027*:内存管理 retainCount(TaggedPointer、retain、release、dealloc)(strong & weak )__main_block_impl_0(id类型-__block-->> __Block_byref_a_0-->>forwarding指针指向copy后的地址)SideTables 、extra_rc(引用计数)
问题
retainCount
(TaggedPointer、retain、release、dealloc)
(strong & weak )
__main_block_impl_0(id类型-__block-->> __Block_byref_a_0-->>forwarding指针指向copy后的地址)
SideTables 、extra_rc(引用计数)(alloc、retain、release、dealloc)
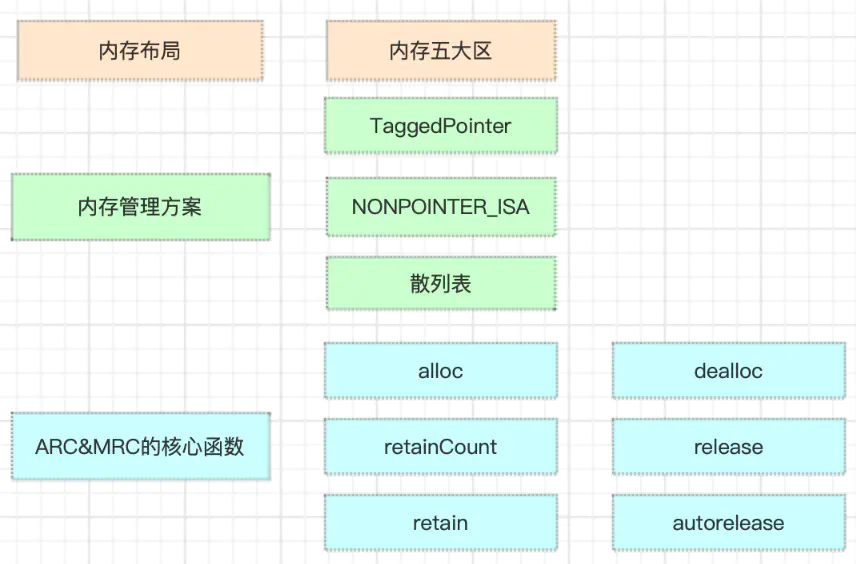
目录
1: 内存布局
2:内存管理方案
预备
正文
一、内存布局
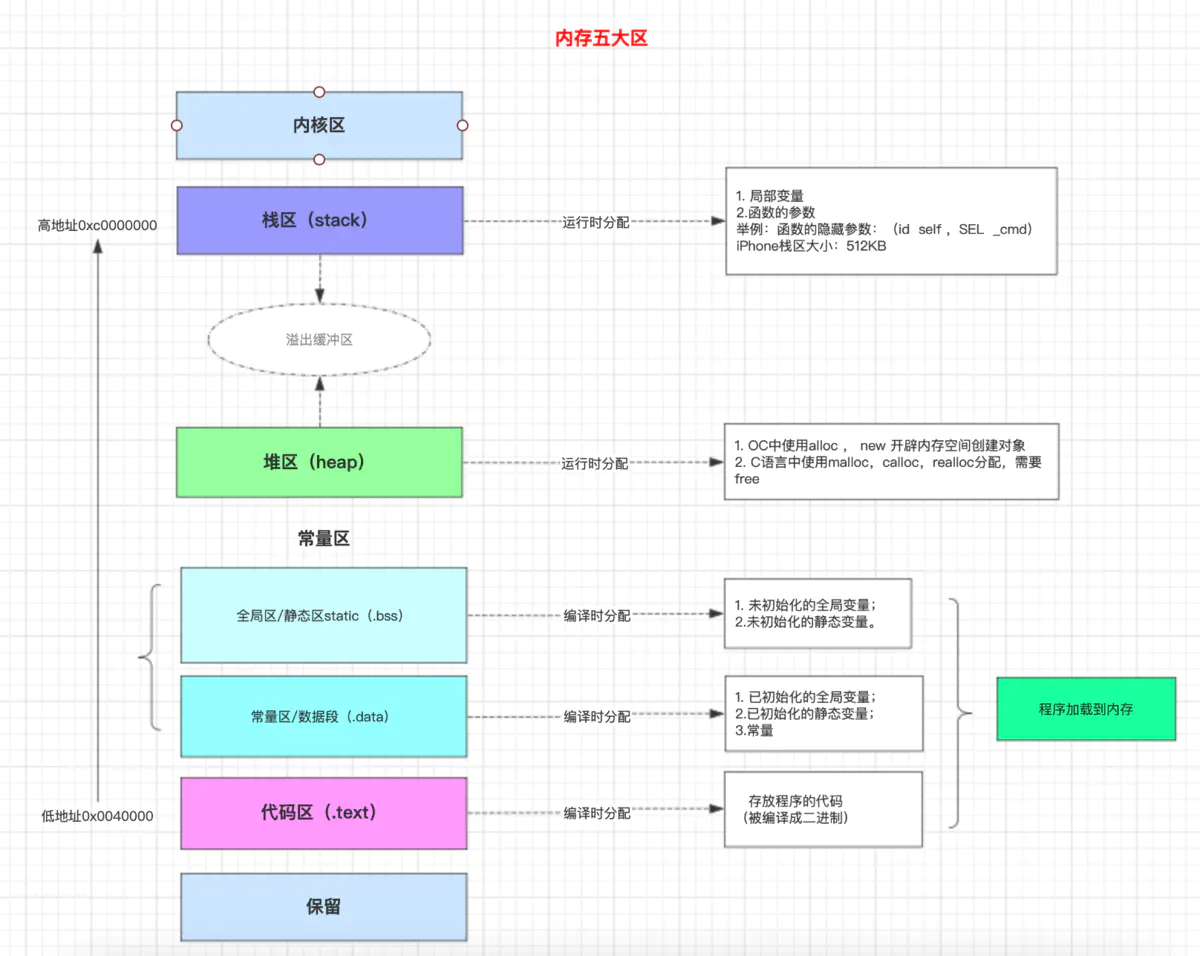
补充说明:
内存五大区,实际是指虚拟内存,而不是真实物理内存。iOS系统中,应用的虚拟内存默认分配4G大小,但五大区只占3G,还有1G是五大区之外的内核区
内存布局相关面试题
面试题1:全局变量和局部变量在内存中是否有区别?如果有,是什么区别?
