

探索Ebay汽车销售数据
一、实验目的
1. 熟悉清理数据的流程;
2. 分析Ebay二手车销售数据;
3. 了解jupyter notebook为pandas提供的一些独特特性。
二、实验开发环境和工具
可以在Windows或Linux操作系统上搭建开发环境,使用Anaconda科学计算包安装Python 3,里面会包含大多数科研常用的库。.ipynb文件推荐使用Anaconda内置的web版Jupyter Notebook。
三、实验内容
在本实验中,我们将使用来自eBay Kleinanzeigen(德国eBay网站的分类部分)的二手车数据集。该数据集最初是被抓取并上传到Kaggle的。 我们对上传到Kaggle的原始数据集进行了一些修改:
- 我们从完整的数据集中采样了50,000个数据点。
- 我们对数据集进行了某种程度的污染,使其更类似于从抓取的数据集中获得的数据(已将上传到Kaggle的版本进行了清理,以便于使用)。
随数据提供的数据字典如下:
- dateCrawled— 首次抓取该广告的时间。所有字段值均从该日期开始。
- name— 汽车名称
- seller— 卖方是私人还是经销商
- offerType— 清单类型
- price— 广告上出售汽车的价格
- abtest— 清单是否包含在A / B测试中
- vehicleType— 车辆类型
- yearOfRegistration— 汽车首次注册的年份
- gearbox— 变速箱类型。
- powerPS— PS中汽车的动力。
- model— 汽车型号名称
- km— 汽车行驶了多少公里
- monthOfRegistration— 汽车首次注册的月份
- fuelType— 汽车使用哪种燃料
- brand——汽车的品牌
- notRepairedDamage——汽车是否有尚未修理的损坏
- dateCreated——创建eBay清单的日期
- nrOfPictures——广告中的图片数量
- postalCode— 车辆位置的邮政编码
- lastSeenOnline— 抓取工具上次在线看到此广告的时间
具体任务如下:
- 读取数据[1]
首先,导入所需的库,然后将数据集读取到pandas中。
具体要求:
- 首先在markdown单元格中编写一个段落,介绍项目和数据集。
- 导入pandas和numpy库
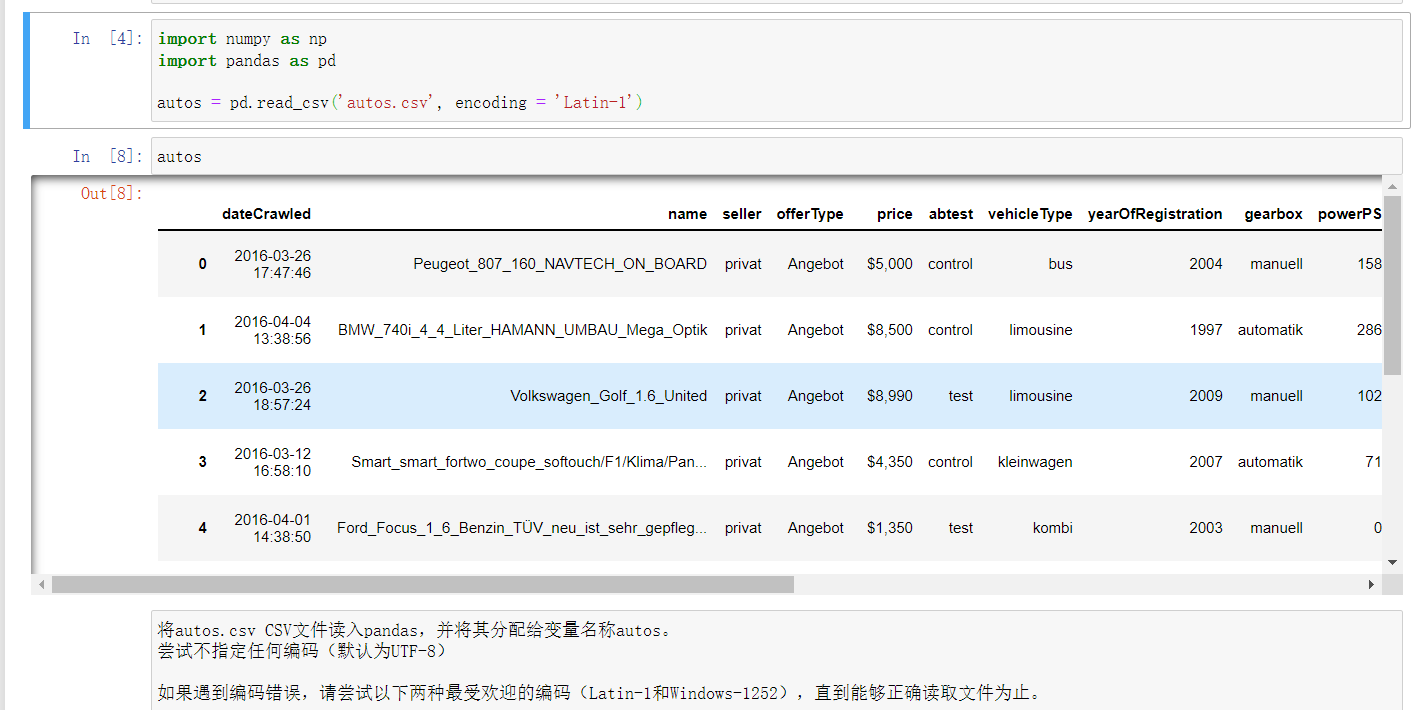
