02*:光栅化、CoreAnimation渲染流程、屏幕撕裂、卡顿(掉帧) 、图形移动、渲染正方形
问题
目录
1:光栅化
2:CoreAnimation渲染流程
3: 屏幕撕裂、卡顿(掉帧)
4: 图形移动、渲染正方形
预备
正文
1:光栅化
1.1 CPU
加载资源,对象的创建和销毁,对象属性的调整、布局计算、Autolayout、文本渲染,文本的计算和排版、
图片格式转码和解码、图像的绘制(Core Graphics)都是在CPU上面进行的。
1.2 GPU
纹理的渲染(OpenGL)
GPU是一个专门为图形高并发计算而量身定做的处理单元,比CPU使用更少的电来完成工作并且GPU的浮点计算能力要超出CPU很多。
GPU的渲染性能要比CPU高效很多,同时对系统的负载和消耗也更低一些,所以在开发中,我们应该尽量让CPU负责主线程的UI调动,把图形显示相关的工作交给GPU来处理,当涉及到光栅化等一些工作时,CPU也会参与进来。
相对于CPU来说,GPU能干的事情比较单一:接收提交的纹理(Texture)和顶点描述(三角形),应用变换(transform)、混合(合成)并渲染,然后输出到屏幕上。通常你所能看到的内容,主要也就是纹理(图片)和形状(三角模拟的矢量图形)两类。
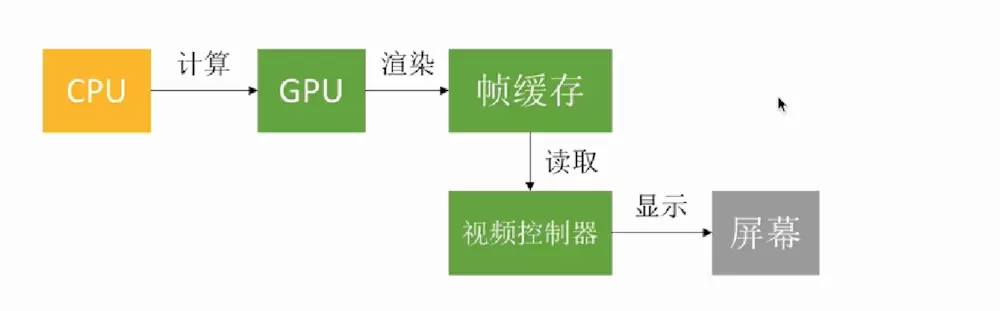
要在屏幕上显示视图,需要CPU和GPU一起协作,CPU计算好显示的内容提交到GPU,GPU渲染完成后将结果放到帧缓存区,随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过可能的数模转换传递给显示器显示。
iOS使用的是双缓冲机制。即GPU会预先渲染好一帧放入一个缓冲区内(前帧缓存),让视频控制器读取,当下一帧渲染好后,GPU会直接把视频控制器的指针指向第二个缓冲器(后帧缓存)。当你视频控制器已经读完一帧,准备读下一帧的时候,GPU会等待显示器的VSync信号发出后,前帧缓存和后帧缓存会瞬间切换,后帧缓存会变成新的前帧缓存,同时旧的前帧缓存会变成新的后帧缓存.
1.3 内存
内存是计算机中重要的部件之一,它是外存与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,
因此内存的性能对计算机的影响非常大。
内存(Memory)也被称为内存储器和主存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。
只要计算机在运行中,操作系统就会把需要运算的数据从内存调到CPU中进行运算,
当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
内存条是由内存芯片、电路板、金手指等部分组成的。
1.4 显存
显存,也被叫做帧缓存,它的作用是用来存储显卡芯片处理过或者即将提取的渲染数据。
如同计算机的内存一样,显存是用来存储要处理的图形信息的部件。
1.5 计算机显示方式演变
1.5.1 随机扫描显示
