spark thriftserver
spark可以作为一个分布式的查询引擎,用户通过JDBC/ODBC的形式无需写任何代码,写写sql就可以实现查询啦,那么我们就可以使用一些支持JDBC/ODBC连接的BI工具(比如tableau)来生成一些报表。
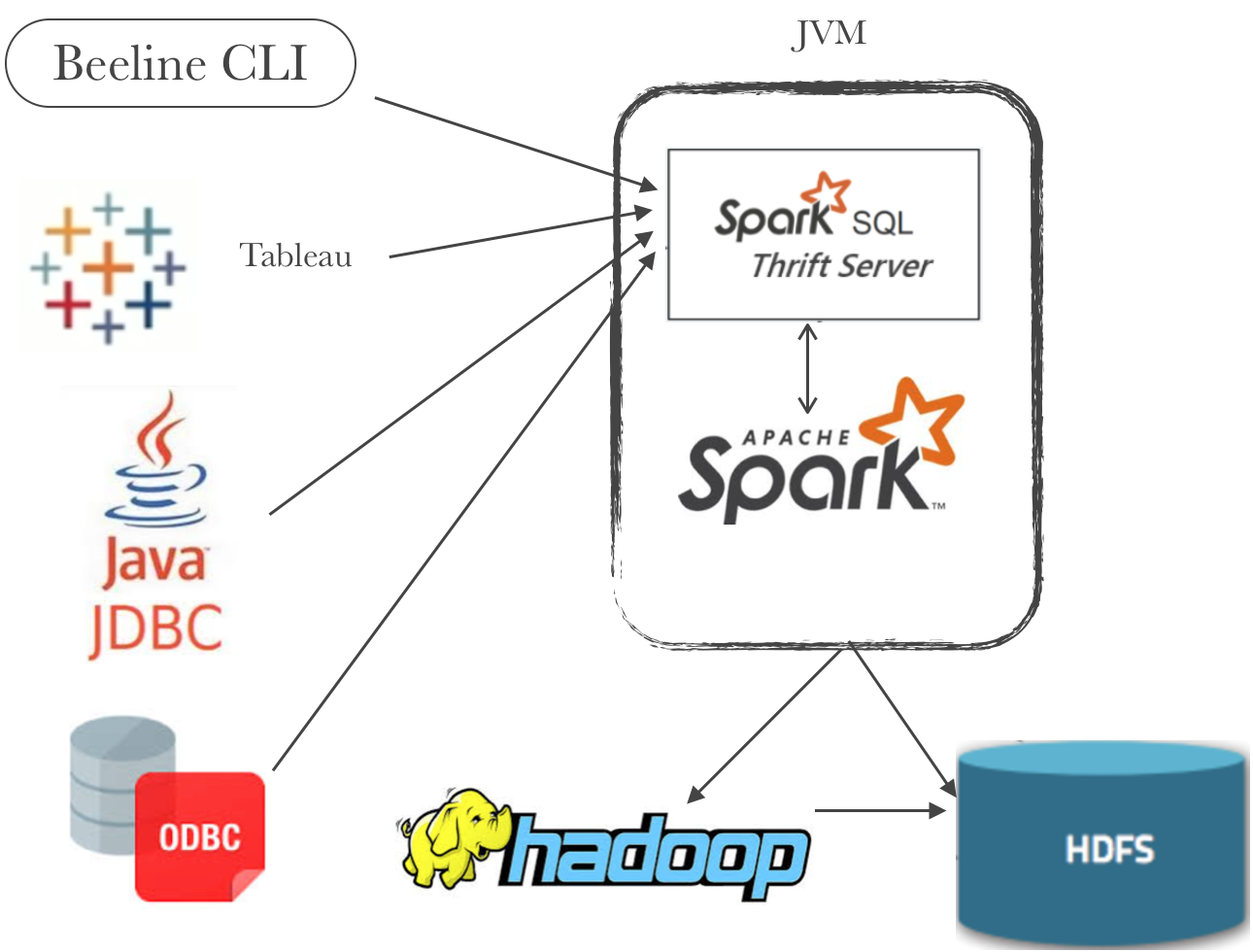
spark thriftserver的实现也是相当于hiveserver2的方式,并且在测试时候,即可以通过hive的beeline测试也可以通过spark bin/下的beeline,不管通过哪个beeline链接,都要指定spark thriftserver的主机和端口(默认是10000),比如
beeline> !connect jdbc:hive2://host_ip:port
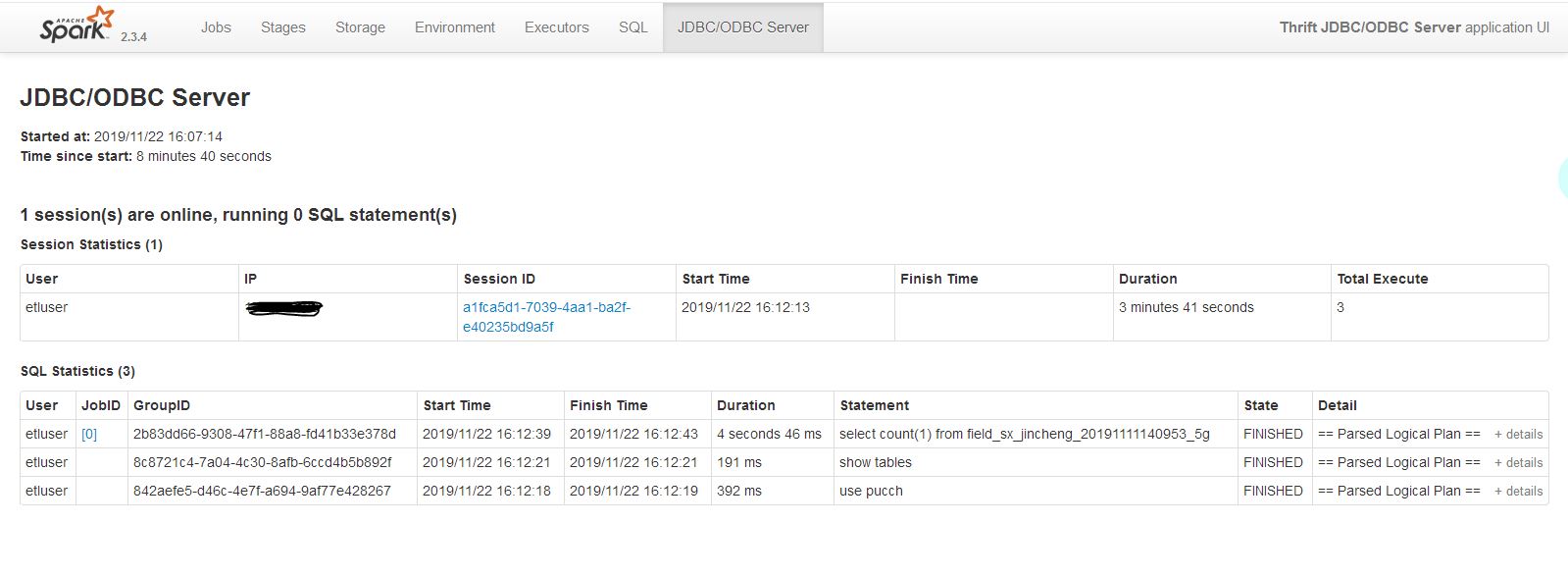
spark thriftserver启动之后实质上就是一个Spark的应用程序,并且也可以通过4040端口来查看web ui界面,但是这个应用程序它支持JDBC/ODBC的连接,如下:
配置
接上文编译spark支持thriftserver编译完成的spark包,在sbin目录下可以看到有start-thriftserver.sh和stop-thriftserver.sh脚本

默认情况下,可以这样启动thriftserver,但是很少这样用
./sbin/start-thriftserver.sh
可以像使用spark-submit一样输入一些相关的参数,比如--master <master-uri>之类的,此外还可以通过--hiveconf 选项来指定hive的相关属性,比如:
./sbin/start-thriftserver.sh \ --hiveconf hive.server2.thrift.port=<listening-port> \ --hiveconf hive.server2.thrift.bind.host=<listening-host> \ --master <master-uri> ...
