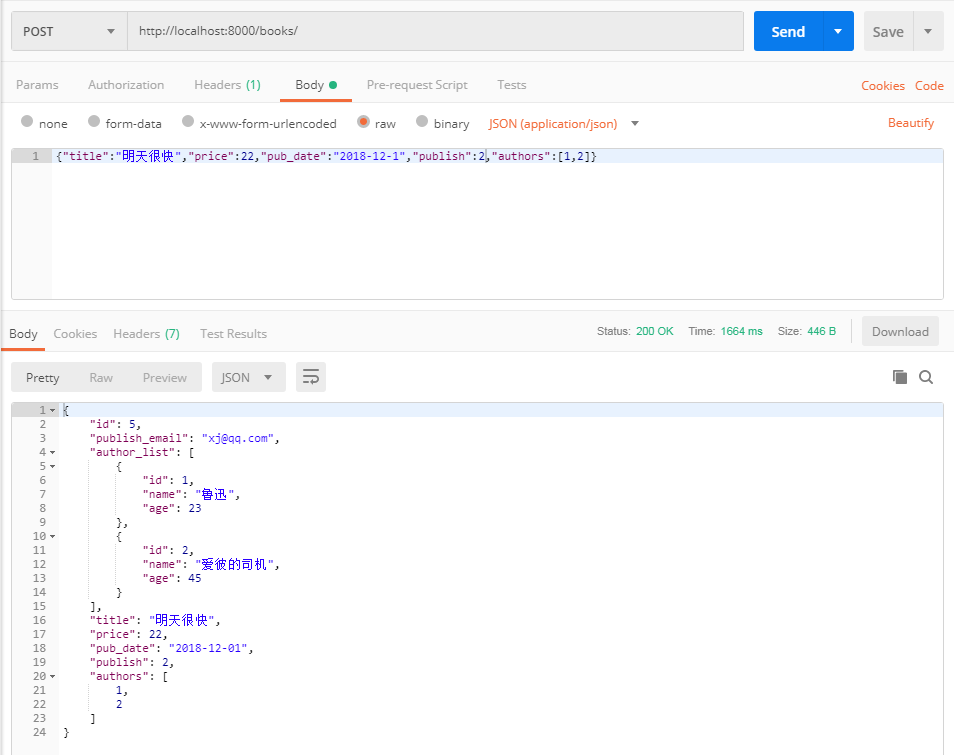
注:如果不设置 read_only=True ,那么提交的数据必须带上新增的字段。
解决方案二:新增同名字段设设置其属性 read_only=True ,还需要重写 ModelSerializer 中的 create 方法。新增接收参数的字段,并设置 write_only=True (标识仅接收数据时使用该字段)。
方案二from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email', read_only=True) publish_pk = serializers.IntegerField(write_only=True) authors = serializers.SerializerMethodField(read_only=True) author_pk_list = serializers.ListField(write_only=True) def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] def create(self, validated_data): print(validated_data) # {'publish_pk': 2, 'author_pk_list': [1, 2], 'title': '明天超级慢', 'price': 22, 'pub_date': datetime.date(2018, 12, 1)} publish_pk = validated_data.pop('publish_pk') author_pk_list = validated_data.pop('author_pk_list') book = models.Book.objects.create(publish_id=publish_pk, **validated_data) book.authors = models.Author.objects.filter(id__in=author_pk_list) return book class BookView(APIView): def post(self, request): modelSerializer = BookModelSerializer(data=request.data) if modelSerializer.is_valid(): modelSerializer.save() return Response(modelSerializer.data) else: return Response(modelSerializer.errors)
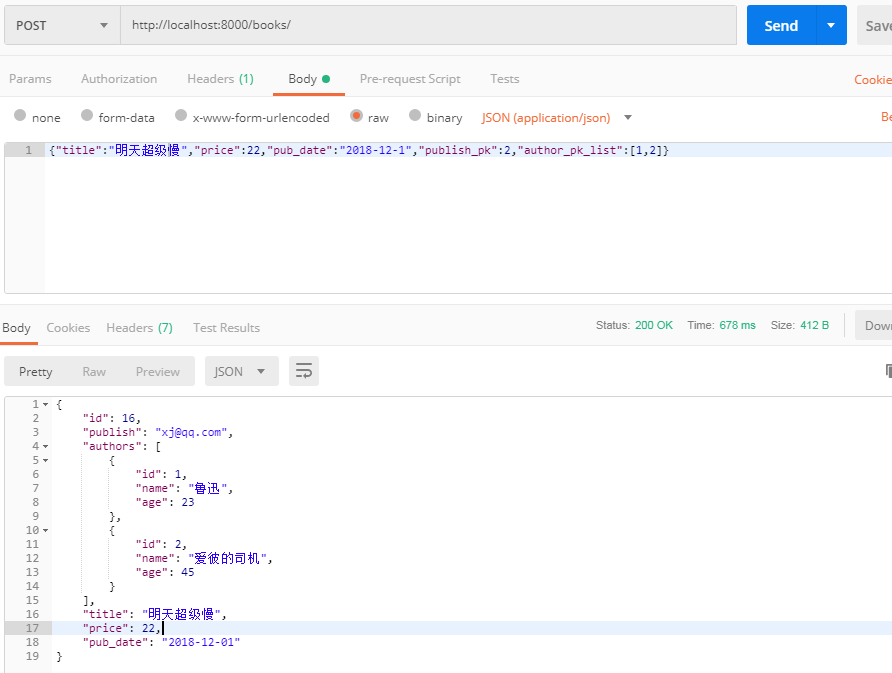
获取单条数据
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email', read_only=True) publish_pk = serializers.IntegerField(write_only=True) authors = serializers.SerializerMethodField(read_only=True) author_pk_list = serializers.ListField(write_only=True) def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] def create(self, validated_data): print( validated_data) # {'publish_pk': 2, 'author_pk_list': [1, 2], 'title': '明天超级慢', 'price': 22, 'pub_date': datetime.date(2018, 12, 1)} publish_pk = validated_data.pop('publish_pk') author_pk_list = validated_data.pop('author_pk_list') book = models.Book.objects.create(publish_id=publish_pk, **validated_data) book.authors = models.Author.objects.filter(id__in=author_pk_list) return book class BookDetailView(APIView): def get(self, request, id): book_obj = models.Book.objects.get(id=id) modelSerializer = BookModelSerializer(book_obj) return Response(modelSerializer.data)
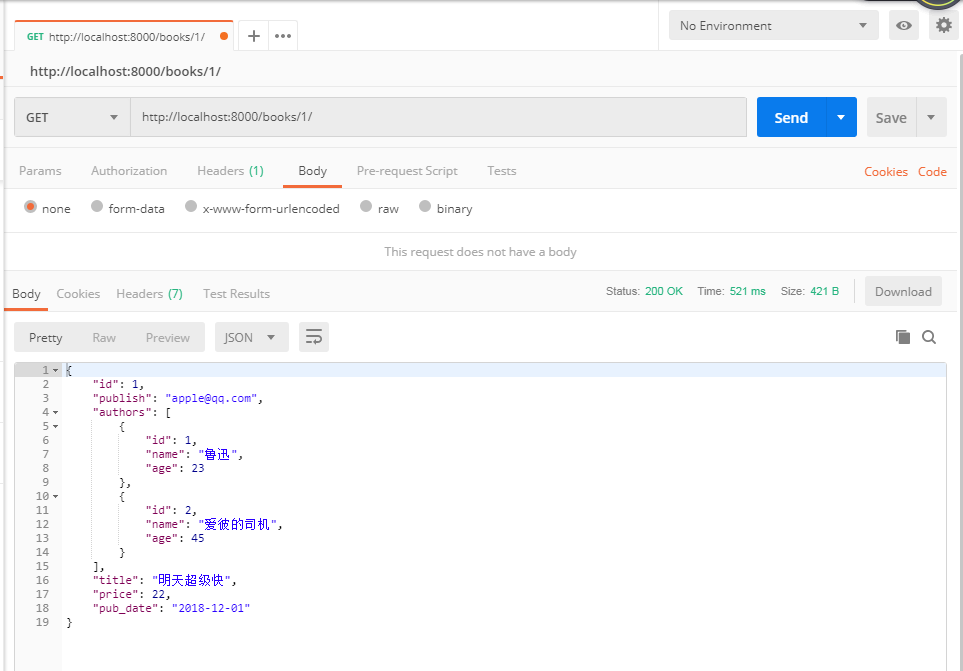
编辑单条数据
和新增单条数据相似,也有两种方式:
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish_name = serializers.CharField(source='publish.name', read_only=True) author_list = serializers.SerializerMethodField(read_only=True) def get_author_list(self, obj): return [model_to_dict(o) for o in obj.authors.all()] class BookDetailView(APIView): def put(self, request, id): book_obj = models.Book.objects.get(id=id) modelSerializer = BookModelSerializer(book_obj, data=request.data) if modelSerializer.is_valid(): return Response(BookModelSerializer(modelSerializer.save()).data) else: return Response(modelSerializer.errors)
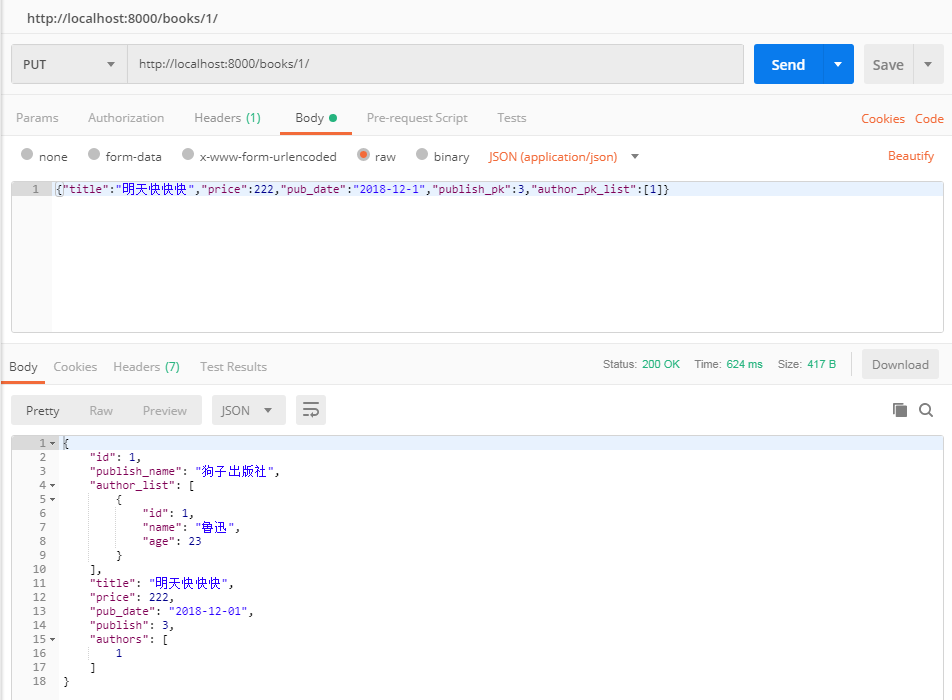
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email', read_only=True) publish_pk = serializers.IntegerField(write_only=True) authors = serializers.SerializerMethodField(read_only=True) author_pk_list = serializers.ListField(write_only=True) def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] def create(self, validated_data): print( validated_data) # {'publish_pk': 2, 'author_pk_list': [1, 2], 'title': '明天超级慢', 'price': 22, 'pub_date': datetime.date(2018, 12, 1)} publish_pk = validated_data.pop('publish_pk') author_pk_list = validated_data.pop('author_pk_list') book = models.Book.objects.create(publish_id=publish_pk, **validated_data) book.authors = models.Author.objects.filter(id__in=author_pk_list) return book def update(self, instance, validated_data): instance.title = validated_data['title'] instance.price = validated_data['price'] instance.pub_date = validated_data['pub_date'] instance.publish_id = validated_data['publish_pk'] instance.authors = models.Author.objects.filter(id__in =validated_data['author_pk_list']) instance.save() return instance class BookDetailView(APIView): def put(self, request, id): book_obj = models.Book.objects.get(id=id) modelSerializer = BookModelSerializer(book_obj, data=request.data) if modelSerializer.is_valid(): return Response(BookModelSerializer(modelSerializer.save()).data) else: return Response(modelSerializer.errors)

删除单条数据
from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email', read_only=True) publish_pk = serializers.IntegerField(write_only=True) authors = serializers.SerializerMethodField(read_only=True) author_pk_list = serializers.ListField(write_only=True) def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] def create(self, validated_data): print( validated_data) # {'publish_pk': 2, 'author_pk_list': [1, 2], 'title': '明天超级慢', 'price': 22, 'pub_date': datetime.date(2018, 12, 1)} publish_pk = validated_data.pop('publish_pk') author_pk_list = validated_data.pop('author_pk_list') book = models.Book.objects.create(publish_id=publish_pk, **validated_data) book.authors = models.Author.objects.filter(id__in=author_pk_list) return book class BookDetailView(APIView): def delete(self,request,id): models.Book.objects.get(id=id).delete() return Response('删除成功')
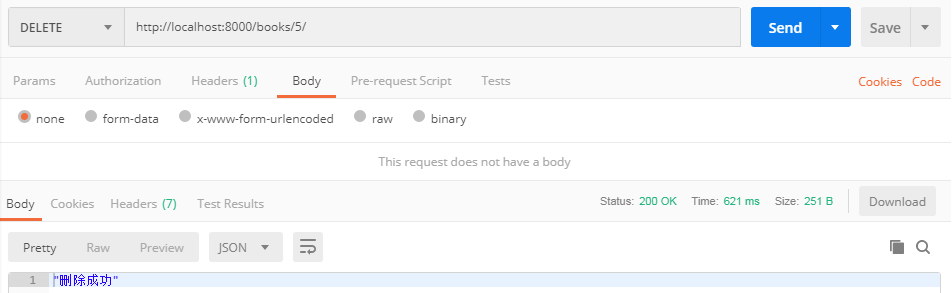
补充
-
HyperlinkedIdentityField
路由from django.conf.urls import url from django.contrib import admin from test_app import views urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^publish/$', views.PublishView.as_view()), url(r'^publish/(?P<pk>\d+)/', views.PublishDetailView.as_view(), name='publish_detail'), url(r'^books/$', views.BookView.as_view()), url(r'^books/(\d+)/', views.BookDetailView.as_view()), ]