-
有区别
-
全局变量保存在内存的全局存储区(即bss+data段),占用静态的存储单元 -
局部变量保存在栈中,只有在所在函数被调用时才动态的为变量分配存储单元
面试题2:Block中可以修改全局变量,全局静态变量,局部静态变量,局部变量吗?
-
可以修改
全局变量,全局静态变量,因为全局变量 和 静态全局变量是全局的,作用域很广 -
可以修改局部静态变量,不可以修改局部斌量
-
局部静态变量(static修饰的) 和 局部变量,被block从外面捕获,成为__main_block_impl_0这个结构体的成员变量 -
局部变量是以值方式传递到block的构造函数中的,只会捕获block中会用到的变量,由于只捕获了变量的值,并非内存地址,所以在block内部不能改变局部变量的值 -
局部静态变量是以指针形式,被block捕获的,由于捕获的是指针,所以可以修改局部静态变量的值
-
-
ARC环境下,一旦使用
__block修饰并在block中修改,就会触发copy,block就会从栈区copy到堆区,此时的block是堆区block -
ARC模式下,Block中引用
id类型的数据,无论有没有__block修饰,都会retain, -
对于
基础数据类型,没有__block就无法修改变量值; -
如果
有__block修饰,也是在底层修改__Block_byref_a_0结构体,将其内部的forwarding指针指向copy后的地址,来达到值的修改
二:内存管理方案
1:ARC和MRC
- 在早期的苹果系统里面是需要我们手动管理内存的,手动内存管理遵循谁创建,谁释放,谁引用,谁管理的原则
- IOS5之后苹果引入了ARC(自动引用计数),ARC是一种编译器特性,只是编译器在对应的时间给我们插入了内存管理的代码,其本质还是按照MRC的规则
2:内存管理方案除了前文提及的MRC和ARC,还有以下三种
-
Tagged Pointer:专门用来处理小对象,例如NSNumber、NSDate、小NSString等 -
Nonpointer_isa:非指针类型的isa,主要是用来优化64位地址。 -
SideTables:散列表,在散列表中主要有两个表,分别是引用计数表、弱引用表
3: TaggedPointer
TaggedPointer是标记指针。标记的是小对象,可以记录小内容的NSString、NSDate、NSNumber等内容。是内存管理(节省内存开销)的一种有效手段。
例如:使用
NSNumber记录10
【常规操作】
去堆中开辟一个内存,用于存储这个对象,在对象内部记录这个内容10,然后需要一个指针,指向堆中的内存首地址。
(内存开销:指针8字节+堆中对象的空间大小)【
TaggedPointer小对象】
记录一个10,根本不用去堆中开辟内存,直接利用指针拥有的8字节空间即可。
(类似NonPointer_isa非指针型isa,使用union联合体位域,中间shiftcls部分存储类信息。其他部位记录其他有效信息。)
(内存开销:指针8字节)结论:
占用空间较小的对象,直接使用指针内部空间,节约内存开销
3.1案例分析
@interface ViewController () @property (nonatomic, strong) dispatch_queue_t queue; @property (nonatomic, copy) NSString * name; @end @implementation ViewController - (void)viewDidLoad { [super viewDidLoad]; self.queue = dispatch_queue_create("ht", DISPATCH_QUEUE_CONCURRENT); for (int i = 0; i < 10000 ; i++) { dispatch_async(self.queue, ^{ self.name = [NSString stringWithFormat:@"ht"]; NSLog(@"%@ %p %s",self.name, self.name, object_getClassName(self.name)); }); } } - (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event { NSLog(@"来了"); for (int i = 0; i < 10000; i++) { dispatch_async(self.queue, ^{ self.name = [NSString stringWithFormat:@"ht_学习不行,回家种田"]; //setter - 新值retain,旧值release NSLog(@"%@ %p %s",self.name, self.name, object_getClassName(self.name)); // getter }); } } @end
上面打印结果:

点击触发TouchBegin后的打印结果
两次10000次的循环,都是对name进行赋值,为什么上面不会崩溃,下面会崩溃?
