Container killed by YARN for exceeding memory limits
19/08/12 14:15:35 ERROR cluster.YarnScheduler: Lost executor 5 on worker01.hadoop.mobile.cn: Container killed by YARN for exceeding memory limits. 5 GB of 5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
在看这个问题之前,首先解释下下面参数的含义:
hadoop yarn-site.xml部分资源定义相关参数,更详细的内容可参考官网链接
yarn.nodemanager.resource.memory-mb //每个NodeManager可以供yarn调度(分配给container)的物理内存,单位MB yarn.nodemanager.resource.cpu-vcores //每个NodeManager可以供yarn调度(分配给container)的vcore个数 yarn.scheduler.maximum-allocation-mb //每个container能够申请到的最大内存 yarn.scheduler.minimum-allocation-mb //每个container能够申请到的最小内存,如果设置的值比该值小,默认就是该值 yarn.scheduler.increment-allocation-mb //container内存不够用时一次性加多少内存 单位MB。CDH默认512M yarn.scheduler.minimum-allocation-vcores //每个container能够申请到的最小vcore个数,如果设置的值比该值小,默认就是该值 yarn.scheduler.maximum-allocation-vcores //每个container能够申请到的最大vcore个数。 yarn.nodemanager.pmem-check-enabled //是否对contanier实施物理内存限制,会通过一个线程去监控container内存使用情况,超过了container的内存限制以后,就会被kill掉。 yarn.nodemanager.vmem-check-enabled //是否对container实施虚拟内存限制
executor-memory和executor-memory-overhead源码含义
EXECUTOR_MEMORY: Amount of memory to use per executor process EXECUTOR_MEMORY_OVERHEAD: The amount of off-heap memory to be allocated per executor in cluster mode
spark.yarn.executor.memoryOverhead源代码实现:
val MEMORY_OVERHEAD_FACTOR = 0.10 val MEMORY_OVERHEAD_MIN = 384L
// Executor memory in MB. protected val executorMemory = sparkConf.get(EXECUTOR_MEMORY).toInt // Additional memory overhead. protected val memoryOverhead: Int = sparkConf.get(EXECUTOR_MEMORY_OVERHEAD).getOrElse( math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN)).toInt
到这里,可能有的同学大概就明白了,比如设置了--executor-memory为2G,为什么报错时候是Container killed by YARN for exceeding memory limits. 2.5 GB of 2.5 GB physical memory used,2.5G从哪里来的?是这样,首先计算出memoryOverhead 默认值是max(2G*0.1,384),也就是384M,又根据上面的yarn.scheduler.increment-allocation-mb值,就会分配2G+512M大小的container...
好了,我们再看问题,从报错的描述上可以大概了解到,container超过了内存的限制从而被kill掉,从上面的参数yarn.nodemanager.pmem-check-enabled可以了解到该参数默认是true,也就是会由它来控制监控container的内存使用,所以第一步我们可以尝试关闭该参数看应用是否可以正常运行
调整一:设置yarn.nodemanager.pmem-check-enabled=false
结果:应用成功运行,但是关闭了对container内存的监控,虽然可以运行,但是明显没有实际性的处理问题,而且不可控的内存使用,对多租户的环境不友好
调整二:根据提示 Consider boosting spark.yarn.executor.memoryOverhead
但是什么是memoryOverhead呢? 如下图:
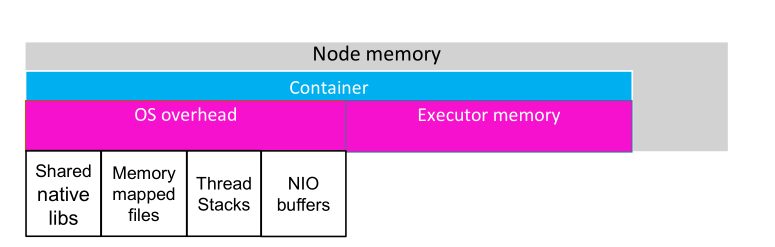
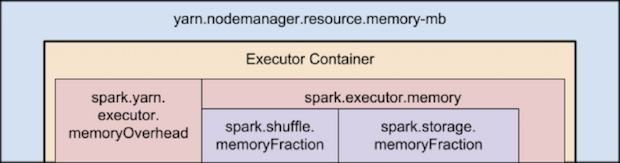
container内存使用情况的时线图:
尝试提升spark.yarn.executor.memoryOverhead参数值至1.5G,可以看到container预留了更多空间给 OS overhead,没有超过container的内存限制
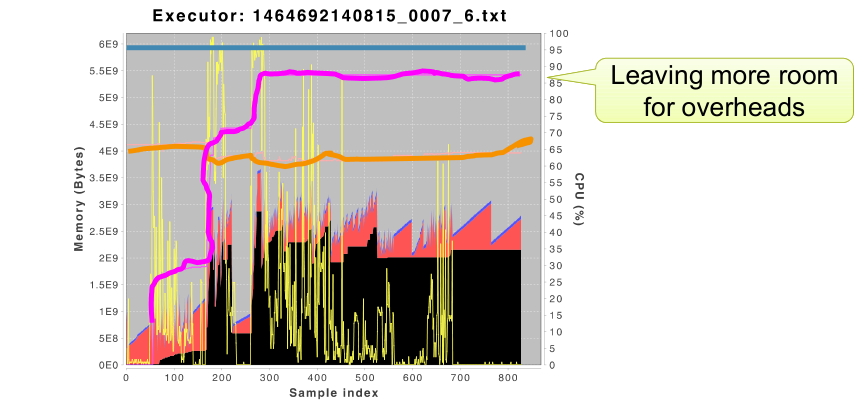
不过很明显,我们是牺牲内存资源来换取应用稳定性。
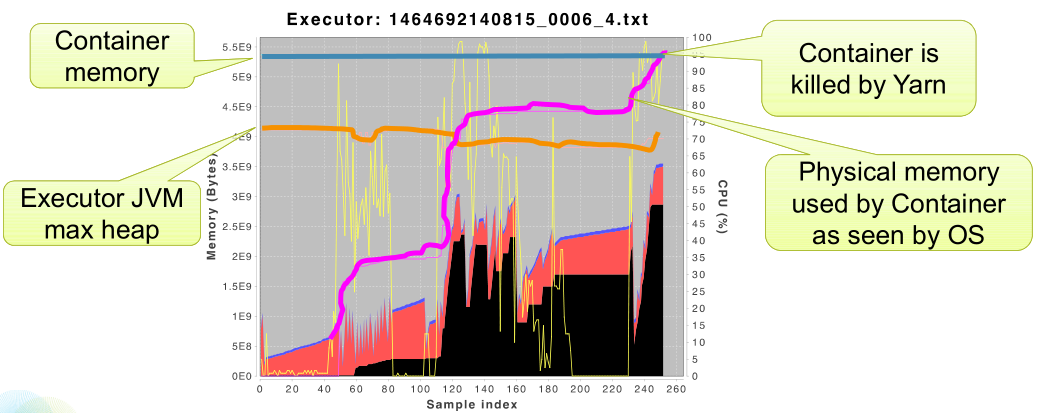
但是真正的原因到底是什么呢?看下图:
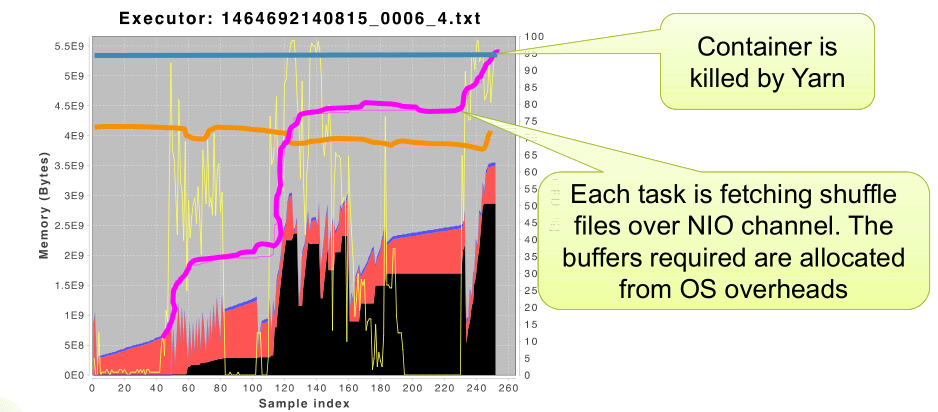
每个任务都是通过NIO channel 去获取shuffle文件。并且所需的缓冲区是从OS overheads中分配的,这也就导致了os overhead越来越大,因此我们也可以通过减少并行度来减少同时运行的任务来尝试避免这样的问题。
调整三:降低参数--excutor-cores值

结果也可以成功运行,但是同样,我们是牺牲了应用的性能和cpu的利用率来换取应用稳定性。
最后,如果有同学单独调整以上参数应用仍然不可用的话,可以尝试上述多种方式同时使用,另外注意
1.对于发生shuffle的算子,比如groupby,可以通过repartition提升并行度
2.避免数据倾斜