视图from rest_framework import serializers from rest_framework.views import APIView from test_app import models from rest_framework.response import Response from django.forms.models import model_to_dict class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' publish = serializers.CharField(source='publish.email', read_only=True) publish_pk = serializers.IntegerField(write_only=True) authors = serializers.SerializerMethodField(read_only=True) author_pk_list = serializers.ListField(write_only=True) publish_link = serializers.HyperlinkedIdentityField( view_name='publish_detail', lookup_field="publish_id", lookup_url_kwarg="pk" ) def get_authors(self, obj): return [model_to_dict(o) for o in obj.authors.all()] def update(self, instance, validated_data): instance.title = validated_data['title'] instance.price = validated_data['price'] instance.pub_date = validated_data['pub_date'] instance.publish_id = validated_data['publish_pk'] instance.authors = models.Author.objects.filter(id__in=validated_data['author_pk_list']) instance.save() return instance class BookView(APIView): def post(self, request): modelSerializer = BookModelSerializer(data=request.data, context={'request': request}) if modelSerializer.is_valid(): modelSerializer.save() return Response(modelSerializer.data) else: return Response(modelSerializer.errors) def get(self, request): obj_list = models.Book.objects.all() serializer = BookModelSerializer(obj_list, many=True, context={'request': request}) return Response(serializer.data) class BookDetailView(APIView): def put(self, request, id): book_obj = models.Book.objects.get(id=id) modelSerializer = BookModelSerializer(book_obj, data=request.data) if modelSerializer.is_valid(): return Response(BookModelSerializer(modelSerializer.save(), context={'request': request}).data) else: return Response(modelSerializer.errors) def get(self, request, id): book_obj = models.Book.objects.get(id=id) modelSerializer = BookModelSerializer(book_obj, context={'request': request}) return Response(modelSerializer.data) def delete(self, request, id): models.Book.objects.get(id=id).delete() return Response('删除成功')

- 注意事项:
- 1、对应路由中的url必须是以有名分组的形式。
- 2、关于属性, view_name 对应路由中url中的 name, lookup_field 用来将当前实例的指定字段值来填充url中的有名分组部分, lookup_url_kwarg 对应url中分组名称。
- 3、只要使用了该字段,那么在创建 ModelSerializer 实例用来序列化时必须指定属性 context={'request': request} ,否则会报错。
mixins
观察上节 ModelSerializer 内容,我们会发现不同模型的增删改查操作中其实有大量的重复逻辑。这些重复逻辑能不能抽取出来呢? mixin 模块就帮我们做了这一点。
继承Mixin类编写视图
from django.conf.urls import url from django.contrib import admin from test_app import views from test_app import mixin_views urlpatterns = [ url(r'^authors/$', mixin_views.AuthorView.as_view()), url(r'^authors/(?P<pk>\d+)/', mixin_views.AuthorDetailView.as_view()), ]
from rest_framework import serializers from test_app.models import * from rest_framework import mixins from rest_framework import generics class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorView(mixins.ListModelMixin, mixins.CreateModelMixin, generics.GenericAPIView): queryset = Author.objects.all() serializer_class = AuthorModelSerializer def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs) def post(self, request, *args, **kwargs): return self.create(request, *args, **kwargs) class AuthorDetailView(mixins.RetrieveModelMixin, mixins.UpdateModelMixin, mixins.DestroyModelMixin, generics.GenericAPIView): queryset = Author.objects.all() serializer_class = AuthorModelSerializer def get(self, request, *args, **kwargs): return self.retrieve(request, *args, **kwargs) def put(self,request, *args, **kwargs): return self.update(request, *args, **kwargs) def delete(self,request, *args, **kwargs): return self.destroy(request, *args, **kwargs)
通过上述代码就能实现上节中的列表查询和单条数据的增删查改功能。
- 注意事项:
- 1、视图类中必须定义 queryset 和 serializer_class 属性( queryset :对应模型的所有数据集合, serializer_class :对应的 ModelSerializer 类)。
- 2、路由中单条数据操作的url中必须包含名为 pk 的分组。
- 3、视图类必须继承 rest_framework.generics.GenericAPIView , mixins.ListModelMixin,mixins.CreateModelMixin 分别对应列表和新增操作, mixins.RetrieveModelMixin, mixins.UpdateModelMixin, mixins.DestroyModelMixin 分别对应单条数据的获取、修改和删除操作。
通用视图
通过使用 Mixin 类,我们使用更少的代码重写了这些视图,但我们还可以再进一步。 rest_framework 提供了一组已经混合好(mixed-in)的通用视图,我们可以使用它来继续简化我们的视图。路由不变,修改视图:
from rest_framework import serializers from test_app.models import * from rest_framework import generics class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorView(generics.ListCreateAPIView): queryset = Author.objects.all() serializer_class = AuthorModelSerializer class AuthorDetailView(generics.RetrieveUpdateDestroyAPIView): queryset = Author.objects.all() serializer_class = AuthorModelSerializer
查看继承类的源码:
class ListCreateAPIView(mixins.ListModelMixin, mixins.CreateModelMixin, GenericAPIView): def get(self, request, *args, **kwargs): return self.list(request, *args, **kwargs) def post(self, request, *args, **kwargs): return self.create(request, *args, **kwargs)
class RetrieveUpdateDestroyAPIView(mixins.RetrieveModelMixin, mixins.UpdateModelMixin, mixins.DestroyModelMixin, GenericAPIView): def get(self, request, *args, **kwargs): return self.retrieve(request, *args, **kwargs) def put(self, request, *args, **kwargs): return self.update(request, *args, **kwargs) def patch(self, request, *args, **kwargs): return self.partial_update(request, *args, **kwargs) def delete(self, request, *args, **kwargs): return self.destroy(request, *args, **kwargs)
发现它们其实很简单,就是将我们之前继承到的多个类统一到一起继承,并且帮我们实现了重复的 CRUD 的逻辑。
ModelViewSet
-
使用
在上面操作中,因为列表查询和单条数据获取都是通过 get 方法,所以为了区分只能使用两个视图,而 rest_framework.viewsets.ModelViewSet 能帮我们将其整合为一个类,但同时我们要给路由中配置的视图类的 as_view 方法增加一个字典参数,利用这个字典参数,来指定什么请求时执行什么方法。
路由from django.conf.urls import url from django.contrib import admin from test_app import views from test_app import mixin_views urlpatterns = [ url(r'^authors/$', mixin_views.AuthorViewSet.as_view({"get":"list","post":"create"})), url(r'^authors/(?P<pk>\d+)/', mixin_views.AuthorViewSet.as_view({ 'get': 'retrieve', 'put': 'update', 'patch': 'partial_update', 'delete': 'destroy' })), ]
视图from test_app.models import * from rest_framework import generics,viewsets,serializers class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer
-
源码分析
首先先看一下 ModelViewSet 的继承结构:ModelViewSet(mixins.CreateModelMixin,mixins.RetrieveModelMixin,mixins.UpdateModelMixin,mixins.DestroyModelMixin,mixins.ListModelMixin,GenericViewSet) GenericViewSet(ViewSetMixin, generics.GenericAPIView) GenericAPIView(views.APIView) APIView(View)路由中执行的 as_view 方法实际上是 rest_framework.viewsets.ViewSetMixin.as_view 方法,查看源码:
rest_framework.viewsets.ViewSetMixin.as_view1 class ViewSetMixin(object): 2 @classonlymethod 3 def as_view(cls, actions=None, **initkwargs): 4 cls.suffix = None 5 6 cls.detail = None 7 8 cls.basename = None 9 10 if not actions: 11 raise TypeError("The `actions` argument must be provided when " 12 "calling `.as_view()` on a ViewSet. For example " 13 "`.as_view({'get': 'list'})`") 14 for key in initkwargs: 15 if key in cls.http_method_names: 16 raise TypeError("You tried to pass in the %s method name as a " 17 "keyword argument to %s(). Don't do that." 18 % (key, cls.__name__)) 19 if not hasattr(cls, key): 20 raise TypeError("%s() received an invalid keyword %r" % ( 21 cls.__name__, key)) 22 23 def view(request, *args, **kwargs): 24 self = cls(**initkwargs) 25 self.action_map = actions 26 27 for method, action in actions.items(): 28 handler = getattr(self, action) 29 setattr(self, method, handler) 30 31 if hasattr(self, 'get') and not hasattr(self, 'head'): 32 self.head = self.get 33 34 self.request = request 35 self.args = args 36 self.kwargs = kwargs 37 38 return self.dispatch(request, *args, **kwargs) 39 40 update_wrapper(view, cls, updated=()) 41 42 update_wrapper(view, cls.dispatch, assigned=()) 43 44 view.cls = cls 45 view.initkwargs = initkwargs 46 view.suffix = initkwargs.get('suffix', None) 47 view.actions = actions 48 return csrf_exempt(view)
可以看到它的返回值是 23 行定义的 view 方法的句柄, 改方法在请求时执行。直接看 27-29 行, actions 实际上就是我们传入的规则字典。假入我们传入 {'get':'list'} 为例,第 28 行就是从当前实例中获取名为 list 的方法,而 list 方法定义在 rest_framework.mixins.ListModelMixin 中。所以在 29 行实际上是把 rest_framework.mixins.ListModelMixin.list 赋值给了 self.get 。接着继续执行到第 38 行的 dispatch 方法,而这个 dispatch 方法实际上是 rest_framework.views.APIView.dispatch 方法,查看源码:
rest_framework.views.APIView.dispatch1 class APIView(View): 2 def dispatch(self, request, *args, **kwargs): 3 self.args = args 4 self.kwargs = kwargs 5 request = self.initialize_request(request, *args, **kwargs) 6 self.request = request 7 self.headers = self.default_response_headers # deprecate? 8 9 try: 10 self.initial(request, *args, **kwargs) 11 12 if request.method.lower() in self.http_method_names: 13 handler = getattr(self, request.method.lower(), 14 self.http_method_not_allowed) 15 else: 16 handler = self.http_method_not_allowed 17 18 response = handler(request, *args, **kwargs) 19 20 except Exception as exc: 21 response = self.handle_exception(exc) 22 23 self.response = self.finalize_response(request, response, *args, **kwargs) 24 return self.response
这次执行到 13 行时,如果请求方式是GET,通过反射从当前实例拿到请求方法名小写后的同名函数也就是 self.get 方法执行。而在之前 self.get 已经指向了 rest_framework.mixins.ListModelMixin.list 方法,所以实际上执行的就是这个 list 方法,其它请求方式以此类推。
认证&权限&频率组件
下面将详细描述认证组件的使用和源码,权限和频率组件的使用与源码与之类似。
认证组件
-
局部视图认证
例:from rest_framework import generics, viewsets, serializers from rest_framework.authentication import BaseAuthentication from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" # 定义认证类1 class AuthorAuthentication1(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication1') # 定义认证类2 class AuthorAuthentication2(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication2') class AuthorViewSet(viewsets.ModelViewSet): # 将要使用的认证类注册到authentication_classes变量中 authentication_classes = [AuthorAuthentication1, AuthorAuthentication2] queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from AuthorAuthentication1 from AuthorAuthentication2 '''
完成上述代码的编写后,此时访问该视图时,就会先执行所注册的认证类中的 authenticate 方法。如果有多个认证类,执行的顺序是按注册的顺序从左到右。当一个认证类的 authenticate 方法返回一个元组时,后续的认证类就不会继续执行,如下:
例:from rest_framework import generics, viewsets, serializers from rest_framework.authentication import BaseAuthentication from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" # 定义认证类1 class AuthorAuthentication1(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication1') return 'zze','token' # 定义认证类2 class AuthorAuthentication2(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication2') class AuthorViewSet(viewsets.ModelViewSet): # 将要使用的认证类注册到authentication_classes变量中 authentication_classes = [AuthorAuthentication1, AuthorAuthentication2] queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from AuthorAuthentication1 '''
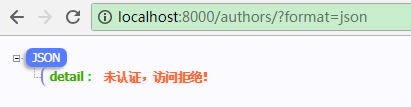
如果想中断认证类的执行并返回错误消息,可以抛出 rest_framework.exceptions.APIException 异常。
例:from rest_framework import generics, viewsets, serializers, exceptions from rest_framework.authentication import BaseAuthentication from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" # 定义认证类1 class AuthorAuthentication1(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication1') raise exceptions.NotAuthenticated(detail='未认证,访问拒绝!') return 'zze','token' # 定义认证类2 class AuthorAuthentication2(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication2') class AuthorViewSet(viewsets.ModelViewSet): # 将要使用的认证类注册到authentication_classes变量中 authentication_classes = [AuthorAuthentication1, AuthorAuthentication2] queryset = Author.objects.all() serializer_class = AuthorModelSerializer
- 步骤:
- 1、定义认证类,继承 rest_framework.authentication.BaseAuthentication ,重写 authenticate 方法,在该方法中编写认证逻辑。
- 2、将定义好的认证类注册到视图类的 authentication_classes 属性中(注意:此时的视图类必须继承 rest_framework.views.APIView )。
-
全局视图认证
编写认证类:
/[app name]/authentications.pyfrom rest_framework.authentication import BaseAuthentication # 定义认证类1 class AuthorAuthentication1(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication1') # 定义认证类2 class AuthorAuthentication2(BaseAuthentication): def authenticate(self, request): print('from AuthorAuthentication2')