A: 因为上面name存储在栈中,不需要手动释放,而下面name存储在堆中,在setter赋值时会触发retain和release,异步线程中,可能导致指针过度释放,造成了崩溃。
-
name赋值为ht时,是小对象(NSTaggedPointerString),直接将内容存储在指针内部,指针存储在栈中,由系统负责管理。不参与 -
name赋值为ht_学习不行,回家种田时,由于内容过多,指针内部空间不够存储,所以去堆中开辟空间,需要管理引用计数了。每次setter都会触发新值retain和旧值release。异步线程中,可能导致retain未完成,但提前release了,导致指针过度释放,造成了崩溃。
name的setter方法实际是调用,打开objc4源码,搜索objc_setProperty:
- 可以看到
taggedPointer对象不参与引用计数的计算。
混淆验证
// 声明(在其他库中实现) extern uintptr_t objc_debug_taggedpointer_obfuscator; // 从objc4源码拷贝解码代码, 入参改为id类型 static inline uintptr_t _objc_decodeTaggedPointer(id ptr) { return (uintptr_t)ptr ^ objc_debug_taggedpointer_obfuscator; } - (void)demo { NSString * str1 = [NSString stringWithFormat:@"a"]; NSNumber * num1 = @(1); NSLog(@"str1: %p-%@", str1, str1); NSLog(@"num1: %p-%@", num1, num1); NSLog(@"str1 解码地址: 0x%lx", _objc_decodeTaggedPointer(str1)); NSLog(@"num1 解码地址: 0x%lx", _objc_decodeTaggedPointer(num1)); }
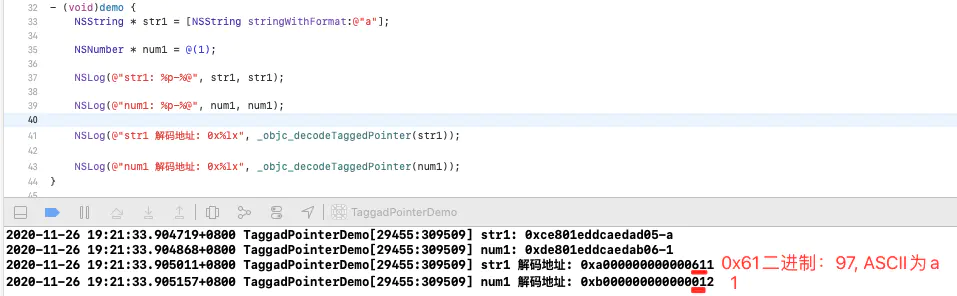
- 可以看到
解码后,从地址就可以直接读出当前内容。所以混淆机制就是为了让小对象从地址上降低识别度
taggedpointer类型的优点:
1:节省内存开销:充分利用指针地址空间。
2:执行效率高: 不需要retain和release,系统直接管理释放、回收,少执行很多代码,不需要堆空间,直接创建和读取。(官方说内存读取快3倍,创建快106倍)
Tagged Pointer 总结
-
Tagged Pointer小对象类型(用于存储NSNumber、NSDate、小NSString),小对象指针不再是简单的地址,而是地址 + 值,即真正的值,所以,实际上它不再是一个对象了,它只是一个披着对象皮的普通变量而以。所以可以直接进行读取。优点是占用空间小 节省内存 -
Tagged Pointer小对象不会进入retain 和 release,而是直接返回了,意味着不需要ARC进行管理,所以可以直接被系统自主的释放和回收 -
Tagged Pointer的内存并不存储在堆中,而是在常量区中,也不需要malloc和free,所以可以直接读取,相比存储在堆区的数据读取,效率上快了3倍左右。创建的效率相比堆区快了近100倍左右 -
所以,综合来说,
taggedPointer的内存管理方案,比常规的内存管理,要快很多 -
Tagged Pointer的64位地址中,前4位代表类型,后4位主要适用于系统做一些处理,中间56位用于存储值 -
优化内存建议:对于
NSString来说,当字符串较小时,建议直接通过@""初始化,因为存储在常量区,可以直接进行读取。会比WithFormat初始化方式更加快速
我们可以通过NSString初始化的两种方式,来测试NSString的内存管理
-
通过
WithString + @""方式初始化 -
通过
WithFormat方式初始化
#define KLog(_c) NSLog(@"%@ -- %p -- %@",_c,_c,[_c class]); - (void)testNSString{ //初始化方式一:通过 WithString + @""方式 NSString *s1 = @"1"; NSString *s2 = [[NSString alloc] initWithString:@"222"]; NSString *s3 = [NSString stringWithString:@"33"]; KLog(s1); KLog(s2); KLog(s3); //初始化方式二:通过 WithFormat //字符串长度在9以内 NSString *s4 = [NSString stringWithFormat:@"123456789"]; NSString *s5 = [[NSString alloc] initWithFormat:@"123456789"]; //字符串长度大于9 NSString *s6 = [NSString stringWithFormat:@"1234567890"]; NSString *s7 = [[NSString alloc] initWithFormat:@"1234567890"]; KLog(s4); KLog(s5); KLog(s6); KLog(s7); }
