03*:双向链表与双向循环链表的实现:(前驱、数据域、后继)(初始化、插入、删除、遍历、查找、更新、长度)
问题
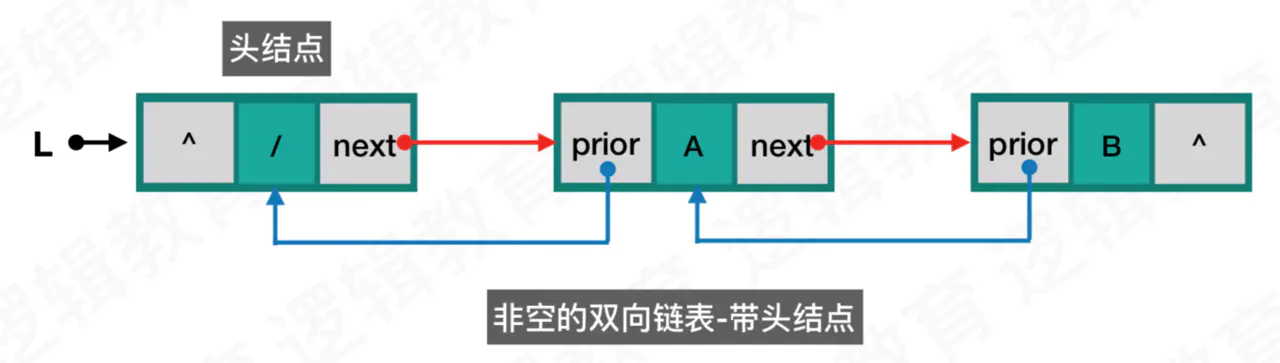
带有头结点的双向链表
带有头结点的双向循环链表
目录
1:双向链表
2:双向链表的操作
3:双向循环链表
预备
正文
一、双向链表
1、结点
单向链表相对数组来说已经有很多优点了,但是,它还有一个最大的弊端,那就是在某种程度上和深度优先遍历有通性.一条路走到黑,从不回头!这种特性在进行数据操作时,会大大浪费时间,鉴于此,出现了双向链表的概念。
顾名思义,双向链表就是具备两个方向的指向,无非就是每个结点成了两个指针。
每次在插入或删除某个节点时, 需要处理四个节点的引用, 而不是两个. 也就是实现起来要困难一些 . 一个节点既有向前连接的引用, 也有一个向后连接的引用.
顾名思义,双向链表就是具备两个方向的指向,无非就是每个结点成了两个指针。
每次在插入或删除某个节点时, 需要处理四个节点的引用, 而不是两个. 也就是实现起来要困难一些 . 一个节点既有向前连接的引用, 也有一个向后连接的引用.

创建结点
//定义结点 typedef struct Node{ ElemType data; struct Node *prior; struct Node *next; }Node; typedef struct Node * LinkList;
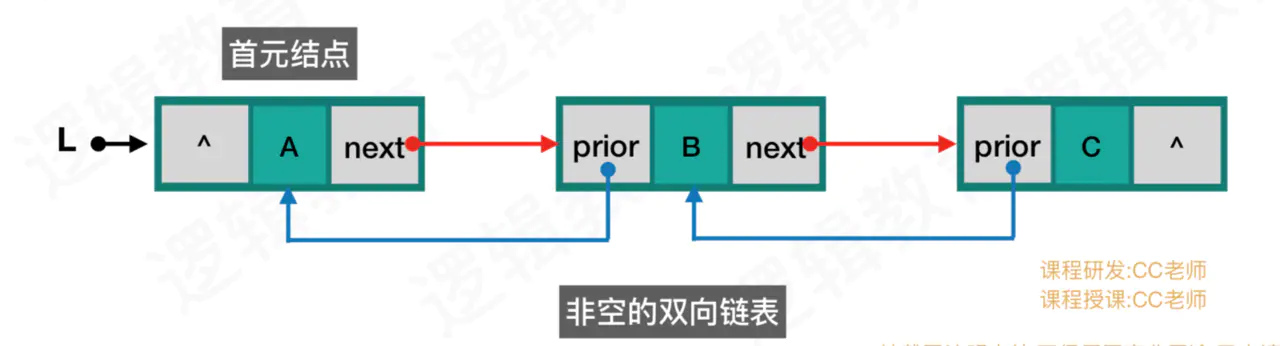
2、结构
非空的带头结点的双向链表:头结点中的数据为空
二、双向链表的操作
1:预备
// ElemtType类型根据实际情况而定,这里假设为int typedef int ElemType; #define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 // Status是函数的类型,其值是函数结果状态代码,如OK等 typedef int Status; // 线性表的双向链表存储结构 typedef struct DulNode { ElemType data; struct DulNode *prior;//前驱 struct DulNode *next;//后继 } DulNode, *DulLinkList;
2: 创建双向链表
- 初始化头结点信息*L的前驱以及后继
- 创建新的临时节点
-
为新增的节点建立依赖关系
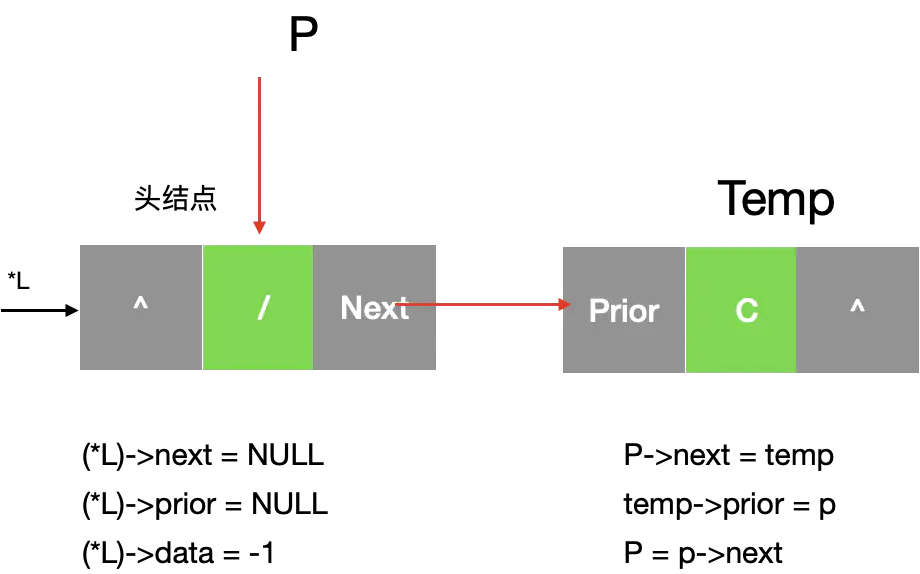
//创建双向链表—— 带有十个元素的链表 int createLinkList(LinkList *L){ //*L 头结点的建立 *L = (LinkList)malloc(sizeof(Node)); if (*L == NULL) return 0;
// 头结点赋值 (*L)->prior = NULL; (*L)->next = NULL; (*L)->data = -1; //新增数据 LinkList p = *L; for(int i=0; i < 10;i++){ //1.创建1个临时的结点 LinkList temp = (LinkList)malloc(sizeof(Node)); temp->prior = NULL; temp->next = NULL; temp->data = I; //2.为新增的结点建立双向链表关系 //① temp 是p的后继 p->next = temp; //② temp 的前驱是p temp->prior = p; //③ p 要记录最后的结点的位置,方便下一次插入 p = p->next; } return 1; }
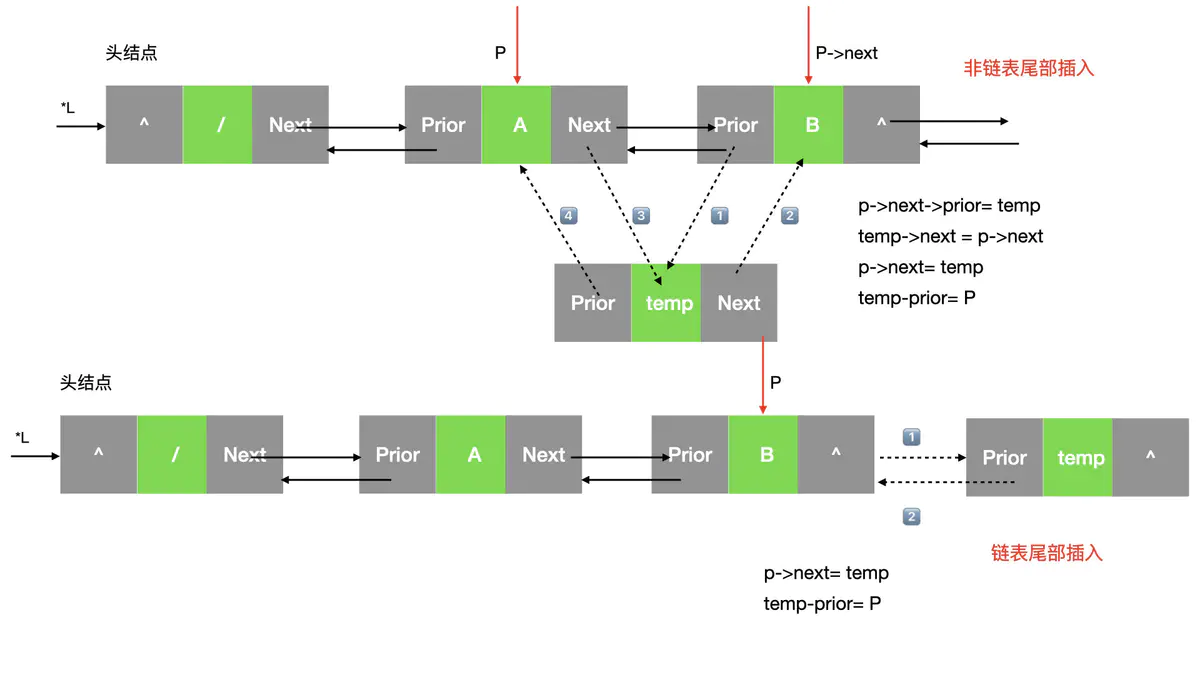
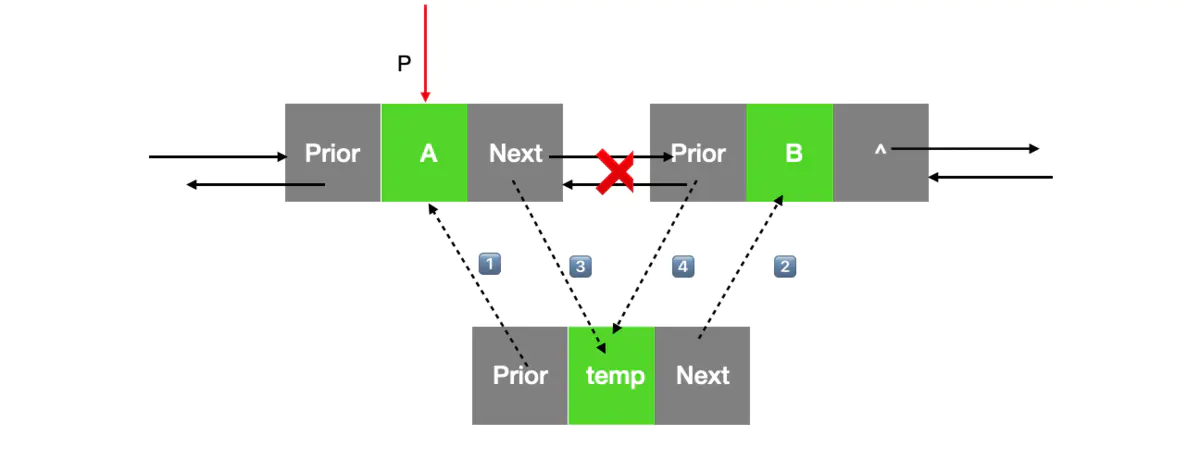
3:指定位置 插入 值 (普通和尾部)
- 边界条件的判断
- 新建结点temp,对它进行赋值prior\next = NULL data = data
- 方便书写。新建一个LinkList p = *L;
- 找到需要插入数据的前一个位置
- 判断插入的位置是否是链表的尾部
- 尾部和非尾部的两种处理
- 非尾部插入
7.1 把需要插入节点的节点的prior指向新创建的节点 p->next->prior = temp;
7.2 将temp的next指向 要插入的位置的节点,temp->next = p->next;
7.3 将原来的p->next指向新创建的节点temp p->next = temp;
7.4 新创建的节点temp的前驱更新为片
(1、2的先后顺序可以互换,3、4的执行顺序也可以互换,但是必须要保证12在34之前执行,防止丢掉后面的节点)
/* 双向链表的插入 */ Status linkLinstInsertData(linkList *L, int place ,ElemType data){ if( *L == NULL) return ERROR; if( place < 1) return ERROR; /* 创建临时结点 */ linkList temp = (linkList)malloc(sizeof(Node)); temp ->data = data; temp->next = NULL; temp->prior = NULL; linkList p = (*L); /* 找到插入结点的位置的前一个结点 */ for (int i = 1; i < place && p; i++) { p = p->next; } /* 如果插入的位置超过链表本身的长度*/ if(p == NULL){ return ERROR; } if (p->next == NULL) {/* 最后一个结点 */ p->next = temp ; temp->prior = p ; } else { /*1️⃣ 将p->next 结点的前驱prior = temp*/ p->next->prior = temp; /*2️⃣ 将temp->next 指向原来的p->next*/ temp->next = p->next; /*3️⃣ p->next 更新成新创建的temp*/ p->next = temp; /*4️⃣ 新创建的temp前驱 = p*/ temp->prior = p; } return OK; }
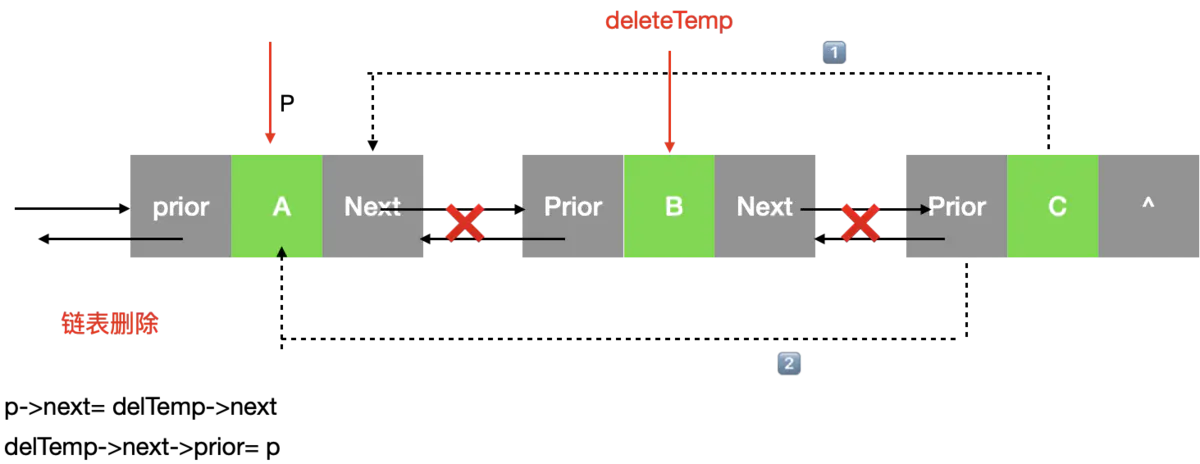
4:删除 指定位置 的结点
找到要删除的结点的前一个位置p, 创建一个临时结点deleTemp。进行判断
- 链表非尾部删除 p->next = deleTemp->next delTemp->next->prior = p
- 链表尾部删除 p->next = deleTemp->next
/* 删除指定位置的节点 */ Status deleteLinkListDataInPlace(linkList * L,int place ,ElemType *deleteData){ /* 判断双向链表是否为空,如果为空则返回ERROR */ if(*L == NULL) return ERROR; linkList p = *L; int k = 1; int length = linkLinstLength(L); /* 超过链表长度 */ if (place > length) { printf("超出链表最大长度\n"); return ERROR; }
// 找到K前面的元素 while (k < place && p != NULL) { p = p->next; k++; } /* 如果k>i 或者 p == NULL 则返回ERROR */ if (k > place || p == NULL) return ERROR; /* 创建临时指针delTemp 指向要删除的结点,并将要删除的结点的data 赋值给*e,带回到main函数 */ linkList deleTemp = p->next ; *deleteData = deleTemp->data ; /* p->next 等于要删除的结点的下一个结点 */ p->next = deleTemp->next ; /* 如果删除结点的下一个结点不为空,则将将要删除的下一个结点的前驱指针赋值p */ if (deleTemp->next != NULL) { deleTemp->next->prior = p; } /* 删除delTemp结点 */ free(deleTemp) ; return OK; }
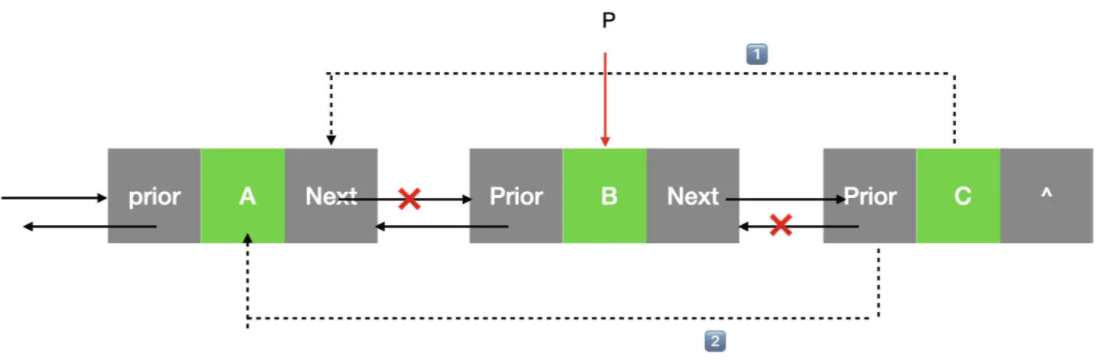
5:删除 指定元素 的结点
- 通过遍历链表找到指定元素的结点而非指定元素的前一个结点
-
判断data数据域是否相等
2.1 相等的情况下。
2.1.1 把当前结点的前驱(要删除的元素的前一个结点)的next指向当前结点的的next:p->prior->next = p->next
2.1.2 判断如果要删除的结点不是最后一个结点,当前结点的next(要删除的元素的前一个结点)的前驱指向当前结点的的前驱:p->next->prior =p->prior
2.2 不相等,继续移动指针遍历
/* 删除指定数据的节点 */ Status deleteDataInListLinst(linkList *L ,int data,ElemType *index){ /* 判断双向链表是否为空,如果为空则返回ERROR */ if(*L == NULL) return ERROR; int i = 0 ; /* 遍历双向链表 */ linkList p = *L; while (p) { /* 判断当前结点的数据域和data是否相等,若相等则删除该结点 */ if (p->data == data) { p->prior->next = p->next; /* 判断当前删除的结点是不是最后一个结点 */ if (p->next != NULL) { /* 修改被删除结点的后继结点的前驱指针 */ p->next->prior =p->prior; } /* 释放被删除结点p */ free(p); /* 只删除一个结点 */ break; } /* 没有找到该结点,则继续移动指针p */ p = p->next; i++; } if(p == NULL){ printf("未找到需要删除的数据\n"); return ERROR; } *index = i ; return OK ; }
6:遍历
//5.2 打印循环链表的元素 void display(LinkList L){ LinkList temp = L->next; if(temp == NULL){ printf("打印的双向链表为空!\n"); return; } while (temp) { printf("%d ",temp->data); temp = temp->next; } printf("\n"); }
7:查找结点
int selectElem(LinkList L,ElemType elem){ LinkList p = L->next; int i = 1; while (p) { if (p->data == elem) { return i; } i++; p = p->next; } return -1;
8:更新结点
Status replaceLinkList(LinkList *L,int index,ElemType newElem){ LinkList p = (*L)->next; for (int i = 1; i < index; i++) { p = p->next; } p->data = newElem; return OK; }
9: 链表的长度
/* 链表的长度 */ int linkLinstLength(linkList *L){ int i = 0 ; linkList temp = *L; while (temp->next != NULL ) { temp = temp->next; i++; } printf("链表的长度 %d\n",i); return i; }
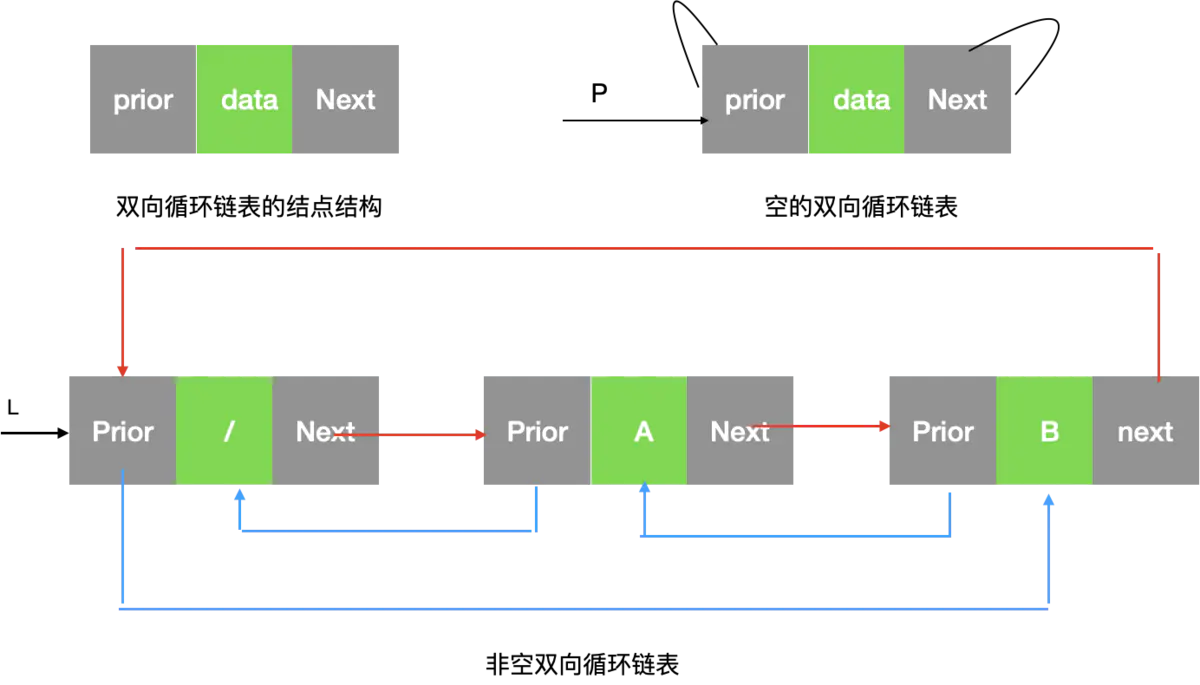
三:双向循环链表
最大的不同之处在于:头结点个尾结点的指向的不同
双向链表的头结点的前驱是null,尾结点的next是null
双向循环链表的头结点的前驱prior指向最后一个结点,尾结点的next指向头结点
1:创建
- 初始化头结点p = *L 它的prior,next都指向自己
- 创建一个新的临时结点temp建立依赖关系
- P的next =temp
- temp->prior = P
- temp->next = (*L)
- p->prior = temp
- p 要记录最后的结点的位置,方便下一次插入 p = p->next
Status creatLinkList(LinkList *L){ *L = (LinkList)malloc(sizeof(Node)); if (*L == NULL) { return ERROR; } (*L)->next = (*L); (*L)->prior = (*L); //新增数据 LinkList p = *L; for(int i=0; i < 10;i++){ //1.创建1个临时的结点 LinkList temp = (LinkList)malloc(sizeof(Node)); temp->data = i; //2.为新增的结点建立双向链表关系 //① temp 是p的后继 p->next = temp; //② temp 的前驱是p temp->prior = p; //③ temp的后继是*L temp->next = (*L); //④ p 的前驱是新建的temp (*L)->prior = temp; //⑤ p 要记录最后的结点的位置,方便下一次插入 p = p->next; } return OK; }
2:插入
1.找到要插入的结点的前一个结点
2.创建新结点temp,data赋值
3.结点temp 的前驱结点为p
4.temp的后继结点指向p->next
5.p的后继结点为新结点temp
6.如果temp 结点不是最后一个结点
6.1 是最后一个结点 头结点的prior 指向temp (*L)->prior = temp
6.2 不是最后一个结点 temp节点的下一个结点的前驱为temp 结点 temp->next->prior = temp
2.创建新结点temp,data赋值
3.结点temp 的前驱结点为p
4.temp的后继结点指向p->next
5.p的后继结点为新结点temp
6.如果temp 结点不是最后一个结点
6.1 是最后一个结点 头结点的prior 指向temp (*L)->prior = temp
6.2 不是最后一个结点 temp节点的下一个结点的前驱为temp 结点 temp->next->prior = temp
/*当插入位置超过链表长度则插入到链表末尾*/ Status LinkListInsert(LinkList *L, int index, ElemType e){ //1. 创建指针p,指向双向链表头 LinkList p = (*L); int i = 1; //2.双向循环链表为空,则返回error if(*L == NULL) return ERROR; //3.找到插入前一个位置上的结点p while (i < index && p->next != *L) { p = p->next; i++; } //4.如果i>index 则返回error if (i > index) return ERROR; //5.创建新结点temp LinkList temp = (LinkList)malloc(sizeof(Node)); //6.temp 结点为空,则返回error if (temp == NULL) return ERROR; //7.将生成的新结点temp数据域赋值e. temp->data = e; //8.将结点temp 的前驱结点为p; temp->prior = p; //9.temp的后继结点指向p->next; temp->next = p->next; //10.p的后继结点为新结点temp; p->next = temp; //如果temp 结点不是最后一个结点 if (*L != temp->next) { //11.temp节点的下一个结点的前驱为temp 结点 temp->next->prior = temp; }else{ (*L)->prior = temp; } return OK; }
3:删除指定位置的结点
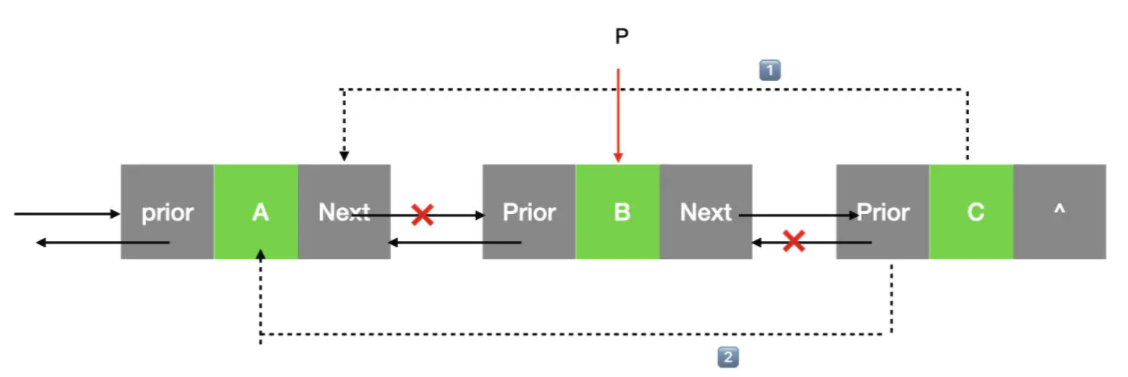
Status LinkListDelete(LinkList *L,int index,ElemType *e){ int i = 1; LinkList temp = (*L)->next; if (*L == NULL) { return ERROR; } //①.如果删除到只剩下首元结点了,则直接将*L置空; if(temp->next == *L){ free(*L); (*L) = NULL; return OK; } //1.找到要删除的结点 while (i < index) { temp = temp->next; i++; } //2.给e赋值要删除结点的数据域 *e = temp->data; //3.修改被删除结点的前驱结点的后继指针 temp->prior->next = temp->next; //4.修改被删除结点的后继结点的前驱指针 temp->next->prior = temp->prior; //5. 删除结点temp free(temp); return OK; }
4:遍历
Status Display(LinkList L){ if (L == NULL) { printf("打印的双向循环链表为空!\n\n"); return ERROR; } printf("双向循环链表内容: "); LinkList p = L->next; while (p != L) { printf("%d ",p->data); p = p->next; } printf("\n\n"); return OK; }
5:获取长度
int getLength(LinkList L){ LinkList p = L->next; int i = 1; while (p->next != L) { i++; p = p->next; } return i; }
总结
- 双向链表对比单向链表,多了一个前驱,用来记录该结点的上一个结点;
- 处理双向链表的插入和删除,需要多处理一个前驱;
- 双向链表在空间占用上比单链表要多一些,不过由于它良好的对称性,使得对某个结点的前后结点的操作,带来了方便,可以有效提高算法的时间性能。就是用空间来换时间。
注意


 浙公网安备 33010602011771号
浙公网安备 33010602011771号