
CAP Theorem
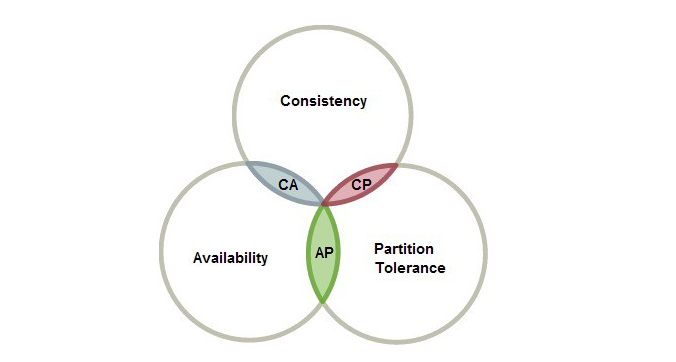
Consistency

一致性是指 “all nodes see the same data at the same time.”
简单地说,执行读操作将返回最近的写操作的值,从而保证所有节点返回相同的数据。
比如在图中,在1:02时将数据record更新为Bulbasaur,在1:03时候record又被更新为Pikachu,我们在第三个节点上进行访问时,输出是最新的“Pikachu”。但是,节点之间需要时间进行更新数据,而在更新时经常会受到网络的影响。
对于一致性,可以分为从客户端和服务端两个不同的视角。
-
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。
-
从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
Availability
可用性是指 every request gets a response on success/failure. 即服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是,该系统使用的任何算法必须最终终止。当同时要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求必须终止。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
Partition Tolerance
分区容错性是指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,或者是机器之间有网络异常,将分布式系统分隔未独立的几个部分,各个部分还能维持分布式系统的运作,这样就具有好的分区容错性。
CAP的证明
如上图,是我们证明CAP的基本场景,网络中有两个节点N1和N2,可以简单的理解N1和N2分别是两台计算机,他们之间网络可以连通,N1中有一个应用程序A,和一个数据库V,N2也有一个应用程序B2和一个数据库V。现在,A和B是分布式系统的两个部分,V是分布式系统的数据存储的两个子数据库。
在满足一致性的时候,N1和N2中的数据是一样的,V0=V0。在满足可用性的时候,用户不管是请求N1或者N2,都会得到立即响应。在满足分区容错性的情况下,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。
如上图,是分布式系统正常运转的流程,用户向N1机器请求数据更新,程序A更新数据库Vo为V1,分布式系统将数据进行同步操作M,将V1同步的N2中V0,使得N2中的数据V0也更新为V1,N2中的数据再响应N2的请求。
这里,可以定义N1和N2的数据库V之间的数据是否一样为一致性;外部对N1和N2的请求响应为可用行;N1和N2之间的网络环境为分区容错性。这是正常运作的场景,也是理想的场景,然而现实是残酷的,当错误发生的时候,一致性和可用性还有分区容错性,是否能同时满足,还是说要进行取舍呢?
作为一个分布式系统,它和单机系统的最大区别,就在于网络,现在假设一种极端情况,N1和N2之间的网络断开了,我们要支持这种网络异常,相当于要满足分区容错性,能不能同时满足一致性和响应性呢?还是说要对他们进行取舍。
假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1,由于网络是断开的,所以分布式系统同步操作M执行失败,所以N2中的数据依旧是V0;这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?有二种选择,第一,牺牲数据一致性,响应旧的数据V0给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1。
这个过程,证明了要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其中一个。
HDFS对于CAP原理是取舍了哪个?
从HDFS写数据的角度来说, 对于A和P和C都有取舍.
HDFS写数据是通过pipeline的方式来进行的, 粗略说, 就是设HDFS的数据都有N=3个副本, 开始写数据时, NameNode会制定3个data node, 分别作为这3个副本的存储机器, 然后这3个机器通过socket串接在一起. 这里还有个"最小写副本数"的概念, 设这个值为MinN, 意思就是说, 当写成功MinN个副本, 就认为写成功了, 然后HDFS内部再会在后台异步将这个副本同步到其他的N - MinN个机器上, 最终形成N个副本.
那么回到开头, 为什么说HDFS其实对于A和P和C都会有取舍呢?
-
如果MinN设为1, 那么其实就是牺牲了P; 因为这种情况下如果有写操作, pipeline管道只有1个data node, 写成功后, hdfs如果在同步这个副本到其他data node的过程中, 有这个block的data node坏掉了, 那么这个单副本的block数据就等于永久丢失了. 相当于无法保证P.
-
如果1 < MinN <= N, 比如MinN == N == 3, 那么这种情况下, pipeline管道中有3个data node都建立连接, 必须要同时写成功3个data node才会算作写成功, 在3个副本任一个副本没有确认写成功前, 写入的流数据(注意, 也是按照流数据, 将数据分做一个一个packet, 依次写入3个data node), 是无法被外部其他Client看到的, 这相当于牺牲了A.
-
最后说说, 为什么说也会牺牲C呢? 每个连入piepine的data node, 其正在被写入的block, 会记录一个当前已确认写入的数据的offset, 我们叫它ackOffset. 这个ackOffset, 决定了当有Client来本dataNode读取数据时, 可以返回给读Client能够读取的数据边界. ackOffset是如何确定的呢? 处于pipeline的最后一个data node, 将数据写入后(我记得不一定会flush磁盘到磁盘, 需要分场景), 更新当前自己的ackOffset, 然后会发送一个ack给它上游的data node; 上游data node收到这个ack后, 才会也更新自己的ackOffset, 然后同样发个ack给自己的上游data node.这个过程虽然很快, 但是理论上也会出现, 当ack在多个data node的pipeline中传递的过程中, 不同的Client读取不同的datanode, 导致读取的数据不一致的问题, 虽然概率会很小, 因为ack的传递会比较快.
另外, hdfs设计为, 同一个block,同时只能有一个写Client, 相当于将这个block租给某一个client,这个就是lease租约机制; 这种情况下, 相当于牺牲了A(因为其他写Client不能进行), 得到了C(只有一个Client写, 所以对于写来说强一致性, 读仍是上面那一大段), 也得到了P.
我认为, 当前的分布式系统, C主要指的是多个读如何做到一致性, 所以如果想做到强一致性, 那么只有写操作完全完成后, 才能让读操作看到,这样就相当于牺牲了A, 而保证了C强一致性. paxos等算法我想就是这个原理.
巨人的肩膀:
https://towardsdatascience.com/cap-theorem-and-distributed-database-management-systems-5c2be977950e

