d2l中的valid_lens用法解析
X的维度: torch.Size([64, 10, 32]) batchsz=64,seq_len=10,dim=32。
其实很好理解啊,X的维度是[64, 10, 32];所以valid_lens要mask它啊,所以,肯定是(64,10),现在 裂变成4个head,所以就是(256,10)。
part0
valid_lens的维度:[64],每个句子对应一个。从数据集中取出来就是如此。
注意Mulitiheadattention的forward函数中,注意X的这个过程:把dim裂开维(num_heads,dim);然后num_heads提前、和batchsz合并,num_heads=4,故X变成了(256,10,8)。
在Mulitiheadattention的过attention之前,valid_lens扩增了头数:
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for
# `num_heads` times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
此时,valid_lens的维度:[256]。只是复制了4个头。
【0】最终使用时,valid_lens到了这里:
class DotProductAttention(nn.Module):
"""Scaled dot product attention."""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# Shape of `queries`: (`batch_size`, no. of queries, `d`)
# Shape of `keys`: (`batch_size`, no. of key-value pairs, `d`)
# Shape of `values`: (`batch_size`, no. of key-value pairs, value
# dimension)
# Shape of `valid_lens`: (`batch_size`,) or (`batch_size`, no. of queries)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# Set `transpose_b=True` to swap the last two dimensions of `keys`
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
self.attention_weights = masked_softmax(scores, valid_lens),
此时其形状 还是torch.Size([256]);
def masked_softmax(X, valid_lens):
"""Perform softmax operation by masking elements on the last axis."""
# `X`: 3D tensor, `valid_lens`: 1D or 2D tensor
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape #XDotProductAttention中的scores,表示单头注意力的分数。shape: torch.Size([256, 10, 10])
if valid_lens.dim() == 1: #若为1维【3,4,5,4,3】这样,长度为256;
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
#则需要扩增shape[1]倍,也就是序列长度倍num_steps. 若为自注意力,确实应该是每个单词都占一行,
#按理说,过程是这样的:[256]变成[256,10],然后经历else中的过程变为[2560]。 [256]变成[2560]。
#编码器过程中,用【3,4,5,4,3】这样直接复制10份,是因为每一个3都表示:第i行对其他值的注意力程度。每一行都代表一个单词,所以每个单词都
#对应着一样的长度序列,也就是这句完成的话,这里就是复制了10个3,[3*10]里这都表示的是对一个句子里的单词的注意力。至于为什么是10不是3,为
#了处理方便吧;但在mask时会把第3行之后的都mask掉。
else: #【1】进入这里
valid_lens = valid_lens.reshape(-1) # [256,10] 变为[2560] #这是由于,decoder的valid_lens生成的时候就是矩阵那样生成的。[1,2,..10],[1,2..,10]这样,所以每一个刚刚好对应了10步。表示了[1,2,..10]中,预测的第一条单词只对1前的输入有注意力,所以也是一样的:第i行对所有的其他单词的注意力,但此时不能往后看;所以分别为[1,2,..10]。这里一个[1,2,..10]表示的是第i个单词对一个句子里的单词的注意力,相当于query_key乘积的scores的scores[i]第i行,因此每一个值scores[i][j](如为3)表示这一行能看多少个有效单词。
# On the last axis, replace masked elements with a very large negative
# value, whose exponentiation outputs 0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)# 对X [256, 10, 10]变为[2560,10],对其无效的位置填充上-1e6
return nn.functional.softmax(X.reshape(shape), dim=-1) #填完后,恢复[256, 10, 10],之后对最后一维softmax
注释1:
def sequence_mask(X, valid_len, value=0):
"""Mask irrelevant entries in sequences."""
