11*:线索化二叉树和⼆叉树的应⽤-哈夫曼编码(线索二叉树,等于是把一棵二叉树转变成了一个双向链表)(线索化二叉树利用二叉树的空链指针,使每个结点都有了唯一前驱和后继,把非线性结构转换为线性结构。)
问题
1:线索化二叉树
/* 线索二叉树存储结点结构*/ typedef struct BiThrNode{ //数据 CElemType data; //左右孩子指针 struct BiThrNode *lchild,*rchild; //左右标记 PointerTag LTag; PointerTag RTag; }BiThrNode,*BiThrTree;
2:哈夫曼编码
// 构建哈弗曼树的结点 typedef struct HaffNode { int weight; // 权值 int flag; // 是否使用过 int parent; // 父节点索引 int leftChild; // 左儿子索引 int rightChild; // 右儿子索引 } HaffNode; typedef struct Code//存放哈夫曼编码的数据元素结构,哈夫曼编码其实就是对应的数据(叶子节点) { int bit[MaxBit];//路径数组 int start; //编码的起始下标,相当于bit数组的下标 int weight;//字符的权值 }Code;
目录
1:产生背景
2:构建线索化二叉树
3:代码实现线索化二叉树
4:哈夫曼树和编码
预备
正文
一、产生背景
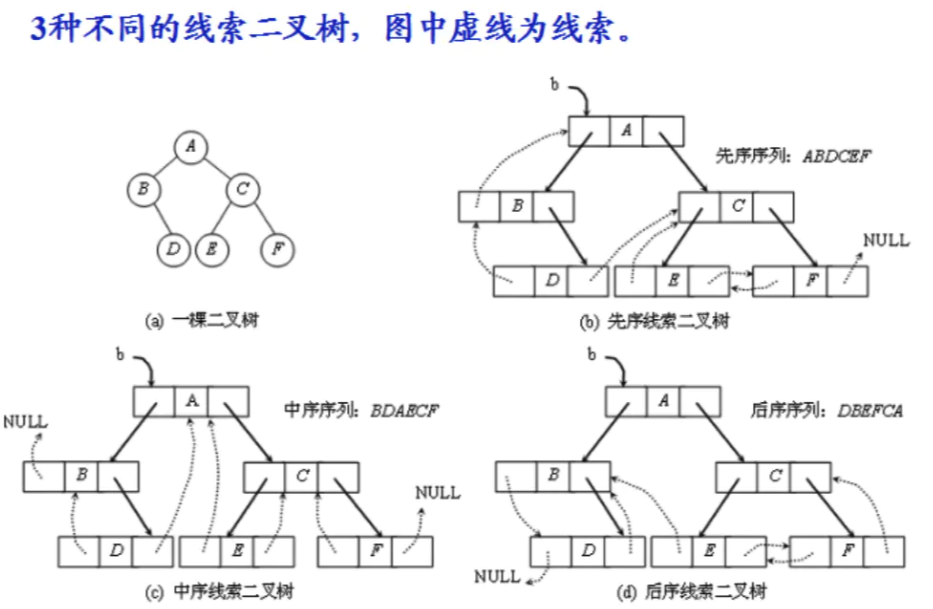
在二叉树的结点上加上线索的二叉树称为线索二叉树,对二叉树以某种遍历方式(如先序、中序、后序或层次等)进行遍历,使其变为线索二叉树的过程称为对二叉树进行线索化。
1:正常二叉树结构:
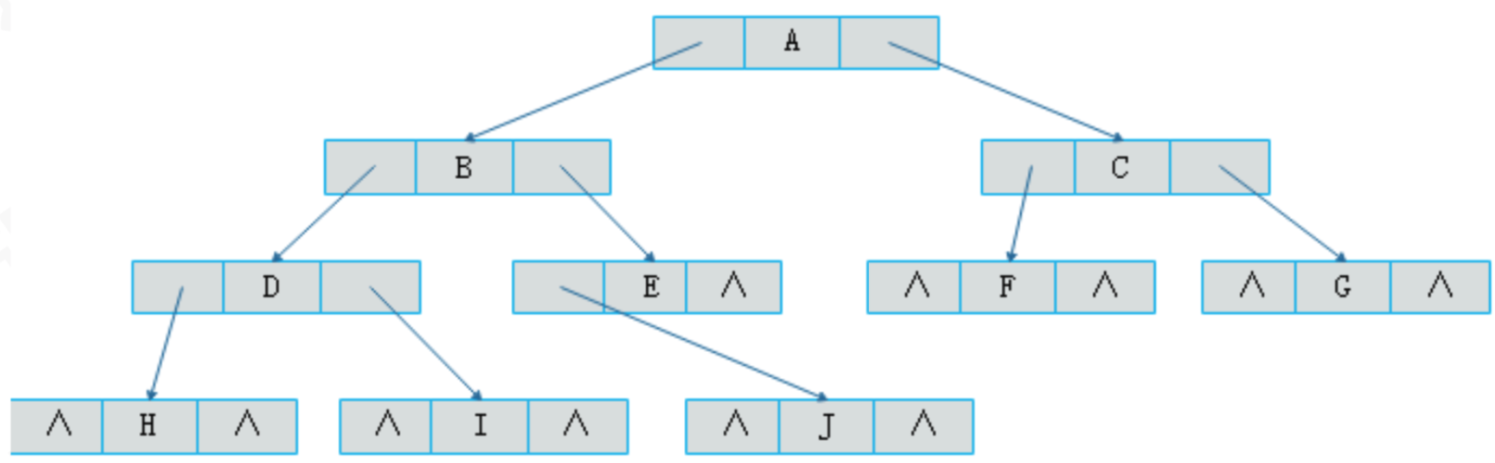
每个结点都有一个左指针、一个右指针,在叶子节点或者个别节点上左指针或者右指针为空,这样无形中浪费了存储空间,
所以这个时候我们引入了线索二叉树,我们可以将空出来的左指针指向该结点的前驱,空出来的右指针指向该结点的后继
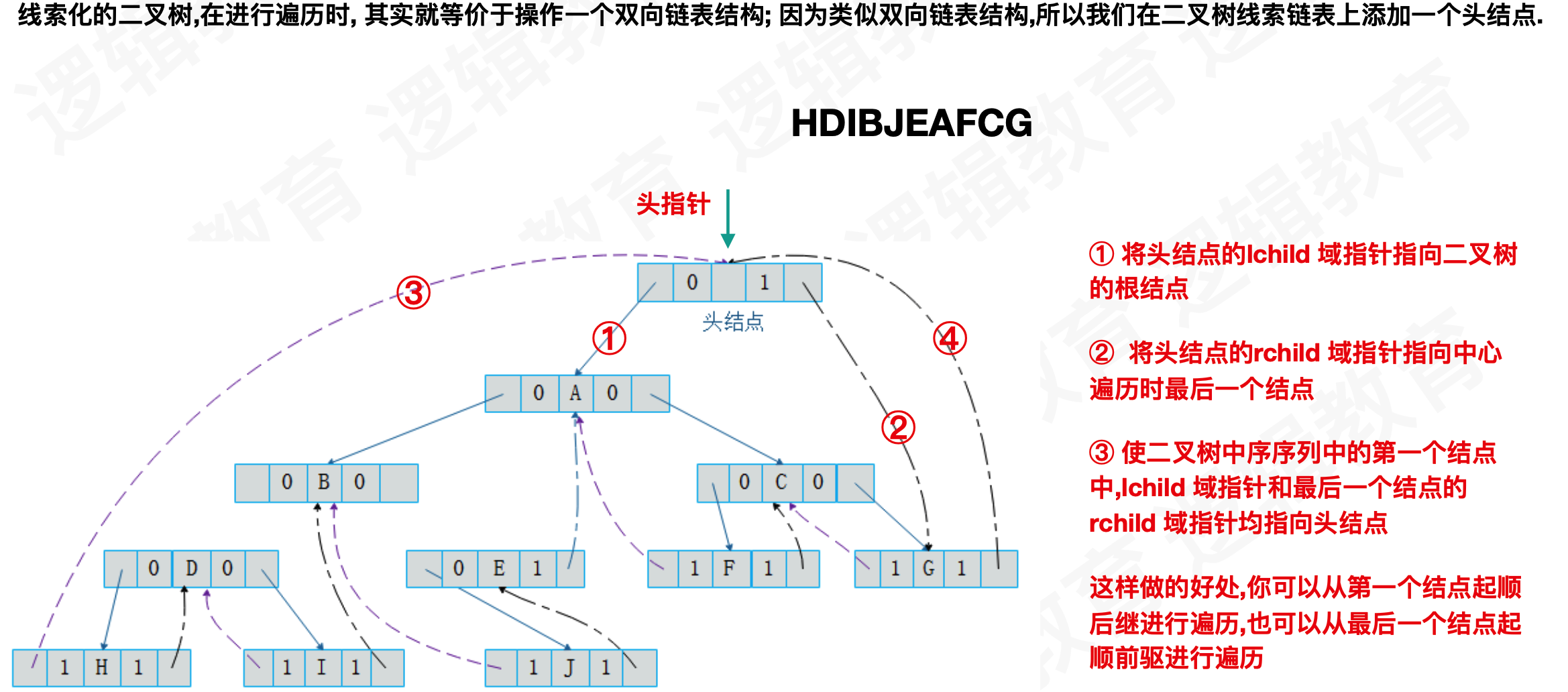
首先我们要来看看这空指针有多少个呢?对于一个有n个结点的二叉链表,每个结点有指向左右孩子的两个指针域,所以一共是2n个指针域。而n个结点的二叉树一共有n-1条分支线数,也就是说,其实是存在2n-(n-1)=n+1个空指针域。比如图有10个结点,而带有“∧”空指针域为11。这些空间不存储任何事物,白白的浪费着内存的资源。
