


dataset的reparation和coalesce
/** * Returns a new Dataset that has exactly `numPartitions` partitions, when the fewer partitions * are requested. If a larger number of partitions is requested, it will stay at the current * number of partitions. Similar to coalesce defined on an `RDD`, this operation results in * a narrow dependency, e.g. if you go from 1000 partitions to 100 partitions, there will not * be a shuffle, instead each of the 100 new partitions will claim 10 of the current partitions. * * However, if you're doing a drastic coalesce, e.g. to numPartitions = 1, * this may result in your computation taking place on fewer nodes than * you like (e.g. one node in the case of numPartitions = 1). To avoid this, * you can call repartition. This will add a shuffle step, but means the * current upstream partitions will be executed in parallel (per whatever * the current partitioning is). * * @group typedrel * @since 1.6.0 */ def coalesce(numPartitions: Int): Dataset[T] = withTypedPlan { Repartition(numPartitions, shuffle = false, planWithBarrier) }
关于coalsece:
1、用于减少分区数量,如果设置的numPartitions超过目前实际有的分区数,则分区数保持不变。
2、窄依赖,不会发生shuffle
3、极端的coalsece可能会影响性能,比如coalsece(1),则只会在一个节点上运行单个任务。这种情况下建议使用repartition,
虽然repartition会发生shuffle,但是repartition对上游的计算,还是多分区并行执行的。
4、应用场景:多用于对一个大数据集filter以后,执行coalsece
/** * Returns a new Dataset that has exactly `numPartitions` partitions. * * @group typedrel * @since 1.6.0 */ def repartition(numPartitions: Int): Dataset[T] = withTypedPlan { Repartition(numPartitions, shuffle = true, planWithBarrier) }
关于repartition:
跟coalsece一样,都是用于明确设置多少个分区,但是repartition是个宽依赖,会发生shuffle。主要注意的地方就是repartition不影响上游计算的分区
如果想极端的控制生成的文件数量来避免太多的小文件,建议repartition
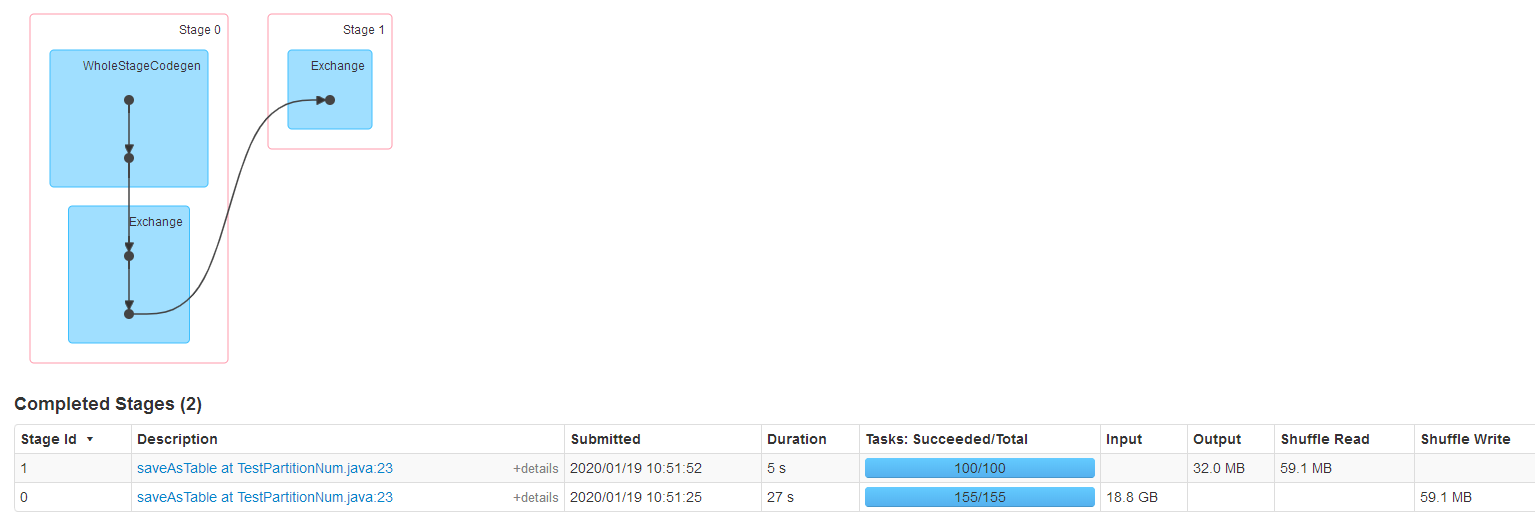
测试:对一个大表查询,将查询的结果写到一张表
coalsece测试,coalsece(100),可以看到只有一个stage,并且并行度是100

repartition测试,repartition(100),发生了shuffle。两个stage,stage0对大表指定条件查询,对应的并行度默认是大表的数据量/128M,在repartition将结果输出到表的时候并行度为我们设置的repartition(100),然后shuffle数据,最后输出
/** * Return a new RDD that has exactly numPartitions partitions. * * Can increase or decrease the level of parallelism in this RDD. Internally, this uses * a shuffle to redistribute data. * * If you are decreasing the number of partitions in this RDD, consider using `coalesce`, * which can avoid performing a shuffle. * * TODO Fix the Shuffle+Repartition data loss issue described in SPARK-23207. */ def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) } /** * Return a new RDD that is reduced into `numPartitions` partitions. * * This results in a narrow dependency, e.g. if you go from 1000 partitions * to 100 partitions, there will not be a shuffle, instead each of the 100 * new partitions will claim 10 of the current partitions. If a larger number * of partitions is requested, it will stay at the current number of partitions. * * However, if you're doing a drastic coalesce, e.g. to numPartitions = 1, * this may result in your computation taking place on fewer nodes than * you like (e.g. one node in the case of numPartitions = 1). To avoid this, * you can pass shuffle = true. This will add a shuffle step, but means the * current upstream partitions will be executed in parallel (per whatever * the current partitioning is). * * @note With shuffle = true, you can actually coalesce to a larger number * of partitions. This is useful if you have a small number of partitions, * say 100, potentially with a few partitions being abnormally large. Calling * coalesce(1000, shuffle = true) will result in 1000 partitions with the * data distributed using a hash partitioner. The optional partition coalescer * passed in must be serializable. */ def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null) : RDD[T] = withScope { require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.") if (shuffle) { /** Distributes elements evenly across output partitions, starting from a random partition. */ val distributePartition = (index: Int, items: Iterator[T]) => { var position = new Random(hashing.byteswap32(index)).nextInt(numPartitions) items.map { t => // Note that the hash code of the key will just be the key itself. The HashPartitioner // will mod it with the number of total partitions. position = position + 1 (position, t) } } : Iterator[(Int, T)] // include a shuffle step so that our upstream tasks are still distributed new CoalescedRDD( new ShuffledRDD[Int, T, T](mapPartitionsWithIndex(distributePartition), new HashPartitioner(numPartitions)), numPartitions, partitionCoalescer).values } else { new CoalescedRDD(this, numPartitions, partitionCoalescer) } }