maxlen = X.size(1) # 10
mask = torch.arange((maxlen), dtype=torch.float32, #
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
part1
【1】而decoder的forward函数中定义了dec_valid_lens的求法,它是使用repeat函数,将repeat的参数[1,..,10]作为元素t,扩充为形状为(batch_size,1)的矩阵,[[t],[t]];
因此dec_valid_lens维度变为(64,10),具体的,就是[[1,2,3,..10],..,[1,2,..,10]]:
dec_valid_lens = torch.arange(1, num_steps + 1,
device=X.device).repeat(
batch_size, 1) #<BOS>平移; 按时间步mask,dec_valid_lens 输出见下 batchsz=64 num_steps=10
与part0相同,注意Mulitiheadattention的forward函数中,X的这个过程:把dim裂开维(num_heads,dim);然后num_heads提前、和batchsz合并,num_heads=4,故X变成了(256,10,8)。
在Mulitiheadattention的过attention之前,valid_lens也扩增了头数:
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for
# `num_heads` times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
此时,由于在dim0上操作,valid_lens的维度:(64,10)就变为 [256,10]。【因为在dim0上复制num_heads=4次】
valid_lens在这里为 torch.Size([256, 10]),继续看下面的函数。
def masked_softmax(X, valid_lens):
"""Perform softmax operation by masking elements on the last axis."""
# `X`: 3D tensor, `valid_lens`: 1D or 2D tensor
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape #XDotProductAttention中的scores,表示单头注意力的分数。shape: torch.Size([256, 10, 10])
if valid_lens.dim() == 1: #若为1维【3,4,5,4,3】这样,长度为256;
valid_lens = torch.repeat_interleave(valid_lens, shape[1]) #则需要扩增shape[1]倍,也就是序列长度倍num_steps. 若为自注意力,确实应该是每个单词都占一行,
#按理说,过程是这样的:[256]变成[256,10],然后经历else中的过程变为[2560]。 [256]变成[2560]。
#编码器过程中,用【3,4,5,4,3】这样直接复制10份,是因为每一个3都表示:第i行对其他值的注意力程度。每一行都代表一个单词,所以每个单词都对应着一样的长度序列,也就是这句完成的话,这里就是复制了10个3,[3*10]里这都表示的是对一个句子里的单词的注意力。至于为什么是10不是3,为了处理方便吧;但在mask时会把第3行之后的都mask掉。
else: #【1】进入这里
valid_lens = valid_lens.reshape(-1) # [256,10] 变为[2560] #这是由于,decoder的valid_lens生成的时候就是矩阵那样生成的。[1,2,..10],[1,2..,10]这样,所以每一个刚刚好对应了10步。表示了[1,2,..10]中,预测的第一条单词只对1前的输入有注意力,所以也是一样的:第i行对所有的其他单词的注意力,但此时不能往后看;所以分别为[1,2,..10]。这里一个[1,2,..10]表示的是第i个单词对一个句子里的单词的注意力,相当于query_key乘积的scores的scores[i]第i行,因此每一个值scores[i][j](如为3)表示这一行能看多少个有效单词。
# On the last axis, replace masked elements with a very large negative
# value, whose exponentiation outputs 0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)# 对X [256, 10, 10]变为[2560,10],对其无效的位置填充上-1e6
return nn.functional.softmax(X.reshape(shape), dim=-1) #填完后,恢复[256, 10, 10],之后对最后一维softmax
注释1:
def sequence_mask(X, valid_len, value=0):
"""Mask irrelevant entries in sequences."""
maxlen = X.size(1) # 10
mask = torch.arange((maxlen), dtype=torch.float32, #这里注释1,它只会
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
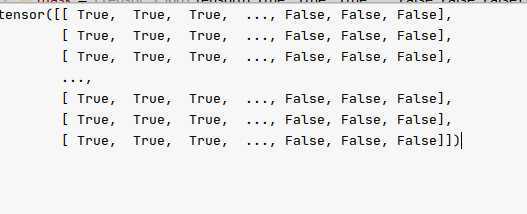
torch.arange((maxlen))=[1,2,..,10]
[[0,1,2,..,9]]<[[1],[2],..,[10]]得到的就是主对角线(不包含包含)以上的右上半角全为False,主对角线(包含)以下全为True的下三角矩阵。这样,上三角(不含对角线)全为-1e6。softmax后全为0。
合理!因为第i行能看到第i个输入。如第0行表示,第0个单词能看到(且只能看到)句子中第0个token
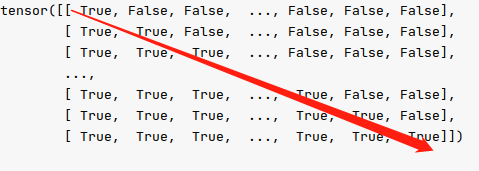
但是这里是否有漏洞?最后一行的最后几个字符就一定不是padding的吗?不是吧。
所以应该再用encoder的valid_lens再过一层mask。取两者的交集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号