039 *:property 后面可以有哪些修饰符?(线程安全、读写、内存管理)(atomic,nonatomic,readonly,readwrite,assign, copy, strong,weak,Retain)(weak和assign)(浅拷贝、单层深拷贝、深拷贝) 可变数组(环形缓冲区)字典(哈希表)
一:@property 后面可以有哪些修饰符?
1:线程安全的:
atomic,nonatomic
2:访问权限的
readonly,readwrite
3:内存管理(ARC)
assign, copy, strong,weak,
4: 内存管理(MRC)
assign,retain,copy
ARC 下,不显式指定任何属性关键字时,默认的关键字都有哪些?
基本数据: atomic,readwrite,assign
普通的 OC 对象: atomic,readwrite,strong
二、 readwrite,readonly,assign,retain,copy,nonatomic,atomic,strong,weak属性的作用分别是什么。
| 关键字 | 注释 |
|---|---|
| readwrite | 此标记说明属性会被当成读写的,这也是默认属性。 |
| readonly | 此标记说明属性只可以读,也就是不能设置,可以获取。 |
| assign | 不会使引用计数加1,也就是直接赋值。 |
| retain | 会使引用计数加1。 |
| copy | 建立一个索引计数为1的对象,在赋值时使用传入值的一份拷贝。 |
| nonatomic | 非原子性访问,多线程并发访问会提高性能。 |
| atomic | 原子性访问。 |
| strong | 打开ARC时才会使用,相当于retain。 |
| weak | 打开ARC时才会使用,相当于assign,可以把对应的指针变量置为nil。 |
三:原子性:非原子性
开发过程中,setter和getter方法处处都在使用,如果使用atomic修饰,setter和getter方法内部会做很多多线程安全的操作,会很占用系统资源,降低系统性能。
所以在平常开发中原子性(线程安全)一般设置为nonatomic,只有在需要安全的地方atomic
说atomic与nonatomic的本质区别其实也就是在setter方法和get方法的操作不同:加锁
// nonatomic的实现: - (void)setCurrentImage:(UIImage *)currentImage { if (_currentImage != currentImage) { [_currentImage release]; _currentImage = [currentImage retain]; // do something } } - (UIImage *)currentImage { return _currentImage; } // atomic的实现: - (void)setCurrentImage:(UIImage *)currentImage { @synchronized(self) { if (_currentImage != currentImage) { [_currentImage release]; _currentImage = [currentImage retain]; // do something } } } - (UIImage *)currentImage { @synchronized(self) { return _currentImage; } }
四:读写访问权限
读写性的控制(readonly,readwrite,setter,getter)
readonly:只读属性,告诉编译器之声明getter方法,而没有setter(只能读取值,不能被赋值)
readwrite:读写属性,告诉编译器,既声明setter又声明getter方法,readwrite是属性读写性控制的默认修饰词
五:内存权限
1:weak和assign的区别-正确使用weak、assign
很少有人知道
1: weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址数组。
2: 更多人的人只是知道weak是弱引用,所引用对象的计数器不会加一,并在引用对象被释放的时候自动被设置为nil。通常用于解决循环引用问题。
3: 但现在单知道这些已经不足以应对面试了,好多公司会问weak的原理。weak的原理是什么呢?下面就分析一下weak的工作原理(只是自己对这个问题好奇,学习过程中的笔记,希望对读者也有所帮助)。
weak 实现原理的概括
Runtime维护了一个weak表,用于存储指向某个对象的所有weak指针。weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址(这个地址的值是所指对象的地址)数组。
weak 的实现原理可以概括一下三步:
1、初始化时:runtime会调用objc_initWeak函数,初始化一个新的weak指针指向对象的地址。
2、添加引用时:objc_initWeak函数会调用 objc_storeWeak() 函数, objc_storeWeak() 的作用是更新指针指向,创建对应的弱引用表。