随机扫描原理: 类似于之前的那种大屁股电视,里面是利用光束进行的扫描
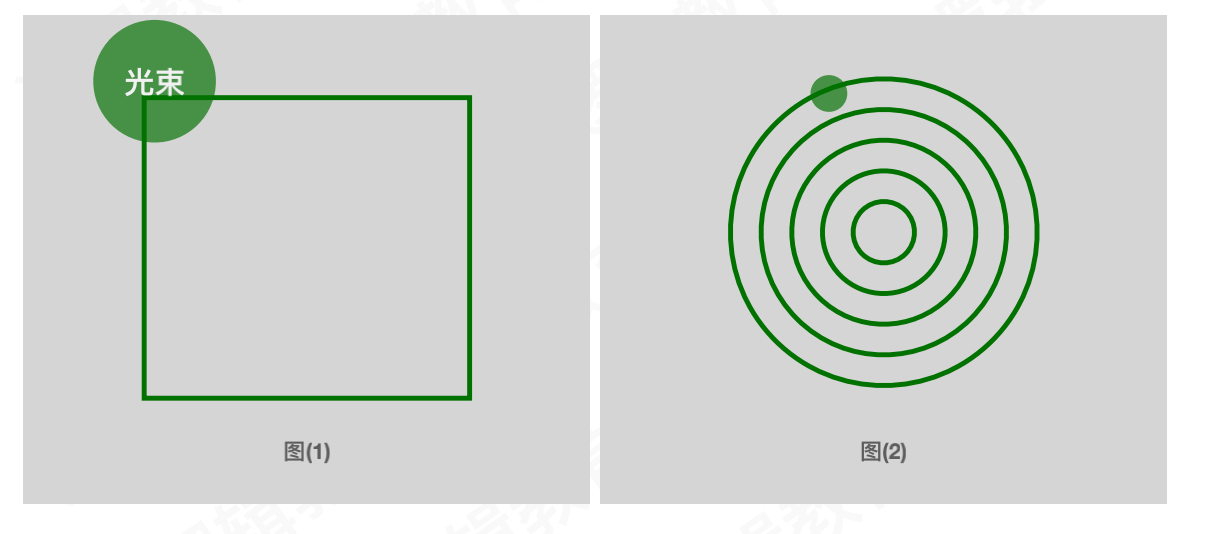
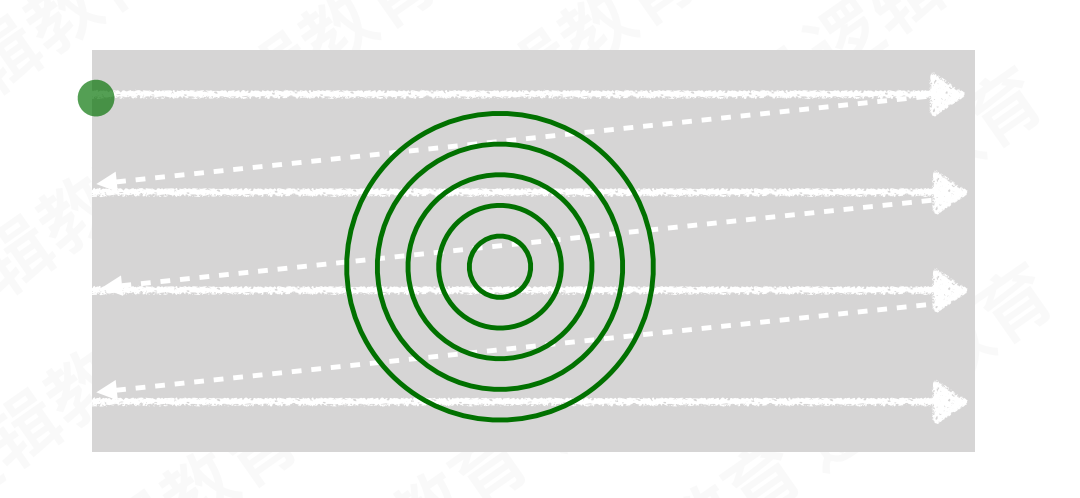
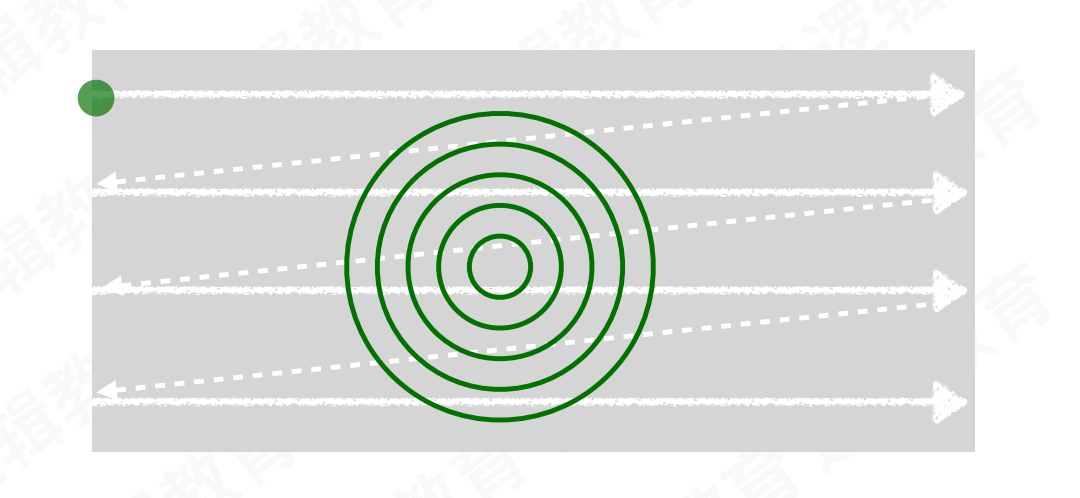
1.5.2 光栅扫描显示
沿着屏幕一行一行的进行扫描
2:CoreAnimation渲染流程
1:CoreAnimation,提供了高帧率和平滑的动画,使CPU没有负担也没有减慢你的应用程序。能够完成绘制动画的每一帧所需的大部分工作。可以配置动画参数,比如开始点和结束点,然后Core animation完成其余的工作,将大部分工作交给专用的图形硬件来加速渲染(GPU)
Core Animation位于AppKit和UIKit之下,紧密集成到Cocoa和Cocoa Touch的视图工作流中。当然,Core Animation也有接口,可以扩展应用程序视图所暴露的功能,让你对应用程序的动画有更细粒度的控制
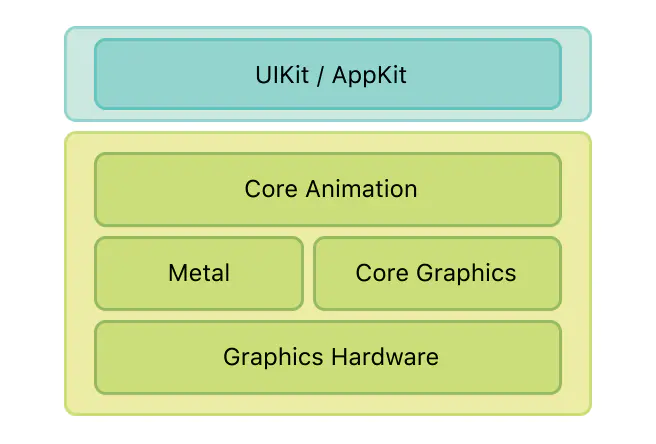
2:Core Animation,它本质上可以理理解为一个复合引擎,主要职责包含:渲染、构建和实现动画。
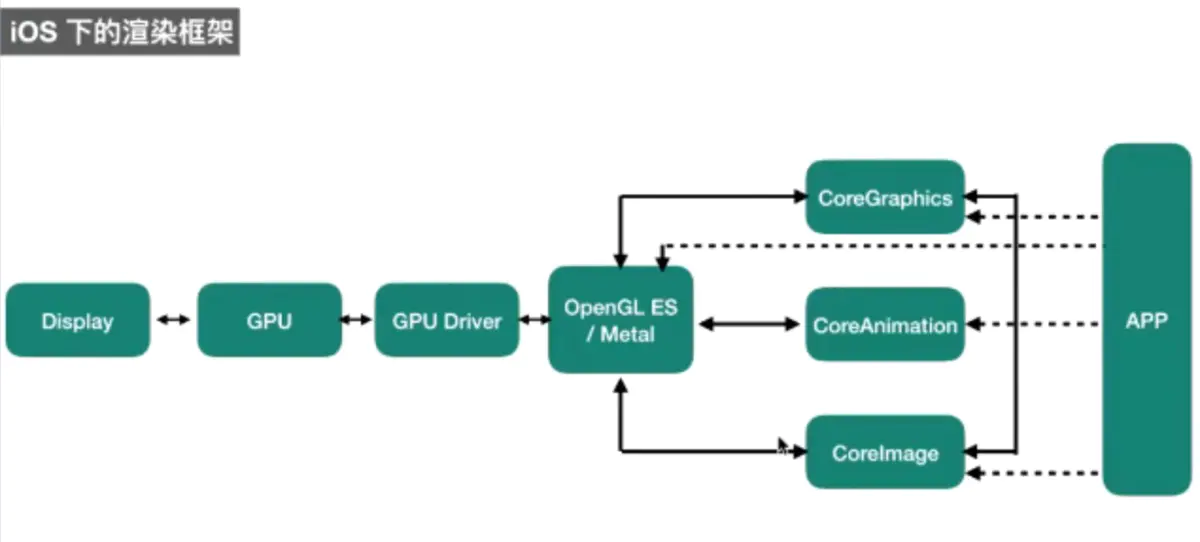
CoreAnimation,是一个复合引擎,其职责是 尽可能快地组合屏幕上不同的可视内容,这些可视内容可被分解成独立的图层(即 CALayer),这些图层会被存储在一个叫做图层树的体系之中。从本质上而言,CALayer 是用户所能在屏幕上看见的一切的基础.
CoreGraphics, 基于 Quartz 高级绘图引擎,主要用于运行时绘制图像。开发者可以使用此框架来处理基于路径的绘图,转换,颜色管理,离屏渲染,图案,渐变和阴影,图像数据管理,图像创建和图像遮罩以及 PDF 文档创建,显示和分析。当开发者需要在 运行时创建图像 时,可以使用 Core Graphics 去绘制。与之相对的是 运行前创建图像,例如用 Photoshop 提前做好图片素材直接导入应用。相比之下,我们更需要 Core Graphics 去在运行时实时计算、绘制一系列图像帧来实现动画
CoreImage,Core Image 与 Core Graphics 恰恰相反,Core Graphics 用于在 运行时创建图像,而 Core Image 是用来处理 运行前创建的图像 的。Core Image 框架拥有一系列现成的图像过滤器,能对已存在的图像进行高效的处理。大部分情况下,Core Image 会在 GPU 中完成工作,但如果 GPU 忙,会使用 CPU 进行处理。
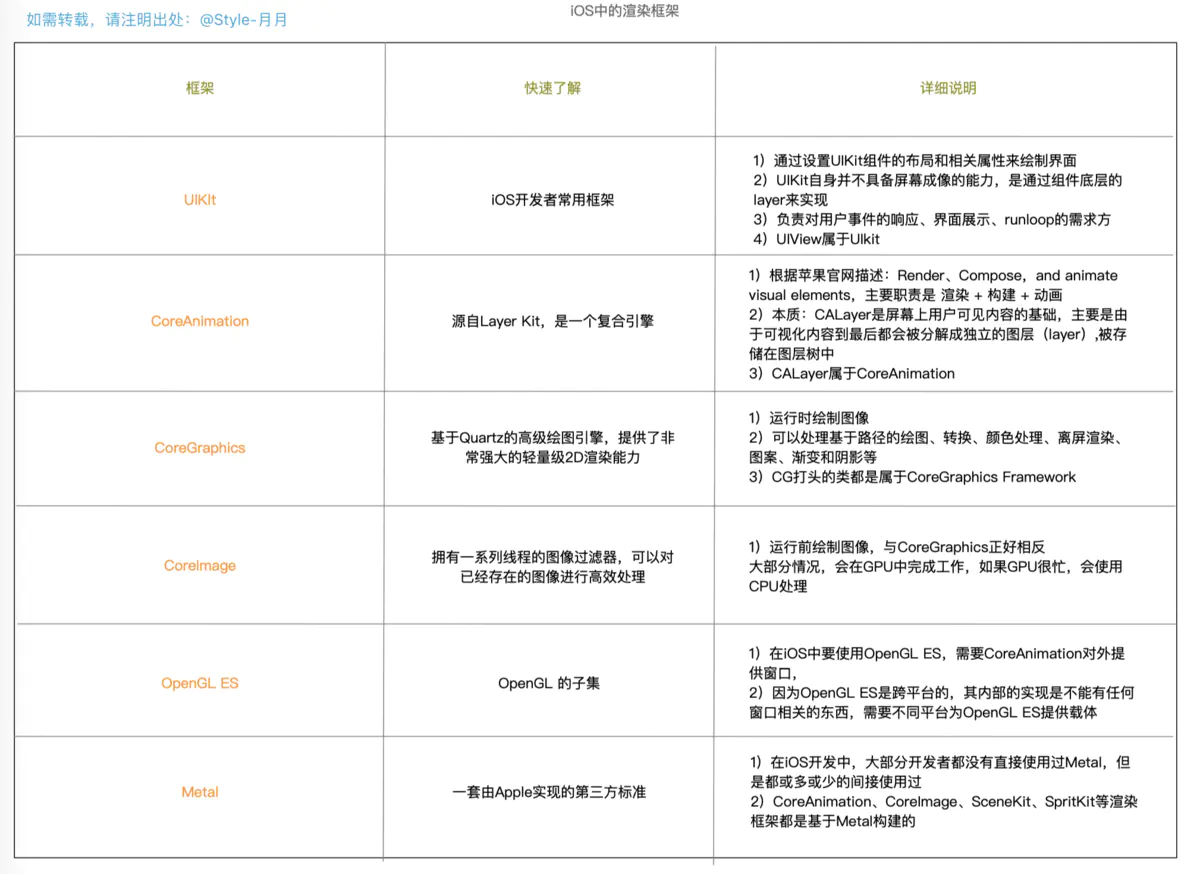
3:iOS中渲染框架总结
主要由以下六种框架,表格中已经说明了,就不再详细解释了
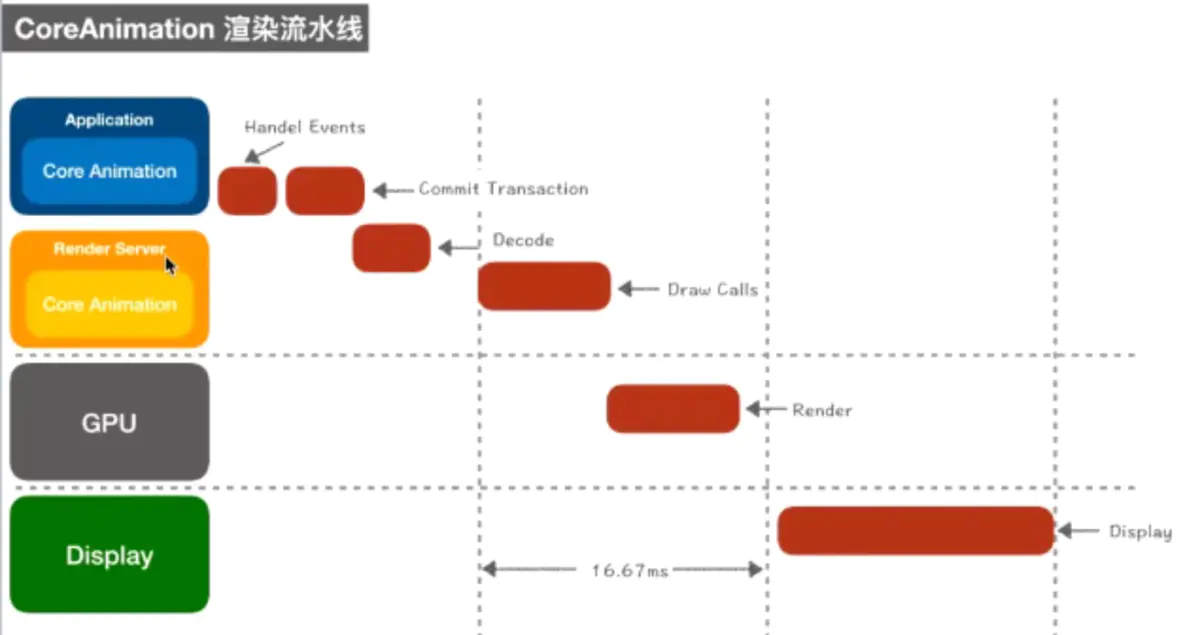
App本身并不负责渲染,渲染由独立进程Render Server负责