以下是运行的结果

所以,从上面可以总结出,NSString的内存管理主要分为3种
-
__NSCFConstantString:字符串常量,是一种编译时常量,retainCount值很大,对其操作,不会引起引用计数变化,存储在字符串常量区 -
__NSCFString:是在运行时创建的NSString子类,创建后引用计数会加1,存储在堆上 -
NSTaggedPointerString:标签指针,是苹果在64位环境下对NSString、NSNumber等对象做的优化。对于NSString对象来说-
当
字符串是由数字、英文字母组合且长度小于等于9时,会自动成为NSTaggedPointerString类型,存储在常量区 -
当有
中文或者其他特殊符号时,会直接成为__NSCFString类型,存储在堆区
-
字符串长度的类型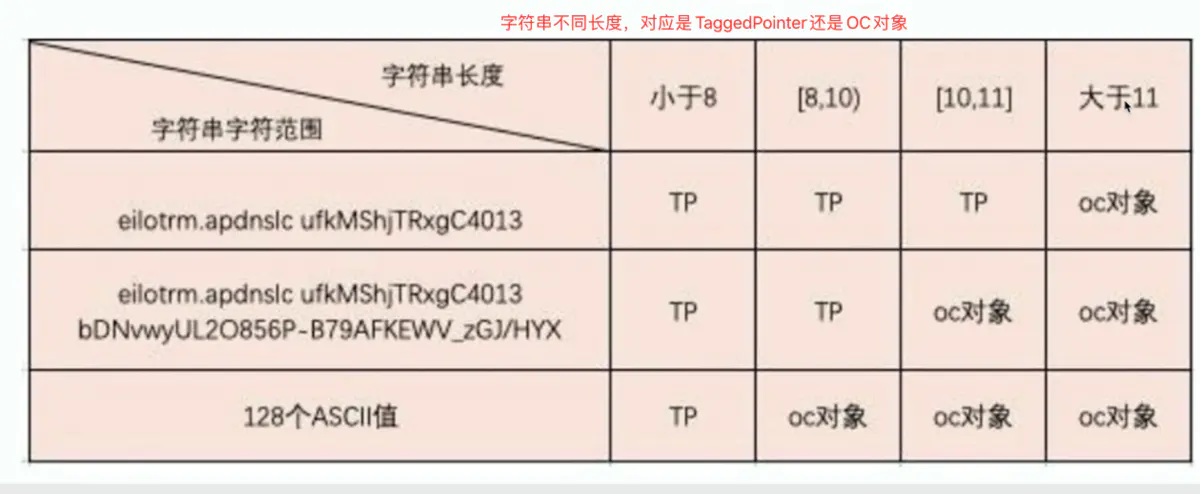
4:NONPOINTER_ISA
# define ISA_MASK 0x0000000ffffffff8ULL # define ISA_MAGIC_MASK 0x000003f000000001ULL # define ISA_MAGIC_VALUE 0x000001a000000001ULL # define ISA_BITFIELD \ uintptr_t nonpointer : 1; \ uintptr_t has_assoc : 1; \ uintptr_t has_cxx_dtor : 1; \ uintptr_t shiftcls : 33; /*MACH_VM_MAX_ADDRESS 0x1000000000*/ \ uintptr_t magic : 6; \ uintptr_t weakly_referenced : 1; \ uintptr_t deallocating : 1; \ uintptr_t has_sidetable_rc : 1; \ uintptr_t extra_rc : 19 # define RC_ONE (1ULL<<45) # define RC_HALF (1ULL<<18)
nonpointer:表示是否对 isa 指针开启指针优化
0:纯isa指针,1:不⽌是类对象地址,isa 中包含了类信息、对象的引⽤计数等has_assoc:关联对象标志位,0没有,1存在has_cxx_dtor:该对象是否有 C++ 或者 Objc 的析构器,如果有析构函数,则需要做析构逻辑, 如果没有,则可以更快的释放对象shiftcls: 存储类指针的值。开启指针优化的情况下,在 arm64 架构中有 33 位⽤来存储类指针。- magic:⽤于调试器判断当前对象是真的对象还是没有初始化的空间
weakly_referenced:此对象是否被指向或者曾经指向⼀个 ARC 的弱变量,没有弱引⽤的对象可以更快释放。deallocating:标志对象是否正在释放内存has_sidetable_rc:当对象引⽤技术⼤于 10 时,则需要借⽤该变量存储进位extra_rc:当表示该对象的引⽤计数值,实际上是引⽤计数值减 1,
例如,如果对象的引⽤计数为 10,那么 extra_rc 为 9。如果引⽤计数⼤于 10,则需要使⽤到下⾯的 has_sidetable_rc。`
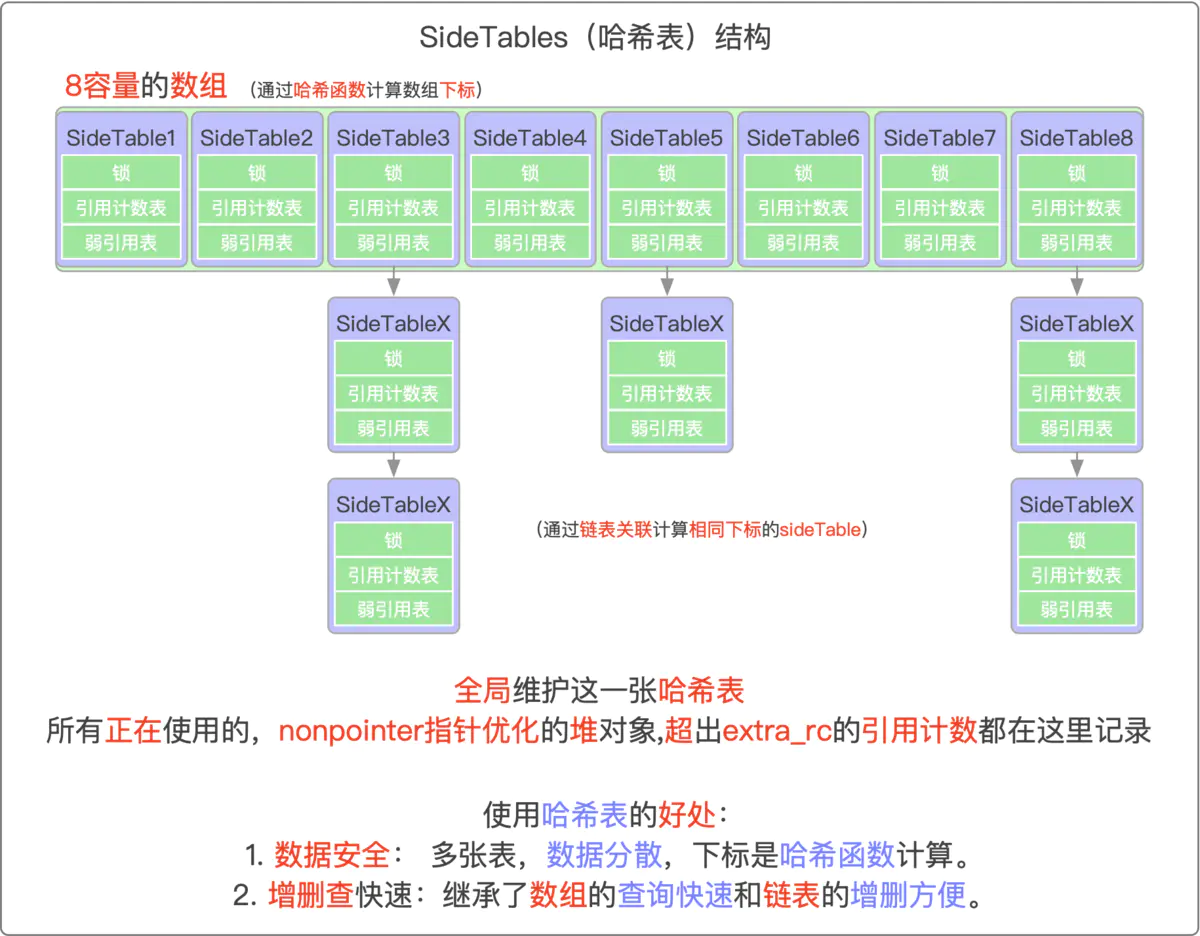
struct SideTable { spinlock_t slock;//开解锁 RefcountMap refcnts;//引用技术表 weak_table_t weak_table;//弱引用表 };
数组:特点在于查询方便(即通过下标访问),增删比较麻烦(类似于之前讲过的 methodList,通过memcopy、memmove增删,非常麻烦),所以数据的特性是读取快,存储不方便
链表:特点在于增删方便,查询慢(需要从头节点开始遍历查询),所以链表的特性是存储快,读取慢
散列表的本质就是一张哈希表,哈希表集合了数组和链表的长处,增删改查都比较方便.