如果集群资源管理为yarn的话,--master设置为yarn,需要配置spark-env.sh脚本,增加hadoop的配置目录等,比如:
# Options read in YARN client/cluster mode # - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf) # - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files # - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN # - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1). # - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G) # - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G) HADOOP_CONF_DIR=/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/conf SPARK_CONF_DIR=/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/conf YARN_CONF_DIR=/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/conf
启动thriftserver
/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/sbin/start-thriftserver.sh \ --master yarn \ --driver-memory 2G \ --executor-memory 2G \ --num-executors 2 \ --executor-cores 2 \ --hiveconf hive.server2.thrift.bind.host=`hostname -i` \ --hiveconf hive.server2.thrift.port=9012
也可以配置thriftserver的动态资源分配,比如:
export SPARK_NO_DAEMONIZE=true export SPARK_LOG_DIR=/data0/Logs/$USER/spark-2.1.0 export SPARK_PID_DIR=$SPARK_LOG_DIR/PID $SPARK_HOME/sbin/start-thriftserver.sh --executor-memory 20g --executor-cores 5 --driver-memory 10g \ --driver-cores 5 --conf spark.dynamicAllocation.enabled=true --conf spark.shuffle.service.enabled=true \ --conf spark.dynamicAllocation.initialExecutors=20 --conf spark.dynamicAllocation.minExecutors=20 \ --conf spark.dynamicAllocation.maxExecutors=400 --conf spark.dynamicAllocation.executorIdleTimeout=300s \ --conf spark.dynamicAllocation.schedulerBacklogTimeout=10s --conf spark.speculation=true \ --conf spark.speculation.interval=2s --conf spark.speculation.multiplier=10 \ --conf spark.speculation.quantile=0.9 --hiveconf hive.server2.global.init.file.location=$SPARK_CONF_DIR \ --hiveconf hive.server2.thrift.bind.host=`hostname -i` --hiveconf hive.server2.thrift.port=9012
执行以后查看进程
[etluser@worker01 spark-2.3.4-bin-hadoop2.6]$ jps 62509 Jps 62255 SparkSubmit [etluser@worker01 spark-2.3.4-bin-hadoop2.6]$ ps -ef | grep 62255 etluser 62255 1 99 15:22 pts/0 00:00:26 /usr/lib/java/jdk1.8.0_144/bin/java -cp /home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/conf/:/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/jars/* -Xmx2G org.apache.spark.deploy.SparkSubmit --master yarn --conf spark.driver.memory=2G --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift JDBC/ODBC Server --executor-memory 2G --num-executors 2 --executor-cores 2 spark-internal --hiveconf hive.server2.thrift.bind.host=172.30.4.33 --hiveconf hive.server2.thrift.port=9012 etluser 62699 77219 0 15:22 pts/0 00:00:00 grep --color=auto 62255
查看日志,看是否有报错。日志如下:


19/11/22 16:06:55 INFO Client: Uploading resource file:/tmp/spark-0b2c2488-9bb3-44d5-bb1d-2d8f815dfc5f/__spark_libs__2287999641897109745.zip -> hdfs://master01.hadoop.dtmobile.cn:8020/user/etluser/.sparkStaging/application_1570496850779_0362/__spark_libs__2287999641897109745.zip 19/11/22 16:06:58 INFO Client: Uploading resource file:/tmp/spark-0b2c2488-9bb3-44d5-bb1d-2d8f815dfc5f/__spark_conf__8007288391370765190.zip -> hdfs://master01.hadoop.dtmobile.cn:8020/user/etluser/.sparkStaging/application_1570496850779_0362/__spark_conf__.zip 19/11/22 16:06:58 INFO SecurityManager: Changing view acls to: etluser 19/11/22 16:06:58 INFO SecurityManager: Changing modify acls to: etluser 19/11/22 16:06:58 INFO SecurityManager: Changing view acls groups to: 19/11/22 16:06:58 INFO SecurityManager: Changing modify acls groups to: 19/11/22 16:06:58 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(etluser); groups with view permissions: Set(); users with modify permissions: Set(etluser); groups with modify permissions: Set() 19/11/22 16:06:58 INFO Client: Submitting application application_1570496850779_0362 to ResourceManager 19/11/22 16:06:58 INFO YarnClientImpl: Submitted application application_1570496850779_0362 19/11/22 16:06:58 INFO