首先,App处理事件(HandleEvents:事件处理)
其次,App通过CPU完成对显示内容的计算(如:视图创建、布局、图片解码、文本绘制)
在完成以上两步之后,App对图层进行打包,在下一个Runloop到来时,将打包数据发送给Render Server(即:完成一次Commit Transaction)
Render Server主要执行OpenGL、CoreGraphice程序,OpenGL调度GPU
GPU在物理层上完成渲染流程(顶点数组,顶点着色器,片元着色器)
最后:等到下一个Runloop,进行显示
4:主要分为两部分:
- CoreAnimation部分
- GPU部分
CoreAnimation部分
- App处理UIView、UIButton等载体的事件,然后通过CPU完成对显示内容的计算,并将计算后的图层进行打包,在下一次runloop时,发送到渲染服务器
-
Render Server中主要对收到的准备显示的内容进行解码,然后执行OpenGL等相关程序,并调用GPU进行渲染
==> Render Server 操作分析
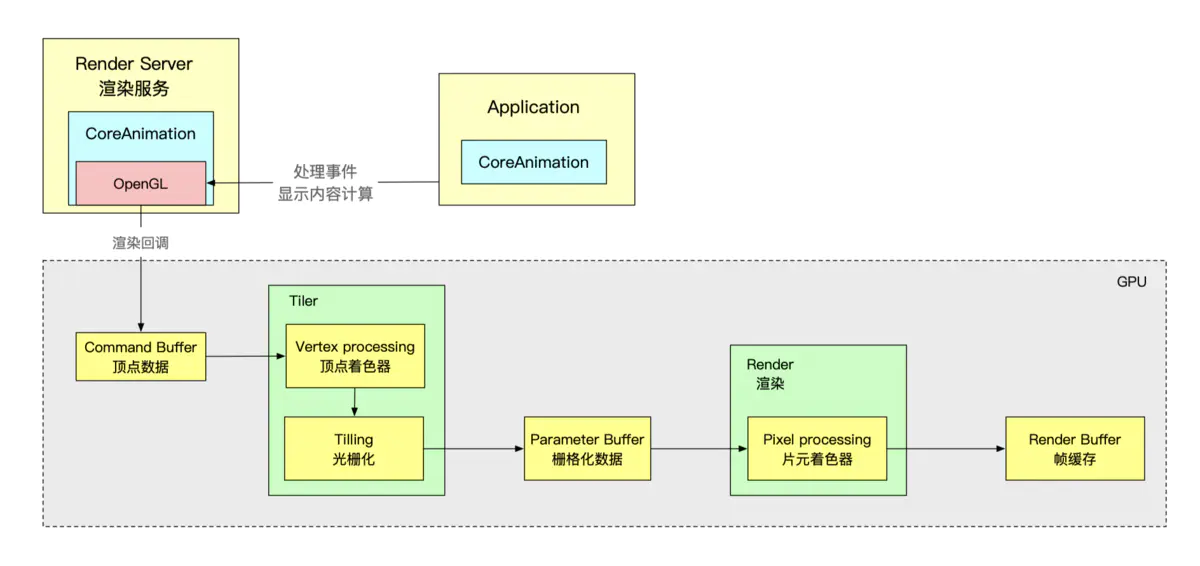
GPU部分
- GPU中通过顶点着色器、片元着色器完成对显示内容的渲染,将结果存入帧缓存区
- GPU通过帧缓存区、视频控制器等相关部件,将其显示到屏幕上
在实际开发过程中,通常会对界面渲染进行优化(防止卡顿出现),卡顿的出现其实与渲染是息息相关的:
CPU完成对显示内容的计算(如:视图创建、布局、图片解码、文本绘制)后,提交数据到GPU,GPU渲染完成后,将渲染结果放入到帧缓存区,视频控制器读取帧缓存区信息进行数模转换(数字信号转化为模拟信号),逐行扫描视图控制器从帧缓存区读取数据,然后显示到屏幕
在这个过程通常会伴随两种情况,图片的撕裂与掉帧。
1:屏幕卡顿
为什么会出现这种情况呢?下面就来详细解说下屏幕卡顿
【高频面试题】屏幕卡顿的原因
主要有以下三种原因
- CPU和GPU在渲染的流水线中耗时过长,导致从缓存区获取位图显示时,下一帧的数据还没有准备好,获取的仍是上一帧的数据,产生掉帧现象,掉帧就会导致屏幕卡顿
- 苹果官方针对屏幕撕裂问题,目前一直使用的方案是
垂直同步+双缓存区,可以从根本上防止和解决屏幕撕裂,但是同时也导致了新的问题掉帧。虽然我们采用了双缓存区,但是我们并不能解决CPU和GPU处理图形图像的速度问题,导致屏幕在接收到垂直信号时,数据尚未准备好,缓存区仍是上一帧的数据,因此导致掉帧 - 在垂直同步+双缓存区的方案上,再次进行优化,将双缓存区,改为
三缓存区,这样其实也并不能从根本上解决掉帧的问题,只是比双缓存区掉帧的概率小了很多,仍有掉帧的可能性,对于用户而言,可能是无感知的。
接下来,详细解析下屏幕撕裂及掉帧问题
2:屏幕撕裂
如图所示,屏幕撕裂就类似于这样的情形

屏幕成像过程
请看下面这张图,详细说明了屏幕成像的一个流程
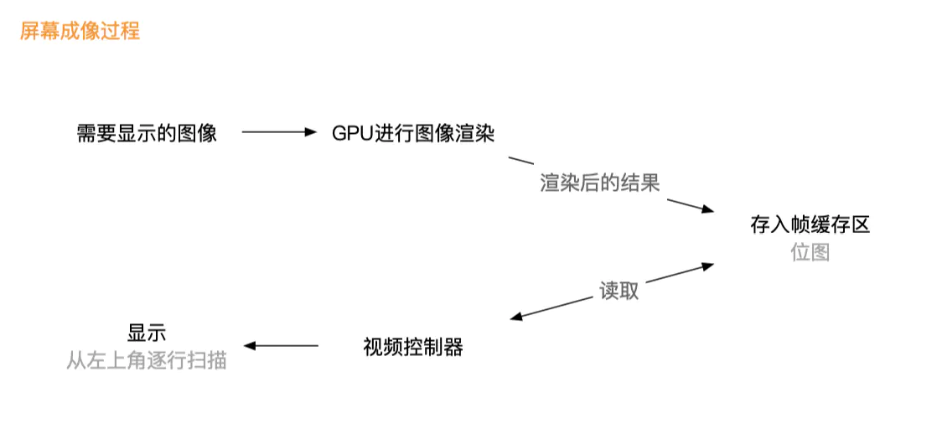