散列表在内存中有8张。
如果只有一张,所有的对象都在一个表中,每次开锁,所有的都会暴露出来。若果每个对象都开一个表就会过度消耗性能。
6:retain 源码分析
进入objc_retain -> retain -> rootRetain源码实现,主要有以下几部分逻辑
ALWAYS_INLINE id objc_object::rootRetain(bool tryRetain, bool handleOverflow) { if (isTaggedPointer()) return (id)this; bool sideTableLocked = false; bool transcribeToSideTable = false; //为什么有isa?因为需要对引用计数+1,即retain+1,而引用计数存储在isa的bits中,需要进行新旧isa的替换 isa_t oldisa; isa_t newisa; //重点 do { transcribeToSideTable = false; oldisa = LoadExclusive(&isa.bits); newisa = oldisa; //判断是否为nonpointer isa if (slowpath(!newisa.nonpointer)) { //如果不是 nonpointer isa,直接操作散列表sidetable ClearExclusive(&isa.bits); if (rawISA()->isMetaClass()) return (id)this; if (!tryRetain && sideTableLocked) sidetable_unlock(); if (tryRetain) return sidetable_tryRetain() ? (id)this : nil; else return sidetable_retain(); } // don't check newisa.fast_rr; we already called any RR overrides //dealloc源码 if (slowpath(tryRetain && newisa.deallocating)) { ClearExclusive(&isa.bits); if (!tryRetain && sideTableLocked) sidetable_unlock(); return nil; } uintptr_t carry; //执行引用计数+1操作,即对bits中的 1ULL<<45(arm64) 即extra_rc,用于该对象存储引用计数值 newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry); // extra_rc++ //判断extra_rc是否满了,carry是标识符 if (slowpath(carry)) { // newisa.extra_rc++ overflowed if (!handleOverflow) { ClearExclusive(&isa.bits); return rootRetain_overflow(tryRetain); } // Leave half of the retain counts inline and // prepare to copy the other half to the side table. if (!tryRetain && !sideTableLocked) sidetable_lock(); sideTableLocked = true; transcribeToSideTable = true; //如果extra_rc满了,则直接将满状态的一半拿出来存到extra_rc newisa.extra_rc = RC_HALF; //给一个标识符为YES,表示需要存储到散列表 newisa.has_sidetable_rc = true; } } while (slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits))); if (slowpath(transcribeToSideTable)) { // Copy the other half of the retain counts to the side table. //将另一半存在散列表的rc_half中,即满状态下是8位,一半就是1左移7位,即除以2 //这么操作的目的在于提高性能,因为如果都存在散列表中,当需要release-1时,需要去访问散列表,每次都需要开解锁,比较消耗性能。extra_rc存储一半的话,可以直接操作extra_rc即可,不需要操作散列表。性能会提高很多 sidetable_addExtraRC_nolock(RC_HALF); } if (slowpath(!tryRetain && sideTableLocked)) sidetable_unlock(); return (id)this; }
-
【第一步】判断是否为
Nonpointer_isa -
【第二步】操作引用计数
-
1、如果不是
Nonpointer_isa,则直接操作SideTables散列表,此时的散列表并不是只有一张,而是有很多张(后续会分析,为什么需要多张) -
2、判断
是否正在释放,如果正在释放,则执行dealloc流程 -
3、执行
extra_rc+1,即引用计数+1操作,并给一个引用计数的状态标识carry,用于表示extra_rc是否满了 -
4、如果
carray的状态表示extra_rc的引用计数满了,此时需要操作散列表,即 将满状态的一半拿出来存到extra_rc,另一半存在 散列表的rc_half。这么做的原因是因为如果都存储在散列表,每次对散列表操作都需要开解锁,操作耗时,消耗性能大,这么对半分操作的目的在于提高性能
-
问题1:散列表为什么在内存有多张?最多能够多少张?
-
如果散列表只有一张表,意味着全局所有的对象都会存储在一张表中,都会进行开锁解锁(锁是锁整个表的读写)。当开锁时,由于所有数据都在一张表,则意味着数据不安全 -
如果
每个对象都开一个表,会耗费性能,所以也不能有无数个表
StripedMap的定义,从这里可以看出,同一时间,真机中散列表最多只能有8张问题2:为什么在用散列表,而不用数组、链表?