SchedulerExtensionServices: Starting Yarn extension services with app application_1570496850779_0362 and attemptId None 19/11/22 16:06:59 INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED) 19/11/22 16:06:59 INFO Client: client token: N/A diagnostics: N/A ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: root.users.etluser start time: 1574410018587 final status: UNDEFINED tracking URL: http://master01.hadoop.dtmobile.cn:8088/proxy/application_1570496850779_0362/ user: etluser 19/11/22 16:07:00 INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED) 19/11/22 16:07:01 INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED) 19/11/22 16:07:02 INFO Client: Application report for application_1570496850779_0362 (state: ACCEPTED) 19/11/22 16:07:03 INFO YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master01.hadoop.dtmobile.cn, PROXY_URI_BASES -> http://master01.hadoop.dtmobile.cn:8088/proxy/application_1570496850779_0362), /proxy/application_1570496850779_0362 19/11/22 16:07:03 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /jobs, /jobs/json, /jobs/job, /jobs/job/json, /stages, /stages/json, /stages/stage, /stages/stage/json, /stages/pool, /stages/pool/json, /storage, /storage/json, /storage/rdd, /storage/rdd/json, /environment, /environment/json, /executors, /executors/json, /executors/threadDump, /executors/threadDump/json, /static, /, /api, /jobs/job/kill, /stages/stage/kill. 19/11/22 16:07:03 INFO Client: Application report for application_1570496850779_0362 (state: RUNNING) 19/11/22 16:07:03 INFO Client: client token: N/A diagnostics: N/A ApplicationMaster host: 172.30.5.213 ApplicationMaster RPC port: 0 queue: root.users.etluser start time: 1574410018587 final status: UNDEFINED tracking URL: http://master01.hadoop.dtmobile.cn:8088/proxy/application_1570496850779_0362/ user: etluser 19/11/22 16:07:03 INFO YarnClientSchedulerBackend: Application application_1570496850779_0362 has started running. 19/11/22 16:07:03 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 41925. 19/11/22 16:07:03 INFO NettyBlockTransferService: Server created on worker01.hadoop.dtmobile.cn:41925 19/11/22 16:07:03 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 19/11/22 16:07:03 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, worker01.hadoop.dtmobile.cn, 41925, None) 19/11/22 16:07:03 INFO BlockManagerMasterEndpoint: Registering block manager worker01.hadoop.dtmobile.cn:41925 with 912.3 MB RAM, BlockManagerId(driver, worker01.hadoop.dtmobile.cn, 41925, None) 19/11/22 16:07:03 INFO YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM) 19/11/22 16:07:03 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, worker01.hadoop.dtmobile.cn, 41925, None) 19/11/22 16:07:03 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, worker01.hadoop.dtmobile.cn, 41925, None) 19/11/22 16:07:03 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /metrics/json. 19/11/22 16:07:09 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.30.5.212:36832) with ID 1 19/11/22 16:07:09 INFO YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.30.5.212:36834) with ID 2 19/11/22 16:07:09 INFO YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8 19/11/22 16:07:09 INFO BlockManagerMasterEndpoint: Registering block manager worker03.hadoop.dtmobile.cn:37315 with 912.3 MB RAM, BlockManagerId(1, worker03.hadoop.dtmobile.cn, 37315, None) 19/11/22 16:07:09 INFO SharedState: loading hive config file: file:/home/etluser/kong/spark/spark-2.3.4-bin/spark-2.3.4-bin-hadoop2.6/conf/hive-site.xml 19/11/22 16:07:09 INFO BlockManagerMasterEndpoint: Registering block manager worker03.hadoop.dtmobile.cn:42908 with 912.3 MB RAM, BlockManagerId(2, worker03.hadoop.dtmobile.cn, 42908, None) 19/11/22 16:07:09 INFO SharedState: spark.sql.warehouse.dir is not set, but hive.metastore.warehouse.dir is set. Setting spark.sql.warehouse.dir to the value of hive.metastore.warehouse.dir ('/user/hive/warehouse'). 