- 将需要显示的图像,经由GPU渲染
- 将渲染后的结果,存储到帧缓存区,帧缓存区中存储的格式是位图
- 由视屏控制器从帧缓存区中读取位图,交由显示器,从左上角逐行扫描进行显示
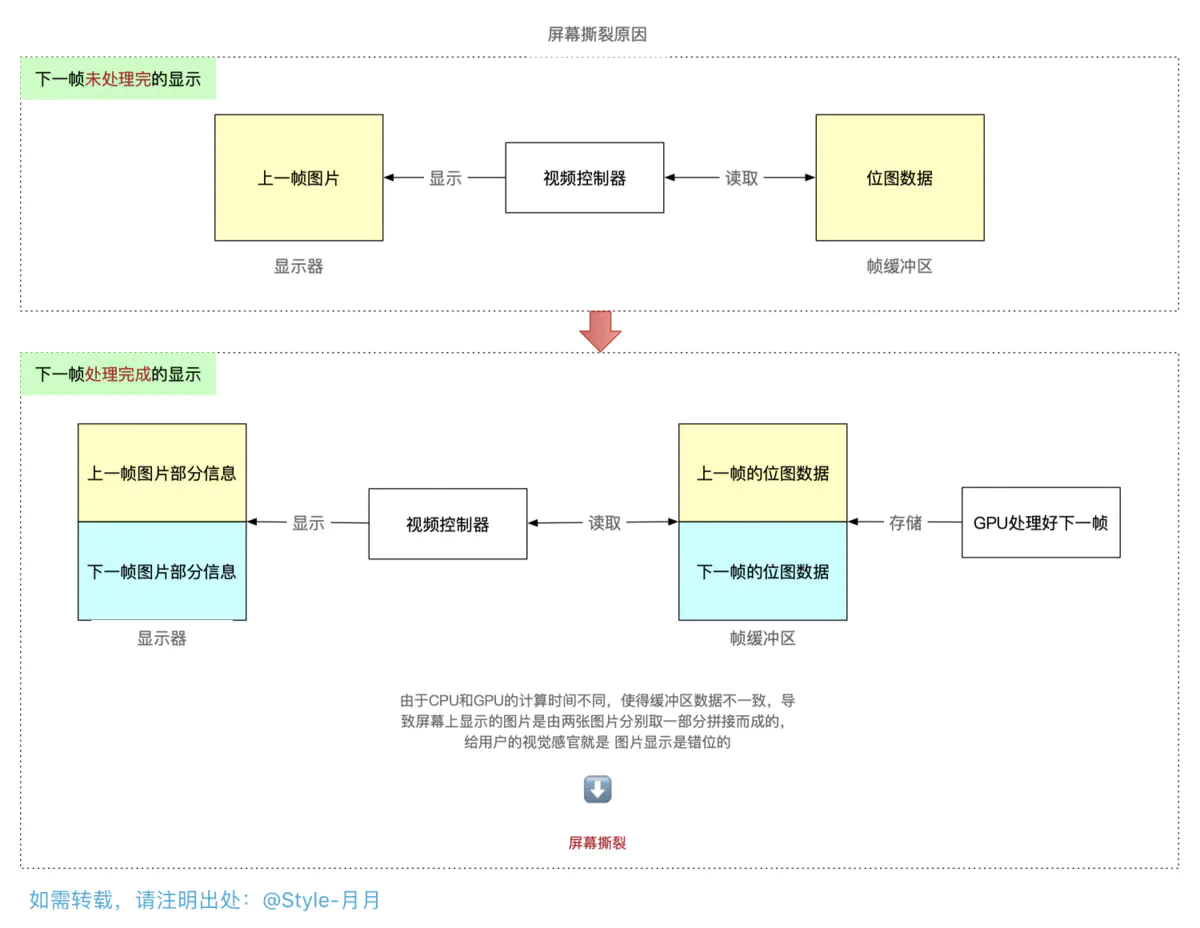
屏幕撕裂的原因
- 在屏幕显示图形图像的过程中,是不断从帧缓存区获取一帧一帧数据进行显示的,
- 然后在渲染的过程中,帧缓存区中仍是旧的数据,屏幕拿到旧的数据去进行显示,
-
在旧的数据没有读取完时 ,新的一帧数据处理好了,放入了缓存区,这时就会导致屏幕另一部分的显示是获取的新数据,从而导致屏幕上呈现图片不匹配,人物、景象等错位显示的情况。
图示如下:
3:苹果官方的解决方案
苹果官方针对屏幕撕裂现象,目前一直采用的是 垂直同步+双缓存,该方案是强制要求同步,且是以掉帧为代价的。
以下是垂直同步+双缓存的一个图解过程,如有描述错误的地方,欢迎留言指出

- 垂直同步:是指给帧缓冲加锁,当电子光束扫描的过程中,只有扫描完成了才会读取下一帧的数据,而不是只读取一部分
- 双缓冲区:采用两个帧缓冲区用途GPU处理结果的存储,当屏幕显示其中一个缓存区内容时,另一个缓冲区继续等待下一个缓冲结果,两个缓冲区依次进行交替
4:掉帧
采用苹果的双缓冲区方案后,又会出现新的问题,掉帧。
什么是掉帧?简单来说就是 屏幕重复显示同一帧数据的情况就是掉帧
如图所示:当前屏幕显示的是A,在收到垂直信号后,CPU和GPU处理的B还没有准备好,此时,屏幕显示的仍然是A
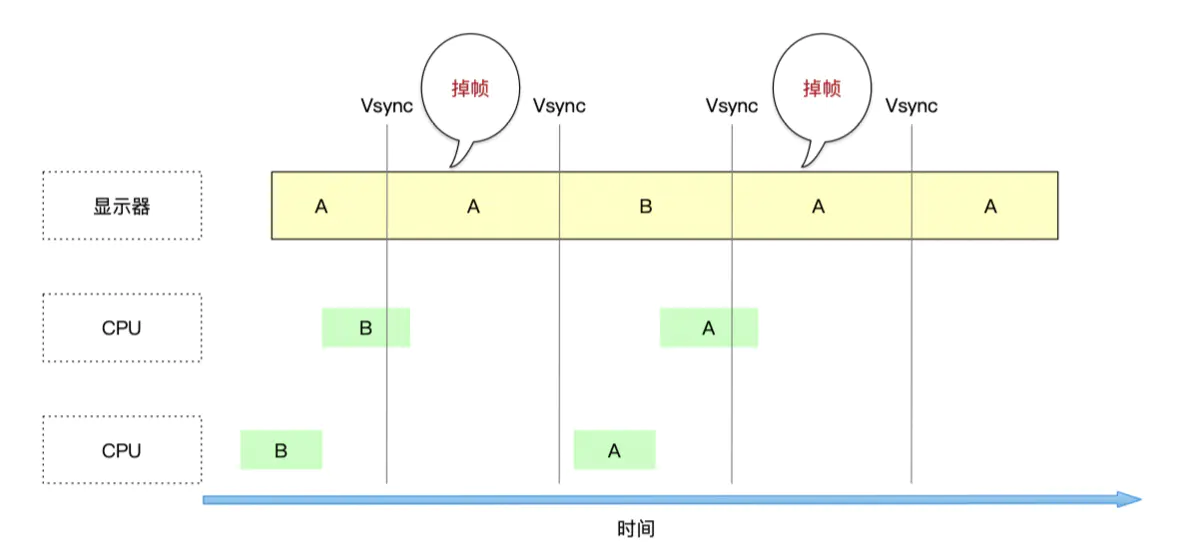
- 针对掉帧情况,我们可以在苹果方案的基础上进行优化,即采用
三缓存区,意味着,在屏幕显示时,后面还准备了3个数据用于显示。
三:UIView和CALayer的区别
首先分别简单说下UIView和CALayer各自的作用
1:UIView
- UIView属于UIKIt
- 负责绘制图形和动画操作
- 用于界面布局和子视图的管理
- 处理用户的点击事件
2:CALayer
- CALayer属于CoreAnimation
- 只负责显示,且显示的是位图
- CALayer既用于UIKit,也用于APPKit,
==> UIKit是iOS平台的渲染框架,APPKit是Mac OSX系统下的渲染框架,
==> 由于iOS和Mac两个系统的界面布局并不是一致的,iOS是基于多点触控的交互方式,而Mac OSX是基于鼠标键盘的交互方式,且分别在对应的框架中做了布局的操作,所以并不需要layer载体去布局,且不用迎合任何布局方式。
3:【面试题】UIView和CALayer的关系
- UIView基于UIKit框架,可以处理用户触摸事件,并管理子视图
- CALayer基于CoreAnimation,而CoreAnimation是基于QuartzCode的。所以CALayer只负责显示,不能处理用户的触摸事件
- 从父类来说,CALayer继承的是NSObject,而UIView是直接继承自UIResponder的,所以UIVIew相比CALayer而言,只是多了事件处理功能,
