Lecture 1 NN,KNN
INT305 Machine Learning
Lecture 1
Outline of this course
·Suprevised Learning
Nearest Neighbors 近邻
Decision Trees 决策树
Ensembles 集成学习
Linear Regression 线性回归
Logistic Regression 逻辑回归
Neural Networks 神经网络
SVMs 支持向量机
·Unsuprevised Learning
K-means
Mixture models
·Basic of Reinforcement Learning
Nearest Neighbors
用于解决Regression(回归)问题:taget(label) 是实数
用于解决Classification(分类)问题:taget(label) 是离散集的一个元素
近年来,taget(label) 常常是一个高度结构化的对象(如图片image)
·Input Vectors:实例特征向量
·计算距离(常用欧几里得距离或者曼哈顿距离)
找到距离向量x最近的实例向量,然后复制它的标签
·决策边界(Decision boundary)
我们可以通过Voronoi diagram(多边形)对分类进行可视化
最近邻分类器(NN)的优点:
不需要为训练集建立模型。
最近邻分类器可以生成任何形状的决策边界。
最近邻分类器的缺点:
容易受到噪声的影响。(NN sensitive to noise or mis-labeled data(class noise))
往往需要对训练集进行预处理才能使用。
每一次分类耗时长。
k-Nearest Neighbors k-近邻算法
k的选取
·Small k
good at capturing fine-grained(细粒度)patterns
may overfit,i.e. be sensitive to random idiosyncrasies in the training data 可能过拟合,即对训练数据中的随机特性敏感
·Large k
makes stabel predictions by averaging over lots of examples
may underfit,i.e. fail to capture important regularities
·Balance k
Optimal choice of k depends on number of data points n.c
Nice theoretical properties if k-->∞ and k/n-->0
Rule of thumb(经验): choose k < √n
We can choose k using validation set
we would like our algorithm to generalize to data it hasn't seen before.
我们希望我们的算法能够推广到以前从未见过的数据.
We can measure the genaralization error(泛化误差)(error rate on new examples)using a test data.
k 是一个超参数,不能作为算法学习的一部分
我们可以使用验证集(validation set)调优超参数
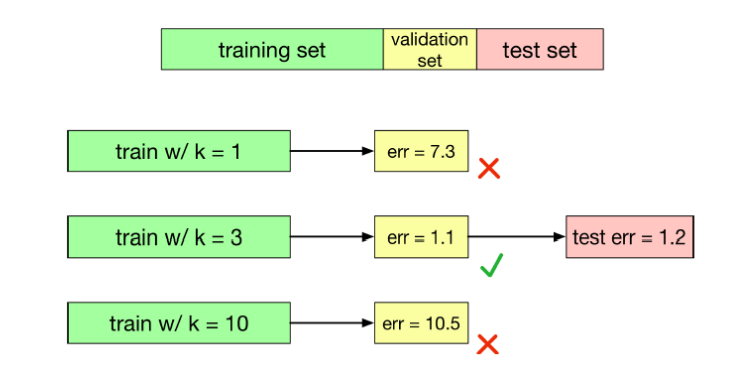
测试集只在最后使用,用来度量最终配置的泛化性能。
Conclusions
Simple algorithm that does all its work at test time - in a sense, no learning
Can control the complexity by varifying k
Suffers from the Curse of Dimensionality*
补充:
对k-近邻算法的说明
按距离加权的k-近邻算法是一种非常有效的归纳推理方法。它对训练数据中的噪声有很好的鲁棒性,而且当给定足够大的训练集合时它也非常有效。注意通过取k个近邻的加权平均,可以消除孤立的噪声样例的影响。
问题一:近邻间的距离会被大量的不相关属性所支配。
应用k-近邻算法的一个实践问题是,实例间的距离是根据实例的所有属性(也就是包含实例的欧氏空间的所有坐标轴)计算的。这与那些只选择全部实例属性的一个子集的方法不同,例如决策树学习系统。
比如这样一个问题:每个实例由20个属性描述,但在这些属性中仅有2个与它的分类是有关。在这种情况下,这两个相关属性的值一致的实例可能在这个20维的实例空间中相距很远。结果,依赖这20个属性的相似性度量会误导k-近邻算法的分类。近邻间的距离会被大量的不相关属性所支配。这种由于存在很多不相关属性所导致的难题,有时被称为维度灾难(curse of dimensionality*)。最近邻方法对这个问题特别敏感。
解决方法:当计算两个实例间的距离时对每个属性加权。
这相当于按比例缩放欧氏空间中的坐标轴,缩短对应于不太相关属性的坐标轴,拉长对应于更相关的属性的坐标轴。每个坐标轴应伸展的数量可以通过交叉验证的方法自动决定。
问题二:应用k-近邻算法的另外一个实践问题是如何建立高效的索引。因为这个算法推迟所有的处理,直到接收到一个新的查询,所以处理每个新查询可能需要大量的计算。
解决方法:目前已经开发了很多方法用来对存储的训练样例进行索引,以便在增加一定存储开销情况下更高效地确定最近邻。一种索引方法是kd-tree(Bentley 1975;Friedman et al. 1977),它把实例存储在树的叶结点内,邻近的实例存储在同一个或附近的结点内。通过测试新查询xq的选定属性,树的内部结点把查询xq排列到相关的叶结点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号