-
数组:特点在于查询方便(即通过下标访问),增删比较麻烦(类似于之前讲过的methodList,通过memcopy、memmove增删,非常麻烦),所以数据的特性是读取快,存储不方便 -
链表:特点在于增删方便,查询慢(需要从头节点开始遍历查询),所以链表的特性是存储快,读取慢 -
散列表的本质就是一张哈希表,哈希表集合了数组和链表的长处,增删改查都比较方便,例如拉链哈希表(在之前锁的文章中,讲过的tls的存储结构就是拉链形式的),是最常用的,如下所示
retain的底层流程如下所示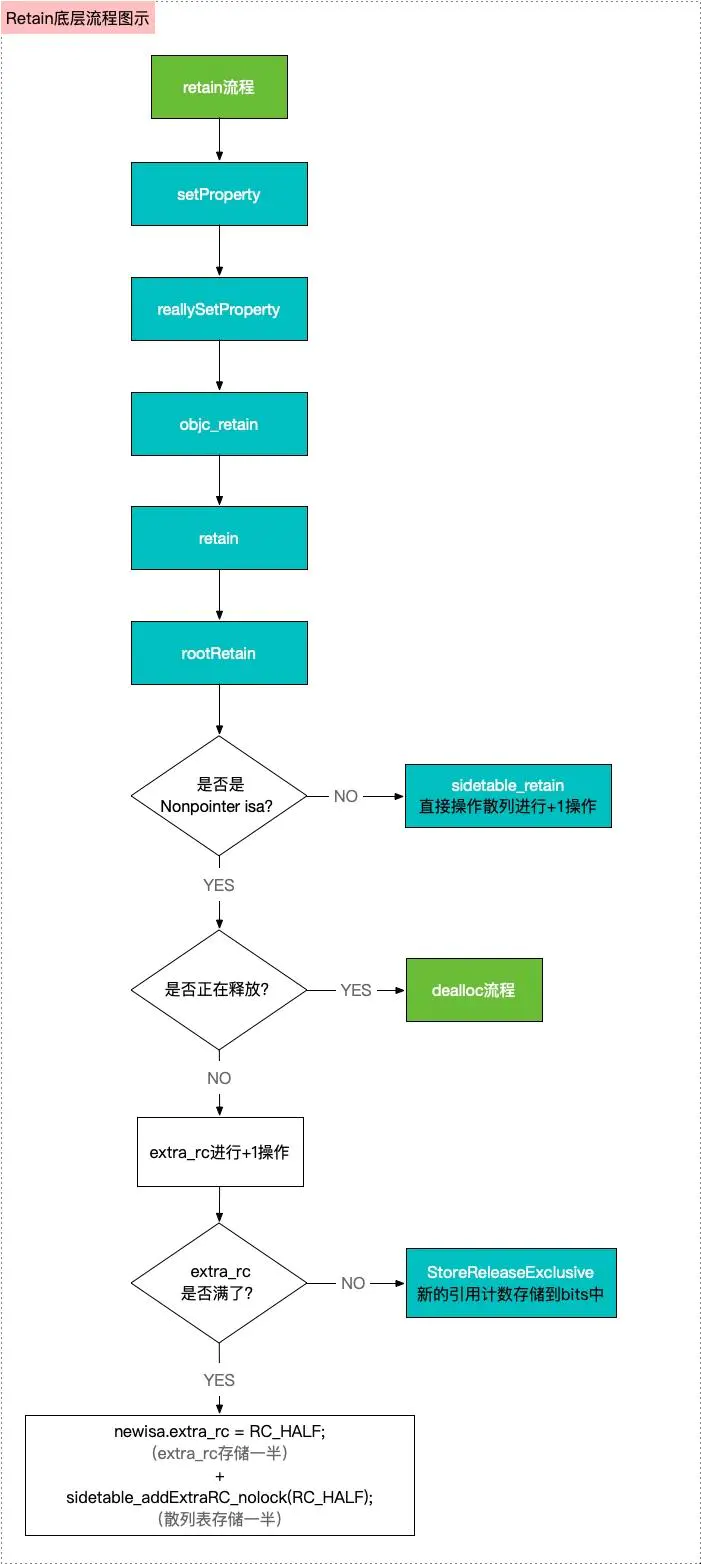
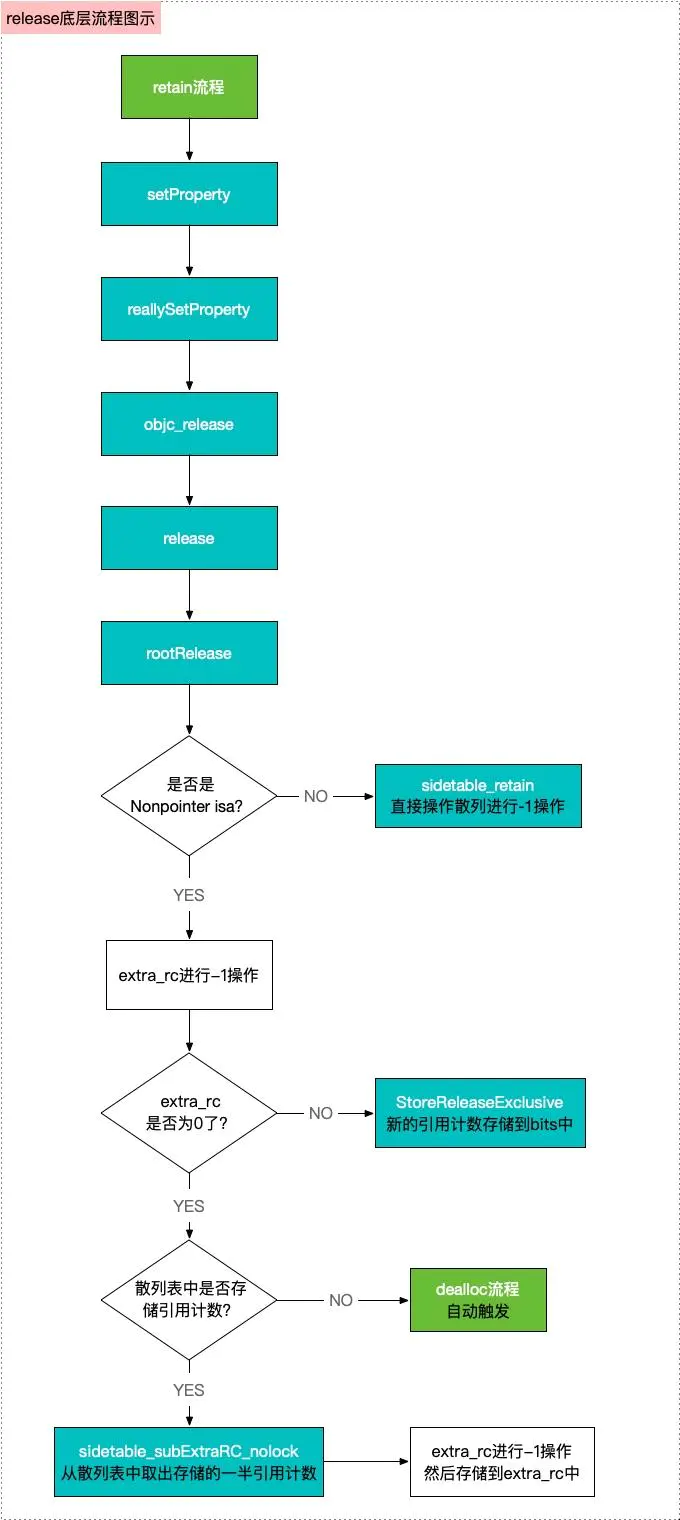
release 源码分析
分析了retain的底层实现,下面来分析release的底层实现
- 通过
setProperty -> reallySetProperty -> objc_release -> release -> rootRelease -> rootRelease顺序,进入rootRelease源码,其操作与retain 相反-
判断是否是
Nonpointer isa,如果不是,则直接对散列表进行-1操作 -
如果是
Nonpointer isa,则对extra_rc中的引用计数值进行-1操作,并存储此时的extra_rc状态到carry中 -
如果此时的状态
carray为0,则走到underflow流程 -
underflow流程有以下几步:-
判断
散列表中是否存储了一半的引用计数 -
如果是,则从
散列表中取出存储的一半引用计数,进行-1操作,然后存储到extra_rc中 -
如果此时
extra_rc没有值,散列表中也是空的,则直接进行析构,即dealloc操作,属于自动触发
-
-
ALWAYS_INLINE bool objc_object::rootRelease(bool performDealloc, bool handleUnderflow) { if (isTaggedPointer()) return false; bool sideTableLocked = false; isa_t oldisa; isa_t newisa; retry: do { oldisa = LoadExclusive(&isa.bits); newisa = oldisa; //判断是否是Nonpointer isa if (slowpath(!newisa.nonpointer)) { //如果不是,则直接操作散列表-1 ClearExclusive(&isa.bits); if (rawISA()->isMetaClass()) return false; if (sideTableLocked) sidetable_unlock(); return sidetable_release(performDealloc); } // don't check newisa.fast_rr; we already called any RR overrides uintptr_t carry; //进行引用计数-1操作,即extra_rc-1 newisa.bits = subc(newisa.bits, RC_ONE, 0, &carry); // extra_rc-- //如果此时extra_rc的值为0了,则走到underflow if (slowpath(carry)) { // don't ClearExclusive() goto underflow; } } while (slowpath(!StoreReleaseExclusive(&isa.bits, oldisa.bits, newisa.bits))); if (slowpath(sideTableLocked)) sidetable_unlock(); return false; underflow: // newisa.extra_rc-- underflowed: borrow from side table or deallocate // abandon newisa to undo the decrement newisa = oldisa; //判断散列表中是否存储了一半的引用计数 if (slowpath(newisa.has_sidetable_rc)) { if (!handleUnderflow) { ClearExclusive(&isa.bits); return rootRelease_underflow(performDealloc); } // Transfer retain count from side table to inline storage. if (!sideTableLocked) { ClearExclusive(&isa.bits); sidetable_lock(); sideTableLocked = true; // Need to start over to avoid a race against // the nonpointer -> raw pointer transition. goto retry; } // Try to remove some