然后只需要将认证类注册到 settings.py 的 REST_FRAMEWORK 节下,视图不用作任何修改:
settings.pyREST_FRAMEWORK = { "DEFAULT_AUTHENTICATION_CLASSES": [ "test_app.authentications.AuthorAuthentication1", "test_app.authentications.AuthorAuthentication2" ] }
视图from rest_framework import generics, viewsets, serializers, exceptions from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from AuthorAuthentication1 from AuthorAuthentication2 '''
注意:如果在视图中重写了 authentication_classes 属性,在该视图中全局认证将不起作用。
权限组件
-
局部视图权限
例:from rest_framework import generics, viewsets, serializers, exceptions from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class Permission1(): def has_permission(self, request, view): # 返回True:通过 False:中断 print('from Permission1') return False class Permission2(): def has_permission(self, request, view): print('from Permission2') return False class AuthorViewSet(viewsets.ModelViewSet): permission_classes = [Permission1, Permission2] queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from from Permission1 '''
-
全局视图权限
/[app name]/permissions.pyclass Permission1(): def has_permission(self, request, view): # 返回True:通过 False:中断 print('from Permission1') return False class Permission2(): def has_permission(self, request, view): print('from Permission2') return False
settings.pyREST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES':[ 'test_app.permissions.Permission1', 'test_app.permissions.Permission2' ] }
视图from rest_framework import generics, viewsets, serializers, exceptions from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from from Permission1 '''
频率组件
-
局部视图频率
例:from rest_framework import generics, viewsets, serializers, exceptions from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class Throttle1: def allow_request(self,request,view): print('from Throttle1') return True class Throttle2: def allow_request(self,request,view): print('from Throttle2') return True class AuthorViewSet(viewsets.ModelViewSet): throttle_classes = [Throttle1,Throttle2] queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from Throttle1 from Throttle2 '''
-
全局视图频率
/[app name]/thorttlesclass Throttle1: def allow_request(self, request, view): print('from Throttle1') return True class Throttle2: def allow_request(self, request, view): print('from Throttle2') return True
settings.pyREST_FRAMEWORK = { 'DEFAULT_THROTTLE_CLASSES' :[ 'test_app.thorttles.Throttle1', 'test_app.thorttles.Throttle2' ] }
视图from rest_framework import generics, viewsets, serializers, exceptions from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer ''' result: from Throttle1 from Throttle2 '''
源码
直接从 rest_framework.views.APIView.dispatch 方法看起:
1 def dispatch(self, request, *args, **kwargs): 2 self.args = args 3 self.kwargs = kwargs 4 request = self.initialize_request(request, *args, **kwargs) 5 self.request = request 6 self.headers = self.default_response_headers 7 8 try: 9 self.initial(request, *args, **kwargs) 10 11 if request.method.lower() in self.http_method_names: 12 handler = getattr(self, request.method.lower(), 13 self.http_method_not_allowed) 14 else: 15 handler = self.http_method_not_allowed 16 17 response = handler(request, *args, **kwargs) 18 19 except Exception as exc: 20 response = self.handle_exception(exc) 21 22 self.response = self.finalize_response(request, response, *args, **kwargs) 23 return self.response
看第 9 行,进到 initial 方法:
1 def initial(self, request, *args, **kwargs): 2 self.format_kwarg = self.get_format_suffix(**kwargs) 3 4 neg = self.perform_content_negotiation(request) 5 request.accepted_renderer, request.accepted_media_type = neg 6 7 version, scheme = self.determine_version(request, *args, **kwargs) 8 request.version, request.versioning_scheme = version, scheme 9 10 self.perform_authentication(request) 11 self.check_permissions(request) 12 self.check_throttles(request)
第 10 行的 perform_authentication 方法其实就是帮我们做认证的方法,进去看一下:
def perform_authentication(self, request): request.user
我们看到,它很简单,就是返回了 request 的一个名为 user 的属性,而这个 request 实际上就是在 rest_framework.views.APIView.dispatch 方法中第 4 行的 request ,而这个 request 我们之前就看过,它实际上就是将原生 request 包装后返回的 rest_framework.request.Request 类的实例,在该类中找到属性 user :
1 @property 2 def user(self): 3 if not hasattr(self, '_user'): 4 with wrap_attributeerrors(): 5 self._authenticate() 6 return self._user
再进到第 5 行的 _authenticate 方法中:
1 def _authenticate(self): 2 for authenticator in self.authenticators: 3 try: 4 user_auth_tuple = authenticator.authenticate(self) 5 except exceptions.APIException: 6 self._not_authenticated() 7 raise 8 9 if user_auth_tuple is not None: 10 self._authenticator = authenticator 11 self.user, self.auth = user_auth_tuple 12 return
看第 2 行在遍历一个 authenticators 属性,而这个 authenticators 实际上就是在创建 rest_framework.request.Request 实例时传入的一个参数,如下:
1 def initialize_request(self, request, *args, **kwargs): 2 parser_context = self.get_parser_context(request) 3 4 return Request( 5 request, 6 parsers=self.get_parsers(), 7 authenticators=self.get_authenticators(), 8 negotiator=self.get_content_negotiator(), 9 parser_context=parser_context 10 )
也就是第 7 行, authenticators 实际上是 get_authenticators 方法的返回值,进到方法中:
1 def get_authenticators(self): 2 return [auth() for auth in self.authentication_classes]
看到这里有种恍然大悟的感觉,我们自己写的视图类是继承了 rest_framework.views.APIView 类的,而第二行的 self.authentication_classes 实际上拿到的就是我们自己在视图类中定义的认证类列表了,返回值是这些认证类的实例列表。再回到上面 rest_framework.request.Request._authenticate 方法中,此时我们就知道,第 2 行遍历的实际上就是我们自己定义的认证类的实例。而在第 4 行执行每个实例的 authenticate 方法了,这也是我们定义的认证类要重写 authenticate 方法的原因。而在第 9-12 行可以看到,如果 authenticate 方法返回了元组,那么执行 11 行将返回的信息保存到 request (当前请求对象)的 user 和 auth 属性中,并且在 12 行 return ,也就是说后续的认证类就不再继续遍历了,也就不继续执行了。说到这里,上述也就是对局部视图原理作了解释,而全局视图呢?通过上面的使用我们知道,使用全局视图时我们不需要在视图类中指定认证类列表,那这个时候上面 rest_framework.views.APIView.get_authenticators 方法中 self.authentication_classes 拿到的是什么?
