
DeepSeek LLM
作者前言:
DeepSeek系列现在非常火,笔者决定主要梳理DeepSeekzui最重要的四代版本:
DeepSeek-LLM; DeepSeek-V2; DeepSeek-V3; DeepSeek-R1 敬请期待。
一、背景动机
-
开源社区的关注点:LLaMA 之后,开源社区主要关注训练固定规模的高质量 LLM(如 7B、13B、34B 和 70B),而对 LLM 的缩放定律研究探索较少。
-
缩放定律的重要性:当前开源 LLM 仍处于 AGI 发展的初期阶段,因此研究扩展定律对于未来发展至关重要。
-
缩放结论的分歧:早期研究(Hoffmann 等人,2022 年;Kaplan 等人,2020 年)对计算预算增长时的模型和数据扩展提出了不同的结论,并未充分解决超参数的影响。
-
研究目标:本研究广泛探索 LLM 的缩放行为,主要应用于 7B 和 67B 规模的模型,以奠定开源 LLM 未来扩展的基础。
-
关键研究内容:
- 研究 batch size 和 learning rate 随模型规模的缩放规律,发现其趋势。
- 研究数据和模型规模的缩放关系,揭示最佳的模型/数据扩展分配策略,并预测大规模模型的性能。
- 发现不同数据集的缩放定律存在显著差异,表明数据选择对缩放行为影响较大,在跨数据集推广缩放定律时需谨慎。
二、做了什么
- 收集 2 万亿个代币进行预训练,主要使用中文和英文。
- 在模型层面,我们通常遵循 LLaMA 的架构,但用多步学习率调度器取代了余弦学习率调度器,在保持性能的同时促进持续训练。
- 从不同来源收集了超过 100 万个实例用于监督微调 (SFT) (Ouyang et al., 2022)。
- 分享在数据消融技术中不同 SFT 策略和发现的经验
- 利用直接偏好优化 (DPO) (Rafailov et al., 2023) 来提高模型的对话性能。
三、预训练
主要目标: 全面增强数据集的丰富性和多样性
3.1 数据预处理
方法分为三个基本阶段:重复数据删除、过滤和重新混合。
其中,重复数据删除和重新混合阶段通过对唯一实例进行采样来确保数据的多样化表示。过滤阶段提高了信息的密度,从而实现了更高效和有效的模型训练。
重复数据删除
扩大了重复数据删除的范围。因为与在单个转储中删除重复数据相比,对整个 Common Crawl 语料库进行重复数据删除可以提高重复实例的删除率。表 1 表明,与 91 个转储相比,在 91 个转储中消除重复数据删除的文档数量是单个转储方法的四倍。
Note: "转储"(dump) 指的是某个时间点抓取到的完整网页数据的存储文件。例如,Common Crawl 定期抓取互联网上的大量网页,并将这些数据存储在不同时间的快照(转储,dump)中。
单个转储(Single Dump)指的是某次抓取的完整网页数据快照。例如:
2023 年 1 月的 Common Crawl 数据 → 这是一个单独的转储
2023 年 7 月的 Common Crawl 数据 → 这是另一个独立的转储
传统去重方法 主要在单个转储内部执行,即在同一次抓取的数据范围内查找并删除重复的内容。

过滤
在过滤阶段,我们专注于为文档质量评估制定稳健的标准。这涉及结合语言和语义评估的详细分析,从个人和全局角度提供数据质量视图。
重新混合
在重新混合阶段,我们调整了解决数据不平衡的方法,专注于增加代表性不足的域的存在。这项调整旨在实现更加平衡和包容的数据集,确保充分代表不同的观点和信息。
3.2 分词器 (Tokenizer) 设计与实现
实现了基于 Huggingface tokenizers 库 的 BBPE(Byte-level Byte Pair Encoding) 算法(详见;我的另一篇博客:https://www.cnblogs.com/zz-w/p/18696566),预分词策略与 GPT-2 相似,主要特点如下:
1. 预分词(Pre-tokenization)
目的:防止来自不同字符类别的 token 进行合并,提高分词合理性。
- 防止新行、标点符号和 CJK(中文-日语-韩语)字符合并
例如:"你好,world!"- 无预分词 可能会生成错误的 token,如
["你好", ",world", "!"](错误合并) - 使用预分词,确保
["你好", ",", "world", "!"](正确拆分)4
- 无预分词 可能会生成错误的 token,如
Note: GPT-2中的预分词
浏览huggingface 的 transformers v4.30.2 里 GPT2Tokenizer 源码(https://huggingface.co/transformers/v3.0.2/_modules/transformers/tokenization_gpt2.html#GPT2Tokenizer),可发现GPT2tokenizer.init 中设置了以下正则表达式变量self.pat,它是用来做预分词处理的(pre-tokenizer)
self.pat 定义如下
import regex as re
# Should have added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
注意这个是 re 是 regex 库而不是 re 库,regex 支持 ?\p 这类更复杂的正则表达式。
`'s|'t|'re|'ve|'m|'ll|'d`:这部分匹配常见的英文缩写和所有格形式,如 `'s`, `'t`, `'re`, `'ve`, `'m`, `'ll`, `'d`(例如,matches `it's`, `don't`, `they're`, `I've`, `I'm`, `we'll`, `I'd`)。
