045*:ipa包的大小受哪些影响?app瘦身
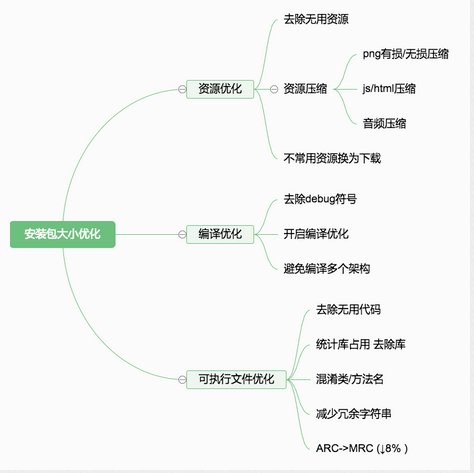
一:资源优化
1:删除无用的资源文件
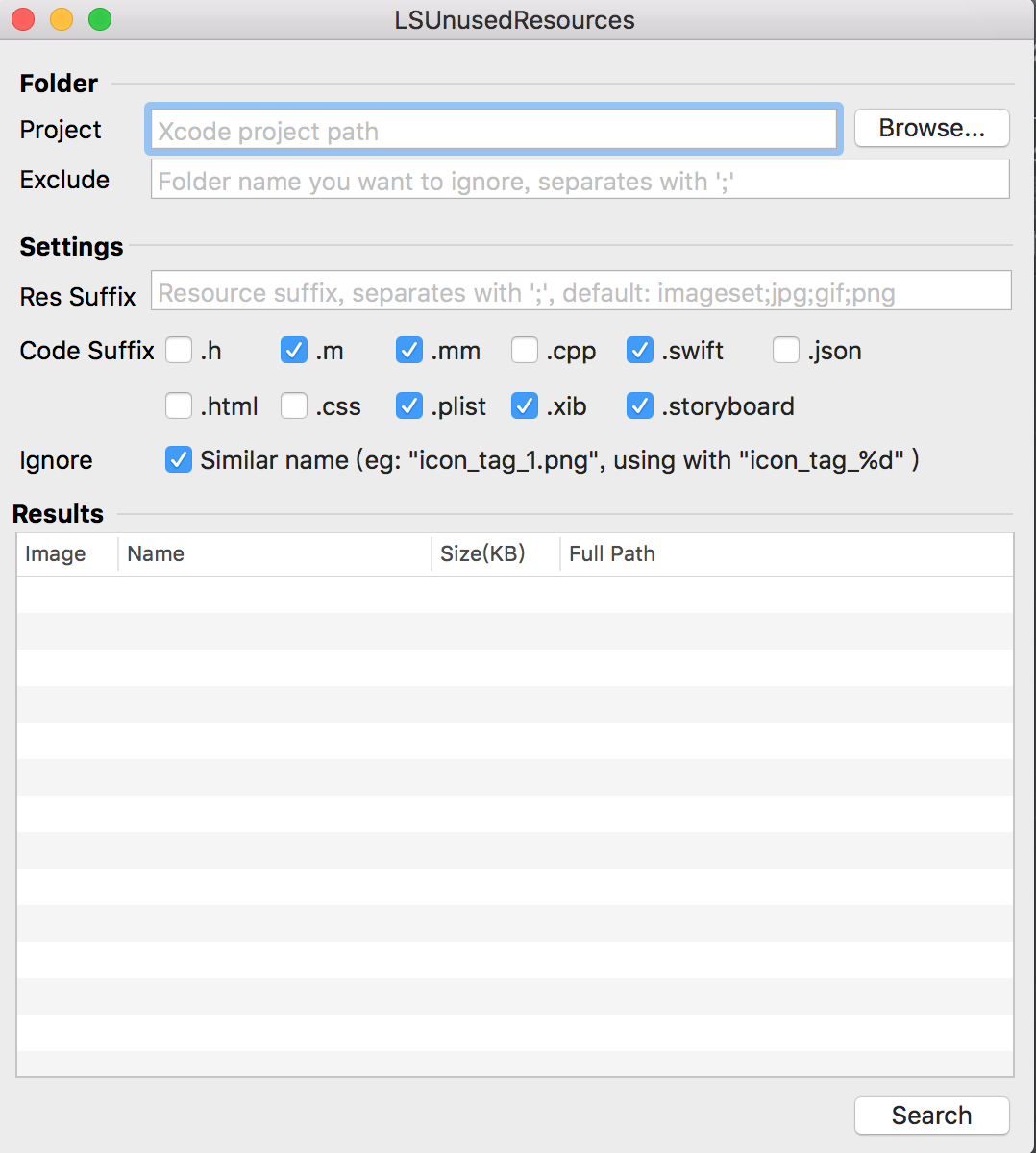
在这里推荐使用工具LSUnusedResources。它在脚本的基础上,做了两个改进:
- 提高匹配速度。LSUnusedResources不是对每个资源文件名都做一次全文搜索匹配,因为加入项目的资源太多,这里会导致性能快速下降。它只是针对源码、Xib、Storyboard 和 plist 等文件,先全文搜索其中可能是引用了资源的字符串,然后用资源名和字符串做匹配。
- 优化匹配结果。比如说脚本会把大量实际上有使用的资源,当做未使用的资源输出(例如拼接的图片名称),而LSUnusedResources不会。
接下来,打开工具LSUnusedResources,点击“Browse...”按钮,选择工程所在目录,点击"Search"按钮,即可开始搜索,如下图所示:
2:对资源文件进行压缩
压缩工具有很多,这里介绍两个好用的:
- 无损压缩工具ImageOptiom(推荐)。这是一款非常好的图片压缩工具,可以进行无损压缩,能够对 png 和 jpeg 图片文件进行优化,它能找到最佳的压缩参数(在设置中可以设置压缩比例,80% 及以上是无损压缩,推荐使用),并通过消除不必要的信息(如文件的 EXIF 标签和颜色配置文件等),优化后达到减小文件大小的效果。
- 有损压缩工具TinyPNG。它使用聪明的有损压缩技术,能有效减少PNG文件的大小。通过选择性地降低图像中颜色的数量,需要更少的字节来存储数据。
【建议】:对于较大尺寸的图片,可以和设计沟通,在不失真和影响效果的前提下,使用TinyPNG进行压缩;较小尺寸的图片,建议使用ImageOptiom。
3:变更图片文件的导入方式
我们都知道,图片资源的导入方式有如下几种:
1. Assets.xcassets。
- 只支持png格式的图片;
- 图片只支持[UIImage imageNamed]的方式实例化,但是不能从Bundle中加载;
- 在编译时,Images.xcassets中的所有文件会被打包为Assets.car的文件。
2. CreateGroup
- 黄色文件夹图标;Xcode中分文件夹,Bundle中都在同一个文件夹下,因此,不能出现文件重名的情况;