1 class APIView(View): 2 3 renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES 4 parser_classes = api_settings.DEFAULT_PARSER_CLASSES 5 authentication_classes = api_settings.DEFAULT_AUTHENTICATION_CLASSES 6 throttle_classes = api_settings.DEFAULT_THROTTLE_CLASSES 7 permission_classes = api_settings.DEFAULT_PERMISSION_CLASSES 8 content_negotiation_class = api_settings.DEFAULT_CONTENT_NEGOTIATION_CLASS 9 metadata_class = api_settings.DEFAULT_METADATA_CLASS 10 versioning_class = api_settings.DEFAULT_VERSIONING_CLASS
通过查看我们会发现,在 rest_framework.views.APIView 类中其实已经有一个默认的 authentication_classes 属性,且有一个为 api_settings.DEFAULT_AUTHENTICATION_CLASSES 的默认值。查看 api_settings :
1 api_settings = APISettings(None, DEFAULTS, IMPORT_STRINGS)
可以看到 api_settings 又是 APISettings 的实例,查看 APISettings :
1 class APISettings(object): 2 def __init__(self, user_settings=None, defaults=None, import_strings=None): 3 if user_settings: 4 self._user_settings = self.__check_user_settings(user_settings) 5 self.defaults = defaults or DEFAULTS 6 self.import_strings = import_strings or IMPORT_STRINGS 7 self._cached_attrs = set() 8 9 @property 10 def user_settings(self): 11 if not hasattr(self, '_user_settings'): 12 self._user_settings = getattr(settings, 'REST_FRAMEWORK', {}) 13 return self._user_settings 14 15 def __getattr__(self, attr): 16 if attr not in self.defaults: 17 raise AttributeError("Invalid API setting: '%s'" % attr) 18 19 try: 20 val = self.user_settings[attr] 21 except KeyError: 22 val = self.defaults[attr] 23 24 if attr in self.import_strings: 25 val = perform_import(val, attr) 26 27 self._cached_attrs.add(attr) 28 setattr(self, attr, val) 29 return val
在 rest_framework.views.APIView 中,我们看到它从 APISettings 的实例中取一个名为 DEFAULT_AUTHENTICATION_CLASSES 的属性,但在该类中并没有这个属性,而我们看到了 15 行的 __getattr__ 方法。首先我们要知道一个类的 __getattr__ 方法是在访问一个该类不存在的属性时调用的,而访问的这个属性名将会作为参数传入,也就是 15 行的 attr 参数。看到第 20 行,它在从 user_settings 中取一个键为 attr 变量值对应的值,而此时 attr 的值就是 DEFAULT_AUTHENTICATION_CLASSES 。再看到 user_settings ,也就是对应第 10 行的 user_settings 属性,从 12 行可以看到,它是通过返回从 settings 中取一个名为 REST_FRAMEWORK 的变量,而这个 settings 其实就是我们自己项目中的 settings.py ,如果我们在其中定义了 REST_FRAMEWORK 变量,且存在名为 DEFAULT_AUTHENTICATION_CLASSES 的键,将取到该键对应的值,也就是我们定义的认证类路径列表,并在 25 行返回路径对应认证类实例列表。而如果不存在该键,也就执行到 22 行,从 defaults 中取该键,而 defaults 就是在上面 rest_framework.settings 中创建 APISettings 实例时和 IMPORT_STRINGS 一起传入的,附上 defaults 和 IMPORT_STRINGS :
1 DEFAULTS = { 2 # Base API policies 3 'DEFAULT_RENDERER_CLASSES': ( 4 'rest_framework.renderers.JSONRenderer', 5 'rest_framework.renderers.BrowsableAPIRenderer', 6 ), 7 'DEFAULT_PARSER_CLASSES': ( 8 'rest_framework.parsers.JSONParser', 9 'rest_framework.parsers.FormParser', 10 'rest_framework.parsers.MultiPartParser' 11 ), 12 'DEFAULT_AUTHENTICATION_CLASSES': ( 13 'rest_framework.authentication.SessionAuthentication', 14 'rest_framework.authentication.BasicAuthentication' 15 ), 16 'DEFAULT_PERMISSION_CLASSES': ( 17 'rest_framework.permissions.AllowAny', 18 ), 19 'DEFAULT_THROTTLE_CLASSES': (), 20 'DEFAULT_CONTENT_NEGOTIATION_CLASS': 'rest_framework.negotiation.DefaultContentNegotiation', 21 'DEFAULT_METADATA_CLASS': 'rest_framework.metadata.SimpleMetadata', 22 'DEFAULT_VERSIONING_CLASS': None, 23 24 # Generic view behavior 25 'DEFAULT_PAGINATION_CLASS': None, 26 'DEFAULT_FILTER_BACKENDS': (), 27 28 # Schema 29 'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.AutoSchema', 30 31 # Throttling 32 'DEFAULT_THROTTLE_RATES': { 33 'user': None, 34 'anon': None, 35 }, 36 'NUM_PROXIES': None, 37 38 # Pagination 39 'PAGE_SIZE': None, 40 41 # Filtering 42 'SEARCH_PARAM': 'search', 43 'ORDERING_PARAM': 'ordering', 44 45 # Versioning 46 'DEFAULT_VERSION': None, 47 'ALLOWED_VERSIONS': None, 48 'VERSION_PARAM': 'version', 49 50 # Authentication 51 'UNAUTHENTICATED_USER': 'django.contrib.auth.models.AnonymousUser', 52 'UNAUTHENTICATED_TOKEN': None, 53 54 # View configuration 55 'VIEW_NAME_FUNCTION': 'rest_framework.views.get_view_name', 56 'VIEW_DESCRIPTION_FUNCTION': 'rest_framework.views.get_view_description', 57 58 # Exception handling 59 'EXCEPTION_HANDLER': 'rest_framework.views.exception_handler', 60 'NON_FIELD_ERRORS_KEY': 'non_field_errors', 61 62 # Testing 63 'TEST_REQUEST_RENDERER_CLASSES': ( 64 'rest_framework.renderers.MultiPartRenderer', 65 'rest_framework.renderers.JSONRenderer' 66 ), 67 'TEST_REQUEST_DEFAULT_FORMAT': 'multipart', 68 69 # Hyperlink settings 70 'URL_FORMAT_OVERRIDE': 'format', 71 'FORMAT_SUFFIX_KWARG': 'format', 72 'URL_FIELD_NAME': 'url', 73 74 # Input and output formats 75 'DATE_FORMAT': ISO_8601, 76 'DATE_INPUT_FORMATS': (ISO_8601,), 77 78 'DATETIME_FORMAT': ISO_8601, 79 'DATETIME_INPUT_FORMATS': (ISO_8601,), 80 81 'TIME_FORMAT': ISO_8601, 82 'TIME_INPUT_FORMATS': (ISO_8601,), 83 84 # Encoding 85 'UNICODE_JSON': True, 86 'COMPACT_JSON': True, 87 'STRICT_JSON': True, 88 'COERCE_DECIMAL_TO_STRING': True, 89 'UPLOADED_FILES_USE_URL': True, 90 91 # Browseable API 92 'HTML_SELECT_CUTOFF': 1000, 93 'HTML_SELECT_CUTOFF_TEXT': "More than {count} items...", 94 95 # Schemas 96 'SCHEMA_COERCE_PATH_PK': True, 97 'SCHEMA_COERCE_METHOD_NAMES': { 98 'retrieve': 'read', 99 'destroy': 'delete' 100 }, 101 } 102 103 104 # List of settings that may be in string import notation. 105 IMPORT_STRINGS = ( 106 'DEFAULT_RENDERER_CLASSES', 107 'DEFAULT_PARSER_CLASSES', 108 'DEFAULT_AUTHENTICATION_CLASSES', 109 'DEFAULT_PERMISSION_CLASSES', 110 'DEFAULT_THROTTLE_CLASSES', 111 'DEFAULT_CONTENT_NEGOTIATION_CLASS', 112 'DEFAULT_METADATA_CLASS', 113 'DEFAULT_VERSIONING_CLASS', 114 'DEFAULT_PAGINATION_CLASS', 115 'DEFAULT_FILTER_BACKENDS', 116 'DEFAULT_SCHEMA_CLASS', 117 'EXCEPTION_HANDLER', 118 'TEST_REQUEST_RENDERER_CLASSES', 119 'UNAUTHENTICATED_USER', 120 'UNAUTHENTICATED_TOKEN', 121 'VIEW_NAME_FUNCTION', 122 'VIEW_DESCRIPTION_FUNCTION' 123 )
可以看到,默认认证类正是我们自己定义认证类时继承的那个类,而这个类什么都没做,如下:
1 class BaseAuthentication(object): 2 3 def authenticate(self, request): 4 raise NotImplementedError(".authenticate() must be overridden.") 5 6 def authenticate_header(self, request): 7 pass
返回认证类实例列表在 rest_framework.views.APIView.get_authenticators 方法中接收到,之后就可以按上述局部视图后续一样执行了。
在权限和频率组件中我没有做很详细的描述,那是因为它们的实现和认证组件大致相同,包括使用方式。