另一方面,我们在做遍历时,比如对图做中序遍历时,得到了HDIBEJAFCG这样的字符序列,遍历过后,我们可以知道,结点I的前驱是D,后继是B,结点F的前驱是A,后继是C。也就是说,我们可以很清楚的知道任意一个结点,它的前驱和后继是哪一个。
可是这是建立在已经遍历过的基础之上的。在二叉链表上,我们只能知道每个结点指向其左右孩子结点的地址,而不知道某个结点的前驱是谁,后继是谁。要想知道,必须遍历一次。以后每次需要知道时,都必须先遍历一次。为什么不考虑在创建时就记住这些前驱和后继呢,那将是多大的时间上的节省。
二:构建线索化二叉树
们将这棵二叉树的所有空指针域中的lchild,改为指向当前结点的前驱。因此H的前驱是NULL(图中①),I的前驱是D(图中②),J的前驱是B(图中③),F的前驱是A(图中④),G的前驱是C(图中⑤)。一共5个空指针域被利用,正好和上面的后继加起来是11个。
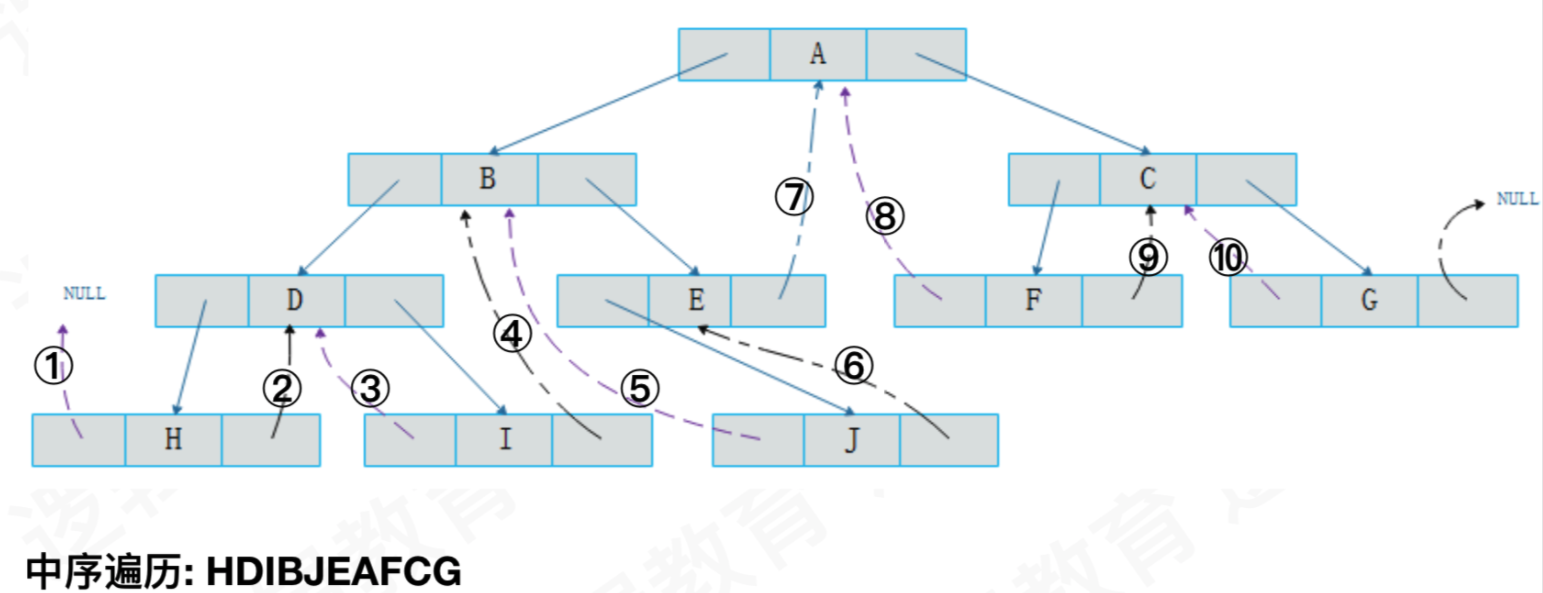
2:双向链表
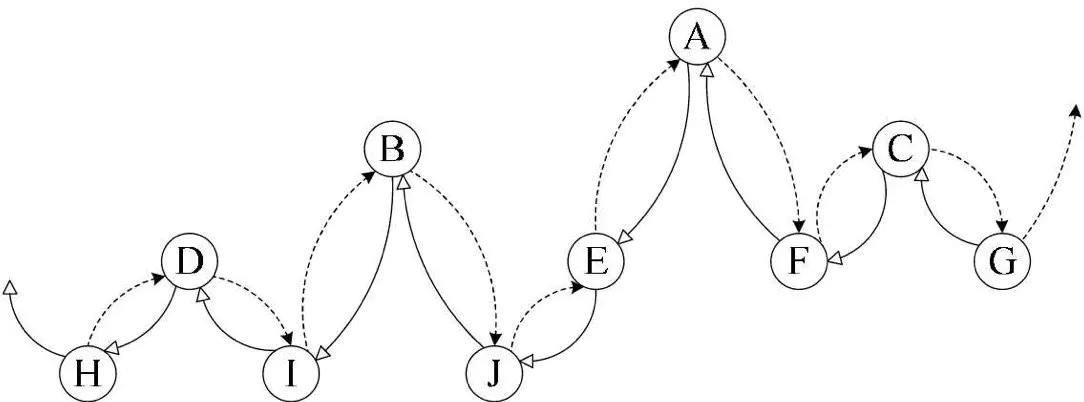
3:问题?如何区分一个结点的左孩子指针指向的是左孩子还是前驱结点?
