
Oracle(2)之多表查询&子查询&集合运算
多表查询
笛卡尔积
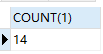
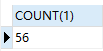
同时查询多张表时,每张表的每条数据都要和其它表的每条数据做组合。如下栗子,我们发现产生的总记录数是 56 条,还发现 emp 表是 14 条,dept 表是 4 条,56 条正是 emp 表和 dept 表的记录数的乘积,这就是笛卡尔积。


select count(1) from dept;

select count(1) from emp;
select count(1) from emp,dept;
连接条件类型
- 等值连接
- 不等值连接
- 外链接
- 自连接
多表基本查询
使用一张以上的表做查询就是多表查询,而多表查询一般则需要通过多表连接来实现。
如果多张表一起进行查询而且每张表的数据很大的话那么该查询的笛卡尔积就会变得非常大,对性能造成影响。而我们仅需要笛卡尔积中部分对我们有用的数据,这时我们可以使用关联查询。
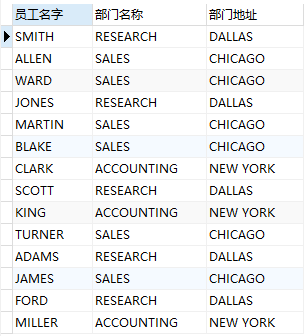
在 emp(员工) 表和 dept(部门) 表中我们会发现有一个共同的字段是 depno,depno 就是两张表关联的字段,用来描述一个员工属于哪个部门。我们可以使用这个字段来做限制条件。
两张表的关联查询字段一般一个是其中一张表的主键,另一个是另一张表的外键。
select e1.ename 员工名字,d1.dname 部门名称,d1.loc 部门地址 from dept d1,emp e1 where d1.deptno = e1.deptno;
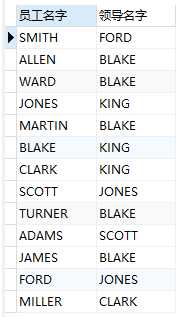
select e1.ename 员工名字,e2.ename 领导名字 from emp e1,emp e2 where e1.mgr=e2.empno;
select e1.ename 员工名字, d1.dname 所属部门名称, decode(s1.grade,1,'一级',2,'二级',3,'三级',4,'四级',5,'五级') 员工工资等级, e2.ename 领导名字, decode(s2.grade,1,'一级',2,'二级',3,'三级',4,'四级',5,'五级') 领导工资等级 from emp e1,dept d1,salgrade s1,emp e2,salgrade s2 where e1.deptno=d1.deptno and e1.sal between s1.losal and s1.hisal and e1.mgr=e2.empno and e2.sal between s2.losal and s2.hisal;
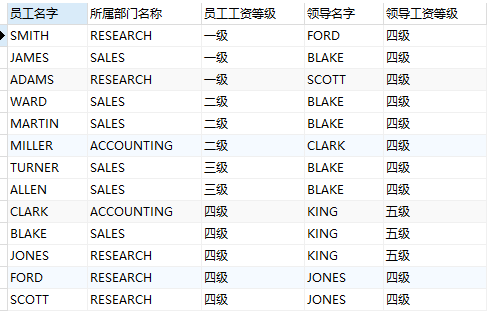
外连接
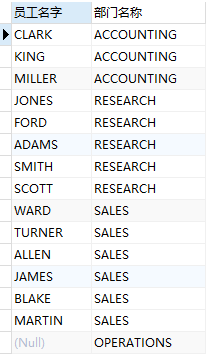
在上面‘查询出员工名字和其所属部门的名称、地址’示例中,其中有一个部门是没有员工的,可还是要求要把这个部门显示出来,这时就可以使用右连接:
-- 使用 + select e1.ename 员工名字,d1.dname 部门名称 from emp e1,dept d1 where e1.deptno(+)=d1.deptno; -- 使用 right join select e1.ename 员工名字,d1.dname 部门名称 from emp e1 right join dept d1 on e1.deptno=d1.deptno;
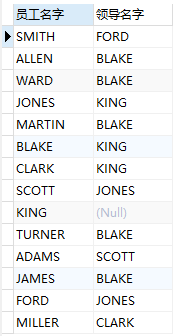
在上面‘查询出每个员工名字和该员工的领导名字’示例中,其中有一个员工是没有领导的,可还是要求将这个员工显示出来,这时就可以使用左连接:
-- 使用 + select e1.ename 员工名字,e2.ename 领导名字 from emp e1,emp e2 where e1.mgr=e2.empno(+); -- 使用 left join select e1.ename 员工名字,e2.ename 领导名字 from emp e1 left join emp e2 on e1.mgr=e2.empno;
注意:'+' 方式外连接是 Oracle 数据库独有的。
子查询
select e1.empno 员工编号, e1.ename 员工名字, e1.job 工作, e1.sal 工资 from emp e1 where e1.sal>(select sal from emp e2 where empno=7654) and e1.job=(select job from emp e3 where empno=7788)

select t_min.min_sal 最低工资, e1.ename 员工名称, d1.dname 部门名称 from dept d1, (select deptno,min(sal) min_sal from emp group by deptno) t_min, emp e1 where d1.deptno = t_min.deptno and e1.sal = t_min.min_sal

-- 查询有员工的部门 select * from dept d1 where exists (select * from emp e1 where d1.deptno=e1.deptno);
-- 查询员工 7788、7844 的领导信息 select * from emp where empno in(select mgr from emp where empno in (7788,7844));