- 将autos.csv文件读入pandas,并将其分配给变量autos。
- 尝试不指定任何编码(默认为UTF-8)
- 如果遇到编码错误,请尝试以下两种最受欢迎的编码(Latin-1和Windows-1252),直到能够正确读取文件为止。
- 仅使用变量autos创建一个新单元格并运行该单元格。
- Jupyter Notebook的一个巧妙功能是它能够呈现任何Pandas对象的前几个值和最后几个值。
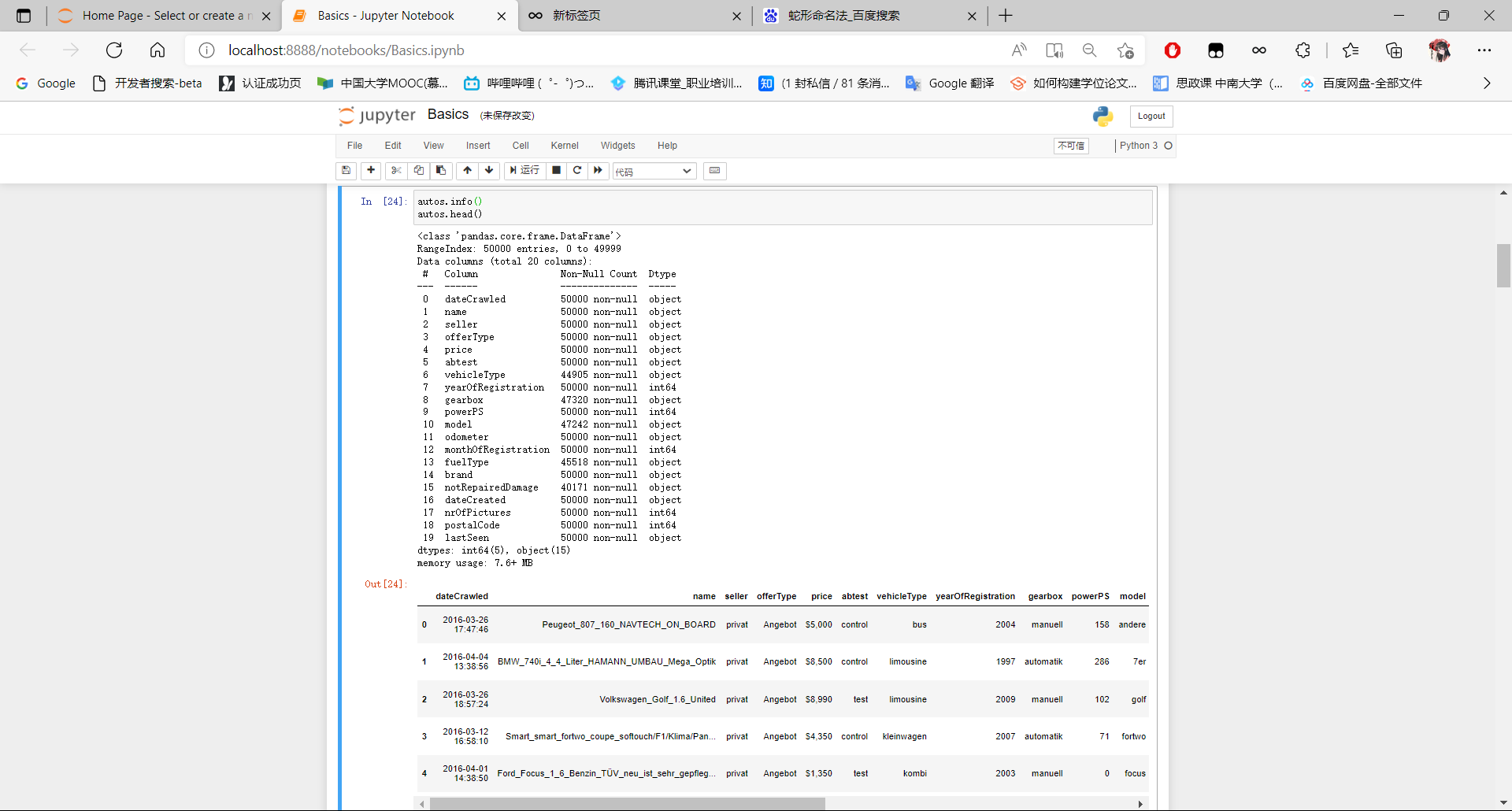
- 使用DataFrame.info()和DataFrame.head()方法可打印有关autos数据框以及前几行的信息。
- 写一个markdown单元,简要描述对数据的观察结果。
代码:
import numpy as np
import pandas as pd
autos = pd.read_csv('autos.csv', encoding = 'Latin-1')
autos.info()
autos.head()
运行截图:
- 清洗列名[2]:
通过对数据的观察,我们可以发现数据集包含20列,其中大多数是字符串。
一些列具有空值,但没有一个列的空值超过20%。并且列名使用驼峰命名(camel case)而不是Python首选的蛇形命名(snake case),这意味着我们不能像之前那样只用下划线替换空格。
让我们将列名从驼峰命名转换为蛇形命名,并根据数据字典对某些列名进行改写,以提高描述性。
具体要求:
- 使用DataFrame.columns属性可打印现有列名称的数组
- 复制该数组,并对列名称进行以下编辑:
- yearOfRegistration改为registration_year
- monthOfRegistration改为registration_month
- notRepairedDamage改为unrepaired_damage
- dateCreated改为ad_created
- 其余列名称从驼峰命名改为蛇形命名
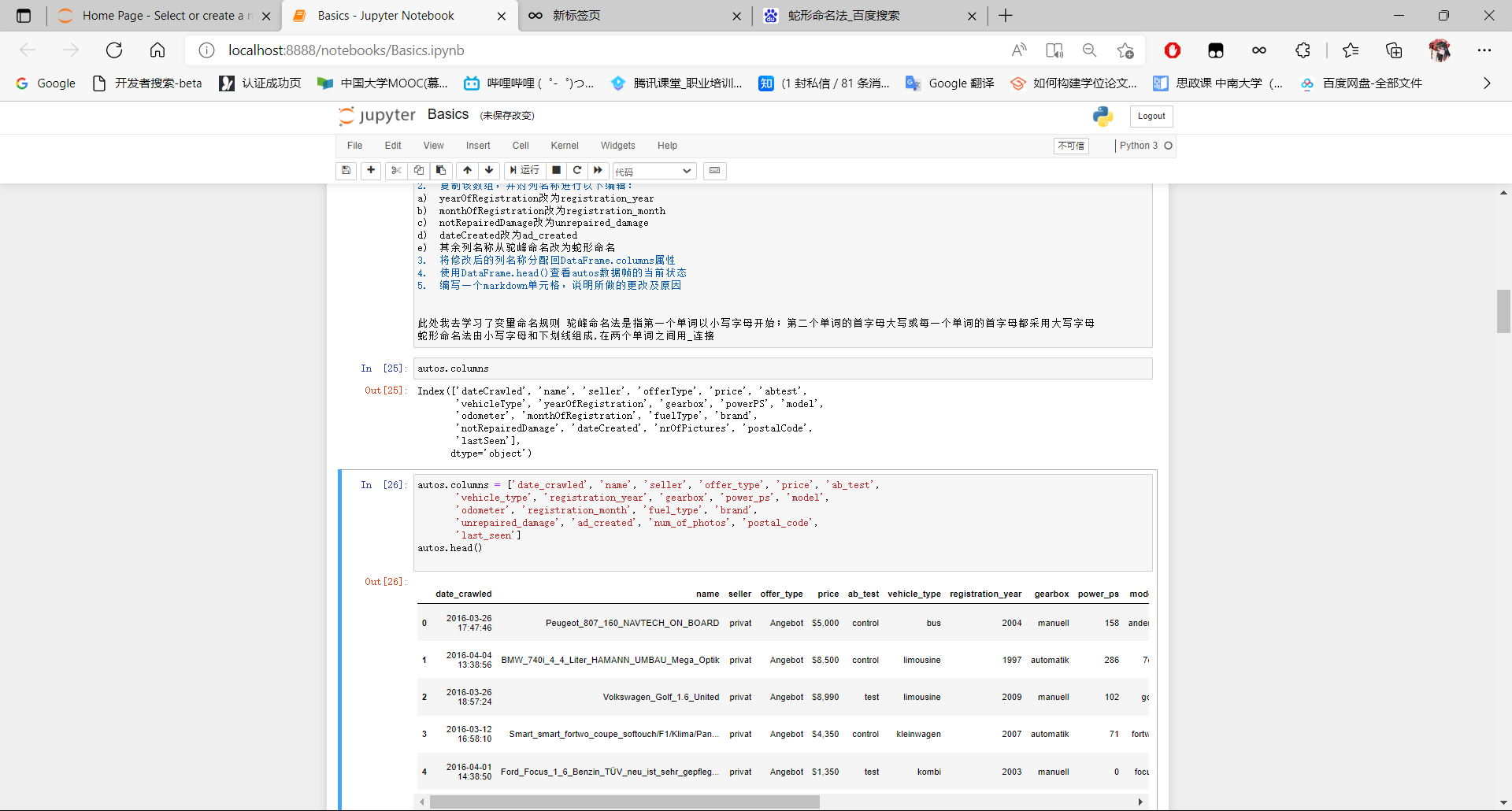
- 将修改后的列名称分配回DataFrame.columns属性
- 使用DataFrame.head()查看autos数据帧的当前状态
- 编写一个markdown单元格,说明所做的更改及原因
代码:
autos.columns
autos.columns = ['date_crawled', 'name', 'seller', 'offer_type', 'price', 'ab_test',
'vehicle_type', 'registration_year', 'gearbox', 'power_ps', 'model',
'odometer', 'registration_month', 'fuel_type', 'brand',
'unrepaired_damage', 'ad_created', 'num_of_photos', 'postal_code',
'last_seen']
autos.head()
运行截图:
- 数据探索和清洗初步[3]
让我们进行一些基本的数据探索,以确定需要执行哪些清洗任务。我们可以观察:
- 所有或几乎所有值都相同的文本列。 由于它们没有有用的分析信息,因此通常可以删除它们。
- 以文本形式存储的数字数据示例,可以清除和转换。
以下方法对于浏览数据很有帮助:
- DataFrame.describe()(使用include ='all'获取分类和数字列)
- Series.value_counts()和Series.head()(如果需要仔细查看任何列) 。
具体要求:
- 使用DataFrame.describe( )查看所有列的描述性统计信息
- 写一个markdown单元格注意:
- 任何大部分情况下只有一个值的列都可作为被删除列的候选
- 任何列都需要更多调查
- 存储为文本的任何数字字段都需要清洗
- 如果你需要进一步观察任何列,请写下你的发现
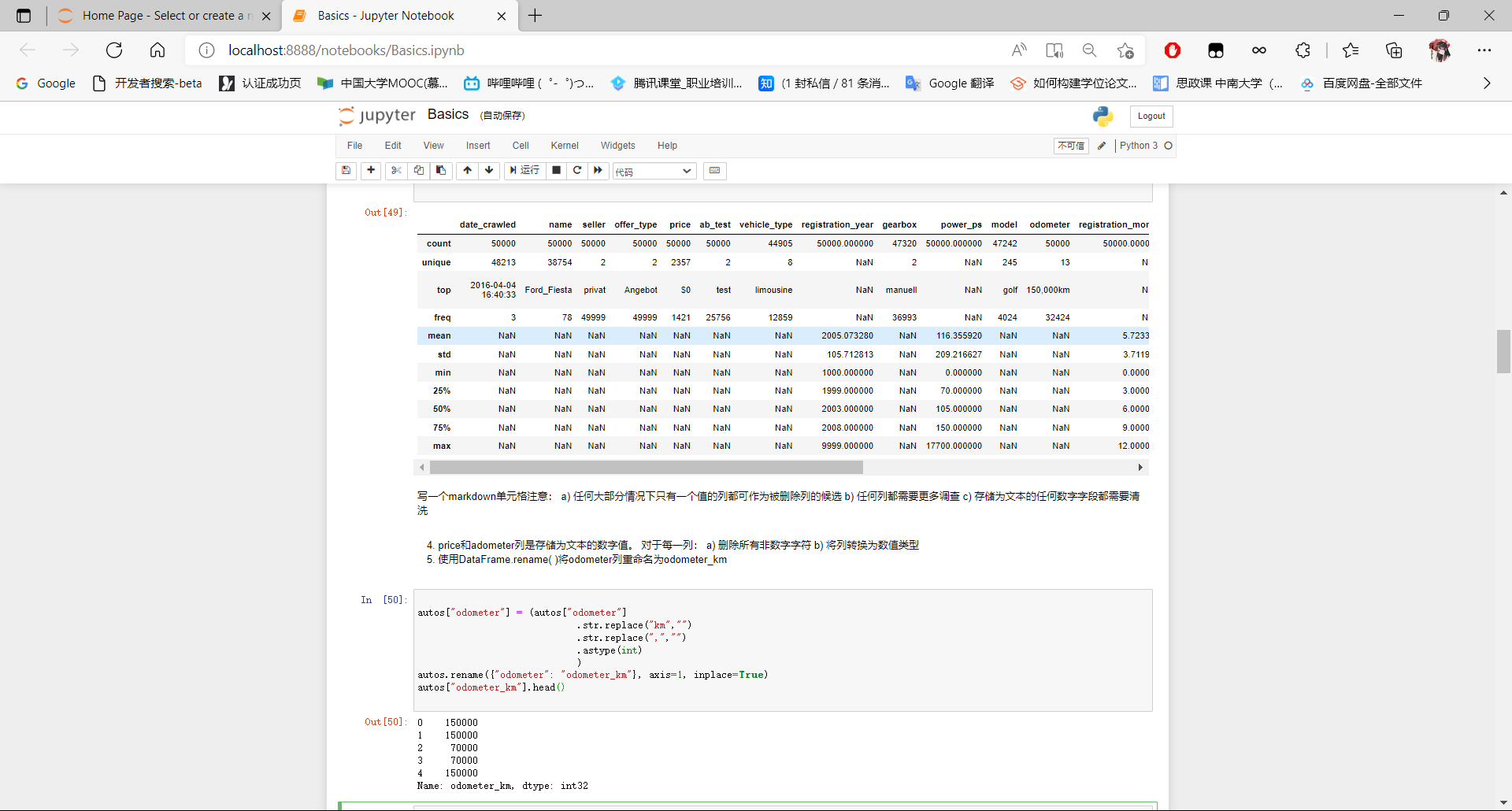
- price和adometer列是存储为文本的数字值。 对于每一列:
- 删除所有非数字字符
- 将列转换为数值类型
- 使用DataFrame.rename( )将odometer列重命名为odometer_km
代码:
autos.describe(include = 'all')
autos["price"] = autos["price"].str.replace("$", "").str.replace(",","").astype(int)
autos["price"].head()
autos["odometer"] = (autos["odometer"]