这个时候我们引入了tag标示,用来标示该指针指向的是孩子还是前驱或者后继
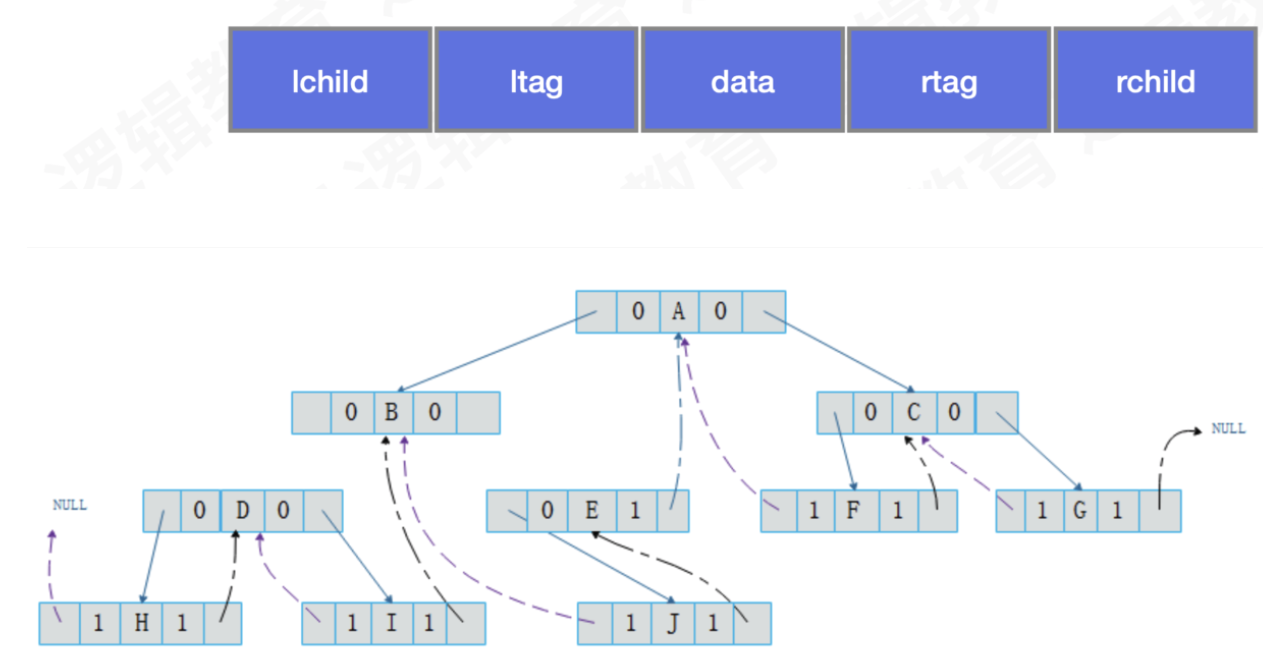
其中:
- ltag为0时指向该结点的左孩子,为1时指向该结点的前驱。
- rtag为0时指向该结点的右孩子,为1时指向该结点的后继。
- 因此对于上面的二叉链表图可以修改为下图5的样子。
三:代码实现线索化二叉树
1:线索二叉树存储结点结构
/* 线索二叉树存储结点结构*/ typedef struct BiThrNode{ //数据 CElemType data; //左右孩子指针 struct BiThrNode *lchild,*rchild; //左右标记 PointerTag LTag; PointerTag RTag; }BiThrNode,*BiThrTree;
2:中序遍历线索二叉树T, 将其中序线索化,Thrt指向头结点

/* 8.3 中序遍历二叉树T, 将其中序线索化,Thrt指向头结点 */ BiThrTree pre; /* 全局变量,始终指向刚刚访问过的结点 */ /* 中序遍历进行中序线索化*/ void InThreading(BiThrTree p){ /* InThreading(p->lchild); ..... InThreading(p->rchild); */ if (p) { //递归左子树线索化 InThreading(p->lchild); //无左孩子 if (!p->lchild) { //前驱线索 p->LTag = Thread; //左孩子指针指向前驱 p->lchild = pre; }else { p->LTag = Link; } //前驱没有右孩子 if (!pre->rchild) { //后继线索 pre->RTag = Thread; //前驱右孩子指针指向后继(当前结点p) pre->rchild = p; }else { pre->RTag = Link; } //保持pre指向p的前驱 pre = p; //递归右子树线索化 InThreading(p->rchild); } }
线索二叉树-双向链表(中序)
/* 中序遍历二叉树T,并将其中序线索化,Thrt指向头结点 */ Status InOrderThreading(BiThrTree *Thrt , BiThrTree T){ *Thrt=(BiThrTree)malloc(sizeof(BiThrNode)); if (! *Thrt) { exit(OVERFLOW); } //建立头结点; (*Thrt)->LTag = Link; (*Thrt)->RTag = Thread; //右指针回指向 (*Thrt)->rchild = (*Thrt); /* 若二叉树空,则左指针回指 */ if (!T) { (*Thrt)->lchild=*Thrt; }else{ (*Thrt)->lchild=T; pre=(*Thrt); //中序遍历进行中序线索化 InThreading(T); //最后一个结点rchil 孩子 pre->rchild = *Thrt; //最后一个结点线索化 pre->RTag = Thread; (*Thrt)->rchild = pre; } return OK; }
中序遍历二叉线索树T(双向链表)

##/*中序遍历二叉线索树T*/ Status InOrderTraverse_Thr(BiThrTree T){ BiThrTree p; p=T->lchild; /* p指向根结点 */ while(p!=T) { /* 空树或遍历结束时,p==T */ while(p->LTag==Link) p=p->lchild; if(!visit(p->data)) /* 访问其左子树为空的结点 */ return ERROR; while(p->RTag==Thread&&p->rchild!=T) { p=p->rchild; visit(p->data); /* 访问后继结点 */ } p=p->rchild; } return OK; }
本质
二叉树的遍历本质上是将一个复杂的非线性结构转换为线性结构,使每个结点都有了唯一前驱和后继(第一个结点无前驱,最后一个结点无后继)。对于二叉树的一个结点,查找其左右子女是方便的,其前驱后继只有在遍历中得到。为了容易找到前驱和后继,有两种方法。一是在结点结构中增加向前和向后的指针,这种方法增加了存储开销,不可取;二是利用二叉树的空链指针。
优势与不足
优势
(1)利用线索二叉树进行中序遍历时,不必采用堆栈处理,速度较一般二叉树的遍历速度快,且节约存储空间。
(2)任意一个结点都能直接找到它的前驱和后继结点。
不足
(1)结点的插入和删除麻烦,且速度也较慢。
(2)线索子树不能共用。
四:⼆叉树的应⽤-哈夫曼编码
1:哈夫曼的思考
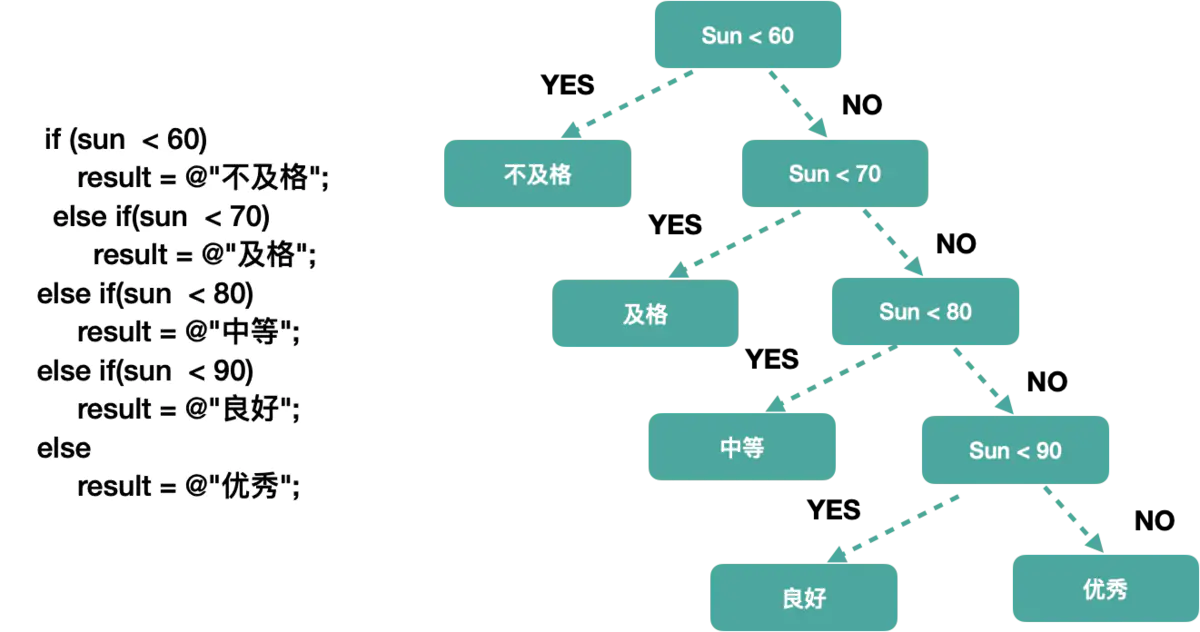
想要找到一个成绩所处的等级,都需要从60开始判断

成绩⽐比重: 在70~89分之间占⽤用了了70% 但是都是需要经过3次判断才能得到正 确的结果. 那么如果数量量集⾮非常⼤大时,这样的⽐比较就会出现效率问题.
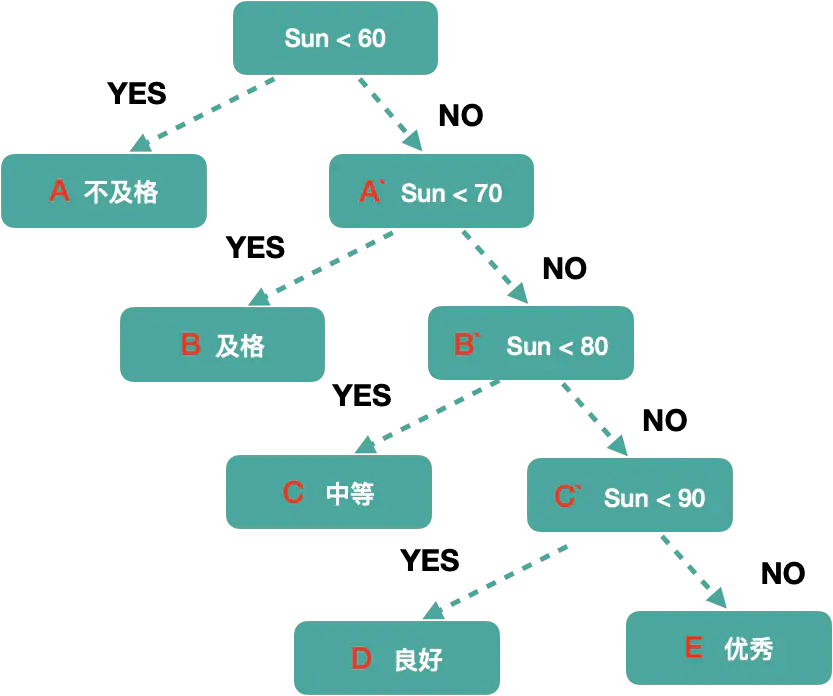
思考:
1:结点D 的路路径⻓长度是?
2:树的路路径⻓长度?