- 可以直接使用[NSBundle mainBundle]作为资源路径,效率高;
- 可以使用[UIImage imageNamed:]加载图像。
3. CreateFolderRefences
- 蓝色文件夹;Xcode中分文件夹,Bundle中同样分文件夹,因此,可以出现文件重名的情况;
- 需要在[NSBundle mainBundle]的基础上拼接实际的路径,效率较差;
- 不能使用[UIImage imageNamed:]加载图像。
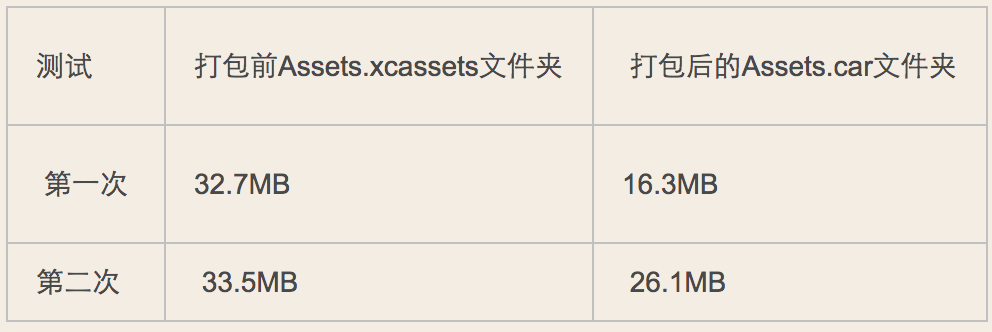
经过测试得知:CreateGroup、CreateFolderRefences两种方式打出来的包,图片都会直接放在.app文件中,所以打包前后,图片的大小不会改变。而加入到Assets.xcassets中的方法则不同,打包后,在.app中会生成Assets.car文件来存储Assets.xcassets中的图片,并且文件大小也大大降低。
值得留意的是,在将图片资源移到Assets.xcassets管理的时候,一般情况下会自动生成与图片名称相同的,比如loading@2x.png和loading@3x.png会自动放置到一个同名的loading文件夹中。然而有一些不规则命名的图片,会出现一些奇怪的问题:
- 图片名称为ios-f2-8-004的图片,放到Images.xcassets中,会自动生成调用的图片名是ios-f2-8-4,最后一位的004,被替换成4,然而在类文件中引用的是[UIImage imageNamed:@"ios-f2-8-004.png"],这样会找不到图片;
- 图片名称为ios-f6-的图片,放到Images.xcassets中,会自动生成调用的图片名是ios-f6,这样也会找不到图片。
因此在移动的时候,一定要细致对比。
4:处理1x图片
我们知道,iPhone设备目前主要有四种尺寸:3.5英寸、4英寸、4.7英寸、5.5英寸,对于这几个尺寸的设备,我们来看一下具体的设备型号和屏幕相关信息:
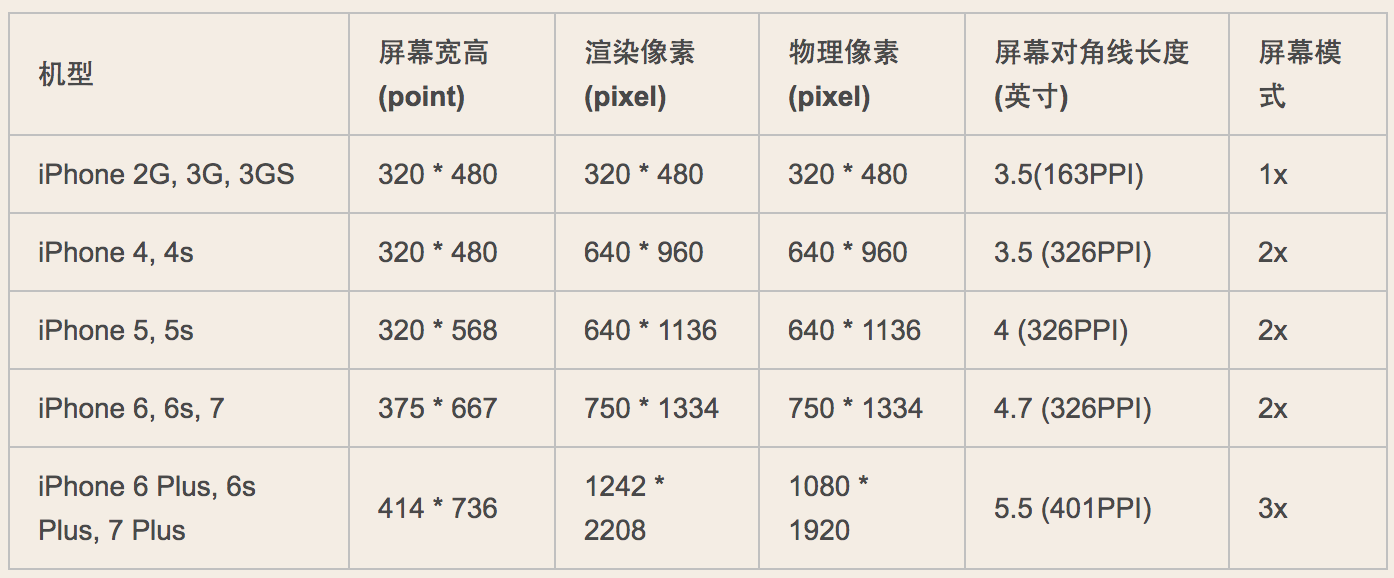
对于上表中的几个概念,这里做一下说明:
- Points: 是iOS开发中引入的抽象单位,称作点。开发过程中所有基于坐标系的绘制都是以 point 作为单位,在iPhone 2G,3G,3GS的年代,point 和屏幕上的像素是完全一一对应的,即 320 * 480 (points), 也是 320 * 480 (pixels);