`?\p{L}+`:这部分使用 Unicode 属性匹配一个或多个任意语言的字母。`\p{L}` 匹配任何语言的字母字符。可选的前导空格由 `?` 表示。
`?\p{N}+`:类似地,这部分匹配一个或多个数字。`\p{N}` 匹配任何数字字符。数字前面的空格是可选的。
`?[^\s\p{L}\p{N}]+`:这部分匹配任何不是空格、字母或数字的字符序列。这可能包括标点符号、特殊字符等。字符序列前的空格是可选的。
`\s+(?!§)`:这个部分稍微复杂一些。`\s+` 匹配一个或多个空白字符,`(?!§)` 是一个负向前瞻断言,确保后面不跟着非空白字符。这样的组合意味着它匹配字符串末尾的空白字符。
`\s+`:匹配一个或多个空白字符。
总的来说,这个正则表达式设计用于匹配包括缩写、单词、数字、特殊符号和某些空白字符在内的多种模式。它似乎用于某种形式的文本处理或分词任务,可能是在自然语言处理的上下文中。使用 `re.findall(self.pat, text)` 将返回给定文本中所有匹配这些模式的子串的列表。
- 数字拆分为单个字符
2024 → ["2", "0", "2", "4"]- 这样有助于模型更好地处理数字,而不是将整个数字作为一个 token。
2. 词汇表设计
- 训练数据:分词器在 约 24GB 的多语言语料库 上进行训练,以适应不同语言的文本处理需求。
- 词汇表规模:
- 常规 token 数量:100,000
- 额外增加 15 个特殊标记(例如
[PAD],[UNK],[CLS],[SEP]等),使最终词汇表达到 100,015。 - 训练时词汇表大小配置为 102,400,确保训练期间的计算效率并为将来可能需要的任何其他特殊标记预留空间。
3.3 模型结构
DeepSeek LLM基本上遵循LLaMA的设计,DeepSeek LLM 采用了 Pre-Norm 结构,即在主要变换之前对输入进行归一化。这有助于稳定训练并提高收敛性。使用了SwiGLU作为Feed-Forward Network(FFN 的激活函数,FFN 的中间层维度设置为
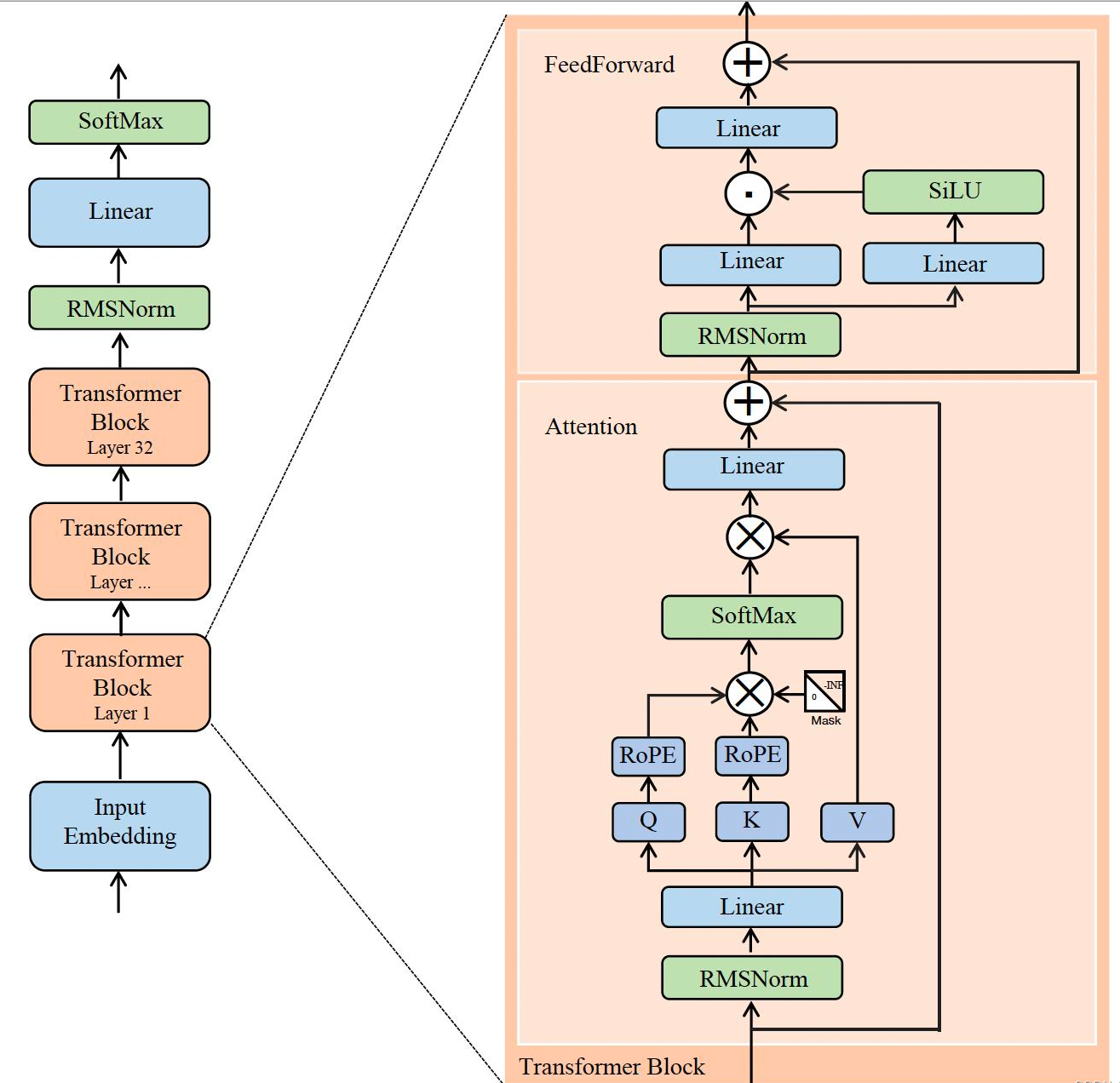
在宏观设计方面,DeepSeek LLM略有不同。DeepSeek LLM 7B是一个30层的网络,DeepSeek LLM 67B有95层。这些层调整在保持与其他开源模型参数一致的同时,也有助于优化训练和推理的模型管道划分。
与大多数使用分组查询注意力(GQA)的模型不同,deepseek扩大了67B模型的参数网络深度,而不是常见的拓宽FFN层中间宽度的做法,旨在获得更好的性能。详细的网络规格可以在表2中找到。

3.4 超参数
本文作者:AAA建材王师傅
本文链接:https://www.cnblogs.com/zz-w/p/18696425
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步