

Flink on yarn以及实现jobManager 高可用(HA)
on yarn:https://ci.apache.org/projects/flink/flink-docs-release-1.8/ops/deployment/yarn_setup.html
flink on yarn两种方式
第一种方式:yarn session 模式,在yarn上启动一个长期运行的flink集群
使用 yarn session 模式,我们需要先启动一个 yarn-session 会话,相当于启动了一个 yarn 任务,这个任务所占用的资源不会变化,并且一直运行。我们在使用 flink run 向这个 session 任务提交作业时,如果 session 的资源不足,那么任务会等待,直到其他资源释放。当这个 yarn-session 被杀死时,所有任务都会停止。
把yarn和hdfs相关配置文件拷贝到flink配置目录下,或者直接指定yarn和hdfs配置文件对应的路径
export HADOOP_CONF_DIR=/root/flink-1.8.2/conf
cd flink-1.8.2/ ./bin/yarn-session.sh -jm 1024m -tm 4096m -s 16
-jm:jobmanager的内存,-tm:每个taskmanager的内存,-s:the number of processing slots per Task Manager
日志如下
[root@master01 flink-1.8.2]# ./bin/yarn-session.sh -jm 1024m -tm 4096m -s 16 2019-12-10 10:05:40,010 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, master01.hadoop.xxx.cn 2019-12-10 10:05:40,012 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 6123 2019-12-10 10:05:40,012 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m 2019-12-10 10:05:40,012 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.heap.size, 1024m 2019-12-10 10:05:40,012 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: taskmanager.numberOfTaskSlots, 1 2019-12-10 10:05:40,012 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: parallelism.default, 1 2019-12-10 10:05:40,067 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2019-12-10 10:05:40,399 INFO org.apache.flink.runtime.security.modules.HadoopModule - Hadoop user set to root (auth:SIMPLE) 2019-12-10 10:05:40,459 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at master01.hadoop.xxx.cn/xxx.xx.x.xxx:8032 2019-12-10 10:05:40,634 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=4096, numberTaskManagers=1, slotsPerTaskManager=16} 2019-12-10 10:05:40,857 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2019-12-10 10:05:40,873 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/root/flink-1.8.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them. 2019-12-10 10:05:42,434 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1570496850779_0463 2019-12-10 10:05:42,457 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1570496850779_0463 2019-12-10 10:05:42,457 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated 2019-12-10 10:05:42,458 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED 2019-12-10 10:05:46,234 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully. 2019-12-10 10:05:46,597 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started. Flink JobManager is now running on worker03.hadoop.xxx.cn:38055 with leader id 00000000-0000-0000-0000-000000000000. JobManager Web Interface: http://worker03.hadoop.xxx.cn:38055
查看web界面可以直接到yarn界面查看,也可以通过日志中给出的jobmanager界面查看

提交任务测试,提交任务使用./bin/flink
cd flink-1.8.2/ ./bin/flink run ./examples/batch/WordCount.jar
日志如下:
[root@master01 flink-1.8.2]# ./bin/flink run ./examples/batch/WordCount.jar 2019-12-10 11:01:43,553 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2019-12-10 11:01:43,553 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - Found Yarn properties file under /tmp/.yarn-properties-root. 2019-12-10 11:01:43,785 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 16 2019-12-10 11:01:43,785 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - YARN properties set default parallelism to 16 YARN properties set default parallelism to 16 2019-12-10 11:01:43,812 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at master01.hadoop.xxx.cn/xxx.xx.x.211:8032 2019-12-10 11:01:43,904 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2019-12-10 11:01:43,904 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2019-12-10 11:01:43,956 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Found application JobManager host name 'worker02.hadoop.xxx.cn' and port '39095' from supplied application id 'application_1570496850779_0467' Starting execution of program Executing WordCount example with default input data set. Use --input to specify file input. Printing result to stdout. Use --output to specify output path. (a,5) (action,1) (after,1) (against,1) (all,2) ......
问题:在提交flink任务时候,flink是怎么找到对应的集群呢?