-- 查询比部门编号为 20 的部门中的所有员工工资都高的员工 select * from emp e1 where e1.sal>all(select sal from emp e2 where e2.deptno=20);

-- 查询员工编号为 7844、7900 的员工 select * from emp e1 where e1.empno=any(7844,7900);

null 值问题:
例(not in):查询不是领导的员工
-- 查询是领导的员工 select * from emp where empno in (select mgr from emp);
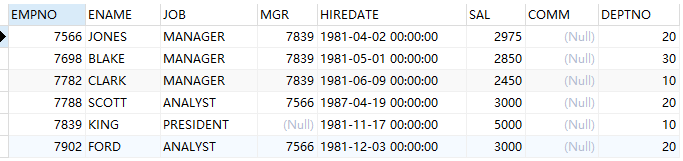
-- 查询不是领导的员工 select * from emp where empno not in (select mgr from emp);

--此时会发现结果为空,查看会发现子查询中存在了 null 值: select mgr from emp;
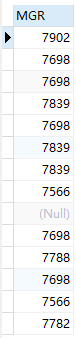
--在 Oracle 中,任何条件与 null 比较结果都为 null ,所以使用在对一个子查询使用 not in 时,应先过滤子查询结果中的 null 值: select * from emp where empno not in (select mgr from emp where mgr is not null);
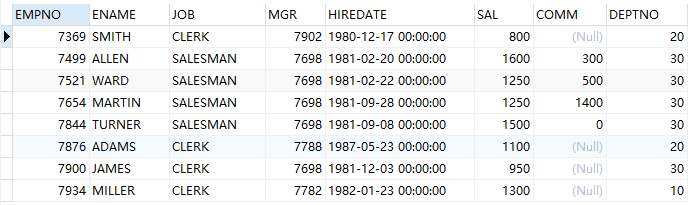
集合运算
-- union :去重排序再合并 (select * from emp where sal>1500) union (select * from emp where deptno=20)
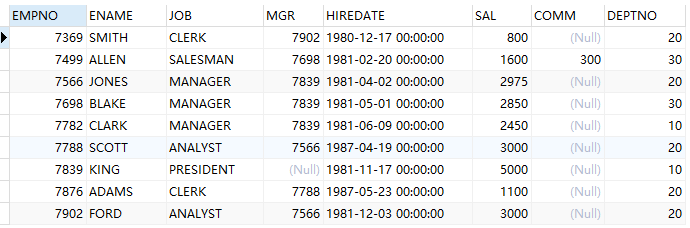
-- union all :不去重直接合并所有 (select * from emp where sal>1500) union all (select * from emp where deptno=20)
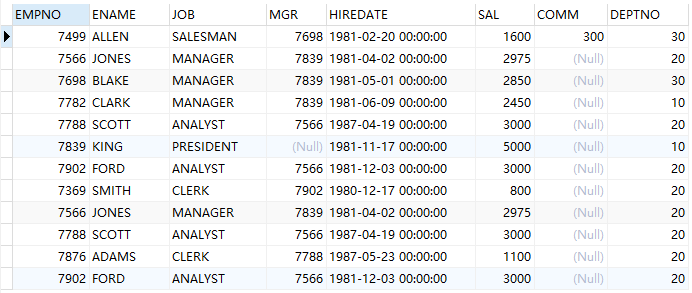
--查询工资大于1500,且在20号部门下的员工 -- intersect :交集运算 (select * from emp where sal>1500) intersect (select * from emp where deptno=20);

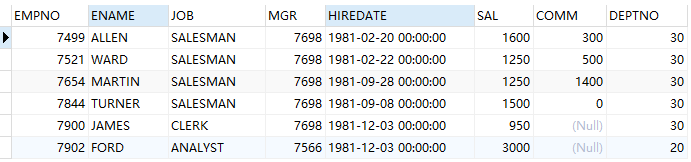
-- minus :差集运算 (select * from emp where to_char(hiredate,'yyyy')='1981') minus (select * from emp where job='PRESIDENT' or job='MANAGER')
集合运算的注意事项:
- 列类型必须一致。
- 列的数量必须一致,如果不足,可用空值填充。
练习
--rownum 是一个伪列,由系统自动生成,用来表示行号。rownum 是 Oracle 中特有的用来表示行号的列,起始值为 1,在查询出结果后再加 1。 -- 查出员工工资最高的前三名并按顺序显示序号 select rownum,e2.* from (select * from emp e1 order by sal desc) e2 where rownum<4;

-- 查询出薪水大于本部门平均薪水的员工 select * from emp e1,(select deptno,avg(sal) avgsal from emp group by deptno) s1 where e1.deptno=s1.deptno and e1.sal>s1.avgsal

--例(sum):统计每年入职的员工个数 select to_char(hiredate,'yyyy') year,count(1) count from emp group by to_char(hiredate,'yyyy');
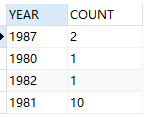
select sum(decode(year,'1987',count)) "1987", sum(decode(year,'1980',count)) "1980", sum(decode(year,'1981',count)) "1981", sum(decode(year,'1982',count)) "1982", sum(count) Total from (select to_char(hiredate,'yyyy') year,count(1) count from emp group by to_char(hiredate,'yyyy')) r1;

-- 方式一 delete from customer where rowid not in (select min(rowid) from customer group by cname) -- 方式二 delete from customer c1 where rowid >(select min(rowid) from customer c2 where c1.cname=c2.cname)
select * from (select rownum hanghao,e1.* from emp e1) e2 where e2.hanghao between 1 and 3;

Java博客目录 | Python博客目录 | C#博客目录