- 从底层来说,UIView属于UIKit的组件,而UIKit的组件到最后都会被分解成layer,存储到图层树中
- 在应用层面来说,需要与用户交互时,使用UIView,不需要交互时,使用两者都可以
UIView和CALayer的渲染
下图可以说明view 和 layer之间是如何渲染的
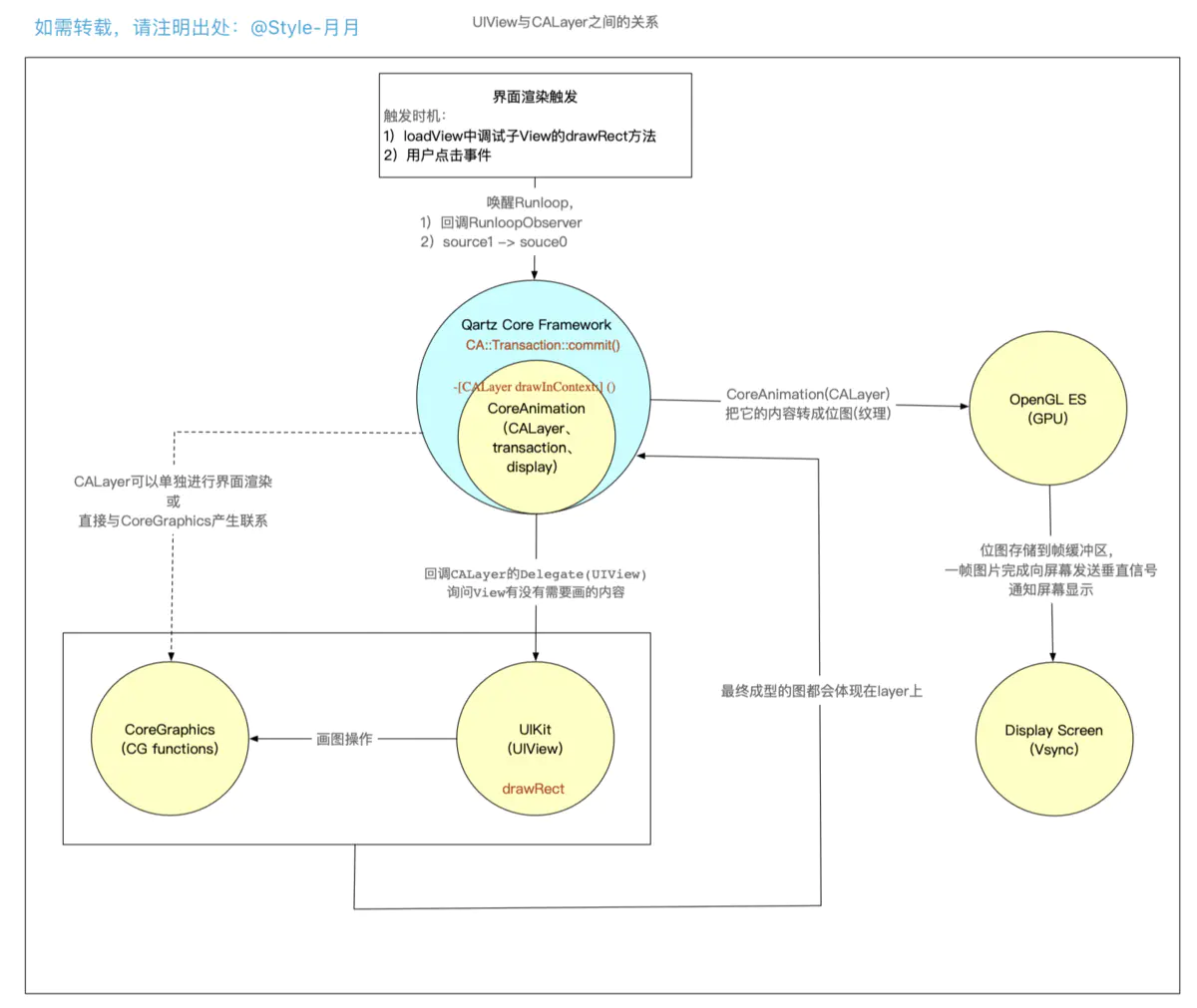
- 界面触发的方式有两种
==> 通过loadView中子View的drawRect方法触发:会回调CoreAnimation中监听Runloop的BeforeWaiting的RunloopObserver,通过RunloopObserver来进一步调用CoreAnimation内部的CA::Transaction::commit(),进而一步步走到drawRect方法
==> 用户点击事件触发:唤醒Runloop,由source1处理(__IOHIDEventSystemClientQueueCallback),并且在下一个runloop里由source0转发给UIApplication(_UIApplicationHandleEventQueue),从而能通过source0里的事件队列来调用CoreAnimation内部的CA::Transaction::commit();方法,进而一步一步的调用drawRect。
最终都会走到CoreAnimation中的CA::Transaction::commit()方法,从而来触发UIView和CALayer的渲染 - 这时,已经到了CoreAnimation的内部,即调用
CA::Transaction::commit();来创建CATrasaction,然后进一步调用CALayer drawInContext:() - 回调CALayer的Delegate(UIView),问UIView没有需要画的内容,即回调到
drawRect:方法 - 在drawRect:方法里可以通过CoreGraphics函数或UIKit中对CoreGraphics封装的方法进行画图操作
- 将绘制好的位图交由CALayer,由OpenGL ES 传送到GPU的帧缓冲区
- 等屏幕接收到垂直信号后,就读取帧缓冲区的数据,显示到屏幕上
四:OpenGL案例-正方形键位控制
1:效果图如下所示:

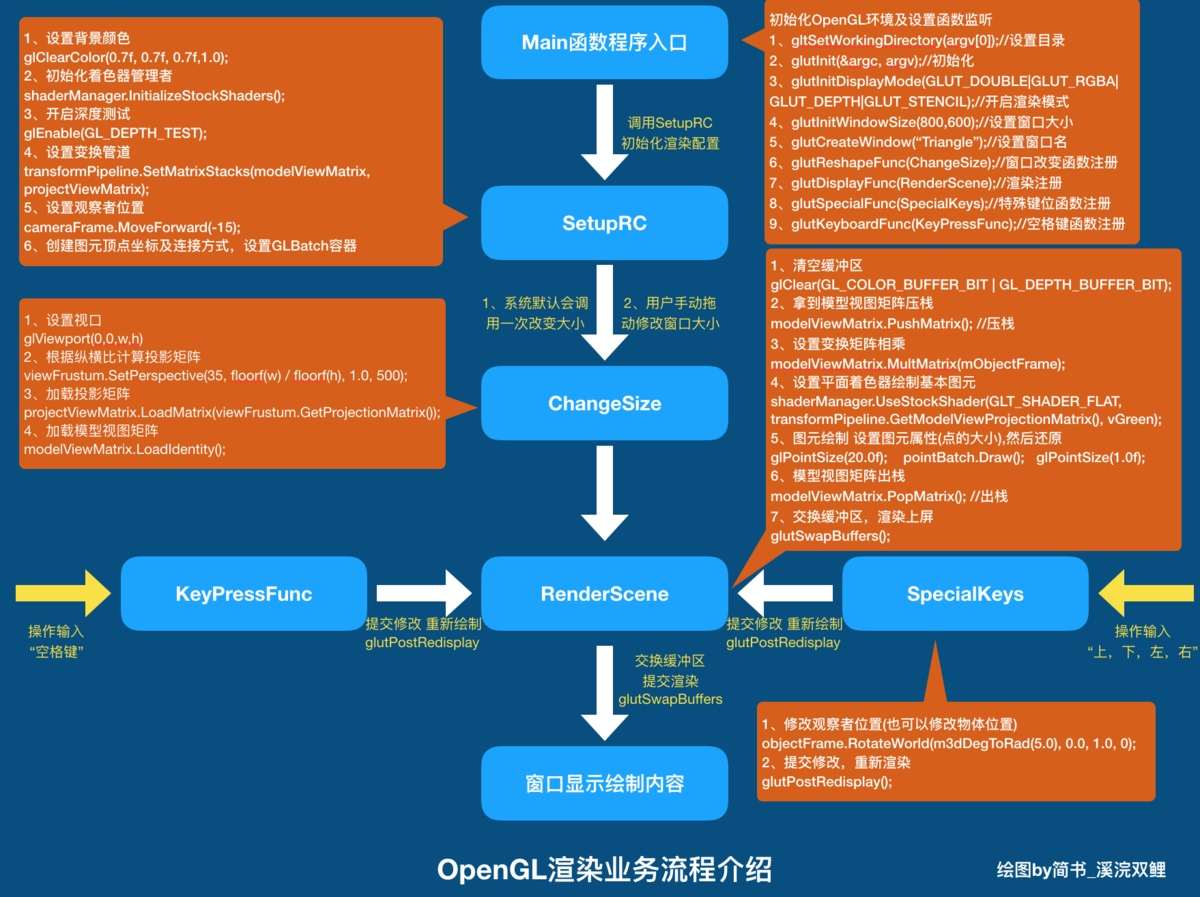
2、流程分析
2.1 程序执行的总流程图
2.2 正方形键位流程图
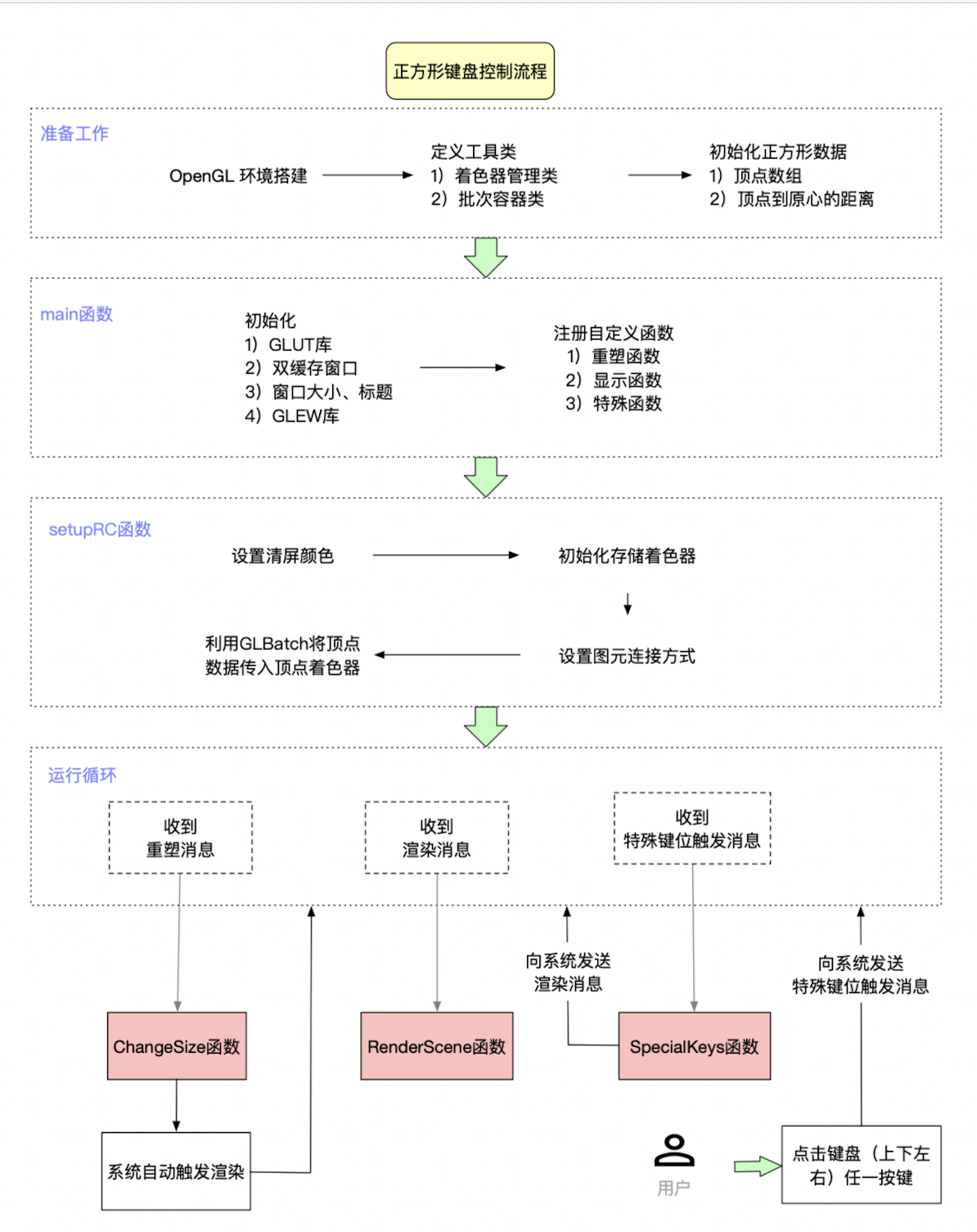
主要需要实现以下两部分:
- 绘制正方形
- 特殊键位移动函数
绘制正方形
在之前的三角形绘制中,我们已经了解了图形绘制的一个基本流程,那么正方形的绘制就是水到渠成的,只需要在三角形代码的基础上做以下修改:
- 定义顶点到坐标轴距离,即
正方形边长 = blockSize * 2
