
Hive ORC File Format
背景
早在2013年1月,ORC(Optimized Row Columnar)出现,作为大规模加速Apache Hive和提高存储在Apache Hadoop中的数据的存储效率的计划的一部分。重点是为了提升处理速度和减小文件占用磁盘大小。
目前有很多公司已经大规模使用ORC了,比如Facebook 在数仓中使用ORC格式存储数十PB的数据,并且验证了ORC明显快于RC文件和Parquet
ORC File文件结构
如下图所示,可以看到ORC File被分成一个个的stripe,在file footer里面包含了该ORC File文件中stripes的元数据信息,比如每个stripe中有多少行,以及每列的数据类型。
ORC File还包含了一些轻量级的索引,读取ORC数据时候就可以使用这些index来判断在一个file中哪些stripes需要被读取,并且可以将查询范围缩小到10000行的集合;实现原理是在ORC中,每个file/每个stripe/每10000行,都有索引来记录该数据范围内每列最大最小值等统计信息,所以可以很容易的根据查询条件判断是否需要读取相应的file/stripe/10000行数据,从而实现Predicate Pushdown
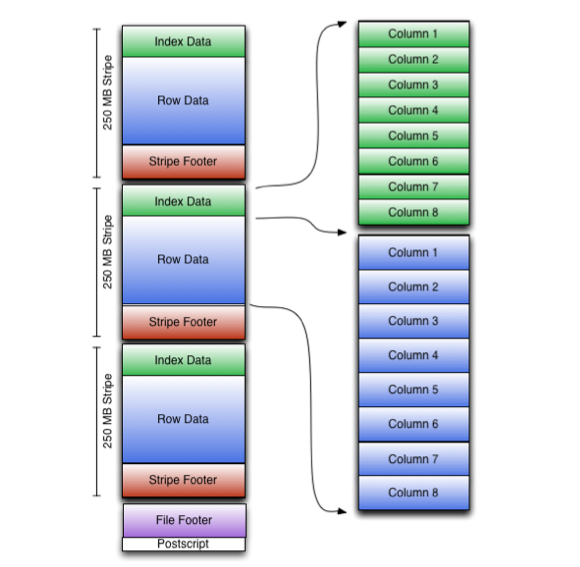
Stripe结构
stripes之间是相互独立的,通常被不同的任务并行处理。每个Stripe都有3个部分:index集合、数据本身以及stripe footer;
stripe footer包含了每个列的编码以及流位置的目录
row data存储数据,列式存储。
Index data包含每列的最大和最小值以及每列所在的行。行索引里面提供了偏移量,它可以跳到正确的压缩块位置。使得在stripe中快速读取的过程中可以跳过很多行,尽管这个stripe的大小很大。在默认情况下,最大可以跳过10000行
详细可以参考:
更高的压缩比,更好的性能–使用ORC文件格式优化Hive
Hive性能优化之ORC索引–Row Group Index vs Bloom Filter Index
在Hive中使用ORC
1.创建一个orc表
CREATE TABLE ksw ( name STRING, color STRING ) STORED AS ORC;
2.修改一个已存在的表为ORC格式
ALTER TABLE ksw SET FILEFORMAT ORC;
3.从Hive 0.14开始,如果表(或分区)中存在很多小的orc文件,还可以执行命令来合并小orc文件,这些文件将在stripe级别合并,而不需要重新序列化。
ALTER TABLE ksw [PARTITION partition_spec] CONCATENATE;
4.使用orcfiledump命令来获取ORC文件的信息
% hive --orcfiledump <path_to_file>
5.从Hive 1.1开始,获取ORC文件的信息使用如下
% hive --orcfiledump -d <path_to_file>
orc表相关属性配置
| KEY | DEFAULT | NOTES |
|---|---|---|
| orc.compress | ZLIB | high level compression = {NONE, ZLIB, SNAPPY} |
| orc.compress.size | 262,144 | compression chunk size |
| orc.stripe.size | 67,108,864 | memory buffer in bytes for writing |
| orc.row.index.stride | 10,000 | number of rows between index entries |
| orc.create.index | true | create indexes? |
| orc.bloom.filter.columns | ”” | comma separated list of column names |
| orc.bloom.filter.fpp | 0.05 | bloom filter false positive rate |
比如创建一个不启用压缩的orc表
CREATE TABLE ksw ( name STRING, color STRING ) STORED AS ORC TBLPROPERTIES ("orc.compress"="NONE");