.str.replace("km","")
.str.replace(",","")
.astype(int)
)
autos.rename({"odometer": "odometer_km"}, axis=1, inplace=True)
autos["odometer_km"].head()
运行截图:

- 探索Odometer和Price列[4]
经过对数据的初步探索,我们了解到有许多文本列中几乎所有值都是相同的(seller和offer_type)。我们还通过将price和odometer列转换为数字类型,并将odometer重命名为odometer_km进行了初步的数据清洗。让我们继续探索数据,特别是寻找看起来不正确的数据。 我们将从分析odometer_km和price列开始。 我们将采取以下步骤:
- 使用最小值和最大值分析列,并查找我们可能希望删除的看起来不切实际的过高或低(离群值)的值
- 可用方法:
- Series.unique().shape:查看多少个唯一值
- Series.describe():查看最小/最大/中位数/均值等
- Series.value_counts():查看唯一值的频次
- 若值过多,可通过链接到.head()来减少显示的数量
- 因为Series.value_counts()返回一个序列,所以我们可以使用Series.sort_index()以及ascending=True或False来查看其最大值和最小值及其计数(也可以在此处链接到head())
- 移除异常值时,我们可以执行df[(df["col"] > x ) & (df["col"] < y )],但使用df[df["col"].between(x,y)]更易读
具体要求如下:
- 对odometer_km和price列:
- 使用以上技术探索数据
- 如果发现有异常值,将其删除
- 通过markdown说明你做的工作
- 除去异常值后,请对剩余值进行观察
代码:
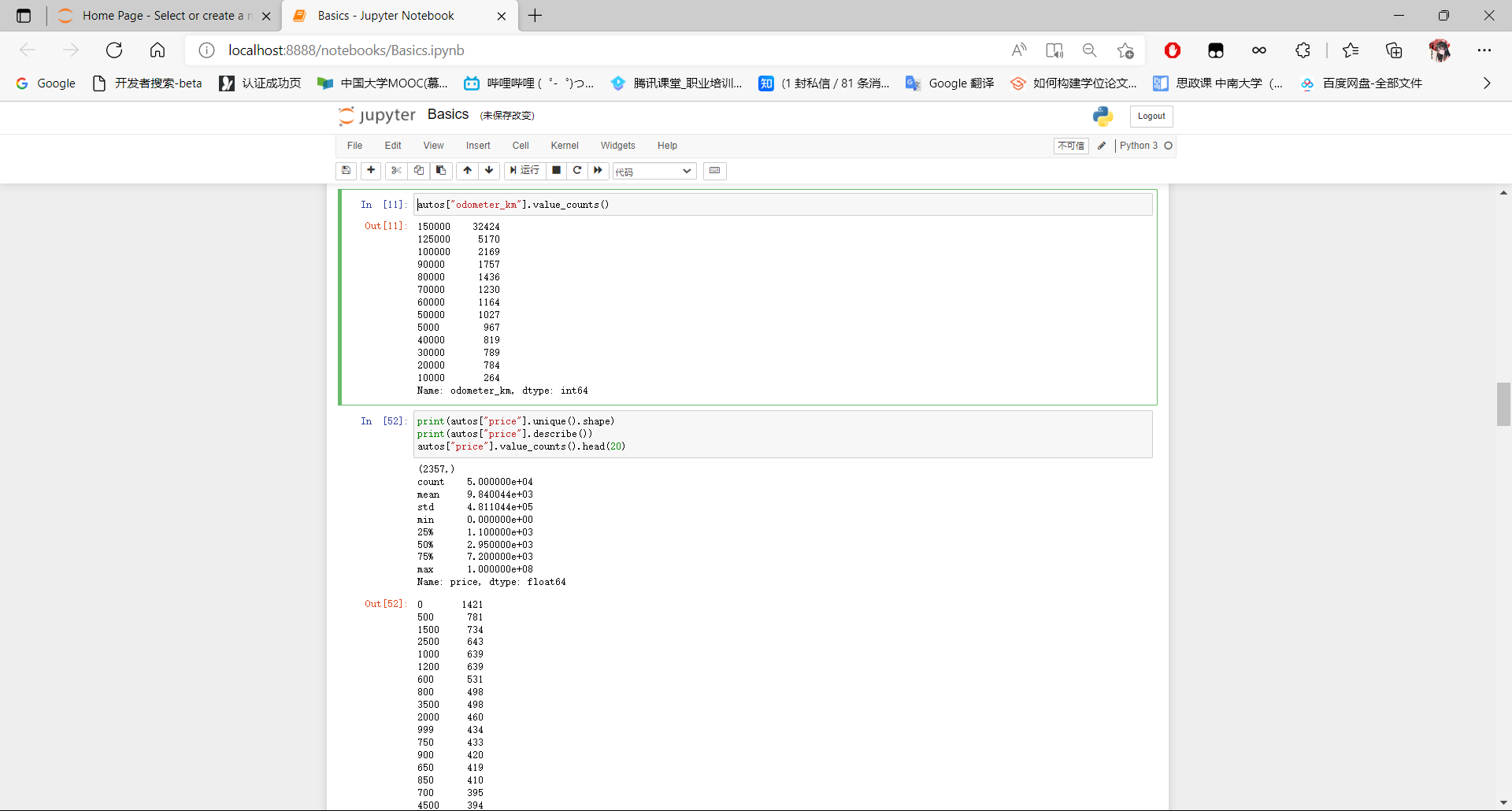
autos["odometer_km"].value_counts()
print(autos["price"].unique().shape)
print(autos["price"].describe())
autos["price"].value_counts().head(20)
