JAVA 草稿
1. 项目启动报错:Failed to start bean 'documentationPluginsBootstrapper'
度娘解释:swagger 的匹配模式进行调整导致,导致默认的匹配默认在spring boot中不会使用,导致报错。
处理方式:(不建议降低spring boot 版本,调整太大了)
2. spring gateway路由出现503
是因为在Spring Cloud 2020版本以后,默认移除了对Netflix的依赖,其中就包括Ribbon,官方默认推荐使用Spring Cloud Loadbalancer正式替换Ribbon,并成为了Spring Cloud负载均衡器的唯一实现,只需要将含有这个过滤器的依赖进行导入就行了
4. List 转为 Map
5. MVC(MODEL、VIEW、Controller)
软件构建模式,常见的分层思想,主要用于网站建立。
- 视图层(view):是指界面层,也就是HTML代码那部分
- 模型图(model):是对应的页面,给界面使用的
Model实体类 - 控制层(controller):可以操作模型层的实体,它控制数据流向模型对象,并在数据变化时更新视图。它强制使用视图与模型分开
6. WebAPI(对接方式)
是用于服务和服务对接方式,现阶段多用于前后端分离。
开发模式类似MVC,只是view层,由后端开发改为前端开发。
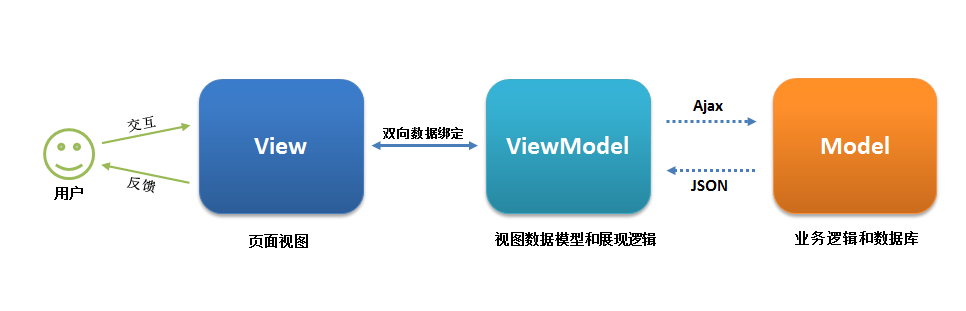
7. MVVM(Model-View-ViewModel)
软件设计模式,MVC 的升级版。前端架构vue
View: 没变。与MVC一样,就是页面,被css渲染后的html页面。永远不能与model进行交互。
Model:感觉没变。
- MVVM中Model 是指整个后端,包括数据与业务逻辑,我认为就是指对接返回的数据。
- 数据和业务逻辑
- 由data entities, business objects, repositories and services构成业务流程
- MVC中Model 是指数据库查询后的数据实体类
- 由data entities, dto 构成的数据载体
ViewModel: 与 controller 相同也不同。
- 相同点:都是沟通 models与view 的渠道。
- 不同点:
- ViewModel紧连view,归属于前端部分,就是vue中我们开发的部分。