- Rendered Pixels: 渲染像素, 以 point 为单位的绘制最终都会渲染成 pixels,这个过程被称为光栅化。基于 point 的坐标系乘以比例因子可以得到基于像素的坐标系,高比例因子会使更多的细节展示,目前的比例因子会是 1x,2x,3x
- Physical Pixels: 物理像素,就是设备屏幕实际的像素。
- Physical Device: 设备屏幕的物理长度,使用英寸作为单位。比如iPhone 4屏幕是3.5英寸,iPhone 5 是4英寸,iphone 6是4.7英寸,这里的数字是指手机屏幕对角线的物理长度。实际上会是Physical Pixels的像素值(而不是Rendered Pixels的像素值)会渲染到该屏幕上, 屏幕会有 PPI(pixels-per-inch) 的特性,PPI 的值告诉你每英寸会有多少像素渲染。
- 屏幕模式: 描述的是屏幕中一个点有多少个 Rendered Pixels 渲染,对于2倍屏(又称 Retina 显示屏),会有 2 * 2 = 4 个像素的面积渲染,对于3倍屏(又称 Retina HD 显示屏),会有 3 * 3 = 9 个像素的面积渲染。
在实际的开发中,所有控件的坐标以及控件大小都是以点为单位的,假如屏幕上需要展示一张 20 * 20 (单位:point)大小的图片,那么设计师应该怎么给图呢?这里就会用到屏幕模式的概念,如果屏幕是 2x,那么就需要提供 40 * 40 (单位: pixel)大小的图片,如果屏幕是 3x,那么就提供 60 * 60 大小的图片,且图片的命名需要遵守以下规范:
- Standard:
<ImageName><device_modifier>.<filename_extension> - High resolution:
<ImageName>@2x<device_modifier>.<filename_extension> - High HD resolution:
<ImageName>@3x<device_modifier>.<filename_extension>
其中:
- ImageName: 图片名字,根据场景命名
- device_modifier: 可选,可以是
~ipad或者~iphone, 当需要为 iPad 和 iPhone 分别指定一套图时需要加上此字段 - filename_extension: 图片后缀名,iOS中使用 png 图片