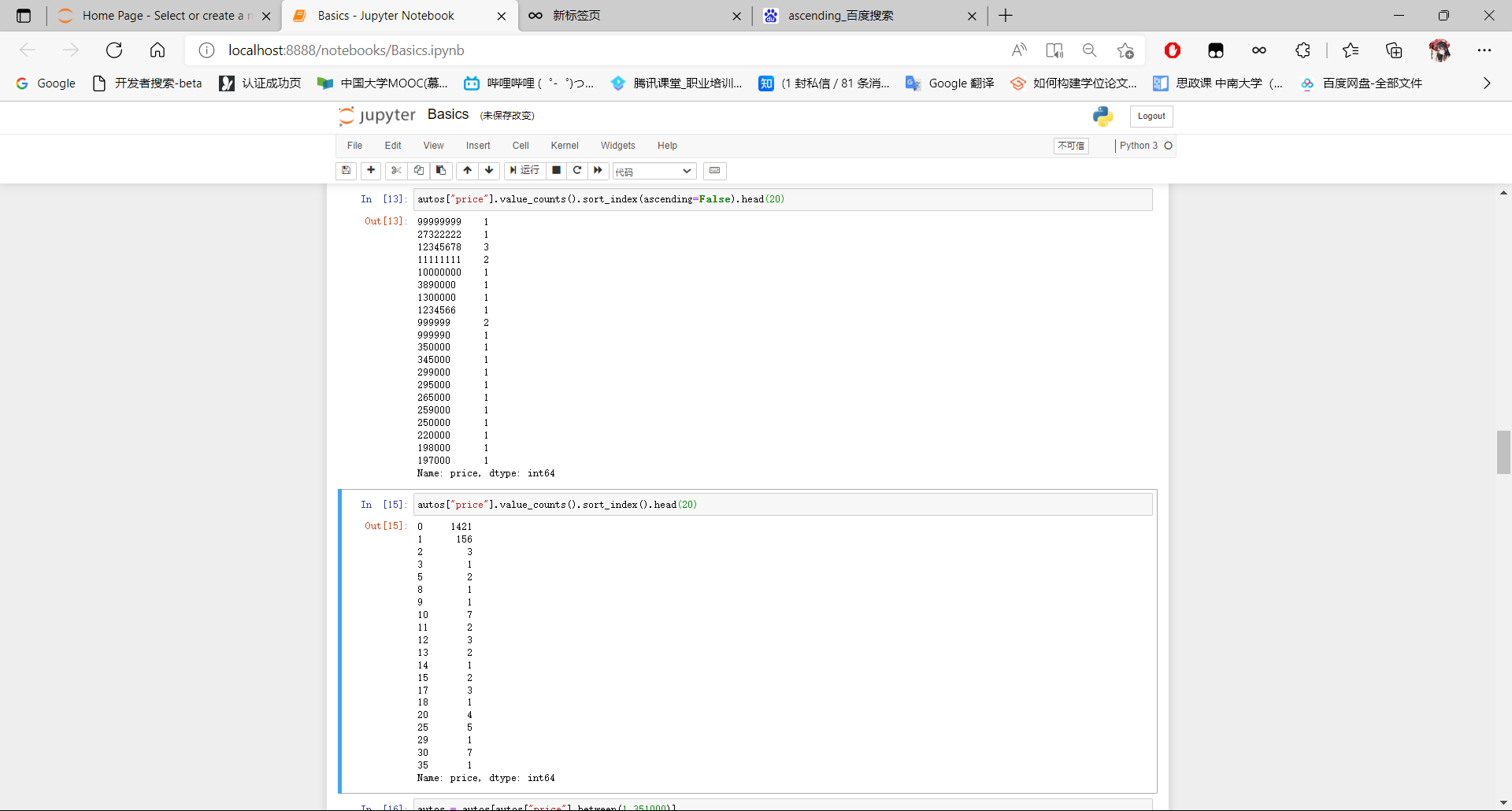
autos["price"].value_counts().sort_index(ascending=False).head(20)
autos["price"].value_counts().sort_index().head(20)
autos = autos[autos["price"].between(1,351000)]
autos["price"].describe()
autos["registration_year"].describe()
运行截图:
(5)探索date类型的列[5]
数据中有5列字段表示日期。 其中一些列是由搜索引擎创建的,而另外一些则来自网站本身。 我们可以通过参考数据字典来区分,如下所示:
- date_crawled:由搜寻器添加
- last_seen:由搜寻器添加
- ad_created:来自网站
- registration_month:来自网站
- registration_year:来自网站
现在,pandas将date_crawled,last_seen和ad_created列都标识为字符串。 因为这三列都表示为字符串,所以需要将这三列数据转换为数字表示,以便定量分析。 其他两列pandas表示为数值,因此我们可以使用Series.describe()之类的方法来了解分布,而无需进行任何额外的数据处理。
首先,让我们了解三个字符串形式的日期列中值的格式。 这些列均表示完整的时间戳形式,如下所示:
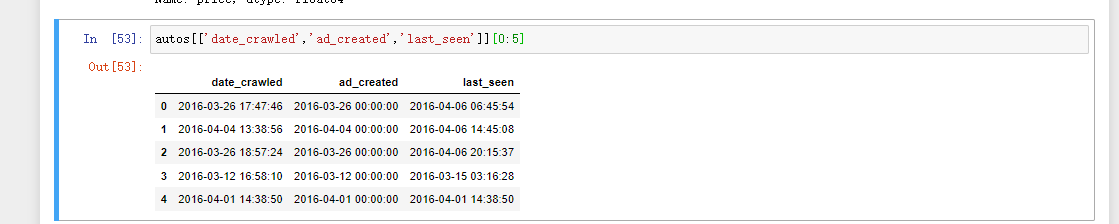
autos[['date_crawled','ad_created','last_seen']][0:5]
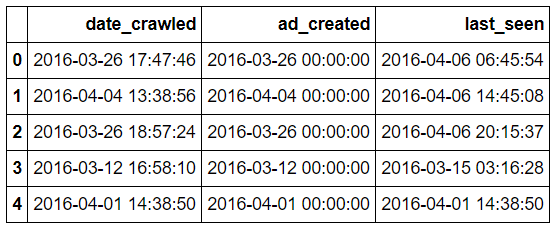
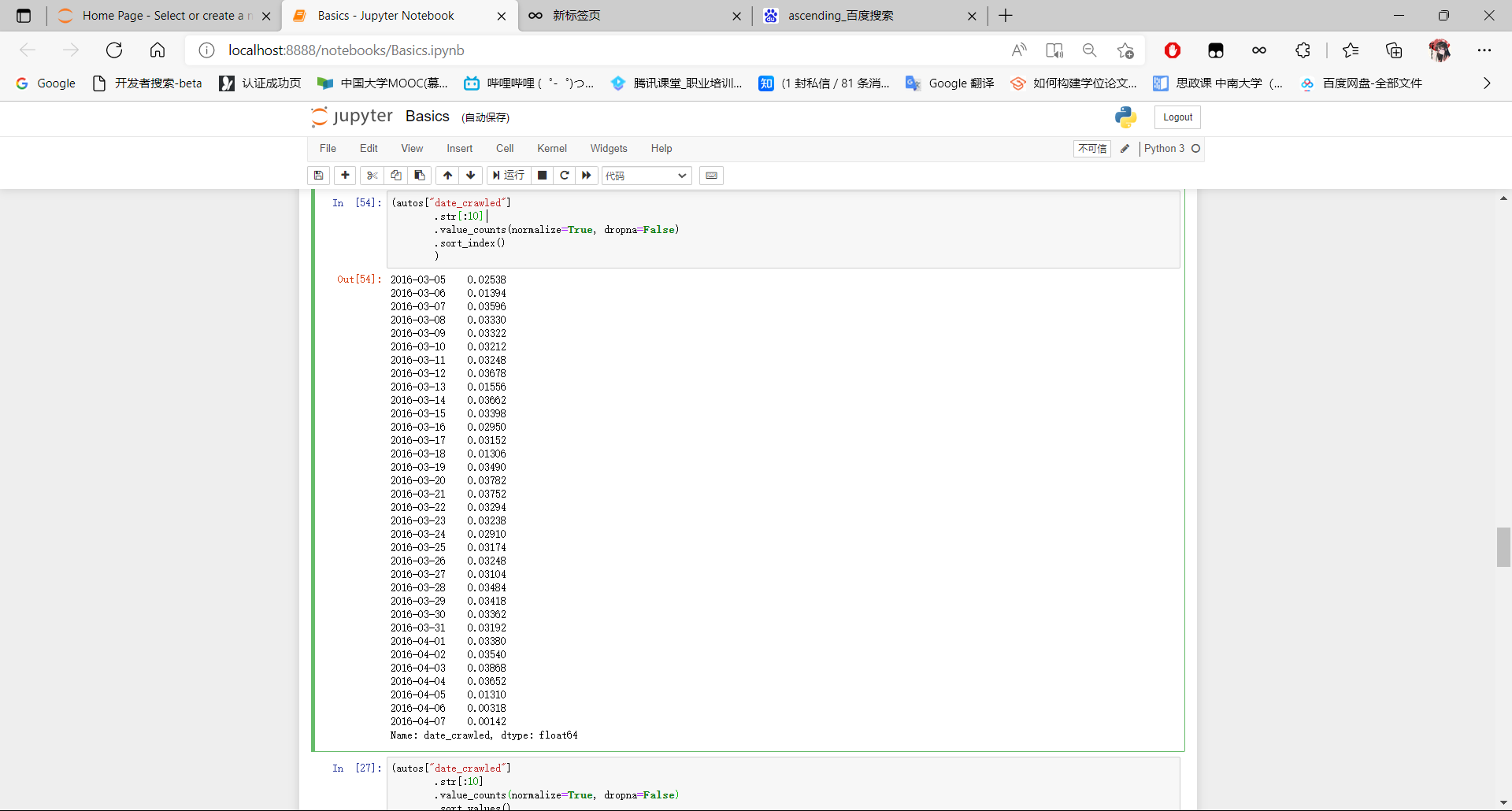
可以注意到前10个字符代表具体哪一天(例如2016-03-12)。 要了解日期范围,我们可以只提取日期值,可使用Series.str [:10] 选择每列的前10个字符,如下所示:
print(autos['date_crawled'].str[:10])
部分结果如下:
- 0 2016-03-26
- 1 2016-04-04
- 2 2016-03-26
- 3 2016-03-12
- ...