- Controller归属于后端部分
8. yml文件定义参数
String、对象、集合、map、ListMap(集合套map) 添加实例
获取方法1:
@Value获取yml文件中单个配置值,可以是字符串、对象、数组等,复制到对应代码的对象中
例如:
获取方法2:
@ConfigurationProperties("cus") 获取yml文件中多个配置值,按照引用名称进行匹配。可以认为是多个@value一起使用
9. Redis 内容乱码
设置 redisTemplate 的序列化。序列化类型,key 使用 string类型序列化,value 使用 json类型序列化
10. MapStruct 部分字段没有映射成功
项目中使用MapStruct进行转换,在实体类User与UserDto中添加新的字段,但是项目运行后,并没有进行赋值。其它字段转换没有问题。
MapStruct的原理:通过映射方式,将User与UserDto中对应属性相互赋值
可能存在问题1:
字段名称不同。在不使用@mapping注释时,二者之间是通过字段名称进行映射的。
可能存在问题2:
实现类没有更新。MapStruct会自动生成实现类,也就是class文件。由于是MapStruct生成的,并不会随之代码的变动而实时变动。通过jd-gui.exe反编译查看impl文件,可以发现此问题。
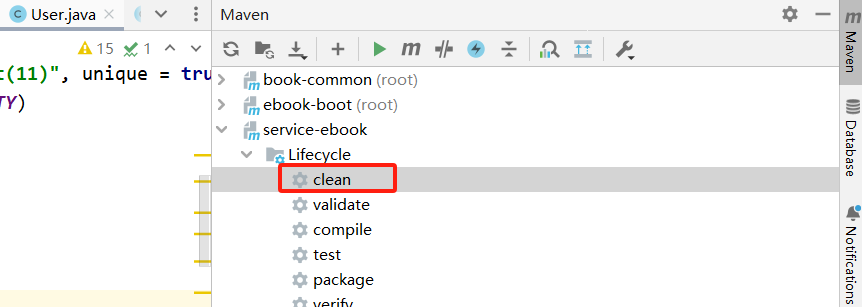
处理方式:使用maven的clean命令,可以清除class文件(trage文件夹)
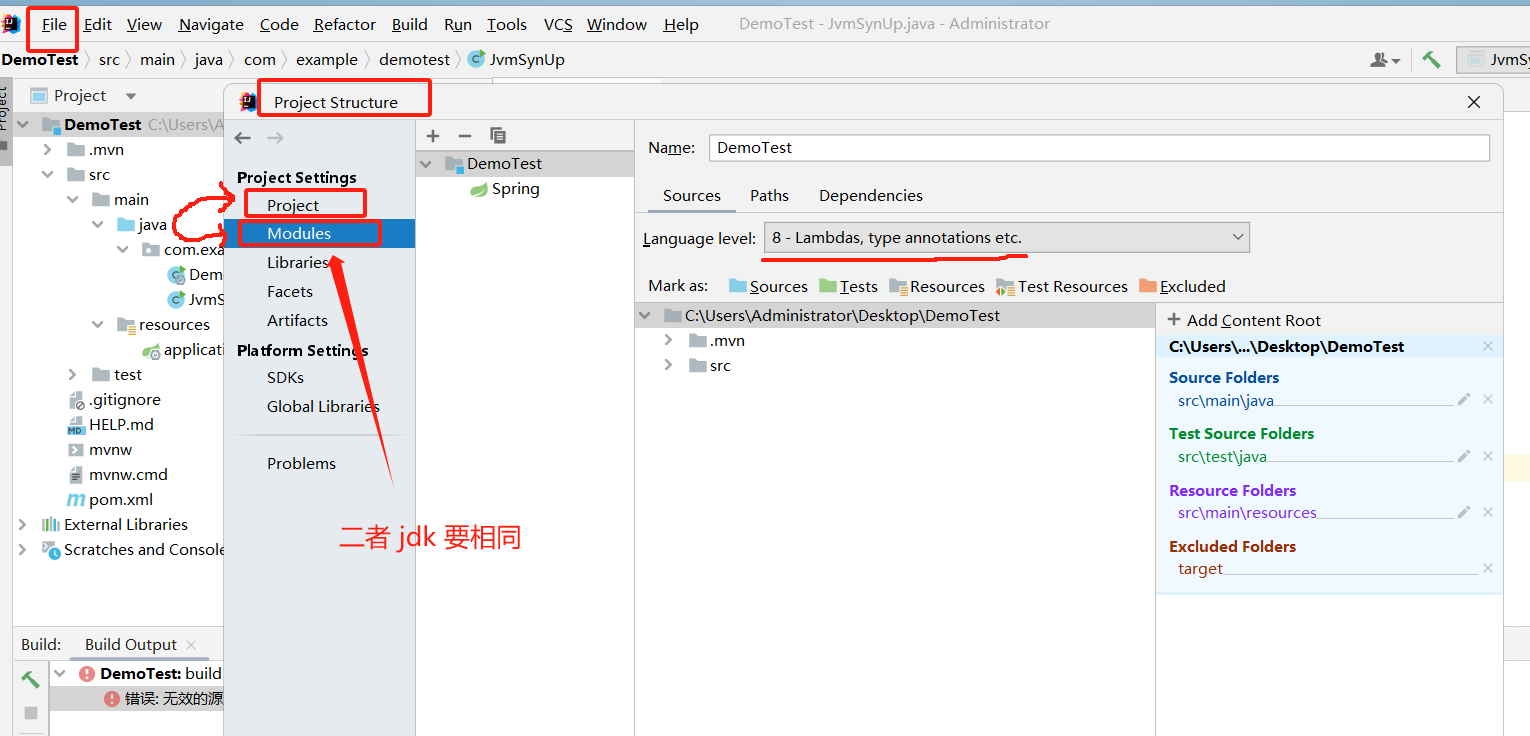
11. java: 错误: 无效的源发行版:17
报错原因是JDK版本不一致。IDE设置的项目JDK与写代码时的JDK不一致。
实际上,我的问题是,在IDEA创建的springboot 3+版本时选择配置了jdk8。但springboot 3+版本已经放弃了JDK8,默认改为JDK17。所以明面上不管怎么调整JDK8的配置,都会报这个错误。
改为JDK17就好了~~~~~~~
12. Oracle 跨库查询
__EOF__

本文链接:https://www.cnblogs.com/zz-1q/p/17375031.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人