解析器
解析器的使用其实和上面的认证、权限、频率组件相似。 rest_framework 给我们提供了一些解析器,如下:
1 from __future__ import unicode_literals 2 3 import codecs 4 5 from django.conf import settings 6 from django.core.files.uploadhandler import StopFutureHandlers 7 from django.http import QueryDict 8 from django.http.multipartparser import ChunkIter 9 from django.http.multipartparser import \ 10 MultiPartParser as DjangoMultiPartParser 11 from django.http.multipartparser import MultiPartParserError, parse_header 12 from django.utils import six 13 from django.utils.encoding import force_text 14 from django.utils.six.moves.urllib import parse as urlparse 15 16 from rest_framework import renderers 17 from rest_framework.exceptions import ParseError 18 from rest_framework.settings import api_settings 19 from rest_framework.utils import json 20 21 22 class DataAndFiles(object): 23 def __init__(self, data, files): 24 self.data = data 25 self.files = files 26 27 28 class BaseParser(object): 29 media_type = None 30 31 def parse(self, stream, media_type=None, parser_context=None): 32 raise NotImplementedError(".parse() must be overridden.") 33 34 35 class JSONParser(BaseParser): 36 media_type = 'application/json' 37 renderer_class = renderers.JSONRenderer 38 strict = api_settings.STRICT_JSON 39 40 def parse(self, stream, media_type=None, parser_context=None): 41 parser_context = parser_context or {} 42 encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) 43 44 try: 45 decoded_stream = codecs.getreader(encoding)(stream) 46 parse_constant = json.strict_constant if self.strict else None 47 return json.load(decoded_stream, parse_constant=parse_constant) 48 except ValueError as exc: 49 raise ParseError('JSON parse error - %s' % six.text_type(exc)) 50 51 52 class FormParser(BaseParser): 53 media_type = 'application/x-www-form-urlencoded' 54 55 def parse(self, stream, media_type=None, parser_context=None): 56 parser_context = parser_context or {} 57 encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) 58 data = QueryDict(stream.read(), encoding=encoding) 59 return data 60 61 62 class MultiPartParser(BaseParser): 63 media_type = 'multipart/form-data' 64 65 def parse(self, stream, media_type=None, parser_context=None): 66 parser_context = parser_context or {} 67 request = parser_context['request'] 68 encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) 69 meta = request.META.copy() 70 meta['CONTENT_TYPE'] = media_type 71 upload_handlers = request.upload_handlers 72 73 try: 74 parser = DjangoMultiPartParser(meta, stream, upload_handlers, encoding) 75 data, files = parser.parse() 76 return DataAndFiles(data, files) 77 except MultiPartParserError as exc: 78 raise ParseError('Multipart form parse error - %s' % six.text_type(exc)) 79 80 81 class FileUploadParser(BaseParser): 82 media_type = '*/*' 83 errors = { 84 'unhandled': 'FileUpload parse error - none of upload handlers can handle the stream', 85 'no_filename': 'Missing filename. Request should include a Content-Disposition header with a filename parameter.', 86 } 87 88 def parse(self, stream, media_type=None, parser_context=None): 89 parser_context = parser_context or {} 90 request = parser_context['request'] 91 encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET) 92 meta = request.META 93 upload_handlers = request.upload_handlers 94 filename = self.get_filename(stream, media_type, parser_context) 95 96 if not filename: 97 raise ParseError(self.errors['no_filename']) 98 content_type = meta.get('HTTP_CONTENT_TYPE', 99 meta.get('CONTENT_TYPE', '')) 100 try: 101 content_length = int(meta.get('HTTP_CONTENT_LENGTH', 102 meta.get('CONTENT_LENGTH', 0))) 103 except (ValueError, TypeError): 104 content_length = None 105 106 # See if the handler will want to take care of the parsing. 107 for handler in upload_handlers: 108 result = handler.handle_raw_input(stream, 109 meta, 110 content_length, 111 None, 112 encoding) 113 if result is not None: 114 return DataAndFiles({}, {'file': result[1]}) 115 116 possible_sizes = [x.chunk_size for x in upload_handlers if x.chunk_size] 117 chunk_size = min([2 ** 31 - 4] + possible_sizes) 118 chunks = ChunkIter(stream, chunk_size) 119 counters = [0] * len(upload_handlers) 120 121 for index, handler in enumerate(upload_handlers): 122 try: 123 handler.new_file(None, filename, content_type, 124 content_length, encoding) 125 except StopFutureHandlers: 126 upload_handlers = upload_handlers[:index + 1] 127 break 128 129 for chunk in chunks: 130 for index, handler in enumerate(upload_handlers): 131 chunk_length = len(chunk) 132 chunk = handler.receive_data_chunk(chunk, counters[index]) 133 counters[index] += chunk_length 134 if chunk is None: 135 break 136 137 for index, handler in enumerate(upload_handlers): 138 file_obj = handler.file_complete(counters[index]) 139 if file_obj is not None: 140 return DataAndFiles({}, {'file': file_obj}) 141 142 raise ParseError(self.errors['unhandled']) 143 144 def get_filename(self, stream, media_type, parser_context): 145 try: 146 return parser_context['kwargs']['filename'] 147 except KeyError: 148 pass 149 150 try: 151 meta = parser_context['request'].META 152 disposition = parse_header(meta['HTTP_CONTENT_DISPOSITION'].encode('utf-8')) 153 filename_parm = disposition[1] 154 if 'filename*' in filename_parm: 155 return self.get_encoded_filename(filename_parm) 156 return force_text(filename_parm['filename']) 157 except (AttributeError, KeyError, ValueError): 158 pass 159 160 def get_encoded_filename(self, filename_parm): 161 encoded_filename = force_text(filename_parm['filename*']) 162 try: 163 charset, lang, filename = encoded_filename.split('\'', 2) 164 filename = urlparse.unquote(filename) 165 except (ValueError, LookupError): 166 filename = force_text(filename_parm['filename']) 167 return filename
而默认生效的以下三个:
'DEFAULT_PARSER_CLASSES': ( 'rest_framework.parsers.JSONParser', 'rest_framework.parsers.FormParser', 'rest_framework.parsers.MultiPartParser' )
局部视图解析
from rest_framework import generics, viewsets, serializers, exceptions from app01.models import * from rest_framework import parsers class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): parser_classes = [parsers.JSONParser, parsers.FormParser, parsers.MultiPartParser, parsers.FileUploadParser] queryset = Author.objects.all() serializer_class = AuthorModelSerializer