2x屏幕的设备会自动加载 xxx@2x.png 命名的图片资源,3x屏幕的设备会自动加载 xxx@3x.png 的图片。从友盟统计数据可以看到,现在基本没有 1x屏幕的设备了,所以可以不用提供这个分辨率的图片。
至于开发中,技术人员和设计人员关于设计和切图的工作流程和规范,可以参看知乎上的这篇文章介绍。
2:清理无用代码--AppCode
AppCode是一种智能的Objective-C集成开发环境,由专业的开发收费IDE的公司Jetbrains开发,具有这些特点:
- 最好的代码助手:IDE深入的了解代码结构,编辑器能提供准确的代码实现选择。通过代码生成节省了不必要的输入,减少了日常任务。
- 可靠的代码重构:安全、准确和可靠的代码重构允许我们随时修改和提升代码质量。
- 快速项目导航:通过类继承可以从方法导航到它的声明或使用处,或者直接从一个文件链接到另一个文件。支持即时跳转到项目中的任何文件、类、标号处,或者查看标号的实际使用者,并不仅仅是文本匹配那么简单。
- 代码质量追踪:支持对Objective-C、C、C++、JavaScript、CSS、HTML、XML和Xpath等进行动态代码分析。AppCode能让您避免潜在的错误,提示您哪些代码可以改善。此外,它还集成了Clang Static Analyzer。
- 强大的代码调试器:使用便携调试器中灵活的断点、窗口、框架视图和求值表达式调整您的应用或单元测试。
- 无缝集成:AppCode完美地集成大部分流行的版本控制系统,如Git, Mercurial、Perforce等,还集成了Kiwi测试框架、Dash和成分文档工具以及很多问题追踪器,提供与Xcode100%的互操作性。
在这里,我们可以用它的inspect code来扫描无用代码,包括无用的类、函数、宏定义、value、属性等,而safe delete功能使得删除一些由于runtime被调用到的代码时更加安全智能。扫描结果示例:
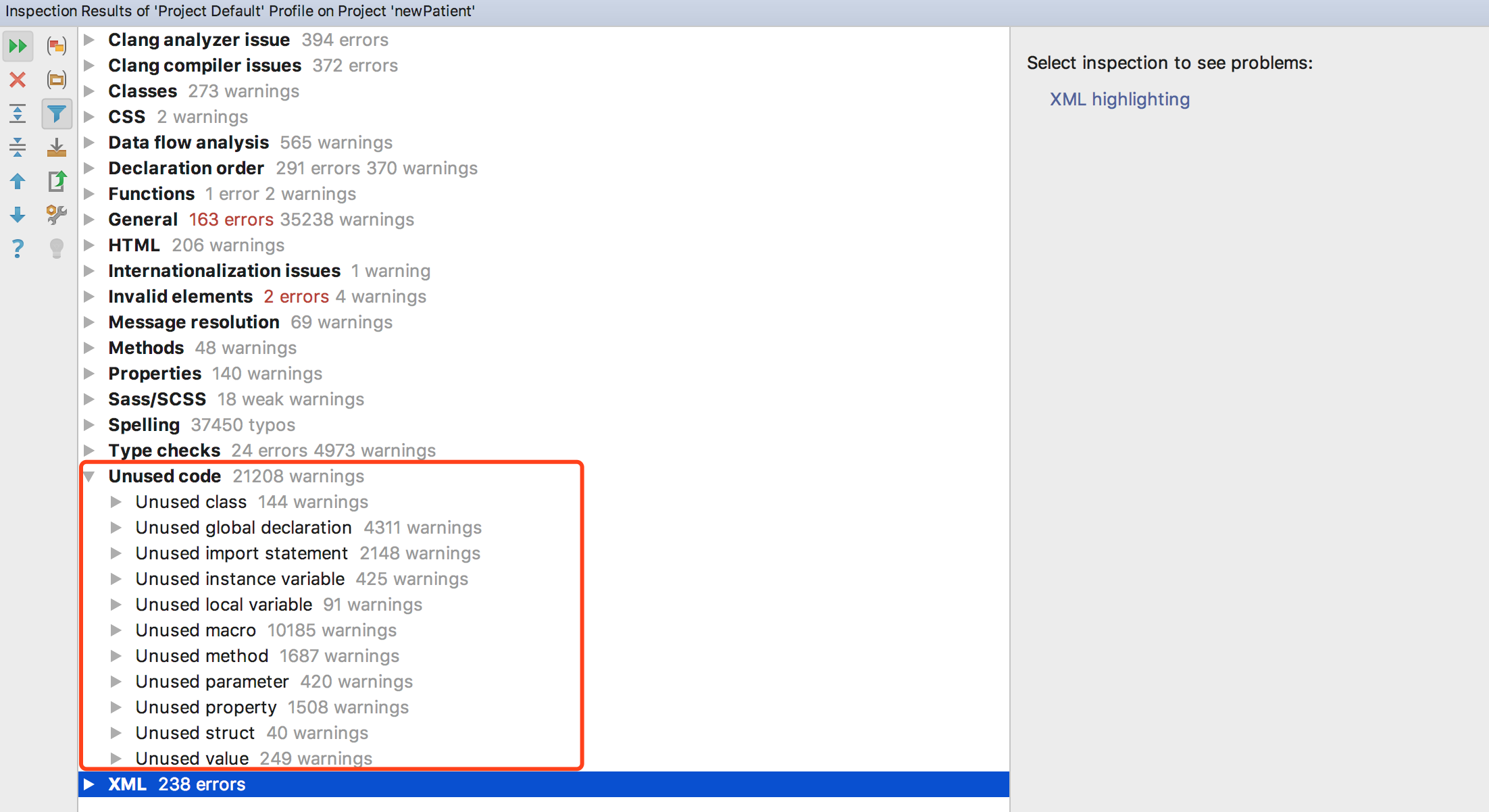
【说明】:如果工程很大,这个扫描的时间可能会比较长。我们现在的工程中,大概有2700个类,扫描时间在一个半小时。
2:清理无用类
实际上,在2.1的扫描结果中,包含无用类,但2.1的扫描时间会比较长,另外扫描出来的内容也较多。如果只是需要清理无用类的话,可以用如下脚本:
# -*- coding: UTF-8 -*- #!/usr/bin/env python # 使用方法:python py文件 Xcode工程文件目录 import sys import os import re if len(sys.argv) == 1: print '请在.py文件后面输入工程路径' sys.exit() projectPath = sys.argv[1] print '工程路径为%s' % projectPath resourcefile = [] totalClass = set([]) unusedFile = [] pbxprojFile = [] def Getallfile(rootDir): for lists in os.listdir(rootDir): path = os.path.join(rootDir, lists) if os.path.isdir(path): Getallfile(path) else: ex = os.path.splitext(path)[1] if ex == '.m' or ex == '.mm' or ex == '.h': resourcefile.append(path) elif ex == '.pbxproj': pbxprojFile.append(path) Getallfile(projectPath) print '工程中所使用的类列表为:' for ff in resourcefile: print ff for e in pbxprojFile: f = open(e, 'r') content = f.read() array = re.findall(r'\s+([\w,\+]+\.[h,m]{1,2})\s+',content) see = set(array) totalClass = totalClass|see f.close() print '工程中所引用的.h与.m及.mm文件' for x in totalClass: print x print '--------------------------' for x in resourcefile: ex = os.path.splitext(x)[1] if ex == '.h': #.h头文件可以不用检查 continue fileName = os.path.split(x)[1] print