然后使用Series.value_counts()生成分布,并按索引排序。
具体要求:
- 使用我们刚刚描述的工作流程来计算date_crawled,ad_created和last_seen列(所有字符串列)中值的百分比分布。
- 要在分布中包括缺失值并使用百分比而不是计数,可使用Series.value_counts(normalize = True,dropna = False)方法。
- 要按日期升序排列(最早到最新),可使用Series.sort_index()方法。
- 每次探索某一列数据后,写下一个markdown单元格以解释对数据的观察结果。
- 使用Series.describe()了解registration_year的分布。
- 写一个markdown单元格来解释对数据的观察结果。
代码:
autos[['date_crawled','ad_created','last_seen']][0:5]
(autos["date_crawled"]
.str[:10]
.value_counts(normalize=True, dropna=False)
.sort_index()
)
(autos["last_seen"].str[:10].value_counts(normalize = True, dropna = False).sort_index())
autos["registration_year"].describe()
运行截图:
(6)处理不正确的注册年份数据[6]
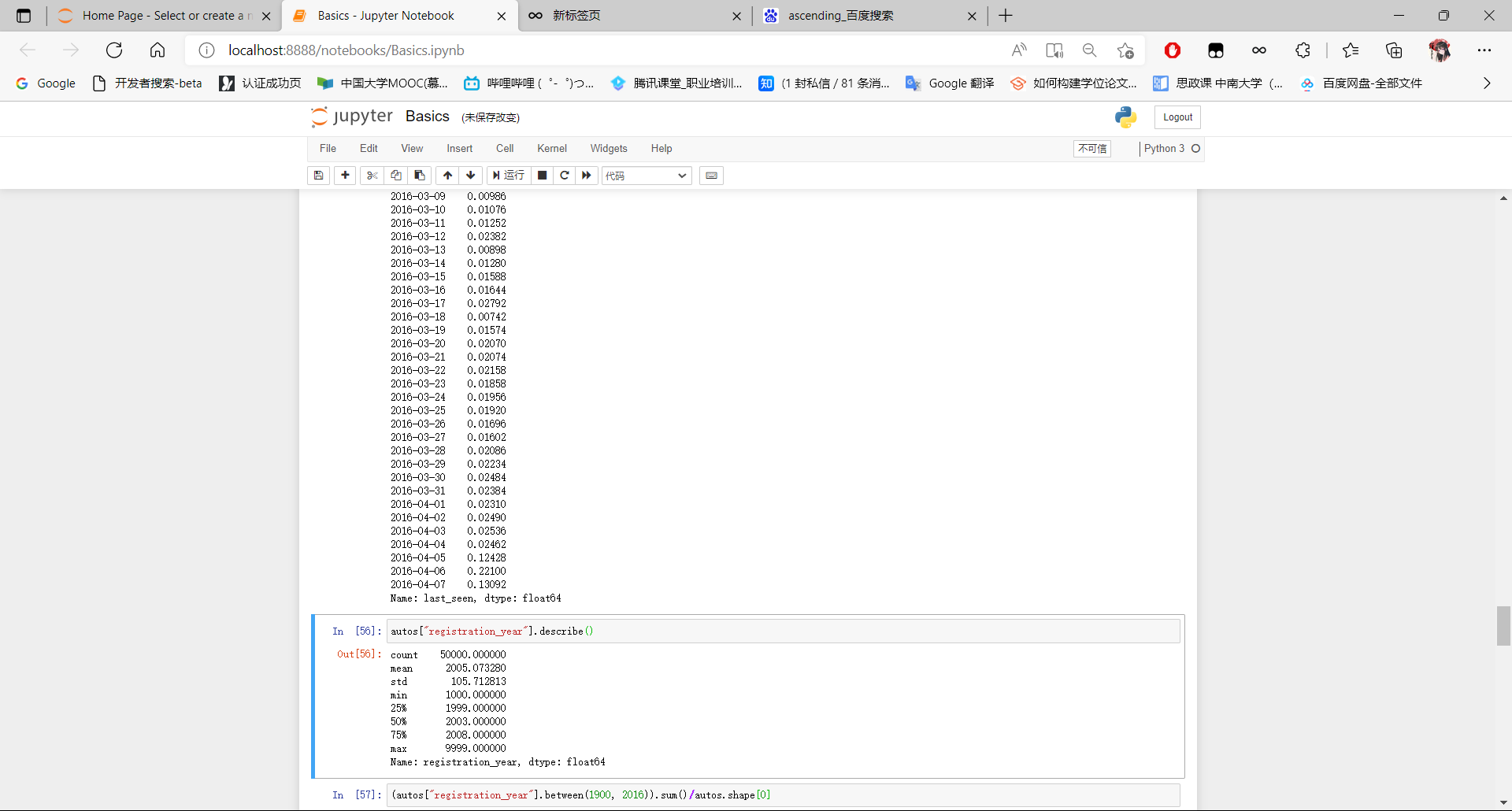
我们可用如下代码对registration_year数据字段进行观察:
autos["registration_year"].describe()
可以发现registration_year列包含一些奇怪的值:
- 最小值是1000,该日期是在发明汽车之前
- 最大值是9999,该日期是在未来很多年之后
由于该数据集是2016年爬取的,因此任何2016年之后的注册年份肯定不正确。而最早的有效年份应当在汽车发明之后,我们可以将最早的注册年份设置为1900年。因此,我们可以计算一下1900年至2016年间隔之外的汽车清单数量,看看是否可以安全地删除这些正常注册年份之外的数据行。
具体要求:
- 确定registration_year列中可接受的最高和最低值。
- 写一个markdown单元格,解释所确定的值及其相应的依据。
- 去除那些上限和下限之外的值
- 并使用Series.value_counts(normalize = True)计算其余值的分布。
- 写一个markdown单元格来解释观察的结果。
代码:
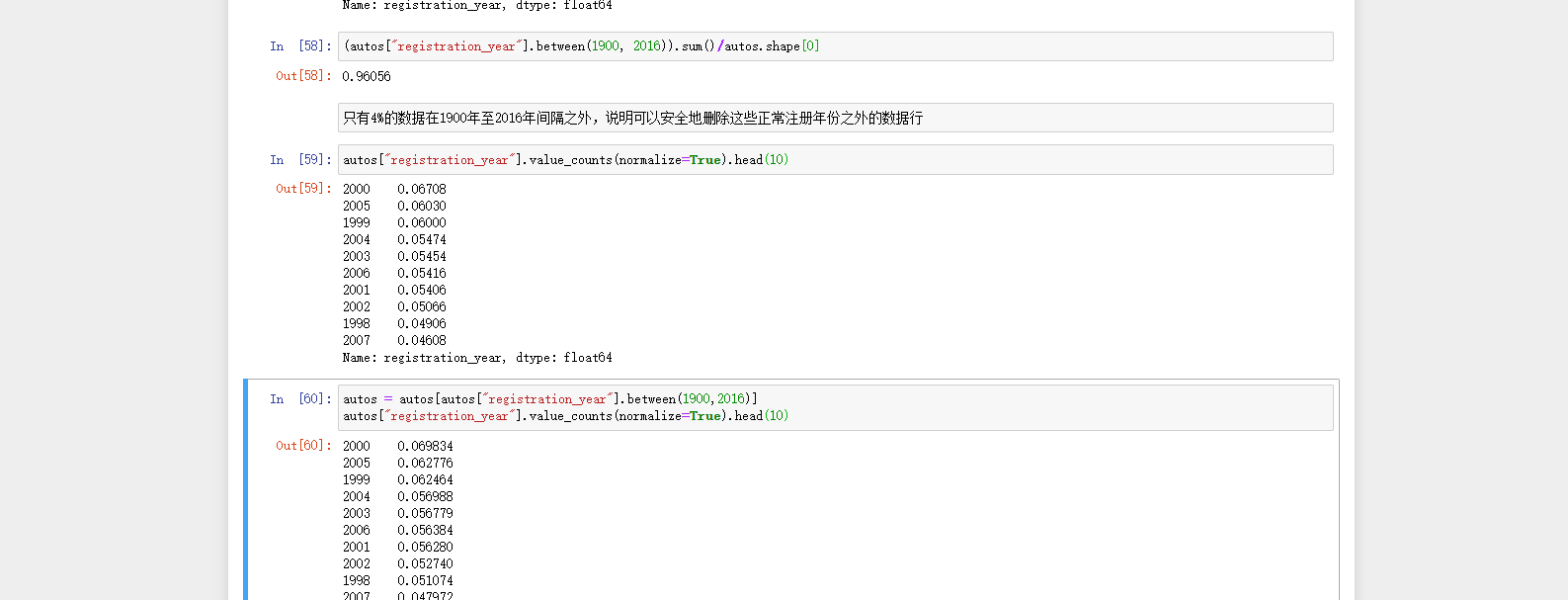
(autos["registration_year"].between(1900, 2016)).sum()/autos.shape[0]
autos["registration_year"].value_counts(normalize=True).head(10)
autos = autos[autos["registration_year"].between(1900,2016)]
autos["registration_year"].value_counts(normalize=True).head(10)