定义:
给定n个权值作为n个叶子结点,构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树。
(01) 路径和路径长度
定义:在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。 例子:100和80的路径长度是1,50和30的路径长度是2,20和10的路径长度是3。
(02) 结点的权及带权路径长度
定义:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。 例子:节点20的路径长度是3,它的带权路径长度= 路径长度 * 权 = 3 * 20 = 60。
(03) 树的带权路径长度
定义:树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
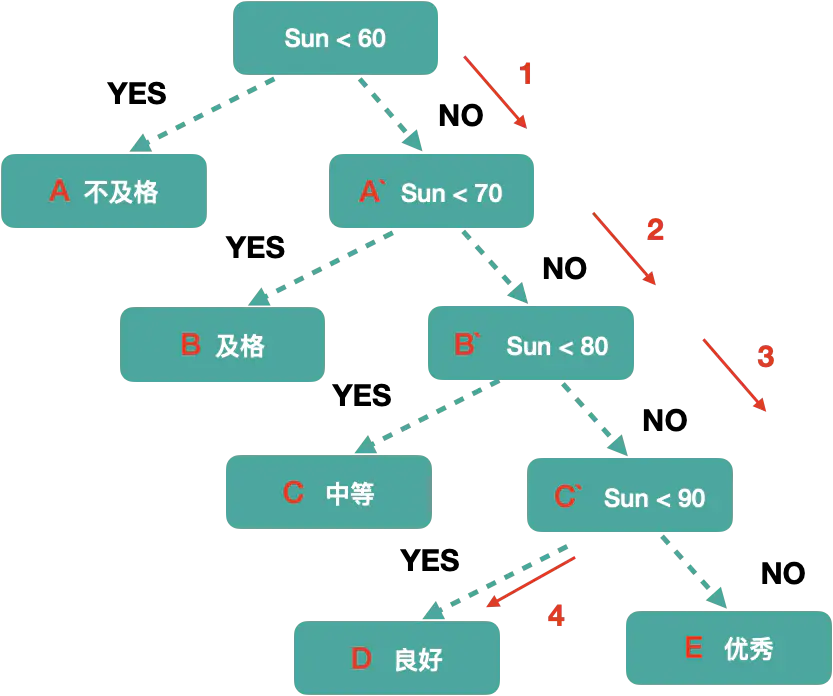
sum = 1+1+2+2+3+3+4+4 = 20 A =1 A’ = 1 B =2 B’ = 2
C =3 C’ = 3
D =4 E =4
但是上面我们根据概率统计发现CD连个区域的概率相对来说是大一点的,重新规划一下书的结构
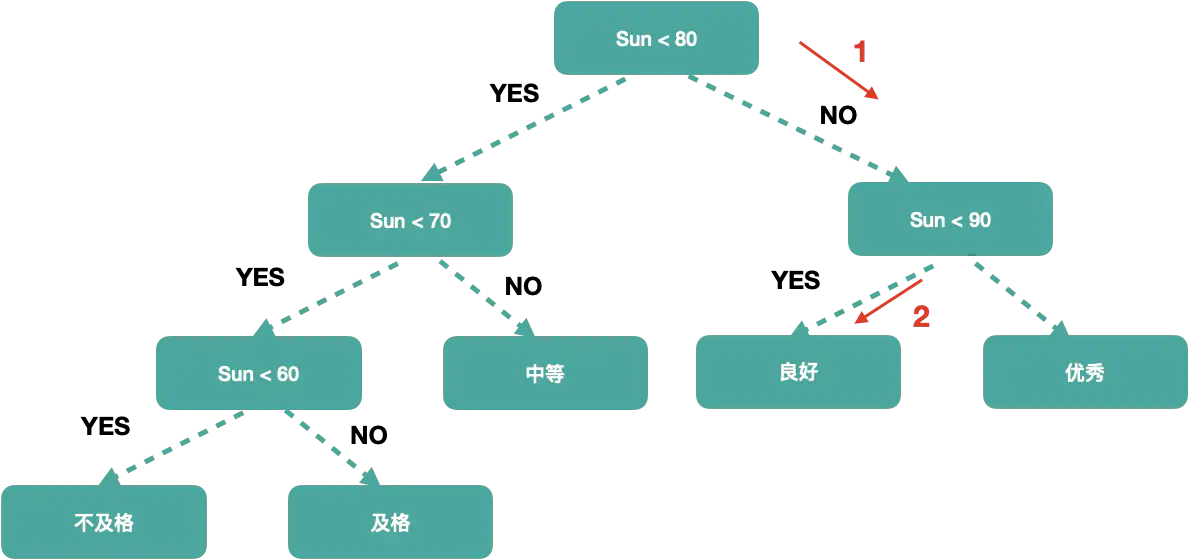
sum = 1+2+3 +3 +2 +1 + 2 + 2 = 16 B’ = 1 A’ = 2 A =3 sum < 80 B =3 C =2 C’ = 1 D =2 E =2
最后我们可以发现
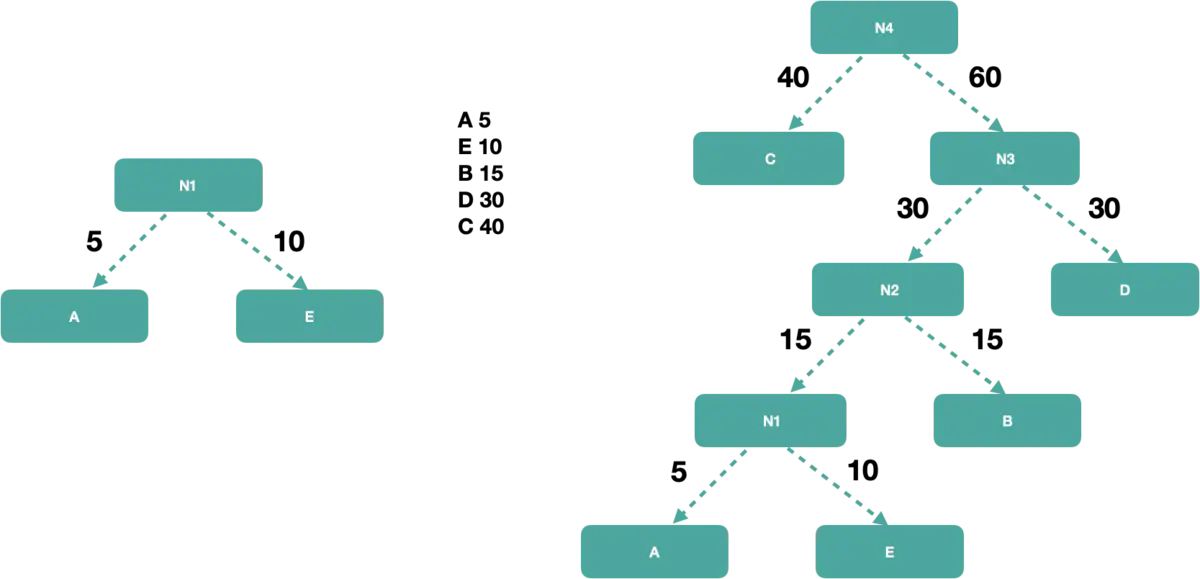
🌲1的WPL = 1 * 5 + 2 * 15 + 3 *40 +4 * 30 + 4 * 10 = 315
🌲2的WPL = 5 * 3 + 15 * 3 + 40 * 2 + 30 * 2 +10 * 2 = 220
所以🌲2的WPL就比🌲1的WPL小很多
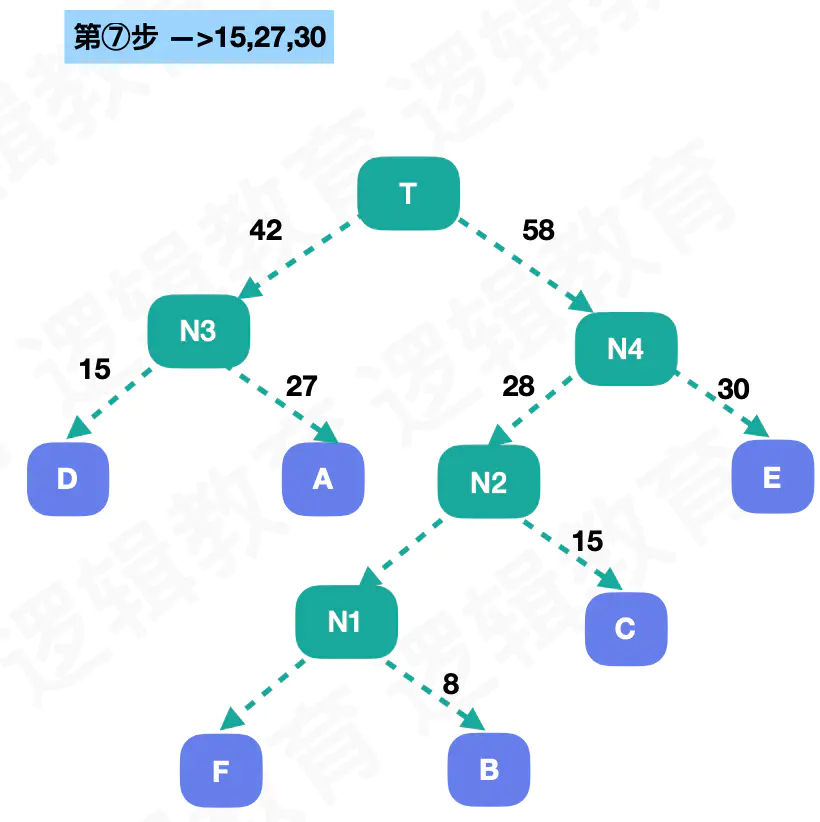
2:如何创建一个哈夫曼树
- 所有的权重进行排序
- 去除最小的两个权重,按照左子树永远小于右子树,如果相等的情况下依然左子树的优先级高,合成一个新的结点
- 3.如果遇见新的结点的权重大于剩余权重的最小者,那么新结点就变成了右子树,一次合并成为新的一个🌲
- 如果新结点比剩余权重的两个以上都大,那么 剩余权重可以重新合成一个树,最后按照左子树小于等于右子树的规则合并成为一个🌲
这样我们就得到了一个WPL最小的树,这种树就叫做哈夫曼树
3:哈夫曼编码的使用
正常我们传输数据最终形式都0和1的组合,假如我们把abcd按照正常数据排列就是

- 字母都是通过三位的二进制表示,后面数字是该字母在传输数据中出现的次数,这样我们传输数据时候每个字母都是需要三位0或者1来表示
- 假如我们通过编码让不同的组合表示字母,这样就会减少0和1的位数,从而减少数据的传输量
- 这种方式用到文件压缩中
我们通过哈夫曼编码来进行转换:
假如我们将左子树的路径叫做0,右子树的路径叫做1,我们通过路径来标示字符就能得到下面编码:
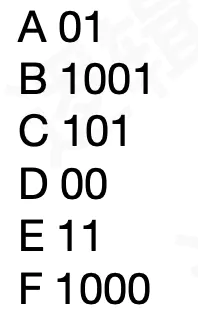

4:哈夫曼编码实现:
1:哈夫曼结点表现的形式


2:实现思路
哈夫曼树的实现思路路:
- 获取根据权值构建的哈夫曼树
- 循环遍历[0,n]个结点;
- 创建临时结点cd ,从根结点开始对⻬齐进⾏行行编码,左孩⼦子为0,右孩⼦子为1;
- 将编码后的结点存储haffCode[i]
- 设置HaffCode[i]的开始位置以及权值;
3:代码
const int MaxValue = 10000;//初始设定的权值最大值 const int MaxBit = 4;//初始设定的最大编码位数 const int MaxN = 10;//初始设定的最大结点个数 // 构建哈弗曼树的结点 typedef struct HaffNode { int weight; // 权值 int flag; // 是否使用过 int parent; // 父节点索引 int leftChild; // 左儿子索引 int rightChild; // 右儿子索引 } HaffNode; typedef struct Code//存放哈夫曼编码的数据元素结构,哈夫曼编码其实就是对应的数据(叶子节点) { int bit[MaxBit];//路径数组 int start; //编码的起始下标,相当于bit数组的下标 int weight;//字符的权值 }Code; //1. //根据权重值,构建哈夫曼树; //{2,4,5,7} //n = 4; void Haffman(int weight[],int n,HaffNode *haffTree){ int j,m1,m2,x1,x2; //1.哈夫曼树初始化 //n个叶子结点. 2n-1 for(int i = 0; i < 2*n-1;i++){ if(i<n) haffTree[i].weight = weight[i]; else haffTree[i].weight = 0; haffTree[i].parent = 0; haffTree[i].flag = 0; haffTree[i].leftChild = -1; haffTree[i].rightChild = -1; } //2.构造哈夫曼树haffTree的n-1个非叶结点 for (int i = 0; i< n - 1; i++){ m1 = m2 = MaxValue; x1 = x2 = 0; //2,4,5,7...j<n+i是因为i每遍历一次,haffTree数组里面就多设置了一个结点,也就是非叶子结点 for (j = 0; j< n + i; j++)//循环找出所有权重中,最小的二个值--morgan { if (haffTree[j].weight < m1 && haffTree[j].flag == 0) { m2 = m1; x2 = x1; m1 = haffTree[j].weight; x1 = j; } else if(haffTree[j].weight<m2 && haffTree[j].flag == 0) { m2 = haffTree[j].weight; x2 = j; } } //3.将找出的两棵权值最小的子树合并为一棵子树 haffTree[x1].parent = n + i; haffTree[x2].parent = n + i; //将2个结点的flag 标记为1,表示已经加入到哈夫曼树中 haffTree[x1].flag = 1; haffTree[x2].flag = 1; //修改n+i结点的权值 haffTree[n + i].weight = haffTree[x1].weight + haffTree[x2].weight; //修改n+i的左右孩子的值 haffTree[n + i].leftChild = x1; haffTree[n + i].rightChild = x2; } } /* 9.2 哈夫曼编码 由n个结点的哈夫曼树haffTree构造哈夫曼编码haffCode //{2,4,5,7} */ void HaffmanCode(HaffNode haffTree[], int n, Code haffCode[]) { //1.创建一个结点cd,类似于temp,中间者 Code *cd = (Code * )malloc(sizeof(Code)); int child, parent; //2.求n个叶结点的哈夫曼编码,haffTree的叶子节点都在最前面,非叶子节点在后面 for (int i = 0; i<n; i++) { //从0开始计数, cd->start = 0; //取得编码对应权值的字符 cd->weight = haffTree[i].weight; //当叶子结点i 为孩子结点. child = i; //找到child 的双亲结点; parent = haffTree[child].parent; //由叶结点向上直到根结点,将该结点的路径找出来 while (parent != 0) { //得到一个编码 if (haffTree[parent].leftChild == child) cd->bit[cd->start] = 0;//左孩子结点编码0 else cd->bit[cd->start] = 1;//右孩子结点编码1 //编码下标自增 cd->start++; //将双亲结点设置为子结点,往上遍历 child = parent; //找到双亲结点 parent = haffTree[child].parent; } int temp = 0; //把cd中的数据赋值到haffCode[i]中. for (int j = cd->start - 1; j >= 0; j--){ temp = cd->start-j-1; haffCode[i].bit[temp] = cd->bit[j]; } //保存好haffCode 的起始位以及权值; haffCode[i].start = cd->start; //保存编码对应的权值 haffCode[i].weight = cd->weight; } } int main(int argc, const char * argv[]) { // insert code here... printf("Hello, 哈夫曼编码!\n"); int i, j, n = 4, m = 0; //权值 int weight[] = {2,4,5,7}; //初始化哈夫曼树, 哈夫曼编码 HaffNode *myHaffTree = malloc(sizeof(HaffNode)*2*n-1); Code *myHaffCode = malloc(sizeof(Code)*n); //当前n > MaxN,表示超界. 无法处理. if (n>MaxN) { printf("定义的n越界,修改MaxN!"); exit(0); } //1. 构建哈夫曼树 Haffman(weight, n, myHaffTree); //2.根据哈夫曼树得到哈夫曼编码 HaffmanCode(myHaffTree, n, myHaffCode); //3. for (i = 0; i<n; i++) { printf("Weight = %d\n",myHaffCode[i].weight); for (j = 0; j<myHaffCode[i].start; j++) printf("%d",myHaffCode[i].bit[j]); m = m + myHaffCode[i].weight*myHaffCode[i].start; printf("\n"); } printf("Huffman's WPS is:%d\n",m); return 0; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号