正则表达式基础
来源:https://blog.csdn.net/zhouzhaoxiong1227/article/details/52026323
正则表达式(Regular Expression),又称正规表示法、常规表示法,在实际的软件开发项目中经常会被使用到。它使用单个字符串来描述、匹配并获取一系列符合某个句法规则的结果。
正则表达式起源
1956年,数学家Stephen Kleene在Warren McCulloch和Walter Pitts早期神经系统工作的基础上,设计出了一个数学符号体系——regular sets(规则的集合),这个东西很快被计算机科学家用于编译器的扫描或词法分析。由于正则表达式强大的文本处理能力,很快被应用到Unix的工具软件grep中;此后,正则表达式被广泛应用于Unix系操作系统、Perl、PHP,Delphi、JAVAScript、C#(.NET)、JAVA、python、Ruby等语言和开发环境中。
正则表达式定义
正则表达式是用来描述字符串特定结构(规则)的语言,由相关引擎执行。正则表达式形象化的描述如图1所示。
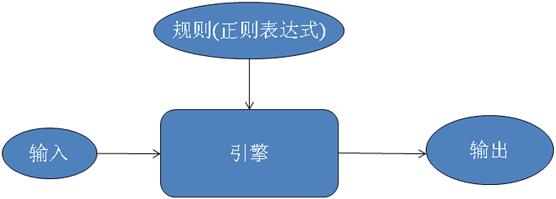
图1 正则表达式形象化的描述
正则表达式作用
1.数据验证
测试输入的字符串,是否符合一定的规则,是否允许输入等。例如,可对Email地址合法性、网址、电话号码、出生年月等进行验证。
2.操作文本
用来识别文档中的特定文本、完全删除该文本或者用其它文本或字符替换。
3.提取子字符串
基于模式匹配,可以查找文档内或输入域内特定的文本,在涉及替换操作时往往都需要先提取。
正则表达式基本语法
1.直接量字符(通常是不可见的字符及匹配自身的字符)
|
字符 |
匹配 |
|
字母数字 |
自身 |
|
\f |
换页符 |
|
\t |
制表符 |
|
\o |
NUL字符 |
|
\n |
换行符 |
|
\v |
垂直制表符 |
|
\r |
回车 |
2.字符类(可以匹配多种字符)
|
字符 |
匹配 |
|
[-] |
在括号内的任意字符,”-”连接字符 |
|
[^-] |
不在括号内的任意字符 |
|
. |
除了换行符和行终止符之外的任意字符 |
|
\w |
任何单字字符(字母、数字、下划线),等于[a-zA-Z0-9_] |
|
\W |
等于[^a-zA-Z0-9_] |
|
\s |
任何空白符,等于[\f\n\r\t\v] |
|
\S |
等于[^\f\n\r\t\v] |
|
\d |
数字[0-9] |
|
\D |
非数字[^0-9] |
3.重复
|
字符 |
匹配 |
|
{n,m} |
匹配前一项至少n次,但不超过m次 |
|
{n,} |
匹配前一项至少n次 |
|
{n} |
匹配前一项正好n次 |
|
? |
有没有,等于{0,1} |
|
+ |
肯定有,等于{1,} |
|
* |
大概有,等于{0,} |
4.选择、分组和锚字符
|
字符 |
匹配 |
|
| |
选择(不是他就是她) |
|
(…) |
分组 |
|
^ |
匹配开头 |
|
$ |
匹配结尾 |
|
\b |
匹配词语的边界 |
|
\B |
匹配非词语的边界 |
5. 标志(标示引擎的工作模式)
|
字符 |
匹配 |
|
i |
不区分大小写 |
|
m |
多行模式 |
|
g |
全局模式 |
说明:
在正则表达式前用“(?i)”标示,例如:(?i)^root$,则root、Root、ROOT都符合要求。
6.其它
1) 匹配元字符“( [ { \ ^ $ | ) ? * + .”,需要用“\”转义。
例如:匹配“.”,正则表达式为“\.”。
2) 贪婪量词与惰性量词
惰性量词仅仅在贪婪量词后面加个“?”。
用贪婪量词进行匹配时,它首先会将整个字符串当成一个匹配,如果匹配成功就退出,如果不匹配,就截去最后一个字符进行匹配;如果不匹配,继续将最后一个字符截去进行匹配,直到有字符匹配为止。
用惰性量词进行匹配时,它首先将第一个字符当成一个匹配,如果成功则退出;如果失败,则测试前两个字符,依次增加,直到遇到合适的匹配为止 。
例如:“\d+”是贪婪量词,而“\d+?”是非贪婪(惰性)量词。
3) 子匹配
内部的分组匹配,用“()”标示一个分组。
子匹配的每个分组都被放在一个特殊的地方以备将来使用,这些被存储的值是分组中的特殊值,称之为反向引用。
例如:验证输入的是日期,再提取到月份,其正则表达式为“^\d{4}\-(\d{2})\-\d{2}$”。
4) 正向前瞻和负向前瞻
正向前瞻:(?<=字符)或(?=字符)
注意:一定要有等于才行。
负向前瞻:(?<!字符)或(?!字符)
注意:一定要有不等于才行。
也就是说,我们可以自己制定匹配的边界在哪里,这在字符串提取时常用。
示例:
例1,我们取“#”之前的字符,但是不包括“#”,其正则表达式:[\w]+(?=#)
例2,我们取不在“#”之前的字符,但是不包括“#”,其正则表达式: [\w]+(?!#)
例3,我们取“<>”之间的字符,但是不包括“<>”,其正则表达式: (?<=<)[\w]+(?=>)
正则表达式常见用法
1.数字
1)正整数: ^[1-9][0-9]*$
2)非正整数: ^((-[1-9][0-9]*)|(0))$
3)负整数:^-[1-9][0-9]*$
4)整数: ^(0|-?[1-9][0-9]*)$
5)非负浮点数:^\d+(\.\d+)?$
2.字母
1)英文字符串:^[A-Za-z]+$
2)英文大写串:^[A-Z]+$
3)英文小写串:^[a-z]+$
4)英文字符数字串:^[A-Za-z0-9]+$
5)英文数字加下划线串:^\w+$
3.其它
1.E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
2.URL:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\':+!]*([^<>\"\"])*$
3.邮政编码:^[1-9]\d{5}$
4.中文:^[\u4e00-\u9fA5]+$
5.电话号码:^((\d2,3\d2,3)|(\d{3}\-))?(0\d2,30\d2,3|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$
6.手机号码:^1\d{10}$
7.首尾空格:(^\s+)|(\s+$)
8.身份证:^(\d{15}|\d{18})$ (注:中国的身份证为15位或18位)
9.账号:^[a-zA-Z]\w{4,15}$ (注:字母开头,允许5-16字节,允许字母数字下划线)
10.IP:^([1-9]\d{0,1}|1\d{2}|2[0-4]\d|25[0-5])(\.([1-9]\d{0,1}|1\d{2}|2[0-4]\d|25[0-5])){3}$ (IP是由大于等于0且小于等于255的数字、“.”组成的,验证每个数字分项再和“.”拼接就可以了)
总结
正则表达式的功能非常的强大,大家在实际使用到的时候才能够感觉得到。当然,要想同时记住这么多的正则表达式的规则,也不是简单的事情。大家可以将常见的正则表达式记录下来(就像本文一样),待需要用到的时候可以拿出来参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号