3、释放时,调用clearDeallocating函数。clearDeallocating函数首先根据对象地址获取所有weak指针地址的数组,然后遍历这个数组把其中的数据设为nil,最后把这个entry从weak表中删除,最后清理对象的记录。
六:weak和assign区别
区别
a.修饰变量类型的区别
weak 只可以修饰对象。如果修饰基本数据类型,编译器会报错-“Property with ‘weak’ attribute must be of object type”。
assign 可修饰对象,和基本数据类型。当需要修饰对象类型时,MRC时代使用unsafe_unretained。当然,unsafe_unretained也可能产生野指针,所以它名字是"unsafe_”。
b.是否产生野指针的区别
weak 不会产生野指针问题。因为weak修饰的对象释放后(引用计数器值为0),指针会自动被置nil,之后再向该对象发消息也不会崩溃。 weak是安全的。
assign 如果修饰对象,会产生野指针问题;如果修饰基本数据类型则是安全的。修饰的对象释放后,指针不会自动被置空,此时向对象发消息会崩溃。
c、相似
都可以修饰对象类型,但是assign修饰对象会存在问题。
d、总结
assign 适用于基本数据类型如int,float,struct等值类型,不适用于引用类型。
因为值类型会被放入栈中,遵循先进后出原则,由系统负责管理栈内存。
而引用类型会被放入堆中,需要我们自己手动管理内存或通过ARC管理。
weak 适用于delegate和block等引用类型,不会导致野指针问题,也不会循环引用,非常安全。
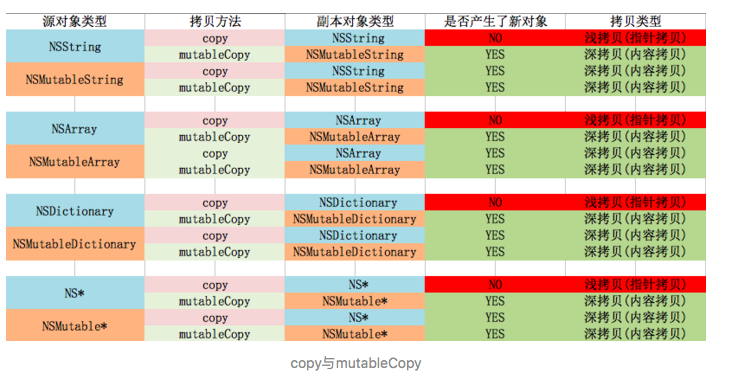
七:copy
1: 怎么用 copy 关键字
NSString、NSArray、NSDictionary 等等经常使用 copy 关键字,是因为他们有对应的可变类型:NSMutableString、NSMutableArray、NSMutableDictionary.
为确保对象中的属性值不会无意间变动,应该在设置新属性值时拷贝一份,保护其封装性.
block,也经常使用 copy,关键字block。
使用 copy 是从 MRC 遗留下来的“传统”,在 MRC 中,方法内部的 block 是在栈区的,使用 copy 可以把它放到堆区.
在 ARC 中写不写都行:对于 block 使用 copy 还是 strong 效果是一样的,但是建议写上 copy,因为这样显示告知调用者“编译器会自动对 block 进行了 copy 操作。
2、用@property 声明的 NSString(或 NSArray,NSDictionary)经常使用 copy 关键字,为什么?如果改用 strong 关键字,可能造成什么问题?
因为父类指针可以指向子类对象,使用 copy 的目的是为了让本对象的属性不受外界影响,使用 copy 无论给我传入是一个可变对象还是不可对象,我本身持有的就是一个不可变的副本.
如果我们使用是 strong,那么这个属性就有可能指向一个可变对象,如果这个可变对象在外部被修改了,那么会影响该属性
c:深浅copy

七:block中copy
1:下面进入主题为什么要用copy去修饰block呢
个人理解:默认情况下,block会存档在栈中(栈是吃了吐),所以block会在函数调用结束被销毁,在调用会报空指针异常,如果用copy修饰的话,可以使其保存在堆区(堆是吃了拉) ,它的生命周期会随着对象的销毁而结束的。只要对象不销毁,我们就可以调用在堆中的block。
在了解block为什么要用copy之前,我们要先了解block的三种类型
一 NSGlobalBlock:全局的静态block 没有访问外部变量 你的block类型就是这种类型(也就是说你的block没有调用其他外部变量)
二 NSStackBlock:保存在栈中的block,没有用copy去修饰并且访问了外部变量,你的block类型就是这种类型,会在函数调用结束被销毁 (需要在MRC)
三 NSMallocBlock 保存在堆中的block 此类型blcok是用copy修饰出来的block 它会随着对象的销毁而销毁,只要对象不销毁,我们就可以调用的到在堆中的block。
2.1:首先,我们要明确一点,为什么要用copy修饰,这是因为在MRC时期,作为全局变量的block在初始化时是被存放在静态区的,这样在使用时如果block内有调用外部变量,那么block无法保留其内存,在初始化的作用域内使用并不会有什么影响,但一但出了block的初始化作用域,就会引起崩溃,使用copy可以将block的内存推入堆中,这样让其拥有保存调用的外部变量的内存的能力。
2.2:(将block存入堆区带来的一个问题,self会持有block的引用,那么在block里使用self会导致循环引用,这也是为什么在MRC和ARC时期要分别用__block和__weak来修饰self的原因)
既然使用copy的原因是为了让Block在初始化作用域外进行正常访问外部变量,那我们就来看使用strong能不能达到这种效果。
3:外部使用了weakSelf,里面使用strongSelf却不会造成循环,究其原因就是因为weakSelf是block截获的属性,而strongSelf是一个局部变量会在“函数”执行完释放。
是为了保证block执行完毕之前self不会被释放,执行完毕的时候再释放。这时候会发现为什么在block外边使用了__weak修饰self,里面使用__strong修饰weakSelf的时候不会发生循环引用?!