19/11/22 16:07:09 INFO SharedState: Warehouse path is '/user/hive/warehouse'. 19/11/22 16:07:09 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL. 19/11/22 16:07:09 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL/json. 19/11/22 16:07:09 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL/execution. 19/11/22 16:07:09 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /SQL/execution/json. 19/11/22 16:07:09 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /static/sql. 19/11/22 16:07:09 INFO HiveUtils: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes. 19/11/22 16:07:10 INFO metastore: Trying to connect to metastore with URI thrift://worker03.hadoop.dtmobile.cn:9083 19/11/22 16:07:10 INFO metastore: Connected to metastore. 19/11/22 16:07:10 INFO SessionState: Created local directory: /tmp/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021_resources 19/11/22 16:07:10 INFO SessionState: Created HDFS directory: /tmp/hive/etluser/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021 19/11/22 16:07:10 INFO SessionState: Created local directory: /tmp/etluser/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021 19/11/22 16:07:10 INFO SessionState: Created HDFS directory: /tmp/hive/etluser/a8f6b1e4-5ada-4c34-aba6-80d7c6d6f021/_tmp_space.db 19/11/22 16:07:10 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse 19/11/22 16:07:10 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint 19/11/22 16:07:10 INFO HiveUtils: Initializing execution hive, version 1.2.1 19/11/22 16:07:11 INFO HiveMetaStore: 0: Opening raw store with implemenation class:org.apache.hadoop.hive.metastore.ObjectStore 19/11/22 16:07:11 INFO ObjectStore: ObjectStore, initialize called 19/11/22 16:07:11 INFO Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored 19/11/22 16:07:11 INFO Persistence: Property datanucleus.cache.level2 unknown - will be ignored 19/11/22 16:07:12 INFO ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order" 19/11/22 16:07:13 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table. 19/11/22 16:07:13 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table. 19/11/22 16:07:13 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MFieldSchema" is tagged as "embedded-only" so does not have its own datastore table. 19/11/22 16:07:13 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MOrder" is tagged as "embedded-only" so does not have its own datastore table. 19/11/22 16:07:14 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY 19/11/22 16:07:14 INFO ObjectStore: Initialized ObjectStore 19/11/22 16:07:14 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0 19/11/22 16:07:14 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException 19/11/22 16:07:14 INFO HiveMetaStore: Added admin role in metastore 19/11/22 16:07:14 INFO HiveMetaStore: Added public role in metastore 19/11/22 16:07:14 INFO HiveMetaStore: No user is added in admin role, since config is empty 19/11/22 16:07:14 INFO HiveMetaStore: 0: get_all_databases 19/11/22 16:07:14 INFO audit: ugi=etluser ip=unknown-ip-addr cmd=get_all_databases 19/11/22 16:07:14 INFO HiveMetaStore: 0: get_functions: db=default pat=* 19/11/22 16:07:14 INFO audit: ugi=etluser ip=unknown-ip-addr cmd=get_functions: db=default pat=* 19/11/22 16:07:14 INFO Datastore: The class "org.apache.hadoop.hive.metastore.model.MResourceUri" is tagged as "embedded-only" so does not have its own datastore table. 19/11/22 16:07:14 INFO SessionState: Created local directory: /tmp/6b9ea521-f369-45c7-8630-4fdc6134ad51_resources 19/11/22 16:07:14 INFO SessionState: Created HDFS directory: /tmp/hive/etluser/6b9ea521-f369-45c7-8630-4fdc6134ad51 19/11/22 16:07:14 INFO SessionState: Created local directory: /tmp/etluser/6b9ea521-f369-45c7-8630-4fdc6134ad51 19/11/22 16:07:14 INFO SessionState: Created HDFS directory: /tmp/hive/etluser/6b9ea521-f369-45c7-8630-4fdc6134ad51/_tmp_space.db 19/11/22 16:07:14 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is /user/hive/warehouse 19/11/22 16:07:14 WARN SessionManager: Unable to create operation log root directory: /var/log/hive/operation_logs 19/11/22 16:07:14 INFO SessionManager: HiveServer2: Background operation thread pool size: 100 19/11/22 16:07:14 INFO SessionManager: HiveServer2: Background operation thread wait queue size: 100 19/11/22 16:07:14 INFO SessionManager: HiveServer2: Background operation thread keepalive time: 10 seconds 19/11/22 16:07:14 INFO AbstractService: Service:OperationManager is inited. 