
02*:单向循环链表的创建插入删除实现(1:线性表、2:单向循环链表)
问题
目录
预备
正文
1:线性表——链表结构与顺序存储结构优缺点对比
1:存储分配方式:
• 顺序存储结构⽤⽤⼀段连续的存储单元依次存储线性表的数据元素
• 单链表采⽤链式存储结构,⽤⼀组任意的存储单元存放线性表的元素
2:时间性能:
• 查找
• 顺序存储 O(1)
• 单链表O(n)
• 插⼊和删除
• 存储结构需要平均移动⼀个表⻓⼀半的元素,时间O(n)
• 单链表查找某位置后的指针后,插⼊和删除为 O(1)
3:空间性能:
• 顺序存储结构需要预先分配存储空间,分太⼤,浪费空间;分⼩了,发⽣上溢出
• 单链表不需要分配存储空间,只要有就可以分配, 元素个数也不受限制
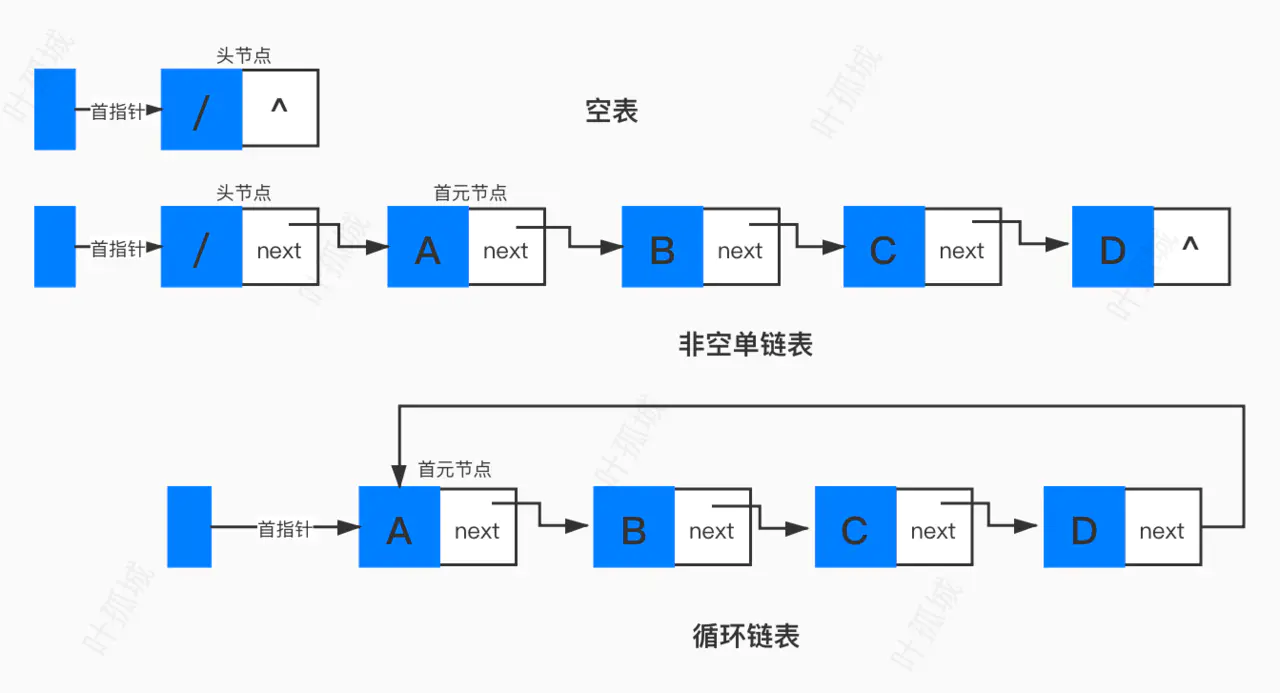
2:单向循环链表
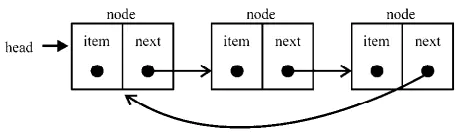
特点
1:循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活。
2:循环链表中没有NULL指针。涉及遍历操作时,其终止条件就不再是像非循环链表那样判别p或p->next是否为空,而是判别它们是否等于某一指定指针,如头指针或尾指针。
3:在单链表中,从一已知结点出发,只能访问到该结点及其后续结点,无法找到该结点之前的其它结点。而在单循环链表中,从任一结点出发都可访问到表中所有结点,这一优点使某些运算在单循环链表上易于实现。
代码
1:定义结构体
typedef int Status;/* Status是函数的类型,其值是函数结果状态代码,如OK等 */ typedef int ElemType;/* ElemType类型根据实际情况而定,这里假设为int */ //定义结点 typedef struct Node{ ElemType data; struct Node *next; }Node; typedef struct Node * LinkList;
2:尾插法创建链表
前面讲过,链表的尾插法创建,新节点放在尾节点之后,但是循环链表要注意新尾节点的next指向。
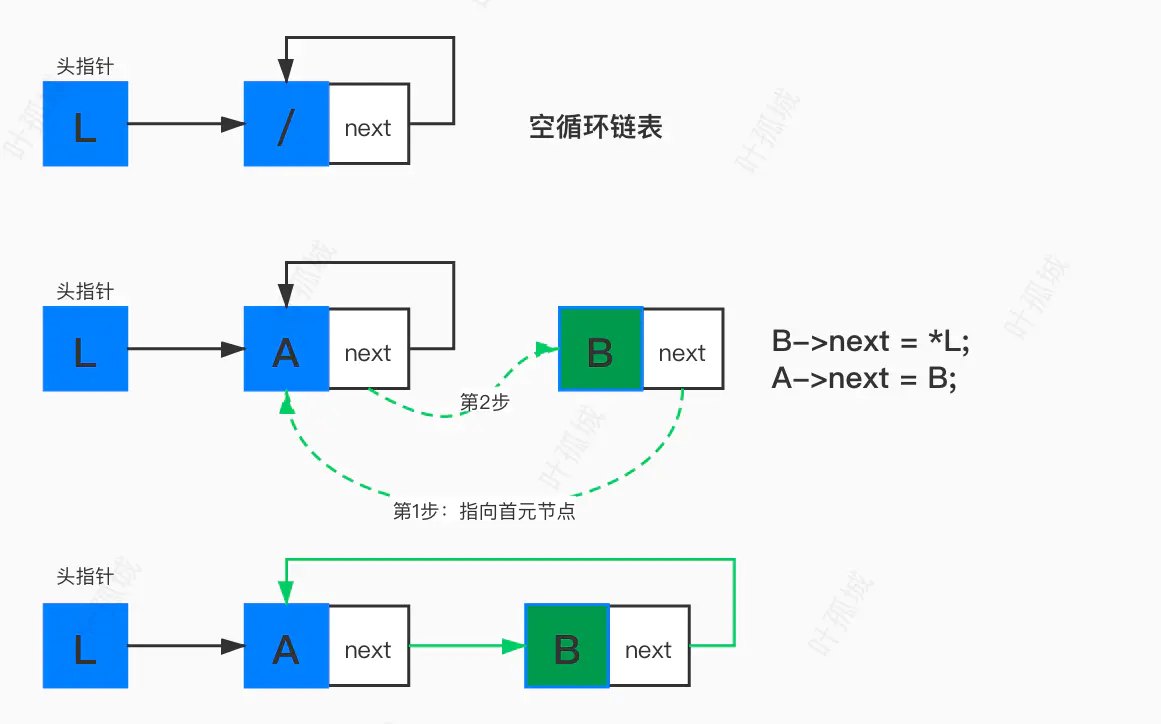
/* 1、链表是否已经存在 2、若不存在,创建新节点,头指针指向新节点,新节点->next指向新节点 3、若已存在,尾插法向后新增节点,新的尾节点->next指向首元节点,即*L */ Status CreateList(LinkList *L) { int item; LinkList temp = NULL; // 每次创建的新节点 LinkList fp = NULL; // 标记尾节点 while (1) { scanf("%d",&item); // 输入创建的新值 if (item == 0) break; // 输入为0时,结束创建 if (*L == NULL) { // 创建首元节点 temp = (LinkList)malloc(sizeof(Node)); if (temp == NULL) return 0; temp->data = item; // 向节点写入数据 temp->next = temp; // 首元节点的next指向自己,因为只有自己一个节点 fp = temp; // 首元节点也是尾节点 *L = temp; // 头指针指向首元节点 } else { // 向链表后追加新节点,并更新尾节点 // 创建新节点 temp = (LinkList)malloc(sizeof(Node)); if (temp == NULL) return 0; temp->data = item; // 新节点next指向尾节点的next 因为是循环,尾节点的next其实就是*L, // temp->next = fp->next; temp->next = *L; // 尾节点指向新节点 fp->next = temp; // 更新尾节点 fp = temp; } } return 1; } int main(int argc, const char * argv[]) { LinkList head; // 创建 CreateList(&head); // 输出链表 PrintList(head); return 0; }
3:遍历
void PrintList(LinkList L) { if (L == NULL) { printf("链表为空!"); } else { /* 第一种遍历方式 */ // LinkList temp = L; // do{ // printf("%5d",temp->data); // temp = temp->next; // }while (temp != L); /* 第二种遍历方式 */ // LinkList temp = L; // while (temp->next != L) { // printf("%5d",temp->data); // temp = temp->next; // } // printf("%5d\n",temp->data); /* 第三种遍历方式 */ LinkList temp = L; for (; temp->next!=L; temp = temp->next) { printf("%5d",temp->data); } printf("%5d\n",temp->data); } }
4:插入
注意: 插入数据是需要判断是不是插入在首节点位置 why?