4.1:__weak 本身是可以避免循环引用的问题的,但是其会导致外部对象释放了之后,block 内部也访问不到这个对象的问题,我们可以通过在 block 内部声明一个 __strong 的变量来指向 weakObj,使外部对象既能在 block 内部保持住,又能避免循环引用的问题。
4.2:__block 本身无法避免循环引用的问题,但是我们可以通过在 block 内部手动把 blockObj 赋值为 nil 的方式来避免循环引用的问题。
另外一点就是 __block 修饰的变量在 block 内外都是唯一的,要注意这个特性可能带来的隐患。但是__block有一点:这只是限制在ARC环境下。在非arc下,__block是可以避免引用循环的
4.3:另外,MRC中__block是不会引起retain;但在ARC中__block则会引起retain。所以ARC中应该使用__weak。
5:为什么使用weakSelf
通过 clang -rewrite-objc 源代码文件名 将代码转为c++代码(实质是c代码),可以看到block是一个结构体,它会将全局变量(self)保存为一个属性(是__strong的),而self强引用了block这会造成循环 引用。所以需要使用__weak修饰的weakSelf。
为什么在block里面需要使用strongSelf
6: MRC使用了retain修饰的block崩溃掉了,当将MRC切换回ARC,并且把修饰符换为strong时,并没有发生崩溃,说明该block被推入了堆,拥有了保存外部变量内存的能力。
- 如果是ARC(自动)在堆区 NSMallocBlock
- 如果是MRC(手动)在栈区 NSStackBlock
8:__block修饰变量在block内部改变其变量值的原理
Block不允许修改外部变量的值,这里所说的外部变量的值,指的是栈中指针的内存地址。__block 所起到的作用就是只要观察到该变量被 block 所持有,就将“外部变量”在栈中的内存地址放到了堆中。进而在block内部也可以修改外部变量的值。
9:不过在声明Block时,使用strong和retain会有截然不同的效果。strong会等于copy,而retain竟然等于assign!
10:【在ARC下】:似乎已经没有栈上的block了,要么是全局的,要么是堆上的。有一个特殊情况:如果仅仅定义了block没有赋值给变量的话,仍是在栈上,
【在非ARC下】:存在这栈、全局、堆这三种形式。
八:其他问题
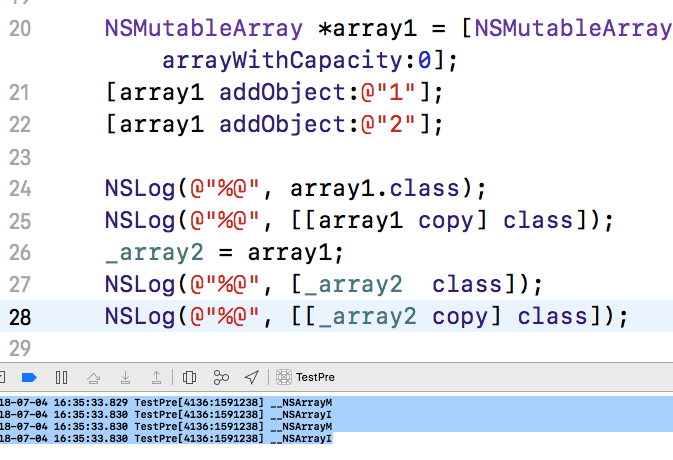
1:浅拷贝、单层深拷贝、深拷贝
1 对于非集合类对象的copy和mutableCopy (以NSString和NSMutableString为例子)
(1) NSString:
NSString *string = @"xiaotaiyang"; NSString *stringCopy = [string copy]; NSMutableString *stringMCopy = [string mutableCopy]; NSLog(@"string: %p, %p", string, &string); NSLog(@"stringCopy: %p, %p", stringCopy, &stringCopy); NSLog(@"stringMCopy: %p, %p", stringMCopy, &stringMCopy); 运行的结果如下: string: 0x1022fe078, 0x7fff5d901a48 stringCopy: 0x1022fe078, 0x7fff5d901a40 stringMCopy: 0x608000260240, 0x7fff5d901a38
从上面可以看出对NSString进行copy,字符串对象的内存地址没有发生变化,仅仅是产生了一个新的指针指向字符串对象,但是进行 mutableCopy 操作,其字符串对象的内存地址已经发生了变化,并且产生了一个新的指针指向字符串对象
(2) NSMutableString
NSMutableString *string = [NSMutableString stringWithFormat:@"abc"]; NSString *stringCopy = [string copy]; NSMutableString *stringMCopy = [string mutableCopy]; NSLog(@"string: %p, %p", string, &string); NSLog(@"stringCopy: %p, %p", stringCopy, &stringCopy); NSLog(@"stringMCopy: %p, %p", stringMCopy, &stringMCopy); 运行的结果如下: string: 0x608000264680, 0x7fff5526aa48 stringCopy: 0xa000000006362613, 0x7fff5526aa40 stringMCopy: 0x608000264940, 0x7fff5526aa38
对 NSMutableString 进行 copy 操作,其内存地址和指针地址都发生了变化,所以操作是深拷贝,和上面有所不同;进行 mutableCopy 操作,其内存地址和指针地址也都发生了变化,所以也是深拷贝。
2 集合类对象的copy和mutableCopy(NSArray和NSMutableArray为例子)
(1) NSArray
NSString *element_01 = @"abc"; NSString *element_02 = @"def"; NSString *element_03 = @"ghi"; NSArray *array = @[element_01, element_02, element_03]; NSArray *arrayCopy = [array copy]; NSMutableArray *arrayMCopy = [array mutableCopy]; NSLog(@"array: %p, %p; array.firstObject: %p", array, &array, array.firstObject); NSLog(@"arrayCopy: %p, %p; arrayCopy.firstObject: %p", arrayCopy, &arrayCopy, arrayCopy.firstObject); NSLog(@"arrayMCopy: %p, %p; arrayMCopy.firstObject: %p", arrayMCopy, &arrayMCopy, arrayMCopy.firstObject); 运行结果如下: array: 0x600000245910, 0x7fff51367a10; array.firstObject: 0x10e898088 arrayCopy: 0x600000245910, 0x7fff51367a08; arrayCopy.firstObject: 0x10e898088 arrayMCopy: 0x600000245670, 0x7fff51367a00; arrayMCopy.firstObject: 0x10e898088
对 NSArray 进行 copy 操作的时候,数组的内存地址没有发生变化,仅仅是产生了一个新的指针指向数组对象,mutableCopy 操作时,其内存地址发生了变化,但是数组元素的内存地址并没有发生变化
(2) NSMutableArray
NSString *element_01 = @"abc"; NSString *element_02 = @"def"; NSString *element_03 = @"ghi"; NSMutableArray *array = [NSMutableArray arrayWithArray:@[element_01, element_02, element_03]]; NSArray *arrayCopy = [array copy]; NSMutableArray *arrayMCopy = [array mutableCopy]; NSLog(@"array: %p, %p; array.firstObject: %p", array, &array, array.firstObject); NSLog(@"arrayCopy: %p, %p; arrayCopy.firstObject: %p", arrayCopy, &arrayCopy, arrayCopy.firstObject); NSLog(@"arrayMCopy: %p, %p; arrayMCopy.firstObject: %p", arrayMCopy, &arrayMCopy, arrayMCopy.firstObject); 运行结果如下: array: 0x6000000460c0, 0x7fff516d3a10; array.firstObject: 0x10e52c088 arrayCopy: 0x600000046420, 0x7fff516d3a08; arrayCopy.firstObject: 0x10e52c088 arrayMCopy: 0x600000046000, 0x7fff516d3a00; arrayMCopy.firstObject: 0x10e52c088
对 NSMutableArray 进行 copy 和 mutableCopy 操作,其内存地址都发生了变化,但是,对于数组中的元素,不管是进行的哪种操作,内存地址始终都没有发生变化,所以属于单层深拷贝
3:深层copy需要实现,
3.1:需要遵守<NSMutableCopying,NSCopying>两个协议,并实现协议方法:
3.2:调用- (instancetype)initWithArray:(NSArray<ObjectType> *)array copyItems:(BOOL)flag; //其他容器对象 如字典集合等也都有这样类似的方法
-(id)mutableCopyWithZone:(NSZone *)zone{ testClass* test = [[self class]allocWithZone:zone]; test.name = _name; return test; } -(id)copyWithZone:(NSZone *)zone{ testClass* test = [[self class]allocWithZone:zone]; test.name = _name; return test; } testClass* class0 = [testClass new]; class0.name = @(1).stringValue; testClass* class1 = [testClass new]; class1.name = @(11).stringValue; testClass* class2 = [testClass new]; class2.name = @(111).stringValue; NSArray* arr = @[class0,class1,class2]; NSMutableArray* arr2 = [[NSMutableArray alloc]initWithArray:arr copyItems:YES];
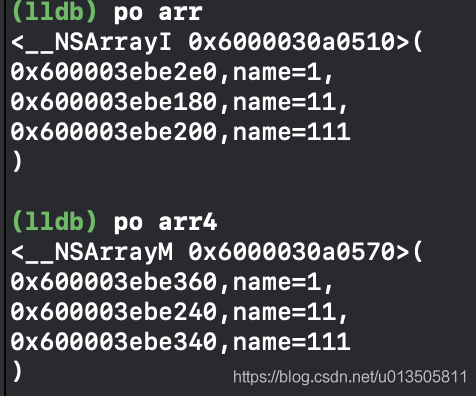
这样就得到了合适的新数组。
4: 那么当自定义的对象的属性中有其他自定义对象,该如何处理呢?