GLfloat blockSize = 0.1f;
- 修改顶点数组
//正方形四个点的坐标 GLfloat vVerts[] = { -blockSize, -blockSize, 0.0f, blockSize, -blockSize, 0.0f, blockSize, blockSize, 0.0f, -blockSize, blockSize, 0.0f, };
- 修改setupRC函数中图元的连接方式
//将 GL_TRIANGLES 修改为 GL_TRIANGLE_FAN ,4个顶点 triangleBatch.Begin(GL_TRIANGLE_FAN, 4);
到此,正方形就绘制完成了,接下来我们需要完成正方形键位控制效果
键位控制效果
主要是指正方形根据选择键盘的上下左右键移动。
该效果的实现有两种方式
- 坐标更新方式
- 矩阵方式
坐标更新方式
顶点根据相对顶点逐个更新顶点坐标,在SpecialKeys函数中完成键位移动时坐标的更新,并手动调用渲染。
三个自定义函数的流程图如下:
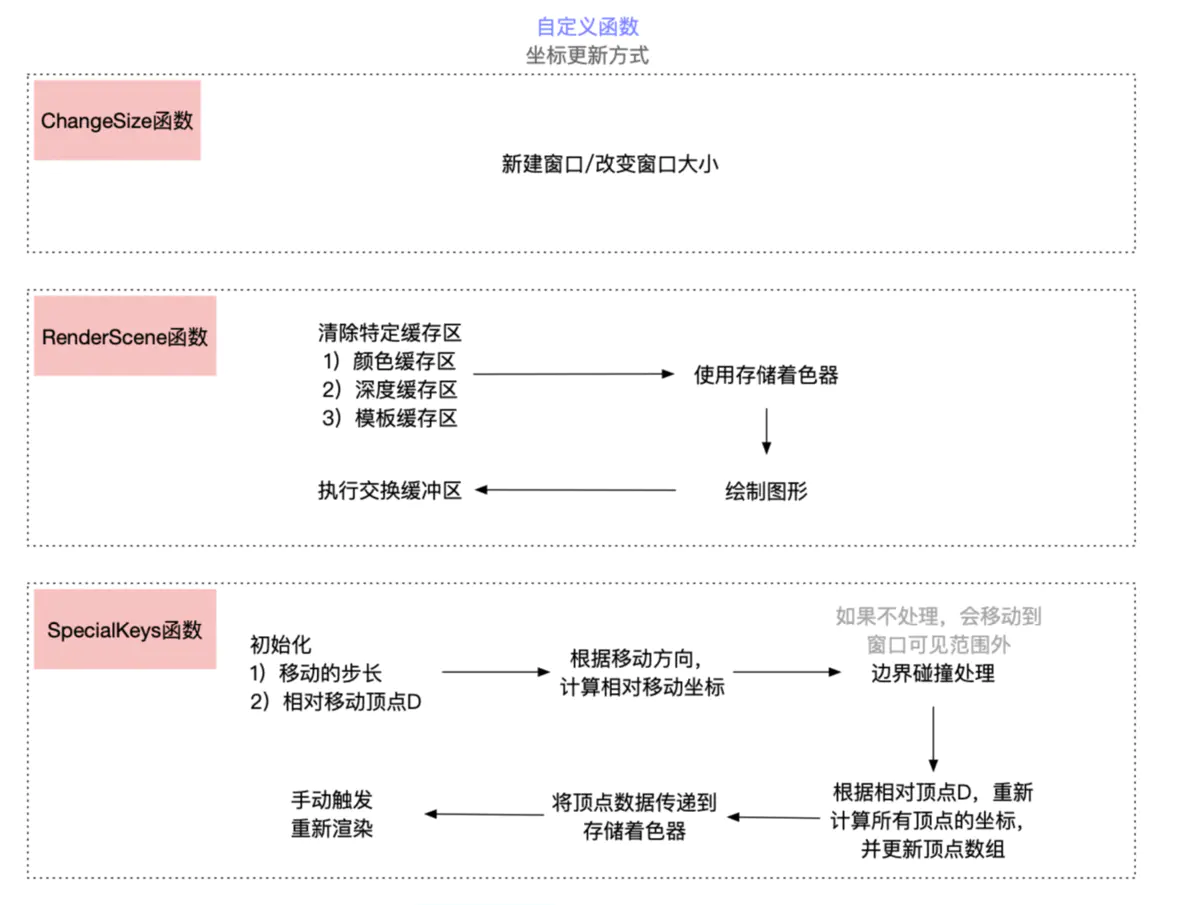
ChangeSize和RenderScene就不做解释了,在绘制时,这部分已经完成了,主要说说SpecialKeys函数
- 首先需要定义一个步长
-
定义一个相对顶点的x和y值
假设正方形如下图所示,以D为相对顶点
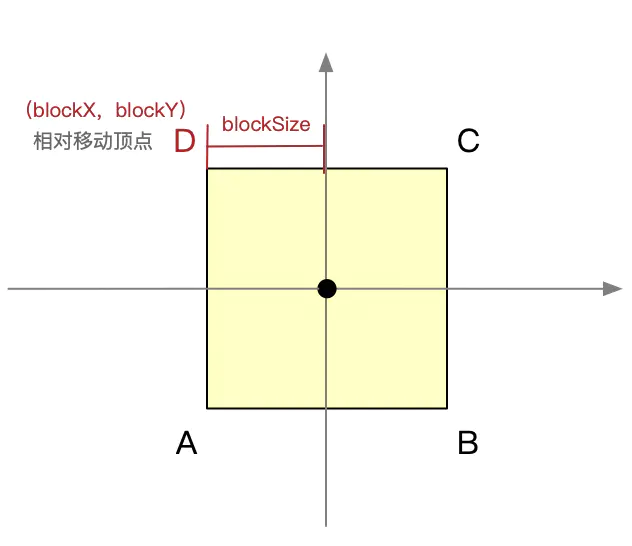
根据键位方向,分别更新x 和 y
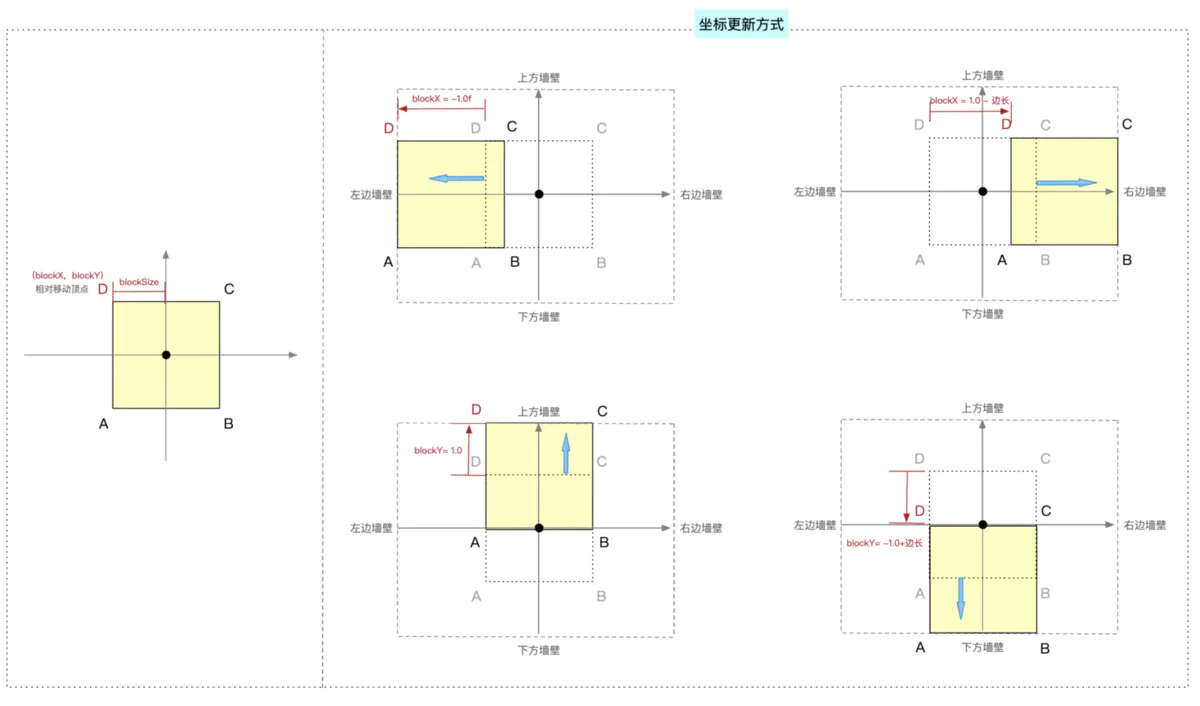
边缘碰撞处理
如果没有这个步骤,图形移动到边缘时,就会移动到屏幕不可见的区域,下图可以说明4个方向对边缘碰撞处理是如何计算的,这里就不做详细说明了
体的代码实现如下:
//key 枚举值,x、y是位置 void SpecialKeys(int key, int x, int y){ //步长 GLfloat stepSize = 0.025f; //相对点的坐标 GLfloat blockX = vVerts[0]; GLfloat blockY = vVerts[10]; printf("v[0] = %f\n",blockX); printf("v[10] = %f\n",blockY); //根据移动方向,更新相对坐标 if (key == GLUT_KEY_UP) { blockY += stepSize; } if (key == GLUT_KEY_DOWN) { blockY -= stepSize; } if (key == GLUT_KEY_LEFT) { blockX -= stepSize; } if (key == GLUT_KEY_RIGHT) { blockX += stepSize; } //触碰到边界(4个边界)的处理 //当正方形移动超过最左边的时候 if (blockX < -1.0f) { blockX = -1.0f; } //当正方形移动到最右边时 //1.0 - blockSize * 2 = 总边长 - 正方形的边长 = 最左边点的位置 if (blockX > (1.0f - blockSize * 2)) { blockX = 1.0f - blockSize * 2; } //当正方形移动到最下面时 //-1.0 - blockSize * 2 = Y(负轴边界) - 正方形边长 = 最下面点的位置 if (blockY < -1.0f + blockSize * 2) { blockY = -1.0f + blockSize * 2; } //当正方形移动到最上面时 if (blockY > 1.0f) { blockY = 1.0f; } printf("blockX = %f\n",blockX); printf("blockY = %f\n",blockY); //重新计算正方形的位置 //一个顶点有三个数 x、y、z vVerts[0] = blockX; vVerts[1] = blockY - blockSize * 2; printf("(%f,%f)\n",vVerts[0],vVerts[1]); vVerts[3] = blockX + blockSize * 2; vVerts[4] = blockY - blockSize * 2; printf("(%f,%f)\n",vVerts[3],vVerts[4]); vVerts[6] = blockX + blockSize * 2; vVerts[7] = blockY; printf("(%f,%f)\n",vVerts[6],vVerts[7]); vVerts[9] = blockX; vVerts[10] = blockY; printf("(%f,%f)\n",vVerts[9],vVerts[10]); //更新顶点数据 triangleBatch.CopyVertexData3f(vVerts); //重新渲染提交 --> RenderScene glutPostRedisplay(); }
矩阵方式
主要是根据x轴、y轴移动的距离,生成一个平移矩阵,通过图形*平移矩阵 = 移动后的图形,得到最终效果
涉及两个函数:RenderScene、SpecialKeys
矩阵方式中自定义函数的流程如下:
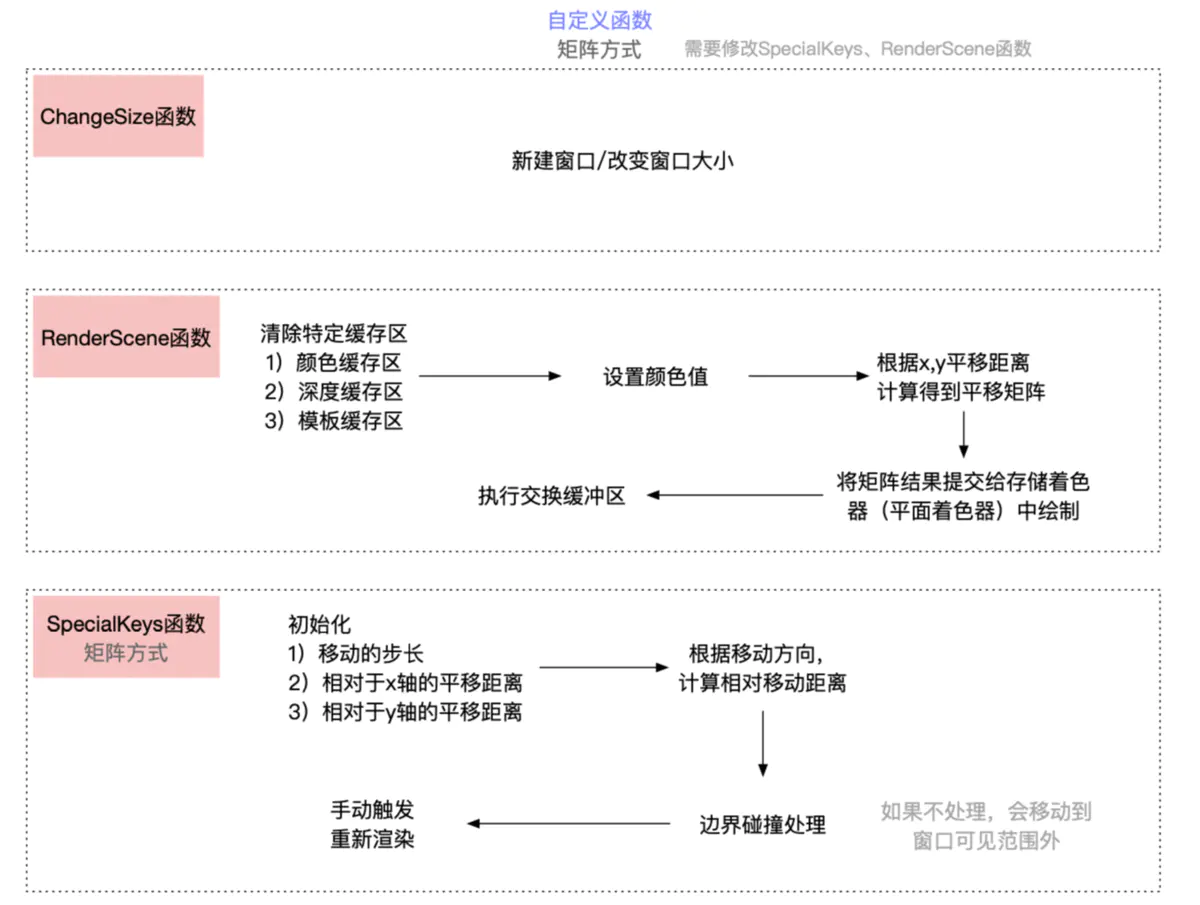
SpecialKeys 函数
- 定义步长及两个全局变量(相对于x轴和y轴的平移距离)
//记录移动图形时,在x轴上平移的距离 GLfloat xPos = 0.0f; //记录移动图形时,在y轴上平移的距离 GLfloat yPos = 0.0f; GLfloat stepSize = 0.025f;
- 根据移动方向,计算移动距离
-
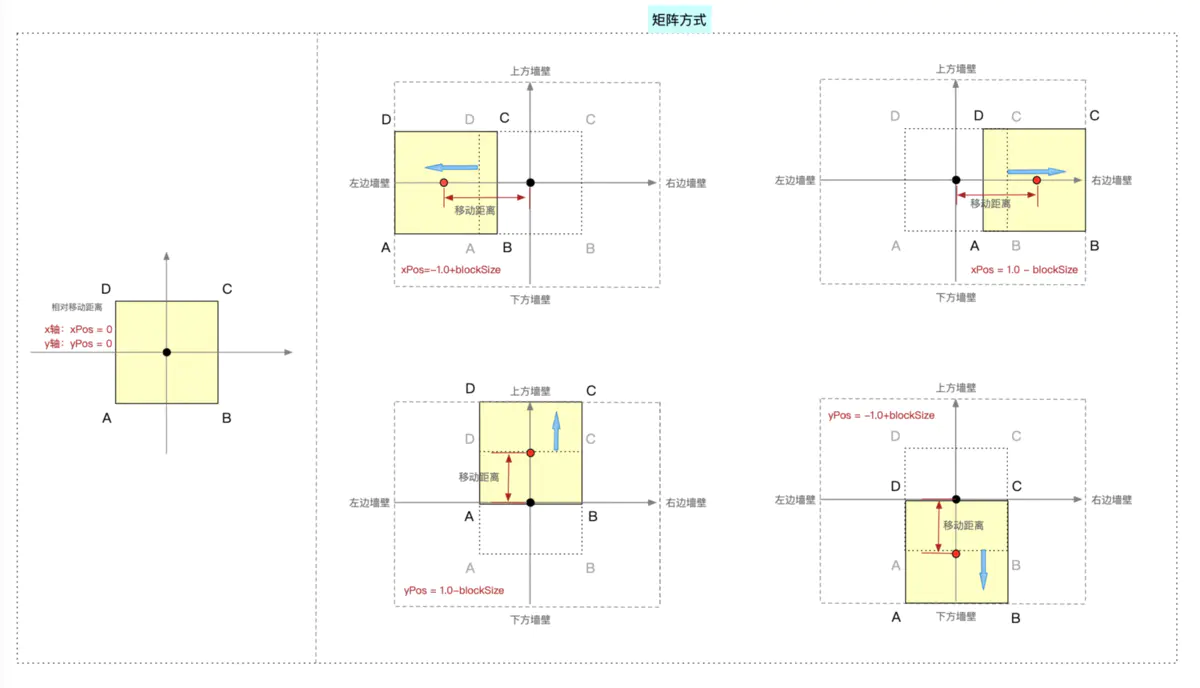
边缘碰撞处理
其移动距离计算的理解如图所示
==> 可以将初始化的平移距离理解为正方形的中心,即原点,在图形移动时,其中心点也发生了移动,所以我们要计算的边缘的移动距离就是两个中心店之间的平移距离
