sklearn中的分词函数countVectorizer()的改动--保留长度为1的字符串
1简述问题
使用countVectorizer()将文本向量化时发现,文本中长度唯一的字符串会被自动过滤掉,这对于我在做的情感分析来讲,一些表较重要的表达情感倾向的词汇被过滤掉,比如文本'没用的东西,可把我可把我坑的不轻,越用越觉得这个手机真的废'。
用结巴分词的精确模式分词,然后我用空格连接这些分词得到的句子是:
'没用 的 东西 , 可 把 我 可 把 我 坑 的 不轻 , 越用 越 觉得 这个 手机 真的 废'
代码如下:
def cut_word(sent):
line=re.sub(r'[a-zA-Z0-9]*','',sent)
wordList=jieba.lcut(line)
#print(wordList)
return ' '.join(wordList)
vec= CountVectorizer(min_df=1)
c='没用的东西,可把我可把我坑的不轻,越用越觉得这个手机真的废'
cut=cut_word(c)
然后用countVectorizer()对这个分好词的句子进行向量化发现,一个字的词都被过滤掉了:
['不轻', '东西', '手机', '没用', '真的','越用']
代码如下:
vec.fit_transform([cut]) vec.get_feature_names()
他把最能表达情感倾向的词“坑”,‘废’给过滤掉了,这对于向量化后的句子特征就损失了很多的信息。我认为因为这个库的函数原本就是为了英文分词的,而英文长度为1 的词是26个字母,并不会表示什么重要含义,所以在编写这个函数时自动就给这些长度低于2的单词给去掉了。但是中文可不一样,一个字的意义可以有非常重要的含义。对于我们分类不重要的词,比如一些代词“你”,‘我’,‘他’等其他经常出现的词,可以用停用词表给过滤掉,这个countVectorizer()就自带了一个组停用词的参数,stop_words,这个停用词是个列表包含了要去掉的停用词,我们可以针对自己需要自定义一个停用词表。当stop_words=‘english’时,函数会自动为英文文本分词去除停用词。中文都是自己自定义。
2解决方法
我是找了源代码,这个函数在sklearn包的feature_exceration文件夹中text.py。
找到了打开文件,找到了CountVectorizer()的代码,定位到fit_transform(raw_documents)中关于词汇表对于原始文本进行处理的地方

看见vocabulary这是包含所有分词的字典,再定位到_cout_vocab()函数位置,

看见raw_vocabulary了,796行是对特征(分词)进行计数的放到字典feature_counter中。doc是原始文本的每行文本,这利用analyze()处理,再往回找
analyze = self.build_analyzer(),可再往上找self.build_analyzer()函数,
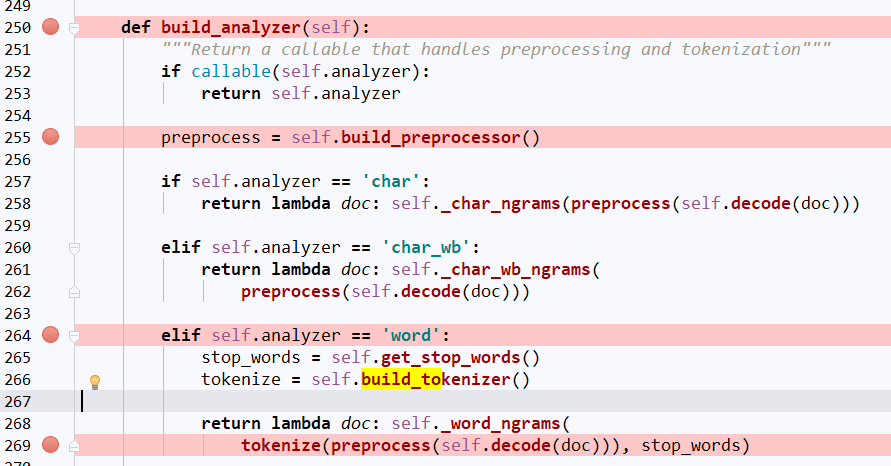
我们主要找的是对文本进行处理的函数,所以找的就是出现文本,且对文本进行操作的函数。定位到264行,根据countVectorizer()的初始定义self.analyzer的默认值是‘word’,所以
self.build_analyzer()函数默认情况下是跳到这里对文本dco进行操作。再看看preprocess()和tokenize()

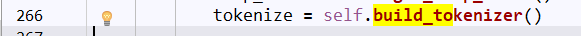
找到self.build_preprocessor()看一下知道是对文本的编码格式以及大小写的操作,对文本预处理的函数。
重点到self.bulid_tokenizer(),看名字就是知道是分词函数了。

这是我该过的,#原句是 return lambda doc: token_pattern.findall(doc),是根据正则表达式token_patten来从文本doc中找到符合正则表达式的所有分词,可见问题出在这里,再回到原文本countVectorizer()定义的正则表达式。

#原句token_patten=u'(?u)\b\w\w+\b',水平太菜不太看懂这个表达式,反正试了一下,这个表达式真的会过滤掉字符长度为1的字符串,我就改了一下正则表达式。因为待分的文本都是分词好且用空格连起来的字符串,所以用郑子表达式空格作为切分文本的标记。
所以总的来说就是改了两个点
(1)CountVectorizer中将默认的正则表达式u'(?u)\b\w\w+\b'改为r"\s+:即token_pattern=r"\s+"
(2)self.build_tokenizer()中fiandall()替换成split(),即return lambda doc: token_pattern.split(doc)
3.测试
结合自己定义的停词表,去掉没用的词,再试一下分词效果:
原来分词效果:
['不轻', '东西', '手机', '没用', '真的','越用']
更改过后效果:
['不轻', '东西', '坑', '废', '手机', '没用', '真的', '越', '越用']
可见,长度为1的重要情感词,'坑', '废',得到了保留。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号