retain counts from the side table. //从散列表中取出存储的一半引用计数 size_t borrowed = sidetable_subExtraRC_nolock(RC_HALF); // To avoid races, has_sidetable_rc must remain set // even if the side table count is now zero. if (borrowed > 0) { // Side table retain count decreased. // Try to add them to the inline count. //进行-1操作,然后存储到extra_rc中 newisa.extra_rc = borrowed - 1; // redo the original decrement too bool stored = StoreReleaseExclusive(&isa.bits, oldisa.bits, newisa.bits); if (!stored) { // Inline update failed. // Try it again right now. This prevents livelock on LL/SC // architectures where the side table access itself may have // dropped the reservation. isa_t oldisa2 = LoadExclusive(&isa.bits); isa_t newisa2 = oldisa2; if (newisa2.nonpointer) { uintptr_t overflow; newisa2.bits = addc(newisa2.bits, RC_ONE * (borrowed-1), 0, &overflow); if (!overflow) { stored = StoreReleaseExclusive(&isa.bits, oldisa2.bits, newisa2.bits); } } } if (!stored) { // Inline update failed. // Put the retains back in the side table. sidetable_addExtraRC_nolock(borrowed); goto retry; } // Decrement successful after borrowing from side table. // This decrement cannot be the deallocating decrement - the side // table lock and has_sidetable_rc bit ensure that if everyone // else tried to -release while we worked, the last one would block. sidetable_unlock(); return false; } else { // Side table is empty after all. Fall-through to the dealloc path. } } //此时extra_rc中值为0,散列表中也是空的,则直接进行析构,即自动触发dealloc流程 // Really deallocate. //触发dealloc的时机 if (slowpath(newisa.deallocating)) { ClearExclusive(&isa.bits); if (sideTableLocked) sidetable_unlock(); return overrelease_error(); // does not actually return } newisa.deallocating = true; if (!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)) goto retry; if (slowpath(sideTableLocked)) sidetable_unlock(); __c11_atomic_thread_fence(__ATOMIC_ACQUIRE); if (performDealloc) { //发送一个dealloc消息 ((void(*)(objc_object *, SEL))objc_msgSend)(this, @selector(dealloc)); } return true; }
所以,综上所述,release的底层流程如下图所示
dealloc 源码分析
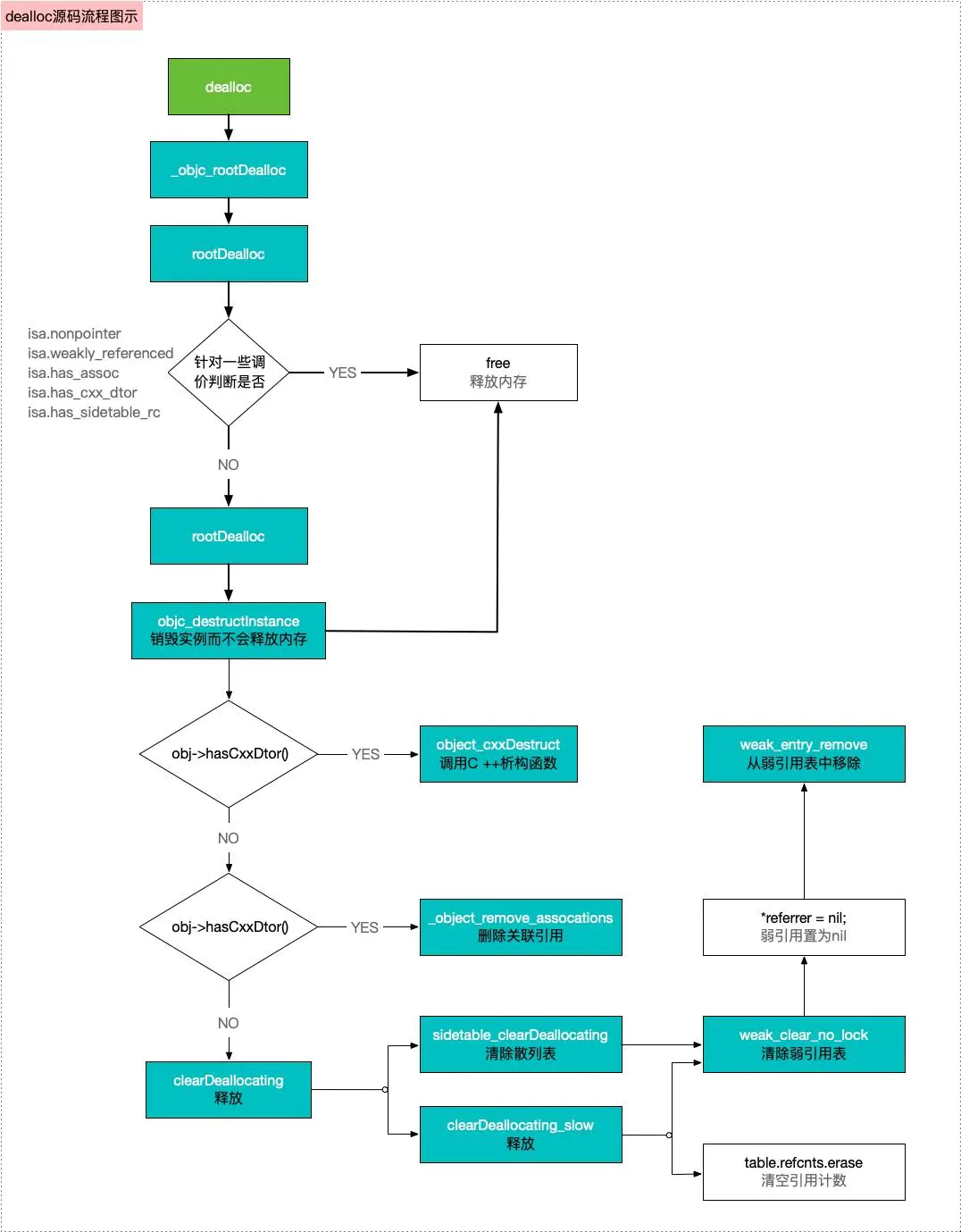
在retain和release的底层实现中,都提及了dealloc析构函数,下面来分析dealloc的底层的实现
- 进入
dealloc -> _objc_rootDealloc -> rootDealloc源码实现,主要有两件事:- 根据条件
判断是否有isa、cxx、关联对象、弱引用表、引用计数表,如果没有,则直接free释放内存 - 如果有,则进入