运行截图:
(7)按品牌探索价格[7]
在本课程中学习的一种分析技术是聚合。处理汽车数据时,很自然地探索不同汽车品牌之间的差异。 我们可以使用聚合来了解brand列。
如果还记得以前的任务,我们将探讨如何使用循环执行聚合。流程如下所示:
- -确定我们要汇总的唯一值
- -创建一个空字典来存储我们的汇总数据
- -遍历唯一值(val),并针对每个值:
- -通过唯一值对数据帧进行分组
- -计算我们感兴趣的任何一列的平均值
- -将val/mean 作为 k/v(键值对)分配给字典。
具体要求:
- 在brand列中浏览唯一值,然后确定要汇总的品牌。
- 可能要选择前20个,或者要选择那些占总价值一定百分比(例如> 5%)的商品。
- 请记住,Series.value_counts()会生成带有索引标签的series,因此,可根据需要使用Series.index属性访问标签。
- 通过Markdown写段话描述品牌数据。
- 创建一个空字典来保存汇总的数据。
- 循环选择所选择的品牌,然后以品牌名称为键,为字典指定平均价格。
- 打印汇总数据字典,并通过Markdown编写一段分析结果的话。
代码:
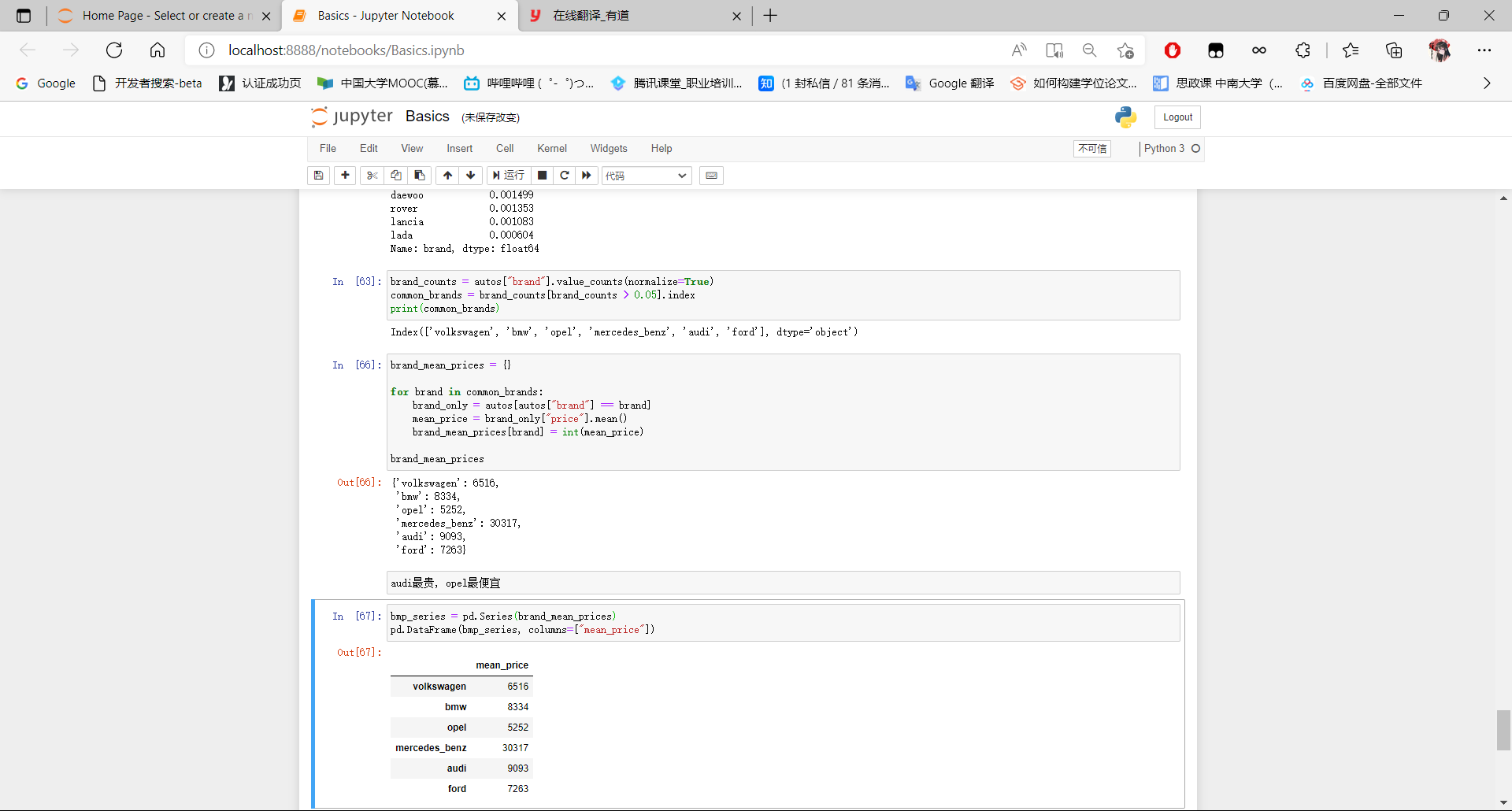
brand_counts = autos["brand"].value_counts(normalize=True)
common_brands = brand_counts[brand_counts > 0.05].index
print(common_brands)
brand_mean_prices = {}
for brand in common_brands:
brand_only = autos[autos["brand"] == brand]
mean_price = brand_only["price"].mean()
brand_mean_prices[brand] = int(mean_price)
brand_mean_prices
bmp_series = pd.Series(brand_mean_prices)
pd.DataFrame(bmp_series, columns=["mean_price"])
运行截图:
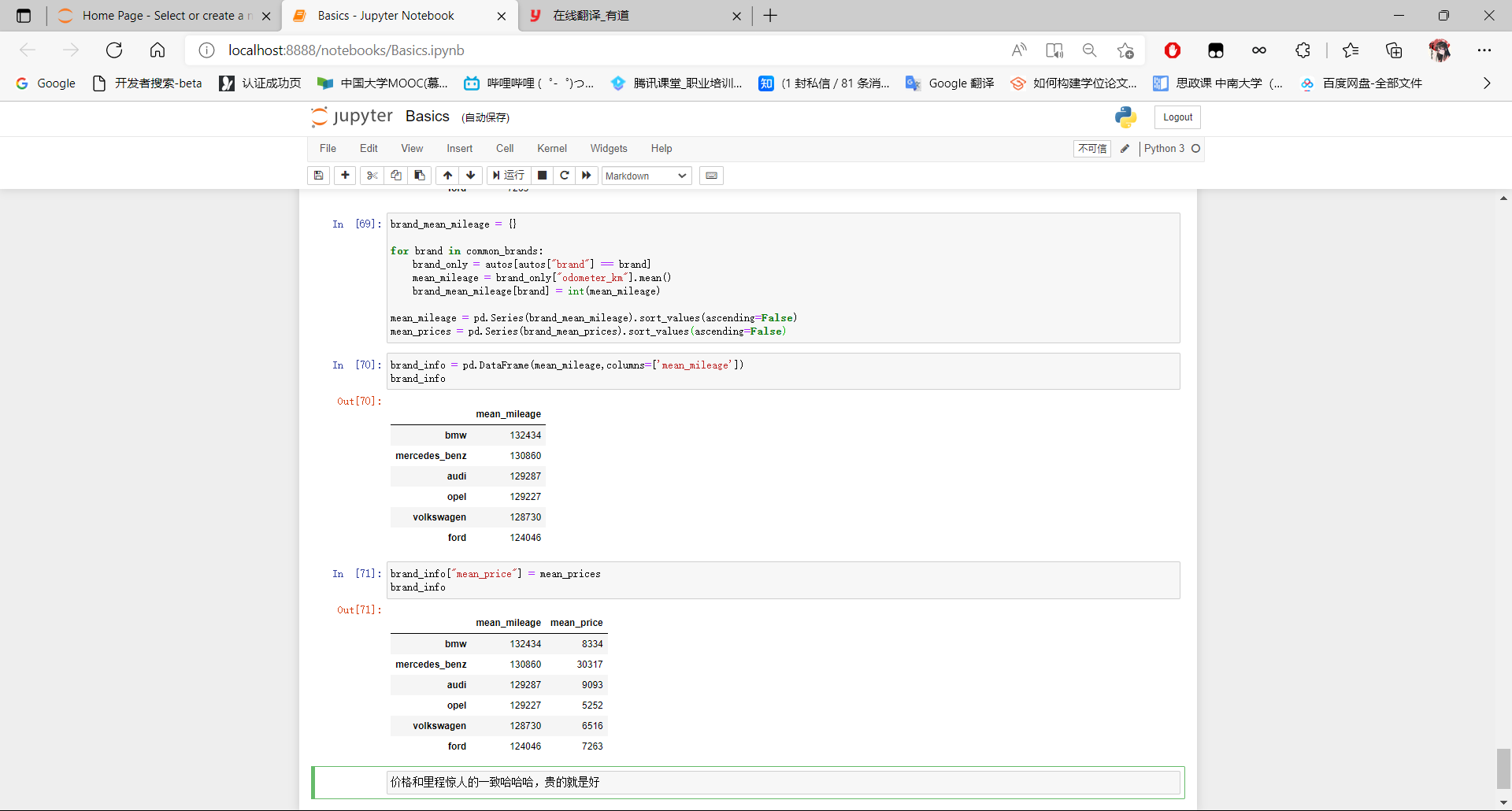
(8)将聚合数据存储在DataFrame中[8]
在前一部分,我们汇总了各个品牌,以了解平均价格。我们观察到排名前6位的品牌之间存在明显的价格差距。
- 奥迪(Audi),宝马(BMW)和奔驰(Mercedes Benz)更贵
- 福特(Ford )和欧宝(Opel)便宜
- 大众(Volkswagen)介于两者之间
对于排名前6位的品牌,让我们使用聚合来了解这些汽车的平均行驶里程,以及是否与均价存在的明显的联系。虽然可以通过显示两个聚合的series对象并在视觉上直接进行比较,但这存在一些限制:
- 如果要扩展到多个列,则很难比较两个以上的聚合series对象
- 难以同时比较每个series对象多个行
- 需要按两个series对象的索引(品牌名称)进行排序,才便于从视觉上直观地比较
另一种可取代的思路是,我们可以将两个series对象中的数据组合成一个 dataframe(具有共享索引),然后直接显示该dataframe。 为了实现这一功能,我们需要学习两种pandas方法:
- pandas.Series构造函数
- pandas.DataFrame构造函数
以下是使用brand_mean_prices字典的series 构造函数的示例:
- bmp_series = pd.Series(brand_mean_prices)
- print(bmp_series)
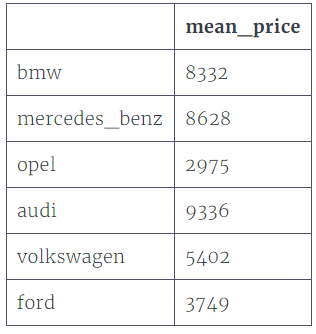
输出结果是:
- audi 9336
- bmw 8332
- ford 3749
- mercedes_benz 8628
- opel 2975
- volkswagen 5402
- dtype: int64
字典中的键成为series对象中的索引。我们可从该series对象创建一个单列dataframe。在调用dataframe构造函数(接受类似数组的对象)以指定列名时,我们需要使用columns参数(或者默认情况下,列名将设置为0):
- df = pd.DataFrame(bmp_series, columns=['mean_price'])
- df
具体要求:
- 使用之前用到过的基于字典+循环的方法来计算每个顶级品牌的平均里程和平均价格,并将结果存储在字典中。
- 使用 series构造函数将两个字典都转换为 series对象。
- 使用dataframe构造函数将一个series对象作为参数创建一个dataframe。
- 将另一个series对象作为新列加入已创建的dataframe中。
- 打印输出dataframe进行观察,并编写一段话分析聚合的数据。
代码:
brand_mean_mileage = {}
for brand in common_brands:
brand_only = autos[autos["brand"] == brand]
mean_mileage = brand_only["odometer_km"].mean()
brand_mean_mileage[brand] = int(mean_mileage)
mean_mileage = pd.Series(brand_mean_mileage).sort_values(ascending=False)
mean_prices = pd.Series(brand_mean_prices).sort_values(ascending=False)
brand_info = pd.DataFrame(mean_mileage,columns=['mean_mileage'])
brand_info
brand_info["mean_price"] = mean_prices
brand_info
运行截图:
在本次实验中,我们练习了各种pandas方法来探索和理解有关二手汽车的数据集。
通过这次实践,我熟悉了pandas库的使用方法,在实践过程中出现了很多错误,如不会调用函数,丢参数等问题,都一个一个攻克,收获了学习的快乐!
参考文献及数据集
https://www.kaggle.com/orgesleka/used-cars-database
项目代码(包含旧版数据集):
https://files.cnblogs.com/files/blogs/766838/project-py-data-1.rar?t=1678809542

 浙公网安备 33010602011771号
浙公网安备 33010602011771号