看日志高亮部分,查看/tmp/.yarn-properties-root文件内容
[root@master01 flink-1.8.2]# more /tmp/.yarn-properties-root #Generated YARN properties file #Tue Dec 10 10:40:29 CST 2019 parallelism=16 dynamicPropertiesString= applicationID=application_1570496850779_0467
这个applicationID不就是我们提交到yarn上flink集群对应的id嘛。
到flink web ui查看任务记录

此外,在启动on yarn flink集群时候可以使用-d or --detached实现类似后台运行的形式执行,此方式下,如果想停止集群,使用yarn application -kill <appId>
第二种方式:Run a single Flink job on YARN
上面第一种方式是在yarn上启动一个flink集群,然后提交任务时候向这个集群提交。此外,也可以在yarn上直接执行一个flink任务,有点类似spark-submit的感觉。
[root@master01 flink-1.8.2]# ./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
日志:
2019-12-10 11:44:56,912 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at master01.hadoop.xxx.cn/xxx.xx.x.xxx:8032 2019-12-10 11:44:57,004 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2019-12-10 11:44:57,004 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar 2019-12-10 11:44:57,101 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1024, numberTaskManagers=1, slotsPerTaskManager=1} 2019-12-10 11:44:57,379 WARN org.apache.flink.yarn.AbstractYarnClusterDescriptor - The configuration directory ('/root/flink-1.8.2/conf') contains both LOG4J and Logback configuration files. Please delete or rename one of them. 2019-12-10 11:45:01,058 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Submitting application master application_1570496850779_0470 2019-12-10 11:45:01,093 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1570496850779_0470 2019-12-10 11:45:01,093 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Waiting for the cluster to be allocated 2019-12-10 11:45:01,094 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - Deploying cluster, current state ACCEPTED 2019-12-10 11:45:05,621 INFO org.apache.flink.yarn.AbstractYarnClusterDescriptor - YARN application has been deployed successfully. Starting execution of program Executing WordCount example with default input data set. Use --input to specify file input. Printing result to stdout. Use --output to specify output path. (a,5) (action,1) (after,1) (against,1)