19/11/22 16:07:14 INFO AbstractService: Service:SessionManager is inited. 19/11/22 16:07:14 INFO AbstractService: Service: CLIService is inited. 19/11/22 16:07:14 INFO AbstractService: Service:ThriftBinaryCLIService is inited. 19/11/22 16:07:14 INFO AbstractService: Service: HiveServer2 is inited. 19/11/22 16:07:14 INFO AbstractService: Service:OperationManager is started. 19/11/22 16:07:14 INFO AbstractService: Service:SessionManager is started. 19/11/22 16:07:14 INFO AbstractService: Service:CLIService is started. 19/11/22 16:07:14 INFO ObjectStore: ObjectStore, initialize called 19/11/22 16:07:14 INFO Query: Reading in results for query "org.datanucleus.store.rdbms.query.SQLQuery@0" since the connection used is closing 19/11/22 16:07:14 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY 19/11/22 16:07:14 INFO ObjectStore: Initialized ObjectStore 19/11/22 16:07:14 INFO HiveMetaStore: 0: get_databases: default 19/11/22 16:07:14 INFO audit: ugi=etluser ip=unknown-ip-addr cmd=get_databases: default 19/11/22 16:07:14 INFO HiveMetaStore: 0: Shutting down the object store... 19/11/22 16:07:14 INFO audit: ugi=etluser ip=unknown-ip-addr cmd=Shutting down the object store... 19/11/22 16:07:14 INFO HiveMetaStore: 0: Metastore shutdown complete. 19/11/22 16:07:14 INFO audit: ugi=etluser ip=unknown-ip-addr cmd=Metastore shutdown complete. 19/11/22 16:07:14 INFO AbstractService: Service:ThriftBinaryCLIService is started. 19/11/22 16:07:14 INFO AbstractService: Service:HiveServer2 is started. 19/11/22 16:07:14 INFO HiveThriftServer2: HiveThriftServer2 started 19/11/22 16:07:14 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver. 19/11/22 16:07:14 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver/json. 19/11/22 16:07:14 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver/session. 19/11/22 16:07:14 INFO JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /sqlserver/session/json. 19/11/22 16:07:14 INFO ThriftCLIService: Starting ThriftBinaryCLIService on port 10000 with 5...500 worker threads
启动成功之后,就可以通过beeline来测试并且到4040界面来查看执行的状态
在使用beeline的时候,会要求输入用户名和密码,如果集群没有做什么安全认证,随意输入账号密码即可
简单测试:
[etluser@worker01 spark-2.3.4-bin-hadoop2.6]$ bin/beeline Beeline version 1.2.1.spark2 by Apache Hive beeline> !connect jdbc:hive2://worker01.hadoop.xxx.cn:9012 Connecting to jdbc:hive2://worker01.hadoop.dtmobile.cn:9012 Enter username for jdbc:hive2://worker01.hadoop.xxx.cn:9012: etluser Enter password for jdbc:hive2://worker01.hadoop.xxx.cn:9012: ******* log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Connected to: Spark SQL (version 2.3.4) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://worker01.hadoop.dtmobile.cn:1> use pucch; +---------+--+ | Result | +---------+--+ +---------+--+ No rows selected (0.725 seconds) 0: jdbc:hive2://worker01.hadoop.xxx.cn:1> show tables; +-----------+--------------------------------------------+--------------+--+ | database | tableName | isTemporary | +-----------+--------------------------------------------+--------------+--+ | pucch | cell_lusun_datasx_jincheng20191111140953 | false | | pucch | dw_sinr_rlt_sx_jincheng20191111140953 | false | +-----------+--------------------------------------------+--------------+--+ 14 rows selected (0.224 seconds) 0: jdbc:hive2://worker01.hadoop.dtmobile.cn:1> select count(1) from field_sx_jincheng_20191111140953_5g; +-----------+--+ | count(1) | +-----------+--+ | 863391 | +-----------+--+
4040界面: