

Mongo按指定字段 分段分组 聚合统计
现在有一批数据如下(表名detectOriginalData):
{ "_id" : "760c29a2720ead1681184dfbef0aaae4", "imgSavePath" : "/opt/temp/face/publicceaf441cf933bba310e4.JPG", "faceDetail" : { "face_token" : "760c29a2720ead1681184dfbef0aaae4", "location" : { "left" : 110.04, "top" : 244.39, "width" : 311.0, "height" : 263.0, "rotation" : -2 } }, "cdt" : ISODate("2020-12-25T10:53:43.647+08:00") }
现在,我们要统计faceDetail.location.width,找出width处于300-400之间,每隔10分一段(也就是300-310、310-320...390-400共10组),之间的faceToken和imgSavePath都有哪些
最后实现的一种为:
db.detectOriginalData.aggregate([ {$match: {"faceDetail.location.width": {$lte: 400, $gte: 300}}}, {$project: {val: "$faceDetail.location.width", ftk: "$faceDetail.face_token", imgPath: "$imgSavePath"}}, {$group: { "_id": { $subtract: [ {$subtract: ["$val", 0]}, {$mod: [{$subtract: ["$val", 0]}, 10]} ] }, ftkList: {$push: "$ftk"}, imgList: {$push: "$imgPath"}, ftkCount: {$sum: 1} }}, {$sort: {_id: -1}} ])
下面为开始用的绕了弯路的一种实现方式,可以忽略。。。
db.detectOriginalData.aggregate([ {$match: {"faceDetail.location.width": {$lte: 400, $gte: 300}}}, {$project: {val: "$faceDetail.location.width", ftk: "$faceDetail.face_token"}}, {$lookup:{ from:"detectOriginalData", localField:"ftk", foreignField: "_id", as: "img"} }, {$project: {val: 1, ftk: 1, imgPath: "$img.imgSavePath"}}, {$unwind: "$imgPath"}, {$group: { "_id": { $subtract: [ {$subtract: ["$val", 0]}, {$mod: [{$subtract: ["$val", 0]}, 10]} ] }, ftkList: {$push: "$ftk"}, imgList: {$push: "$imgPath"}, ftkCount: {$sum: 1} }}, {$sort: {_id: -1}} ])
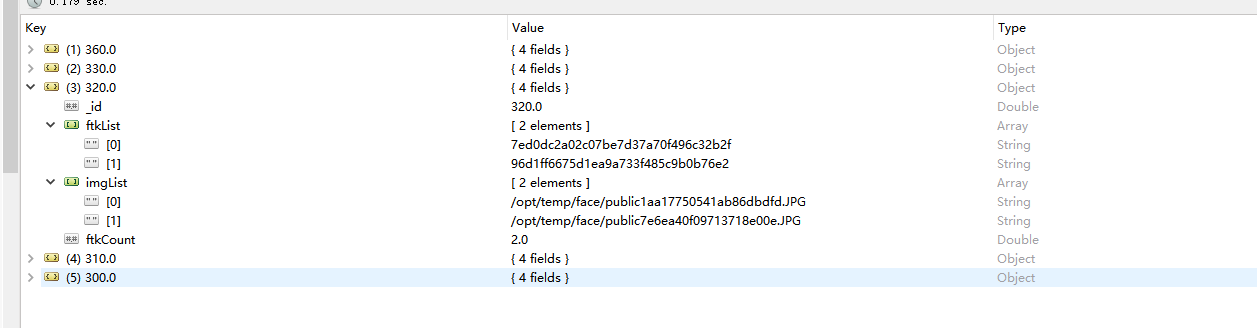
最后的结果如下(_id=320,代表width处于320-330之间的数据):
************2021-01-19 新增,测试小伙伴提了个统计需求。。。。。。
先看统计数据关联的另一张表(过滤详情表detectFilterDetail),大概数据结构如下(只截取部分字段):
{ "_id" : ObjectId("5feaa27fd873663e8085507d"), "faceToken" : "2268048d7df15fa15652cc745261404e", "paramRecordId" : "5feaa273d873663e80855047", "paramBoolean" : { "ageMax" : true, "ageMin" : true, "qualityBlur" : true, "qualityOcclusionMouth" : true, "locationWidthMin" : false, "locationHeightMin" : false }, "filterCount" : 2, "filterKey" : [ "locationWidthMin", "locationHeightMin" ], "cdt" : ISODate("2020-12-29T11:29:03.651+08:00") }
现在是想要统计,detectFilterDetail表的detectFilterDetail.paramBoolean.qualityOcclusionMouse为true的分布,也就是和上一个统计一样,统计每个分段里面,为true的数量有多少