全局视图解析
REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES': ( 'rest_framework.parsers.JSONParser', 'rest_framework.parsers.FormParser', 'rest_framework.parsers.MultiPartParser', 'rest_framework.parsers.FileUploadParser' ) }
from rest_framework import generics, viewsets, serializers, exceptions from app01.models import * from rest_framework import parsers class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer
分页
普通分页
配置全局每页条数:
REST_FRAMEWORK = { 'PAGE_SIZE':2 }
from rest_framework import generics, viewsets, serializers from rest_framework.pagination import PageNumberPagination from rest_framework.response import Response from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer def list(self, request, *args, **kwargs): pnp = PageNumberPagination() page_result = pnp.paginate_queryset(AuthorViewSet.queryset, request, self) bs = AuthorModelSerializer(page_result, many=True) return Response(bs.data)
针对局部视图分页:
from rest_framework.pagination import PageNumberPagination from rest_framework.response import Response from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class PNPagination(PageNumberPagination): page_size = 1 # 每页数据条数 page_query_param = 'page' # 请求时页码参数名 page_size_query_param = "size" # 临时指定每页数据条数 max_page_size = 5 # 临时指定每页数据条数最大值 class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer def list(self, request, *args, **kwargs): pnp = PNPagination() page_result = pnp.paginate_queryset(AuthorViewSet.queryset, request, self) bs = AuthorModelSerializer(page_result, many=True) return Response(bs.data)
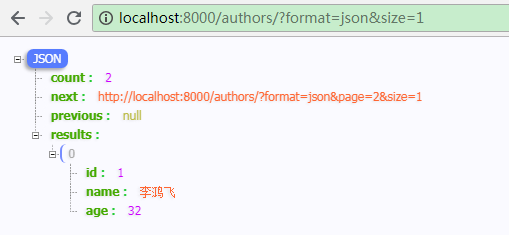
rest_framework 为简易使用进行了进一步的封装:
from rest_framework import generics, viewsets, serializers from rest_framework.pagination import PageNumberPagination from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class PNPagination(PageNumberPagination): page_size = 1 # 每页数据条数 page_query_param = 'page' # 请求时页码参数名 page_size_query_param = "size" # 临时指定每页数据条数 max_page_size = 5 # 临时指定每页数据条数最大值 class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer pagination_class = PNPagination
偏移分页
from rest_framework import generics, viewsets, serializers from rest_framework.pagination import LimitOffsetPagination from test_app.models import * class AuthorModelSerializer(serializers.ModelSerializer): class Meta: model = Author fields = "__all__" class LOPagination(LimitOffsetPagination): limit_query_param = 'limit' # 每页条数 offset_query_param = 'offset' # 偏移条数 class AuthorViewSet(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializer pagination_class = LOPagination

渲染器
当我们用浏览器访问接口时,会发现返回的内容被包装美化了,如下:
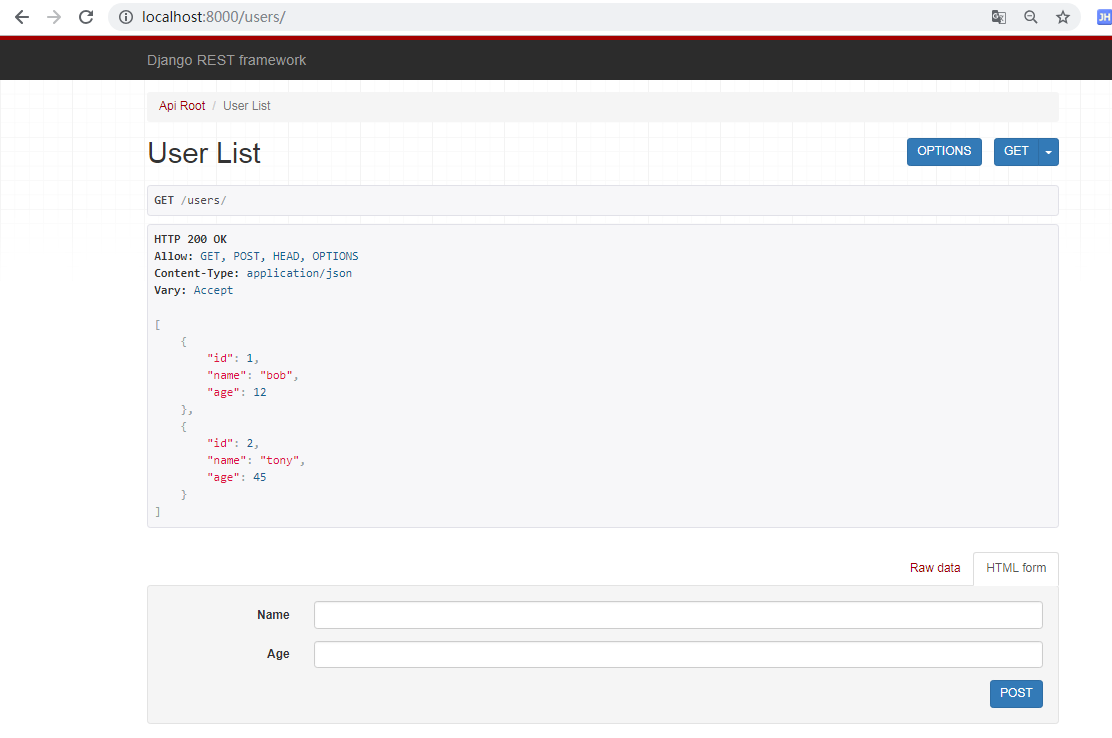
这个其实就是渲染器的作用,下面补充说明渲染器的相关配置。
局部视图渲染
from api.models import * from rest_framework import viewsets, serializers from rest_framework import renderers class UserModelSerializer(serializers.ModelSerializer): class Meta: model = User fields = "__all__" class UserViewSet(viewsets.ModelViewSet): renderer_classes = [renderers.JSONRenderer] queryset = User.objects.all() serializer_class = UserModelSerializer
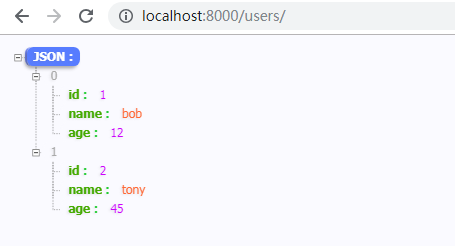
全局视图渲染
REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': ['rest_framework.renderers.JSONRenderer', ] }
from api.models import * from rest_framework import viewsets, serializers from rest_framework import renderers class UserModelSerializer(serializers.ModelSerializer): class Meta: model = User fields = "__all__" class UserViewSet(viewsets.ModelViewSet): queryset = User.objects.all() serializer_class = UserModelSerializer
rest_framework 默认使用的渲染器如下:
'DEFAULT_RENDERER_CLASSES': ( 'rest_framework.renderers.JSONRenderer', 'rest_framework.renderers.BrowsableAPIRenderer', ),
版本控制
局部视图版本控制
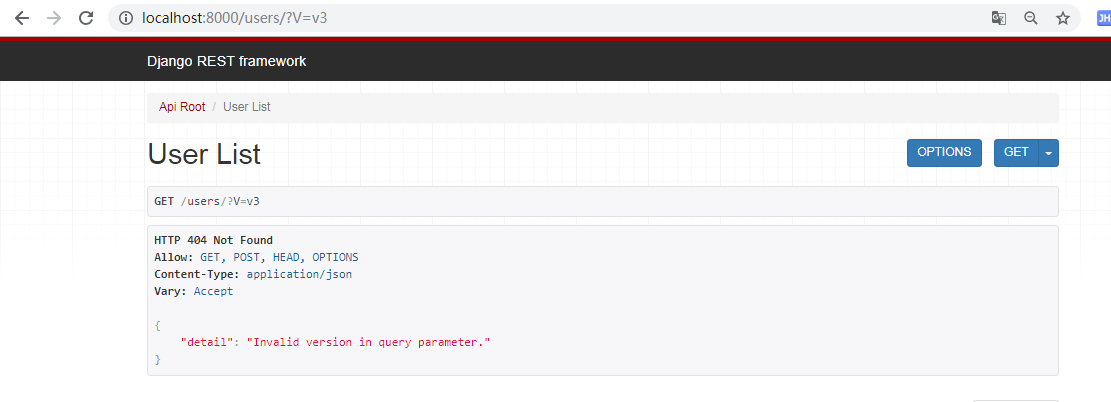
REST_FRAMEWORK = { 'ALLOWED_VERSIONS': ['v1', 'v2'], # 配置允许的版本 'VERSION_PARAM': 'V', # 版本参数名 默认为 version }
from api.models import * from rest_framework import viewsets, serializers from rest_framework import versioning class UserModelSerializer(serializers.ModelSerializer): class Meta: model = User fields = "__all__" class UserViewSet(viewsets.ModelViewSet): versioning_class = versioning.QueryParameterVersioning queryset = User.objects.all() serializer_class = UserModelSerializer
from api.models import * from rest_framework import viewsets, serializers from rest_framework import versioning class UserModelSerializer(serializers.ModelSerializer): class Meta: model = User fields = "__all__" class UserViewSet(viewsets.ModelViewSet): versioning_class =versioning.URLPathVersioning queryset = User.objects.all() serializer_class = UserModelSerializer
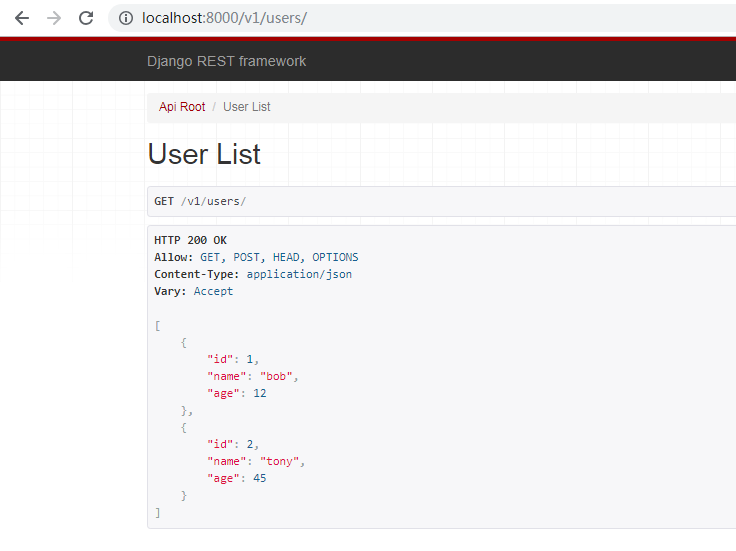
注意,使用路径版本控制的时候需要修改路由(下面的全局视图也需要),如下:
from django.conf.urls import url,include from rest_framework import routers from api import views router = routers.DefaultRouter() router.register('(?P<V>\w+)/users', views.UserViewSet) # V 对应配置中的 VERSION_PARAM urlpatterns = [ url(r'', include(router.urls)), ]
全局视图版本控制
REST_FRAMEWORK = { 'ALLOWED_VERSIONS': ['v1', 'v2'], # 配置允许的版本 'VERSION_PARAM': 'V', # 版本参数名 默认为 version 'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning' # 版本控制类 # rest_framework.versioning.QueryParameterVersioning 参数版本控制 }
from api.models import * from rest_framework import viewsets, serializers class UserModelSerializer(serializers.ModelSerializer): class Meta: model = User fields = "__all__" class UserViewSet(viewsets.ModelViewSet): queryset = User.objects.all() serializer_class = UserModelSerializer
补充
request.META
通过 rest_framework 提供的 rest_framework.request.Request 实例下的 META 可以拿到很多请求信息,例如:
{ 'ALLUSERSPROFILE': 'C:\\ProgramData', 'AMDAPPSDKROOT': 'C:\\Program Files (x86)\\AMD APP\\', 'ANDROID_SWT': 'C:\\Users\\joyceyang\\AppData\\Local\\Android\\Sdk\\tools\\lib\\monitor-x86_64', 'APPDATA': 'C:\\Users\\joyceyang\\AppData\\Roaming', 'APPIUM_HOME': 'C:\\Users\\joyceyang\\AppData\\Local\\Programs\\appium-desktop', 'CLASSPATH': '.;F:\\Java\\jdk1.8.0_144\\lib\\dt.jar;F:\\Java\\jdk1.8.0_144\\lib\\tools.jar;', 'COMMONPROGRAMFILES': 'C:\\Program Files\\Common Files', 'COMMONPROGRAMFILES(X86)': 'C:\\Program Files (x86)\\Common Files', 'COMMONPROGRAMW6432': 'C:\\Program Files\\Common Files', 'COMPUTERNAME': 'ZHANGZHONGEN', 'COMSPEC': 'C:\\Windows\\system32\\cmd.exe', 'DJANGO_SETTINGS_MODULE': 'django_test.settings', 'FP_NO_HOST_CHECK': 'NO', 'HOMEDRIVE': 'C:', 'HOMEPATH': '\\Users\\joyceyang', 'JAVA_HOME': 'F:\\Java\\jdk1.8.0_144', 'JMETER_HOME': 'F:\\jmeter\\apache-jmeter-3.0', 'LOCALAPPDATA': 'C:\\Users\\joyceyang\\AppData\\Local', 'LOGONSERVER': '\\\\ZHANGZHONGEN', 'MOZ_PLUGIN_PATH': 'C:\\Program Files (x86)\\Foxit Software\\Foxit Reader\\plugins\\', 'NUMBER_OF_PROCESSORS': '4', 'OS': 'Windows_NT', 'PATH': 'C:\\Users\\joyceyang\\AppData\\Local\\Programs\\Python\\Python37\\Scripts\\;C:\\Users\\joyceyang\\AppData\\Local\\Programs\\Python\\Python37\\;C:\\Program Files\\Python36\\Scripts\\;C:\\Program Files\\Python36\\;C:\\ProgramData\\Oracle\\Java\\javapath;F:\\Java\\jdk1.8.0_144\\bin;F:\\Java\\jdk1.8.0_144\\jre\\bin;F:\\Python35\\Scripts\\;F:\\Python35\\;C:\\Program Files (x86)\\AMD APP\\bin\\x86_64;C:\\Program Files (x86)\\AMD APP\\bin\\x86;C:\\Windows\\system32;C:\\Windows;C:\\Windows\\System32\\Wbem;C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\;C:\\Program Files (x86)\\ATI Technologies\\ATI.ACE\\Core-Static;F:\\Python36\\chromedriver_win32.exe;F:\\Python36\\chromedriver;F:\\Python36\\IEDriverServer_x64_3.3.0;C:\\Program Files (x86)\\Mozilla Firefox;F:\\Python36\\geckodriver-v0.14.0-win64\\geckodriver;C:\\Program Files (x86)\\Microsoft SQL Server\\100\\Tools\\Binn\\;C:\\Program Files\\Microsoft SQL Server\\100\\Tools\\Binn\\;C:\\Program Files\\Microsoft SQL Server\\100\\DTS\\Binn\\;C:\\Program Files (x86)\\Microsoft SQL Server\\100\\Tools\\Binn\\VSShell\\Common7\\IDE\\;C:\\Program Files (x86)\\Microsoft SQL Server\\100\\DTS\\Binn\\;C:\\Program Files (x86)\\Microsoft Visual Studio 9.0\\Common7\\IDE\\PrivateAssemblies\\;F:\\Python36\\geckodriver-v0.15.0-win64\\geckodriver.exe;F:\\Python36\\geckodriver-v0.15.0-win32\\geckodriver.exe;F:\\Python36\\selenium\\webdriver\\firefox;C:\\Users\\joyceyang\\PycharmProjects;F:\\Python36\\Lib\\site-packages\\selenium\\webdriver;F:\\PyCharm 2017.2;G:\\Python27;G:\\Python27\\Scripts;I:\\Program Files\\nodejs\\;C:\\Users\\joyceyang\\AppData\\Local\\Android\\Sdk\\tools;C:\\Users\\joyceyang\\AppData\\Local\\Android\\Sdk\\platform-tools;C:\\Users\\joyceyang\\AppData\\Local\\Programs\\appium-desktop\\node_modules\\.bin\\;F:\\Python35\\chromedriver.exe;F:\\Python35\\geckodriver.exe;C:\\Program Files\\Microsoft\\Web Platform Installer\\;C:\\Program Files (x86)\\Microsoft ASP.NET\\ASP.NET Web Pages\\v1.0\\;C:\\Program Files (x86)\\Windows Kits\\8.0\\Windows Performance Toolkit\\;C:\\Program Files\\Microsoft SQL Server\\110\\Tools\\Binn\\;F:\\Program Files\\python27;C:\\Program Files\\MySQL\\MySQL Server 5.6\\bin;C:\\Users\\joyceyang\\AppData\\Roaming\\npm;', 'PATHEXT': '.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH;.MSC;.PY;.PYW', 'PROCESSOR_ARCHITECTURE': 'AMD64', 'PROCESSOR_IDENTIFIER': 'Intel64 Family 6 Model 60 Stepping 3, GenuineIntel', 'PROCESSOR_LEVEL': '6', 'PROCESSOR_REVISION': '3c03', 'PROGRAMDATA': 'C:\\ProgramData', 'PROGRAMFILES': 'C:\\Program Files', 'PROGRAMFILES(X86)': 'C:\\Program Files (x86)', 'PROGRAMW6432': 'C:\\Program Files', 'PSMODULEPATH': 'C:\\Windows\\system32\\WindowsPowerShell\\v1.0\\Modules\\', 'PUBLIC': 'C:\\Users\\Public', 'PYCHARM_HOSTED': '1', 'PYCHARM_MATPLOTLIB_PORT': '1946', 'PYTHONIOENCODING': 'UTF-8', 'PYTHONPATH': 'C:\\Program Files\\JetBrains\\PyCharm 2018.2.1\\helpers\\pycharm_matplotlib_backend;E:\\learning\\python\\Django\\1112\\django_test', 'PYTHONUNBUFFERED': '1', 'SESSIONNAME': 'Console', 'SYSTEMDRIVE': 'C:', 'SYSTEMROOT': 'C:\\Windows', 'TEMP': 'C:\\Users\\JOYCEY~1\\AppData\\Local\\Temp', 'TMP': 'C:\\Users\\JOYCEY~1\\AppData\\Local\\Temp', 'USERDOMAIN': 'ZHANGZHONGEN', 'USERNAME': 'zze', 'USERPROFILE': 'C:\\Users\\joyceyang', 'VS110COMNTOOLS': 'C:\\Program Files (x86)\\Microsoft Visual Studio 11.0\\Common7\\Tools\\', 'WINDIR': 'C:\\Windows', 'WINDOWS_TRACING_FLAGS': '3', 'WINDOWS_TRACING_LOGFILE': 'C:\\BVTBin\\Tests\\installpackage\\csilogfile.log', 'RUN_MAIN': 'true', 'SERVER_NAME': 'ZHANGZHONGEN.te.local', 'GATEWAY_INTERFACE': 'CGI/1.1', 'SERVER_PORT': '8000', 'REMOTE_HOST': '', 'CONTENT_LENGTH': '', 'SCRIPT_NAME': '', 'SERVER_PROTOCOL': 'HTTP/1.1', 'SERVER_SOFTWARE': 'WSGIServer/0.2', 'REQUEST_METHOD': 'GET', 'PATH_INFO': '/authors/', 'QUERY_STRING': 'format=json', 'REMOTE_ADDR': '127.0.0.1', 'CONTENT_TYPE': 'text/plain', 'HTTP_HOST': 'localhost:8000', 'HTTP_CONNECTION': 'keep-alive', 'HTTP_CACHE_CONTROL': 'max-age=0', 'HTTP_UPGRADE_INSECURE_REQUESTS': '1', 'HTTP_USER_AGENT': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', 'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'HTTP_ACCEPT_ENCODING': 'gzip, deflate, br', 'HTTP_ACCEPT_LANGUAGE': 'zh-CN,zh;q=0.9', 'HTTP_COOKIE': '_gcl_au=1.1.1751777454.1538096424; _ga=GA1.1.976162796.1538096425; _pk_id.5.1fff=270301285dcb1afa.1538096424.20.1539314306.1539314283.; csrftoken=sAWJy3GqUFz9XzC5xNUbCdQEeuiUbW1Eq89BzrkliCKZxcNFfALIMChDvoMERqf9; _gid=GA1.1.414362598.1542248585', 'wsgi.input': <_io.BufferedReader name=716>, 'wsgi.errors': <_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>, 'wsgi.version': (1, 0), 'wsgi.run_once': False, 'wsgi.url_scheme': 'http', 'wsgi.multithread': True, 'wsgi.multiprocess': False, 'wsgi.file_wrapper': <class 'wsgiref.util.FileWrapper'> }
url控制
在之前使用 ModelViewSet 时是以以下方式配置 url :
from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^authors/$', views.AuthorViewSet.as_view({"get": "list", "post": "create"})), url(r'^authors/(?P<pk>\d+)/', views.AuthorViewSet.as_view({ 'get': 'retrieve', 'put': 'update', 'patch': 'partial_update', 'delete': 'destroy' })), ]
使用这种方式有一个很明显的弊端就是如果每增加一个视图就需要再配置两个 url ,而 rest_framework 给我们提供了简化操作的方式,如下:
from django.conf.urls import url, include from app01 import views from rest_framework import routers router = routers.DefaultRouter() router.register('authors', views.AuthorViewSet) urlpatterns = [ url(r'', include(router.urls)), ]
Java博客目录 | Python博客目录 | C#博客目录