需要在包含其他对象属性的类的copywithzone方法中,创建一个新的testOther对象,然后赋值给当前拷贝的对象的相关指针:
4.1:否则:不会其他类不会copy
@implementation testClass -(id)mutableCopyWithZone:(NSZone *)zone{ testClass* test = [[self class]allocWithZone:zone]; test.name = _name; test.other = _other; return test; } -(id)copyWithZone:(NSZone *)zone{ testClass* test = [[self class]allocWithZone:zone]; test.name = _name; test.other = _other; return test; } @end
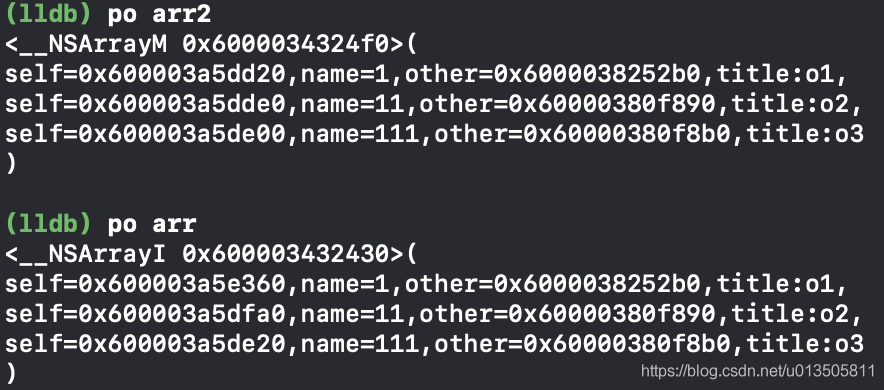
4.2:需要在包含其他对象属性的类的copywithzone方法中,创建一个新的testOther对象
@interface testClass : NSObject<NSMutableCopying,NSCopying> @property(nonatomic, strong) NSString* name; @property(nonatomic, strong) testOther* other; @end @implementation testClass -(id)mutableCopyWithZone:(NSZone *)zone{ testClass* test = [[self class]allocWithZone:zone]; test.name = _name; testOther* temp = [testOther new]; temp.title = _other.title; test.other = temp; return test; } -(id)copyWithZone:(NSZone *)zone{ testClass* test = [[self class]allocWithZone:zone]; test.name = _name; testOther* temp = [testOther new]; temp.title = _other.title; test.other = temp; return test; } @end @interface testOther : NSObject<NSCopying> @property(nonatomic,strong) NSString* title; @end @implementation testOther -(id)copyWithZone:(NSZone *)zone{ testOther* other = [[self class]allocWithZone:zone]; other.title = _title; return other; } @end testOther* other1 = [testOther new]; other1.title = @"o1"; testOther* other2 = [testOther new]; other2.title = @"o2"; testOther* other3 = [testOther new]; other3.title = @"o3"; testClass* class0 = [testClass new]; class0.name = @(1).stringValue; class0.other = other1; testClass* class1 = [testClass new]; class1.name = @(11).stringValue; class1.other = other2; testClass* class2 = [testClass new]; class2.name = @(111).stringValue; class2.other = other3; NSArray* arr = @[class0,class1,class2]; NSMutableArray* arr2 = [[NSMutableArray alloc]initWithArray:arr copyItems:YES];
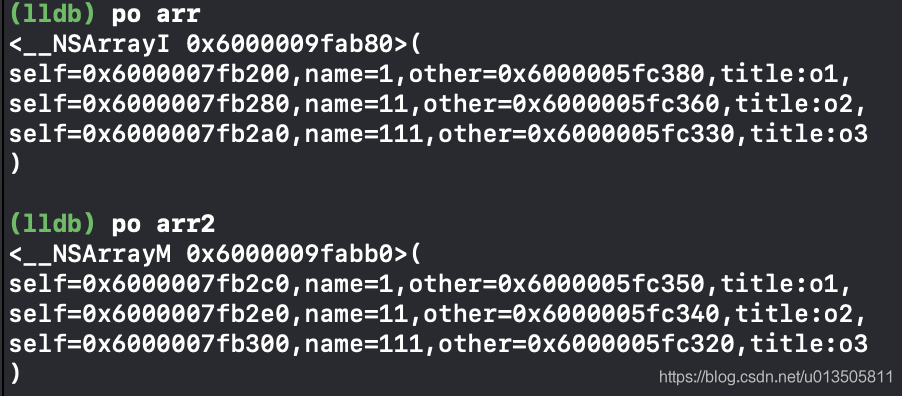
2:数组copy后里面的元素会复制一份新的吗?不会
对数组进行copy或mutableCopy操作只是对数组这个容器对象进行了深/浅拷贝,而不会对数组中的对象进行操作,最后拷贝完得到的数组中的对象仍旧是指向之前的地址。
这样就会导致,我们在修改经过深拷贝之后的数组中的对象中属性时,同时会影响到原始数组中的对象,达不到想要的结果。
3:可变数组的实现原理
NSMutableArray的底层原理
_used 是计数的意思
_list 是缓冲区指针
_size 是缓冲区的大小
_offset 是在缓冲区里的数组的第一个元素索引
数据结构
正如你会猜测的,__NSArrayM 用了环形缓冲区 (circular buffer)。这个数据结构相当简单,只是比常规数组或缓冲区复杂点。环形缓冲区的内容能在到达任意一端时绕向另一端。
环形缓冲区有一些非常酷的属性。尤其是,除非缓冲区满了,否则在任意一端插入或删除均不会要求移动任何内存。我们来分析这个类如何充分利用环形缓冲区来使得自身比 C 数组强大得多。在任意一端插入或者删除,只是修改offset参数,不需要移动内存,我们访问的时候只是不和普通的数组一样index多少就是多少,这里会计算加上offset之后处理的值取数据,而不是插入头和尾巴的时候,环形结构会根据最少移动内存指针的方式插入,例如要在A和B之间插入,按照C的数组,我们需要把B到E的元素移动内存,但是环形缓冲区的设计,我们只要把A的值向前移动一个单位内存,即可,同时修改offset偏移量,就能保证最小的移动单元来完成中间插入。