- 手动触发重新渲染
具体实现如下:
//使用矩阵方式(一起搞定),不需要修改每个顶点,只需要记录移动步长,碰撞检测 void SpecialKeys(int key, int x, int y){ GLfloat stepSize = 0.025f; if (key == GLUT_KEY_UP) { yPos += stepSize; } if (key == GLUT_KEY_DOWN) { yPos -= stepSize; } if (key == GLUT_KEY_LEFT) { xPos -= stepSize; } if (key == GLUT_KEY_RIGHT) { xPos += stepSize; } //碰撞检测 xPos是平移距离,即移动量 if (xPos < (-1.0f + blockSize)) { xPos = -1.0f + blockSize; } if (xPos > (1.0f - blockSize)) { xPos = 1.0f - blockSize; } if (yPos < (-1.0f + blockSize)) { yPos = -1.0f + blockSize; } if (yPos > (1.0f - blockSize)) { yPos = 1.0f - blockSize; } glutPostRedisplay(); }
RenderScene 函数
主要步骤如下:
- 清理特定缓存区
- 根据平移距离计算平移矩阵
- 将矩阵结果交给存储着色器(平面着色器)中绘制
在位置更新方式中,使用的是单元着色器,而矩阵方式中,涉及的矩阵是4*4的,单元着色器不够用,所以使用平面着色器
具体的代码实现如下
//开始渲染 void RenderScene(void) { //1.清除一个或者一组特定的缓存区 glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT); //1.设置颜色RGBA GLfloat vRed[] = {1.0f, 0.5f, 0.0f, 1.0f}; //定义矩阵 M3DMatrix44f mTransformMatrix; //平移矩阵 m3dTranslationMatrix44(mTransformMatrix, xPos, yPos, 0.0f); //当单元着色器不够用时,使用平面着色器 //参数1:存储着色器类型 //参数2:使用什么矩阵变换 //参数3:颜色 shaderManager.UseStockShader(GLT_SHADER_FLAT, mTransformMatrix, vRed); //提交着色器 triangleBatch.Draw(); glutSwapBuffers(); }
完整代码见Github -02_正方形键位控制
注意


 浙公网安备 33010602011771号
浙公网安备 33010602011771号