......
可以看到,第一件事是连接yarn的resourcemanager。
./bin/flink run 命令解析:
run [OPTIONS] <jar-file> <arguments> "run" 操作参数: -c,--class <classname> 如果没有在jar包中指定入口类,则需要在这里通过这个参数指定 -m,--jobmanager <host:port> 指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager -p,--parallelism <parallelism> 指定程序的并行度。可以覆盖配置文件中的默认值。 默认查找当前yarn集群中已有的yarn-session信息中的jobmanager【/tmp/.yarn-properties-root】: ./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1 连接指定host和port的jobmanager: ./bin/flink run -m hadoop100:1234 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1 启动一个新的yarn-session: ./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1 注意:yarn session命令行的选项也可以使用./bin/flink 工具获得。它们都有一个y或者yarn的前缀 例如:./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
Flink on yarn的内部实现
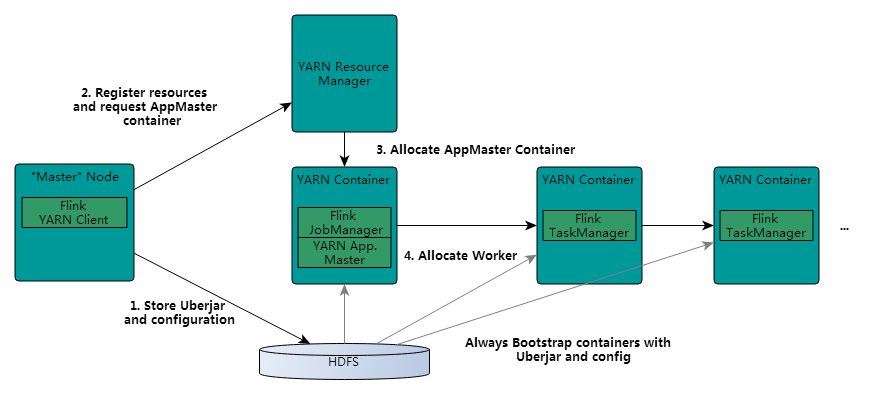
既然是on yarn,那必然需要知道yarn以及hdfs的相关配置,获取相关配置流程如下:
1,先检查有没有设置 YARN_CONF_DIR, HADOOP_CONF_DIR or HADOOP_CONF_PATH环境变量,如果其中之一设置了的话,那就通过此方式读取环境信息。
2,如果第一部分没有设置任何内容,那么客户端会去找HADOOP_HOME环境变量,然后访问$HADOOP_HOME/etc/hadoop路径下的配置文件。
当flink在提交一个任务时,客户端首先会检查资源是否可用(内存和cpu),然后上传flink jar包到hdfs。
然后客户端申请container启动applicationMaster,被选中的nodeManager初始化container,比如下载相关文件,然后启动applicationMaster。
JobManager和AM在同一个container中运行。AM也就知道JobManager的地址。然后为taskManager生成一个新的Flink配置文件(以便它们可以连接到JobManager)。文件也被上传到HDFS。此外,AM container还提供Flink的web接口。(yarn分配的所有端口都是临时端口。并且允许用户并行执行多个Flink任务)
之后,AM开始为Flink的taskManager分配container,后者将从HDFS下载jar包和修改后的配置文件。即可接收job然后执行
HA
因为单点故障的存在(single point of failure (SPOF))所以要做HA,实现HA又分flink standalone模式和on yarn模式
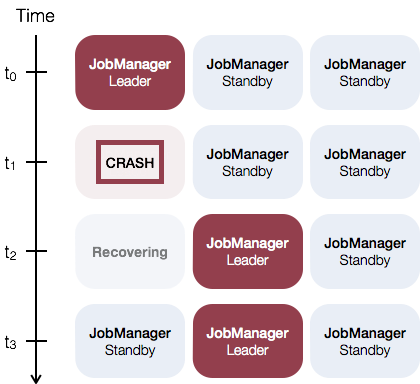
flink standalone模式下的HA
运行多个jobManager,其中一个为leader,其他为standby,通过zookeeper实现故障切换。如下图:
相关配置:
1.在conf/masters文件中添加多个jobManager主机和端口号,我这里环境如下
[root@master01 conf]# more masters master01.hadoop.xxx.cn:8081 worker03.hadoop.xxx.cn:8081