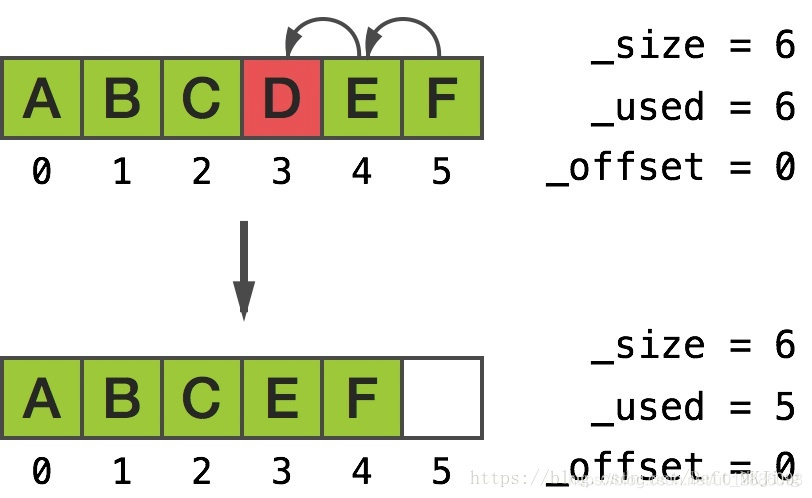
往中部插入对象有非常相似的结果。合理的解释就是,__NSArrayM 试着去最小化内存的移动,因此会移动最少的一边元素。
删除头部元素和添加元素
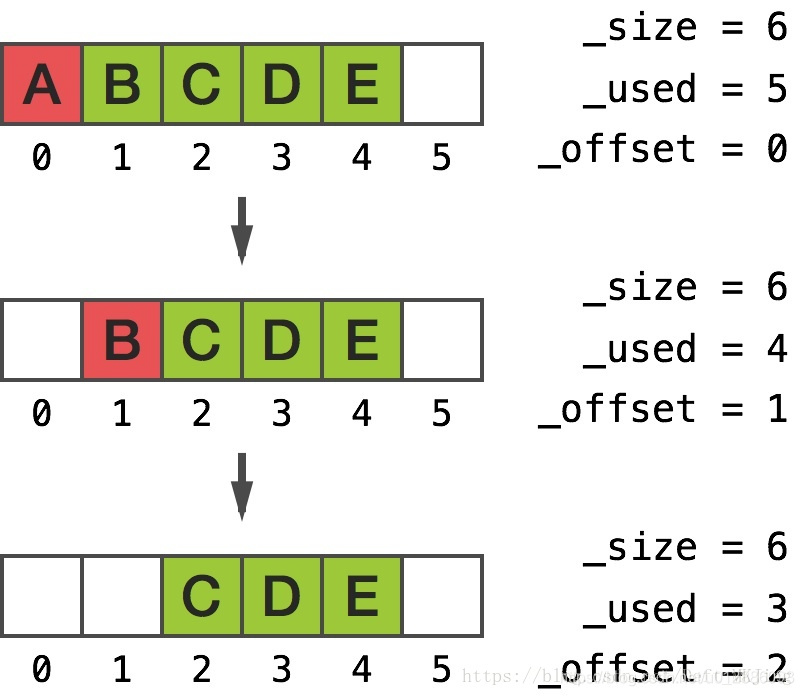
NSMutableArray 是一个高级抽象数组,解决了 C 风格数组对应的缺点。(C数组插入的时候都会移动内存,不是O(1),用到了环形缓冲区数据结构来处理内存移动的损耗)
但是可变数组任意一端插入或删除能有固定时间的性能。而且在中间插入和删除的时候都会试着去移动最小化内存。
环形缓冲区的数据结构如果是连续数组结构,在扩容的时候难免会移动大量内存,因此用链表实现环形缓冲会更好
注意:扩容,内存足够时,内容不变,内存不够,重新创建,里面元素内存会改变。
扩容机制
上面提到了指向数据的指针的指针,其实这个指针所指向的内容在数组容量不够的时候是会发生变化的,我们可以去创建分类然后写入下面这个方法,就可以实时的观察这个指针所指向内容的变化
-(void *)dataAddress { void * address = (__bridge void *)self; //void ** 指向指针的指针,指针类型占据8个字节,+2就是往下挪16个字节 这里用*((long *)address +2)也是可以的 return *((void **)address +2); }
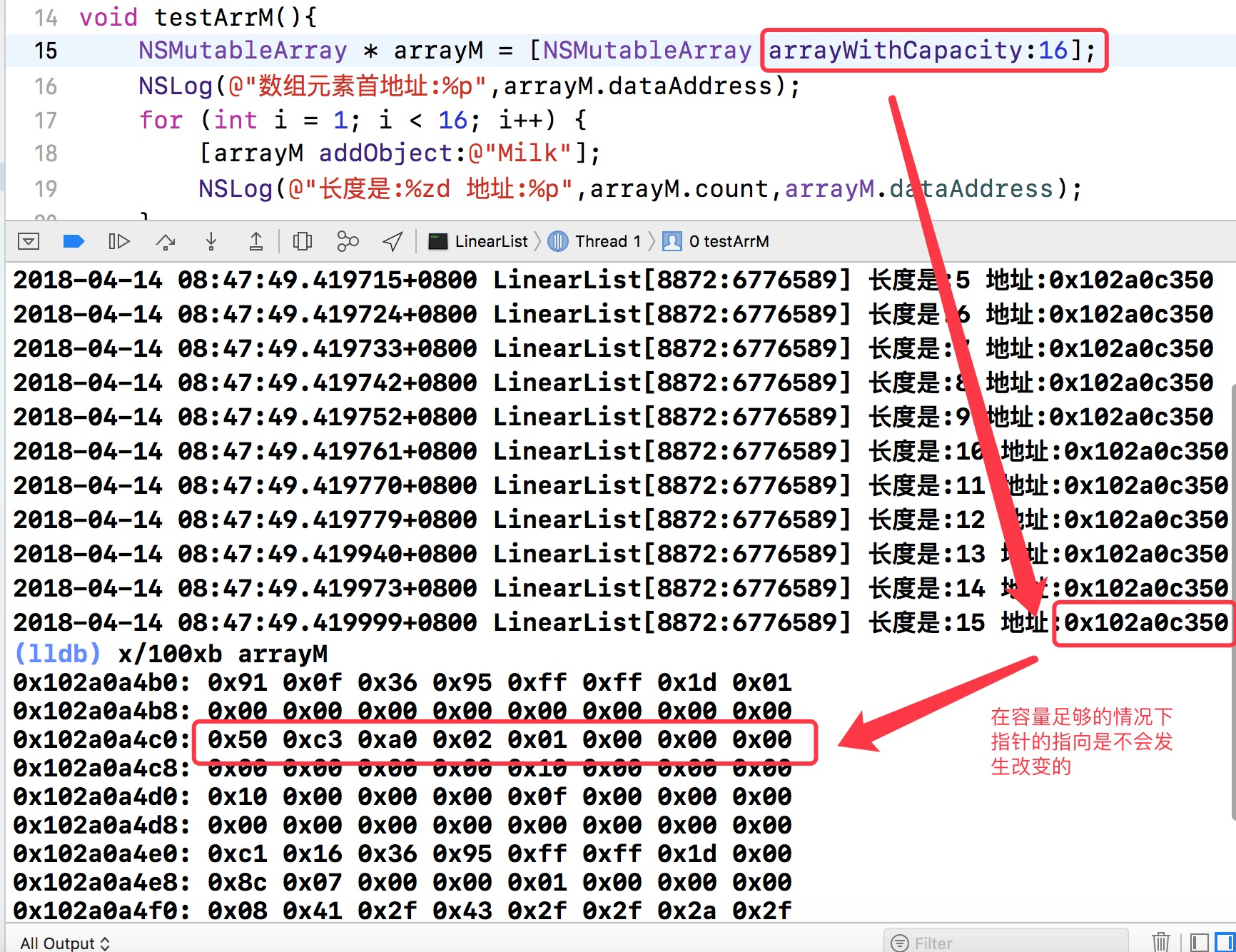
现在我们可以理解为什么append方法不是线程安全的了。如果在某一个线程中插入新元素,导致了数组扩容,那么Swift会创建一个新的数组(意味着地址完全不同)。然后ARC会为我们自动释放旧的数组,但这时候可能另一个线程还在访问旧的数组对象。
这个时候我们把数组的容量变为2,再去观察,观察后我们发现其实发生了频繁的改变的,只是扩容的规律还没有找到。

4:字典的实现原理
NSDictionary(字典)是使用hash表来实现key和value之间的映射和存储的
方法:- (void)setObject:(id)anObject forKey:(id)aKey;
Objective-C中的字典NSDictionary底层其实是一个哈希表
根据数据结构可以发现dictionary内部使用了两个指针数组分别来保存keys和values,先不去讨论这两个数组的元素如何形成对应关系,已知的是dictionary采用的是连续存储的方式存储键值对,因此接下来我们将一步步了解字典是如何完成key-value的匹配过程。我们刚才在CFDictionary的结构体的时候看到了key和values这两个二级指针,可以基本断定为数组结构,由于是两个数组分别存储,因此,key哈希出来的数组下标地址,同样这个地址对应到values数组的下标,就是匹配到的值。因此keys和values这两个数组的长度一致才能保证匹配到数据。内部结构还有个_capacity表示当前通列表的扩充阀域 ,当count数量达到这个长度就扩容