fileName if fileName not in totalClass: unusedFile.append(x) for x in unusedFile: resourcefile.remove(x) print '未引用到工程的文件列表为:' writeFile = [] for unImport in unusedFile: ss = '未引用到工程的文件:%s\n' % unImport writeFile.append(ss) print unImport unusedFile = [] allClassDic = {} for x in resourcefile: f = open(x,'r') content = f.read() array = re.findall(r'@interface\s+([\w,\+]+)\s+:',content) for xx in array: allClassDic[xx] = x f.close() print '所有类及其路径:' for x in allClassDic.keys(): print x,':',allClassDic[x] def checkClass(path,className): f = open(path,'r') content = f.read() if os.path.splitext(path)[1] == '.h': match = re.search(r':\s+(%s)\s+' % className,content) else: match = re.search(r'(%s)\s+\w+' % className,content) f.close() if match: return True ivanyuan = 0 totalIvanyuan = len(allClassDic.keys()) for key in allClassDic.keys(): path = allClassDic[key] index = resourcefile.index(path) count = len(resourcefile) used = False offset = 1 ivanyuan += 1 print '完成',ivanyuan,'共:',totalIvanyuan,'path:%s'%path while index+offset < count or index-offset > 0: if index+offset < count: subPath = resourcefile[index+offset] if checkClass(subPath,key): used = True break if index - offset > 0: subPath = resourcefile[index-offset] if checkClass(subPath,key): used = True break offset += 1 if not used: str = '未使用的类:%s 文件路径:%s\n' %(key,path) unusedFile.append(str) writeFile.append(str) for p in unusedFile: print '未使用的类:%s' % p filePath = os.path.split(projectPath)[0] writePath = '%s/未使用的类.txt' % filePath f = open(writePath,'w+') f.writelines(writeFile) f.close()
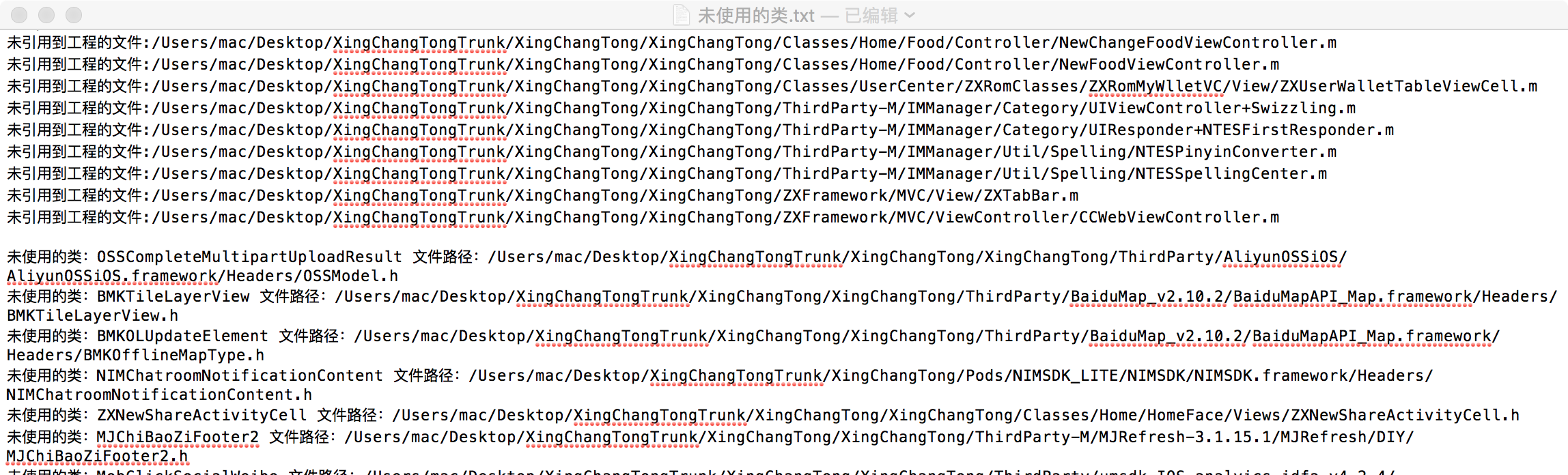
同样的工程,这个脚本执行速度大概是三分钟,结果如下:
3:音频和视频压缩。
4:不常用文件改为下载。
二:编译优化
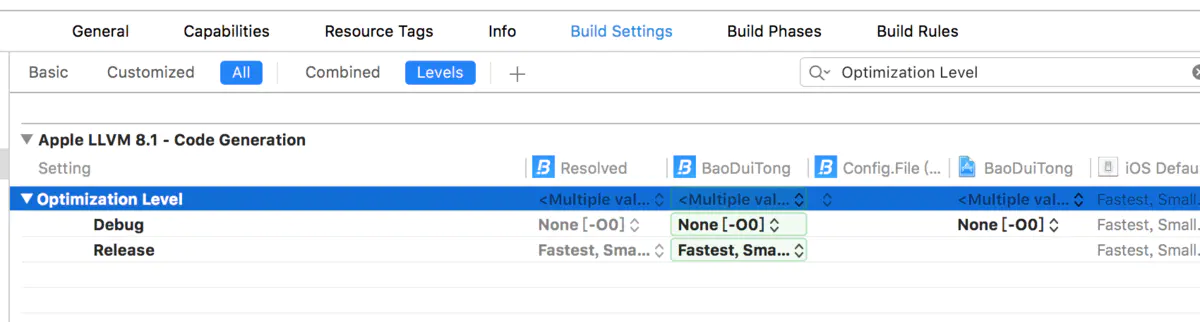
1:编译器优化级别
Build Settings->Optimization Level有几个编译优化选项,release版应该选择Fastest, Smalllest[-Os],这个选项会开启那些不增加代码大小的全部优化,并让可执行文件尽可能小。
2:去除符号信息
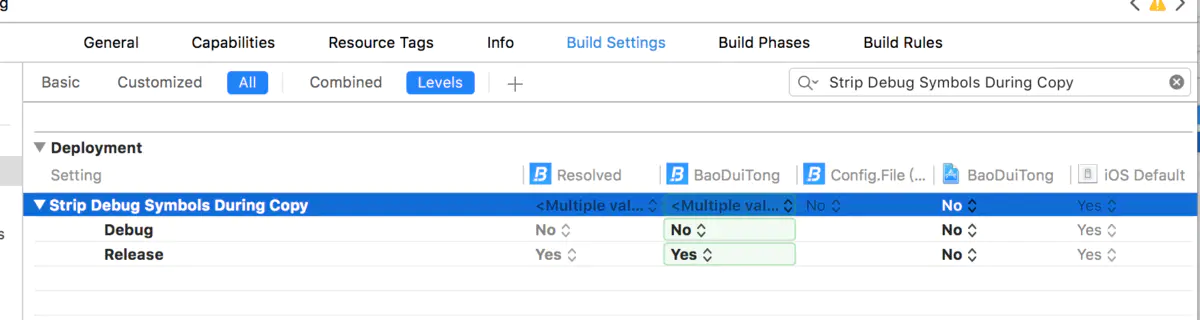
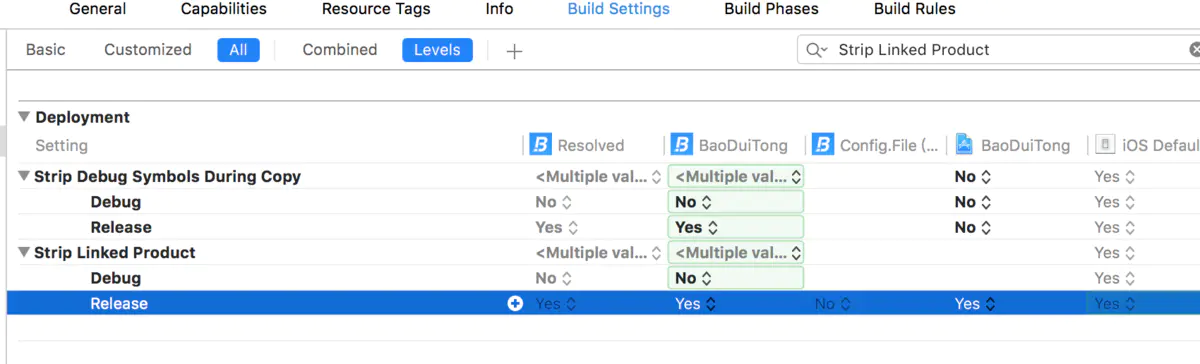
3:Strip Linked Product:DEBUG下设为NO,RELEASE下设为YES,用于RELEASE模式下缩减app的大小;
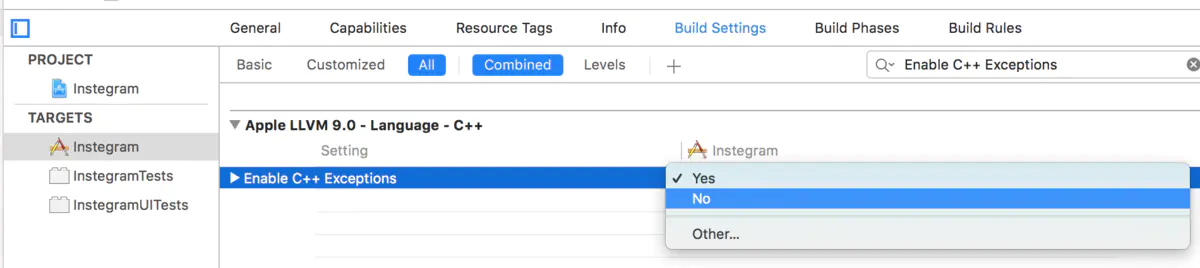
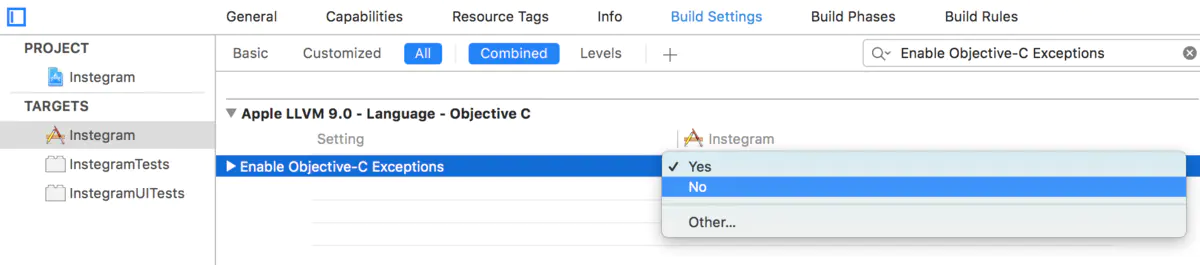