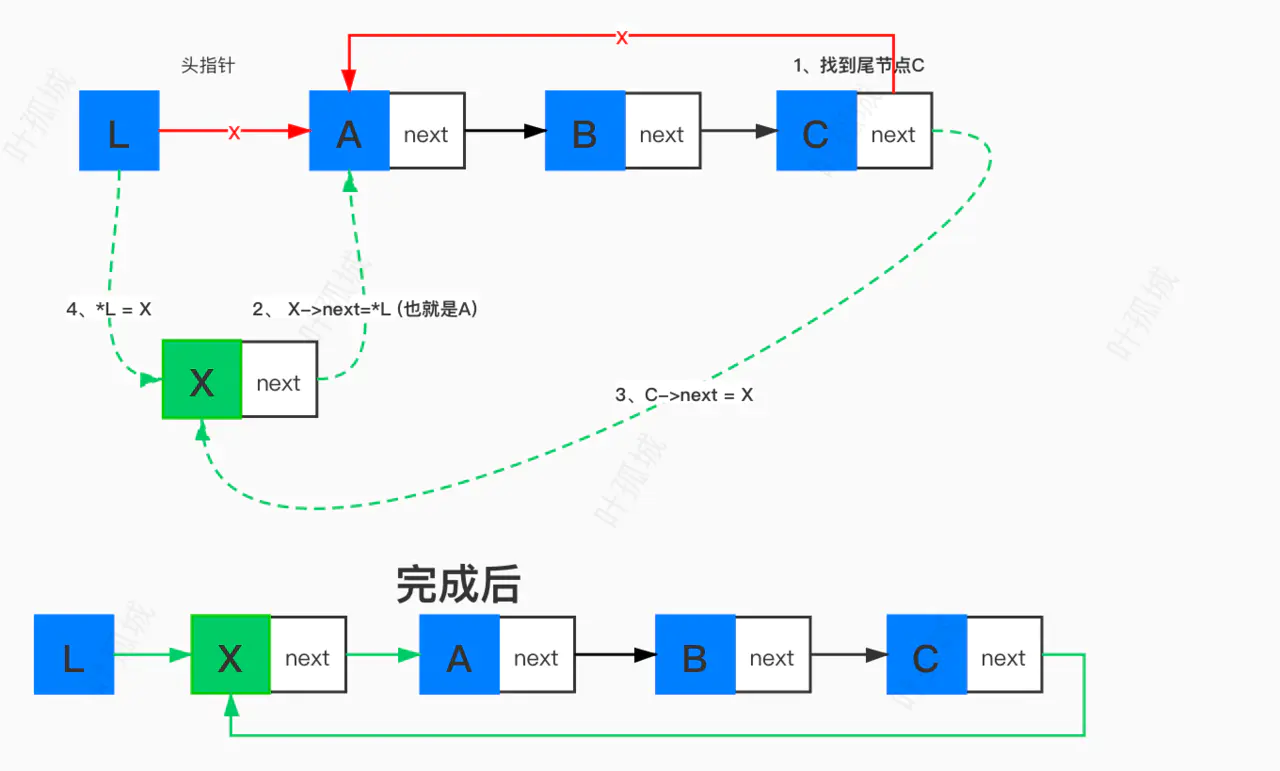
插入在其他任意位置
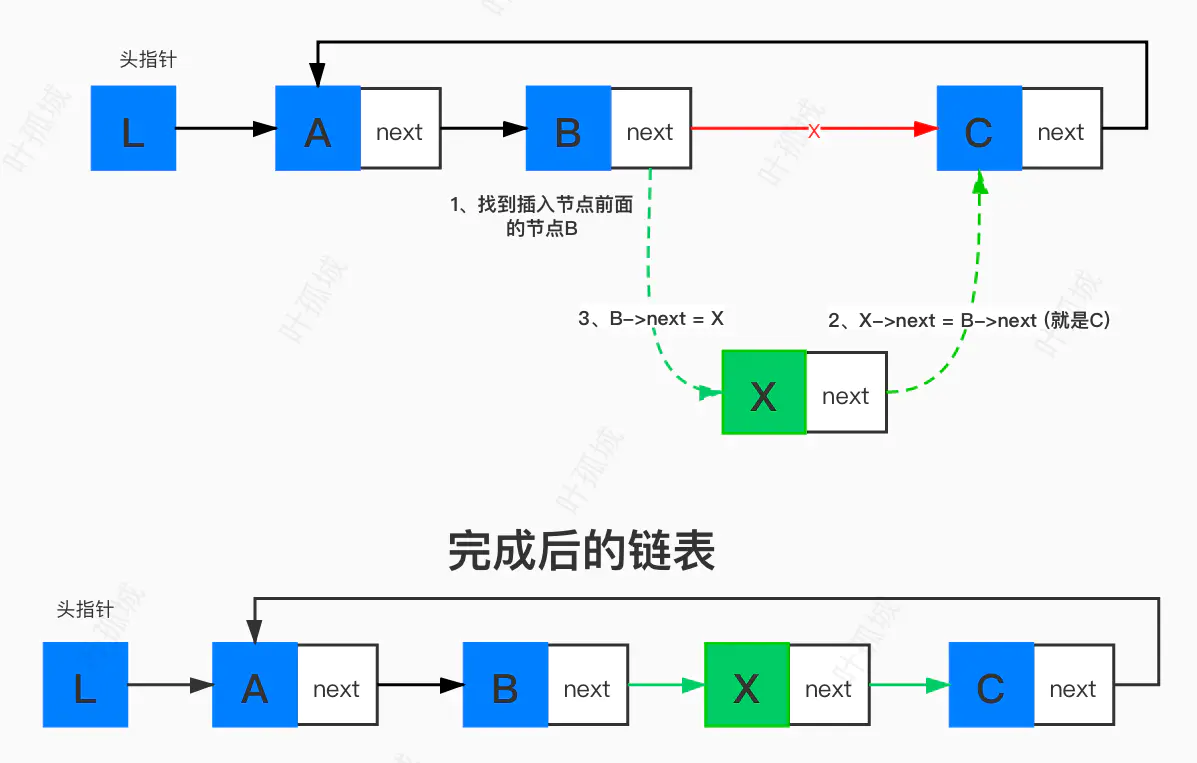
/// 插入数据 /// @param L 链表(链表的头指针) /// @param index 插入位置 1是首元节点 所以插入位置要从1开始 /// @param m 插入的节点数据 Status ListInsert(LinkList *L, int index, int m) { LinkList target = NULL; // 插入的节点的前一个节点 LinkList temp = NULL; // 新节点 if (index < 1) return ERROR; if (index == 1) { temp = (LinkList)malloc(sizeof(Node)); if (temp == NULL) return ERROR; temp->data = m; // 1、找到尾节点target for (target = *L; target->next != *L; target = target->next) ; // 2、新节点指向首节点 temp->next = *L; // 3、尾节点指向新节点 target->next = temp; // 4、头指针指向新首元节点 *L = temp; } else { int i; // 辅助确定插入位置 temp = (LinkList)malloc(sizeof(Node)); if (temp == NULL) return ERROR; temp->data = m; // 1、找到插入位置的前一个节点target for (i = 1, target = *L; target->next != *L && i != index-1; i++,target = target->next) ; // 2、新节点 指向 target的后节点 temp->next = target->next; // 3、target 指向 新节点 target->next = temp; } return OK; }
5:删除
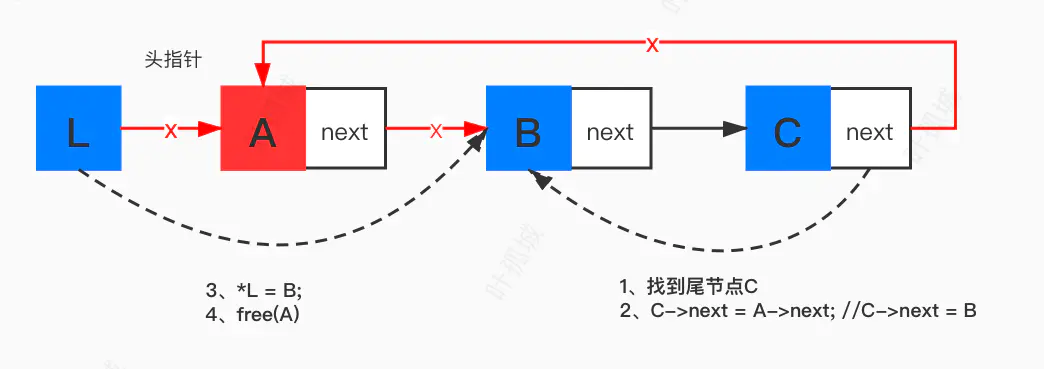
删除首元节点
删除其他任意节点
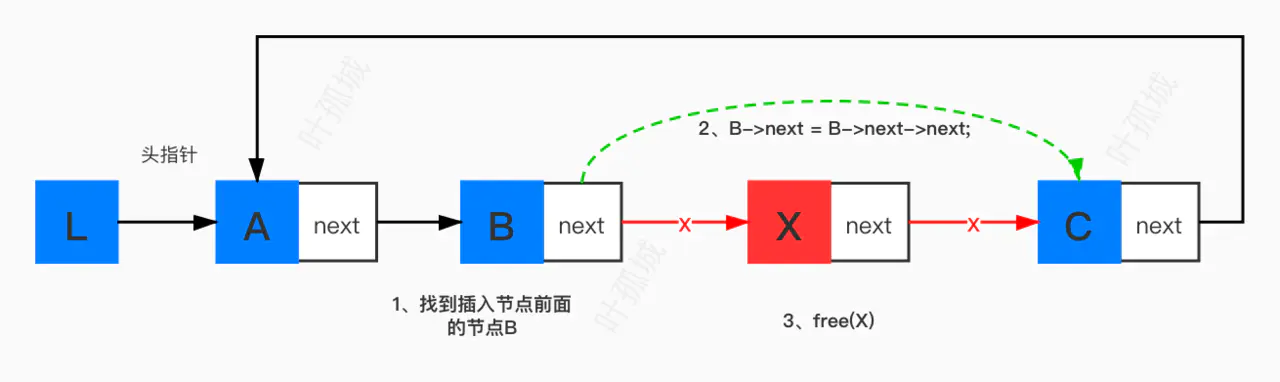
/// 删除指定位置的节点 /// @param L 链表 /// @param index 位置 Status ListDelete(LinkList *L, int index) { if (*L == NULL) return ERROR; // 只剩一个节点 if ((*L)->next == *L) { free((*L)) (*L) = NULL; return ERROR; } LinkList target , temp; if (index == 1) { // 删除首元节点 // 1、找到尾节点target for (target = *L; target->next != *L; target = target->next); temp = *L; // temp要删除的节点 // 2、尾节点指向删除节点后的节点 target->next = (*L)->next; // 3、首指针指向尾节点后的节点 *L = target->next; // 4、释放 free(temp); } else { // 删除其他任意节点 int i; // 1、找到尾节点target 和 要删除的temp for (i=1, target = *L; target->next != *L && i < index-1; target = target->next, i++); temp = target->next; // 2、target指向temp的后一个节点 target->next = temp->next; // 3、释放 free(temp); } return OK; }

6:查询
下面的实现代码,本质还是遍历
根据位置查询值
ElemType FindValue(LinkList L, int index) { int i; // 辅助确定插入位置 LinkList target; // 1、找到插入位置的前一个节点target for (i = 1, target = L; target->next != L && i != index-1; i++,target = target->next) ; return target->next->data; }
根据值查询位置(前提条件:每个节点的存储的值没有重复)
int FindIndex(LinkList L, ElemType v) { int i = 1; LinkList temp = L; for (; temp->next!=L && temp->data != v; temp = temp->next,i++) ; if (temp->next == L && temp->data != v) return -1; return i; }

注意
1、为什么插入、删除都要注意是不是首元节点?
需要变更头指针指向新的首元节点
2、博客外的问题:创建链表时,是不是双指针?具体什么含义?
struct Node *LinkList; // 存储节点实体在内存中的地址,所以指针->实体节点 LinkList L; CreateList(&L); // 传指针L的地址 : 指针的指针 . . . Void CreateList(LinkList *pL) { // pL 已经不是上面的L *pL 才是上面的L // 所以到这里, pL 就是指向L的指针 L指向实体节点 // malloc 函数返回的开辟的内存空间的地址,所以要用指针接收 *pL = (LinkList)malloc(sizeof(Node)); // *pL 里存的就是节点的内存地址 // 所以pL里存的是节点的内存地址的地址 }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号