可以看到,NSDictionary设置的key和value,key值会根据特定的hash函数算出建立的空桶数组,keys和values同样多,然后存储数据的时候,根据hash函数算出来的值,找到对应的index下标,如果下标已有数据,开放定址法后移动插入,如果空桶数组到达数据阀值,这个时候就会把空桶数组扩容,然后重新哈希插入。这样把一些不连续的key-value值插入到了能建立起关系的hash表中,当我们查找的时候,key根据哈希值算出来,然后根据索引,直接index访问hash表keys和hash表values,这样查询速度就可以和连续线性存储的数据一样接近O(1)了,只是占用空间有点大,性能就很强悍。如果删除的时候,也会根据_maker标记逻辑上的删除,除非NSDictionary(NSDictionary本体的hash值就是count)内存被移除。我们也会根据dictionary之所以采用这种设计,其一出于查询性能的考虑;其二dictionary在使用过程中总是会很快的被释放,不会长期占用内存。
三:哈希存储过程
1.根据 key 计算出它的哈希值 h。
2.假设箱子的个数为 n,那么这个键值对应该放在第 (h % n) 个箱子中。
3.如果该箱子中已经有了键值对,就使用开放寻址法或者拉链法解决冲突。
在使用拉链法解决哈希冲突时,每个箱子其实是一个链表,属于同一个箱子的所有键值对都会排列在链表中。
哈希表还有一个重要的属性: 负载因子(load factor),它用来衡量哈希表的空/满程度,一定程度上也可以体现查询的效率,计算公式为:
负载因子 = 总键值对数 / 箱子个数
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
哈希表在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变,这个过程也称为重哈希(rehash)。
哈希表的扩容并不总是能够有效解决负载因子过大的问题。假设所有 key 的哈希值都一样,那么即使扩容以后他们的位置也不会变化。虽然负载因子会降低,但实际存储在每个箱子中的链表长度并不发生改变,因此也就不能提高哈希表的查询性能。
5:为什么不可变对象要用copy。用@property声明的NSString(或NSArray,NSDictionary)经常使用copy关键字,为什么?如果改用strong关键字,可能造成什么问题
1:经常使用copy关键字原因:
因为父类指针可以指向子类对象,使用copy的目的是为了让本对象的属性不受外界影响,使用copy无论给我传入是一个可变对象还是不可对象,我本身持有的就是一个不可变的副本.
2:如果改用strong关键字,可能造成什么问题?
如果我们使用是strong,那么这个属性就有可能指向一个可变对象,如果这个可变对象在外部被修改了,那么会影响该属性.
引用:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号