4:编译器优化,去掉异常支持。Enable C++ Exceptions、Enable Objective-C Exceptions设置为NO,Other C Flags添加-fno-exceptions

4、舍弃架构armv7
armv7用于支持4s和4,4s是2011年11月正式上线,虽然还有小部分人在使用,但是追求包体大小的完全可以舍弃了。
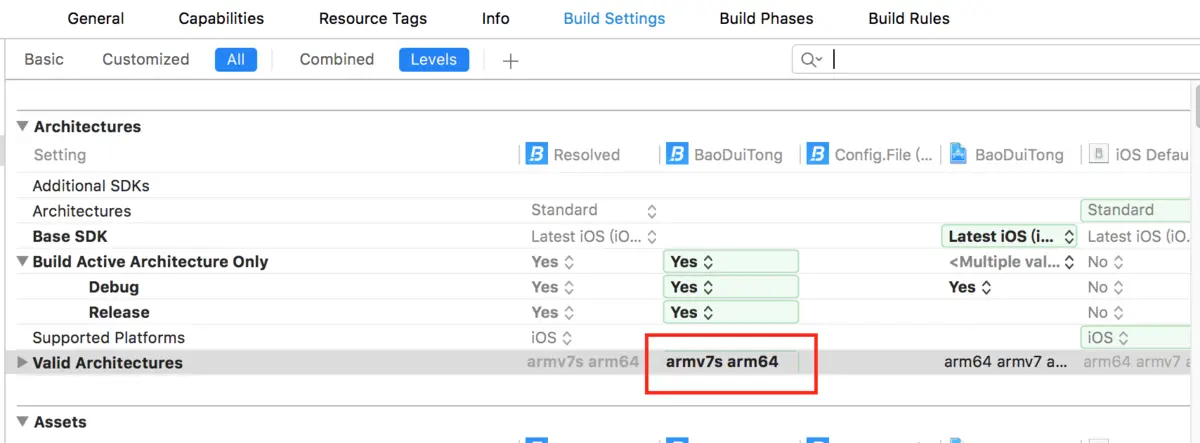
5:配置编译选项
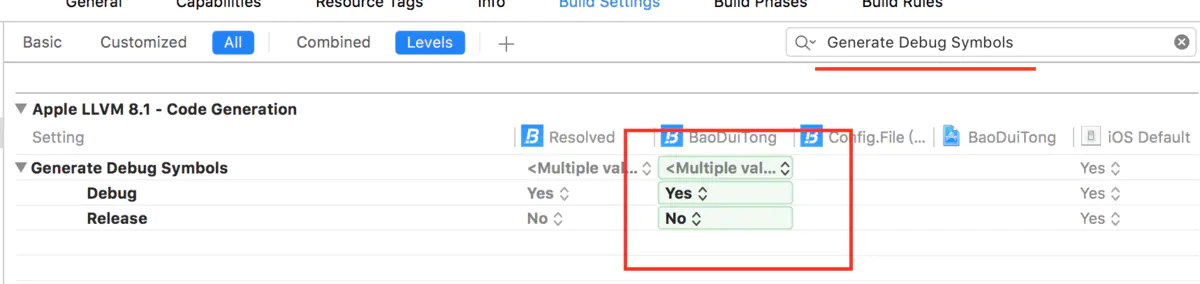
(Levels选项内)Generate Debug Symbols 设置为NO,这个配置选项应该会让你减去小半的体积。注意这个如果设置成NO就不会在断点处停下
6:其次针对一些库ARC和MRC对库的大小也是有影响,由于现在都是arc管理内存很多库都更新成arc模式了,由于arc模式下是系统自从插入release,所以对大小也是有影响的,见下图:
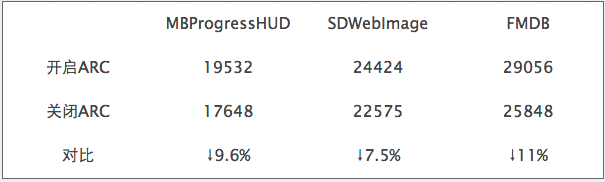
结果是ARC大概会使代码段增加10%的size,考虑代码段占可执行文件大约有80%,估计对整个可执行文件的影响会是8%。
可以评估一下8%的体积下降是不是值得把项目里某些模块改成MRC,这样程序的维护成本上升了,一般不到特殊情况不建议这么做。
三:类/方法名长度:混淆
观察linkmap可以发现每个类和方法名都在__cstring段里都存了相应的字符串值,所以类和方法名的长短也是对可执行文件大小是有影响的,原因还是object-c的动态特性,因为需要通过类/方法名反射找到这个类/方法进行调用,object-c对象模型会把类/方法名字符串都保存下来。
对此我们可以考虑在编译前把所有类和方法名进行混淆,跟压缩js一样,把长名字替换成短名字,这样做的好处除了缩小体积外,还对安全性有很大提升,别人拿到可执行文件对它class-dump出来的结果都是混淆后的类和方法名,就无法从类和方法名中猜出某个方法是做什么的,就难以挂钩子进行hack。不过这样做有个缺点,就是crash堆栈反解出来的堆栈方法名会是混淆后的,需要再加一层混淆->原名的转换,实现和使用成本有点高。实际上这部分占用的长度比较小,中型项目也就几百K,对安全性要求高的情况可以试试。
引用:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号