2.修改conf/flink-conf.yaml文件,主要是指定通过zookeeper来实现HA
(我这里已有运行正常的cdh集群)
high-availability: zookeeper high-availability.storageDir: hdfs:///flink/ha/ high-availability.zookeeper.quorum: master01.hadoop.xxx.cn:2181,worker01.hadoop.xxx.cn:2181,worker03.hadoop.xxx.cn:2181
此外,zookeeper是在/flink目录下存储对应的元数据(类似hbase),并且zk存储的并不是真正做recovery的元数据,数据其实是存储在hdfs上的,zk存储的只是指向hdfs路径的一个标识。
3.发flink包到各个节点
4.执行bin/start-cluster.sh
看wei界面
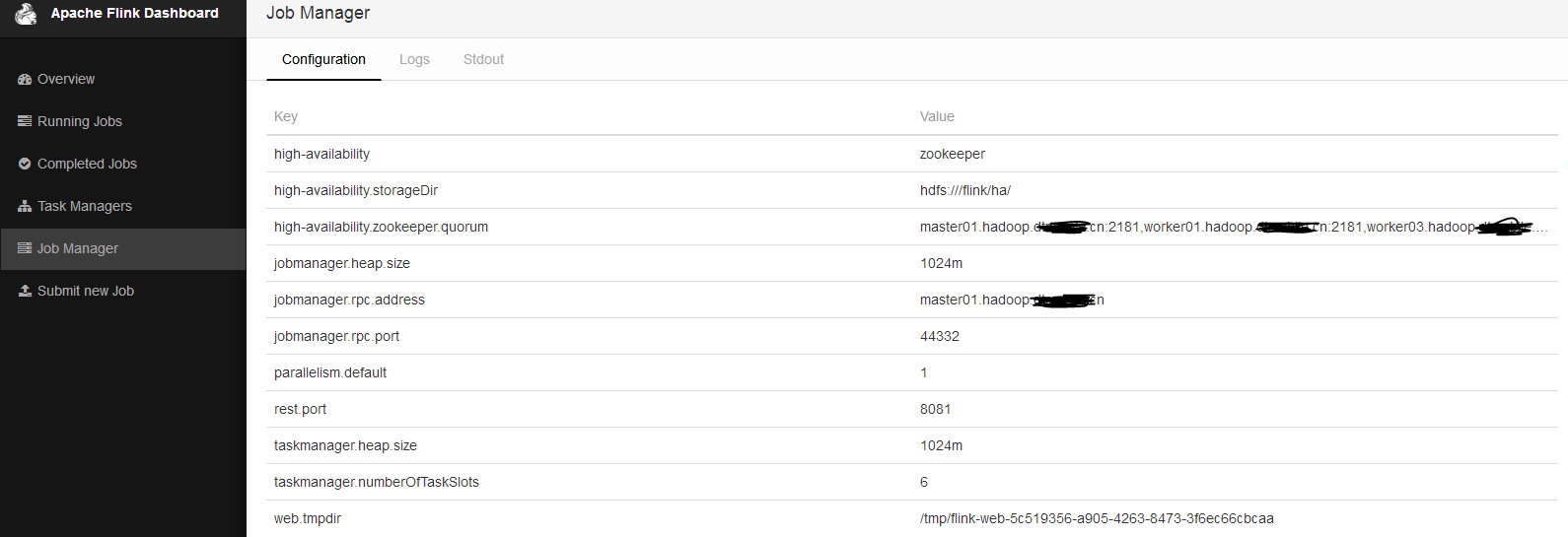
可以看到已经启用HA以及使用的zk集群,目前leader为master01节点。zk目录结构存储如下:
[zk: localhost:2181(CONNECTED) 0] ls / [flink, hive_zookeeper_namespace_hive, zookeeper, solr] [zk: localhost:2181(CONNECTED) 1] ls /flink [default] [zk: localhost:2181(CONNECTED) 2] ls /flink/default [jobgraphs, leader, leaderlatch]
kill掉master01节点的jobManager进程看能否实现切换,进程如下:
83819 StandaloneSessionClusterEntrypoint
再访问web界面,如下:

Flink on yarn HA实现
官网介绍:https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/jobmanager_high_availability.html#yarn-cluster-high-availability
我们需要修改 yarn-site.yaml 文件中的配置,如下所示:
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description> The maximum number of application master execution attempts. </description> </property>
yarn.resourcemanager.am.max-attempts 表示 Yarn 的 application master 的最大重试次数。
除了上述 HA 配置之外,还需要配置 flink-conf.yaml 中的最大重试次数(默认为2):
yarn.application-attempts: 10
当 yarn.application-attempts 配置为 10 的时候:
这意味着如果程序启动失败,YARN 会再重试 9 次(9 次重试 + 1 次启动),如果 YARN 启动 10 次作业还失败,则 YARN 才会将该任务的状态置为失败。如果发生进程抢占,节点硬件故障或重启,NodeManager 重新同步等,YARN 会继续尝试启动应用。 这些重启不计入 yarn.application-attempts 个数中。
同时官网给出了重要提示,不同 Yarn 版本的容器关闭行为不同:
-
YARN 2.3.0 < YARN 版本 < 2.4.0。如果 application master 进程失败,则所有的 container 都会重启。
-
YARN 2.4.0 < YARN 版本 < 2.6.0。TaskManager container 在 application master 故障期间,会继续工作。这样的优点是:启动时间更快,且缩短了所有 task manager 启动时申请资源的时间。
-
YARN 2.6.0 <= YARN 版本:失败重试的间隔会被设置为 Akka 的超时时间。在一次时间间隔内达到最大失败重试次数才会被置为失败。
zookeeper.sasl.service-name
zookeeper.sasl.login-context-name