琢磨了一会,大概实现sql如下:
db.detectFilterDetail.aggregate([ {$match: {"paramRecordId": "5feaa273d873663e80855047", "paramBoolean.qualityOcclusionMouth": true}}, {$project: {flag: "$paramBoolean.qualityOcclusionMouth", ftk: "$faceToken"}}, {$lookup:{ from:"detectOriginalData", localField:"ftk", foreignField: "_id", as: "f_ftk"} }, {$project: {flag: 1, ftk: 1, val: "$f_ftk.faceDetail.quality.occlusion.mouth"}}, {$unwind: "$val"}, {$group: { "_id": { $subtract: [ {$subtract: ["$val", 0]}, {$mod: [{$subtract: ["$val", 0]}, 0.1]} ] }, ftkList: {$push: "$ftk"}, ftkCount: {$sum: 1} }}, //{$group: {"_id": null, count: {$sum: 1}}} {$sort: {_id: -1}} ])
结果如下:

************2021-05-17 新增,有个其他场景统计需求,用这份数据测试一下。。。。。。
(过滤详情表detectFilterDetail)统计需求就是:根据 过滤参数个数filterCount字段 分组,既要 统计总数,又要统计其中某个具体参数占的数量(就是paramBoolean里面某个具体参数占的数量,这里选paramBoolean.qualityBlur来测试
)
实现sql如下:
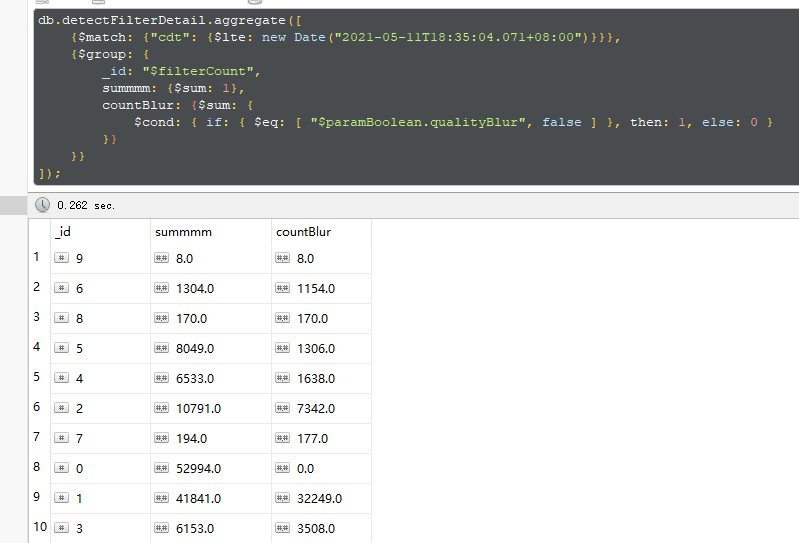
db.detectFilterDetail.aggregate([ {$match: {"cdt": {$lte: new Date("2021-05-11T18:35:04.071+08:00")}}}, {$group: { _id: "$filterCount", summmm: {$sum: 1}, countBlur: {$sum: { $cond: { if: { $eq: [ "$paramBoolean.qualityBlur", false ] }, then: 1, else: 0 } }} }} ]);
结果如下:
其中,$cond还有一种更简单的写法:
$cond: [{$eq: ["$paramBoolean.qualityOcclusionNose", false]}, 1, 0 ]
PS:暂时做个记录,后续再稍微解释各个语句的大概作用
************2023-10-09 新增,现场有个小伙伴提了个需求,对某记录按天分组统计。。。。。。
其中,表的数据结构大概长这样:
{
"_id" : ObjectId("62ad1581af8d0507d0cd621b"),
"imsi" : "460076410375112",
"imei" : "",
"regional" : "中国",
"isp" : 3,
"netType" : "CMCC2",
"createTime" : NumberLong(1655510401),
"uptime" : NumberLong(1655510391),
"deviceId" : "ZDKGEC005",
"lon" : 105.13,
"lat" : 28.19,
"distance" : 530,
"rsrp" : [
-103
]
}
其中,需要分组统计的就是uptime字段,是Int64类型的,单位是秒
最后实现的SQL如下:
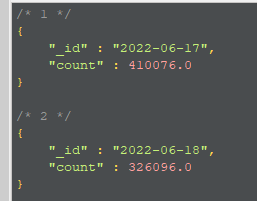
db.imsiRecord.aggregate([ {$match: { "uptime": { $gte: ISODate("2022-06-17 00:00:00") / 1000, $lte: ISODate("2022-06-18 00:00:00") / 1000 }, "deviceId" : /ZDK/, }}, {$project: { "imsi": 1, "uptime": 1, "day": { $dateToString:{ format:"%Y-%m-%d", date:{$add:[new Date(0), {$multiply: ["$uptime", 1000]}, 28800000]}, }}, }}, {$group: { _id: "$day", count: {$sum: 1}, }}, {$sort: {_id:1}}, ]);
注意,需要特殊处理的是uptime这个字段,因为单位是秒,需要处理成毫秒,所以额外乘以1000,输出结果大致如下:
数据量大的话,这将是一个比较耗时的操作,慎用!!!