object_dispose方法
- 根据条件
inline void objc_object::rootDealloc() { //对象要释放,需要做哪些事情? //1、isa - cxx - 关联对象 - 弱引用表 - 引用计数表 //2、free if (isTaggedPointer()) return; // fixme necessary? //如果没有这些,则直接free if (fastpath(isa.nonpointer && !isa.weakly_referenced && !isa.has_assoc && !isa.has_cxx_dtor && !isa.has_sidetable_rc)) { assert(!sidetable_present()); free(this); } else { //如果有 object_dispose((id)this); } }
- 进入
object_dispose源码,其目的有以下几个- 销毁实例,主要有以下操作
-
调用c++析构函数
-
删除关联引用
-
释放散列表
-
清空弱引用表
-
- free释放内存
- 销毁实例,主要有以下操作
id object_dispose(id obj) { if (!obj) return nil; //销毁实例而不会释放内存 objc_destructInstance(obj); //释放内存 free(obj); return nil; } 👇 void *objc_destructInstance(id obj) { if (obj) { // Read all of the flags at once for performance. bool cxx = obj->hasCxxDtor(); bool assoc = obj->hasAssociatedObjects(); // This order is important. //调用C ++析构函数 if (cxx) object_cxxDestruct(obj); //删除关联引用 if (assoc) _object_remove_assocations(obj); //释放 obj->clearDeallocating(); } return obj; } 👇 inline void objc_object::clearDeallocating() { //判断是否为nonpointer isa if (slowpath(!isa.nonpointer)) { // Slow path for raw pointer isa. //如果不是,则直接释放散列表 sidetable_clearDeallocating(); } //如果是,清空弱引用表 + 散列表 else if (slowpath(isa.weakly_referenced || isa.has_sidetable_rc)) { // Slow path for non-pointer isa with weak refs and/or side table data. clearDeallocating_slow(); } assert(!sidetable_present()); } 👇 NEVER_INLINE void objc_object::clearDeallocating_slow() { ASSERT(isa.nonpointer && (isa.weakly_referenced || isa.has_sidetable_rc)); SideTable& table = SideTables()[this]; table.lock(); if (isa.weakly_referenced) { //清空弱引用表 weak_clear_no_lock(&table.weak_table, (id)this); } if (isa.has_sidetable_rc) { //清空引用计数 table.refcnts.erase(this); } table.unlock(); }
所以,综上所述,dealloc底层的流程图如图所示
alloc底层分析-> retain -> release -> dealloc就全部串联起来了综上所述,alloc创建的对象实际的引用计数为0,其引用计数打印结果为1,
是因为在底层rootRetainCount方法中,引用计数默认+1了,但是这里只有对引用计数的读取操作,是没有写入操作的,
简单来说就是:为了防止alloc创建的对象被释放(引用计数为0会被释放),所以在编译阶段,程序底层默认进行了+1操作。实际上在extra_rc中的引用计数仍然为0
总结
-
alloc创建的对象没有retain和release -
alloc创建对象的引用计数为0,会在编译时期,程序默认加1,所以读取引用计数时为1
注意
引用
1:iOS-底层原理 33:内存管理(一)TaggedPointer/retain/release/dealloc/retainCount 底层分析
3:OC底层原理三十五:内存管理(TaggedPointer、引用计数)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号