006:cache_t-(buckets[sel imp]、mask、flag、occupied)-【cache_insert(散列表,3/4两倍扩容)】
问题
1:缓存的流程
msg_send-->>cache_fill-->>cache_insert
-->>_occupied+1-->>
-->>reallocate-->>cache_collect_free-->>_garbage_make_room
-->>扩容-->>(散列表)存储sel和imp
目录
1:cache_t
2:cache_t 分析--结构分析
3:探究缓存机制
4:cache_t的原理图
5:主要问题
预备
1:cache_t 简单介绍
正文
1:cache_t
作为类结构体中的一个元素,作用缓存类的sel和imp.
使得类在调用方法时能快速的发送消息,减少类查找方法的时间.
到这片文章为止,类的结构以及分析完成.下篇文章开始分析类的方法执行,具体结构如下:

2:cache_t 分析--结构分析
1:cache中存储的是什么?
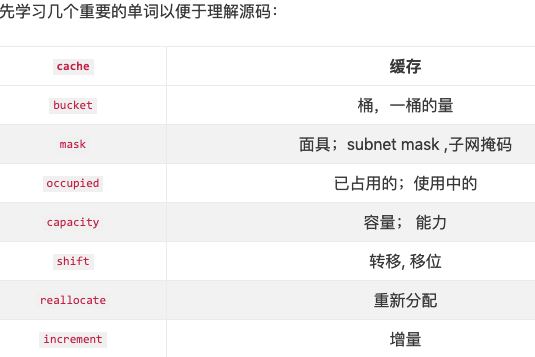
struct cache_t { #if CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_OUTLINED//macOS、模拟器 -- 主要是架构区分 // explicit_atomic 显示原子性,目的是为了能够 保证 增删改查时 线程的安全性 //等价于 struct bucket_t * _buckets; //_buckets 中放的是 sel imp //_buckets的读取 有提供相应名称的方法 buckets() explicit_atomic<struct bucket_t *> _buckets; explicit_atomic<mask_t> _mask; #elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_HIGH_16 //64位真机 explicit_atomic<uintptr_t> _maskAndBuckets;//写在一起的目的是为了优化 mask_t _mask_unused; //以下都是掩码,即面具 -- 类似于isa的掩码,即位域 // 掩码省略.... #elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_LOW_4 //非64位 真机 explicit_atomic<uintptr_t> _maskAndBuckets; mask_t _mask_unused; //以下都是掩码,即面具 -- 类似于isa的掩码,即位域 // 掩码省略.... #else #error Unknown cache mask storage type. #endif #if __LP64__ uint16_t _flags; #endif uint16_t _occupied; //方法省略..... }
1.2:优化cache_t代码
struct cache_t { explicit_atomic<struct bucket_t *> _buckets; explicit_atomic<mask_t> _mask; uint16_t _flags; uint16_t _occupied; };
1.3:cache_t的结构
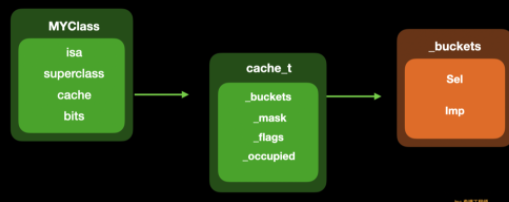
1.4:每个字段的作用
buckets: 存储bucket_t的数组。其中bucket_t是包含SEL和IMP的结构体
SEL应该是char*类型的字符串,char*强转unsigned long,其实就是SEL的内存地址。代码如下_imp就是方法实现IMP了。
struct bucket_t { private: // IMP-first is better for arm64e ptrauth and no worse for arm64. // SEL-first is better for armv7* and i386 and x86_64. #if __arm64__ explicit_atomic<uintptr_t> _imp; explicit_atomic<SEL> _sel; #else explicit_atomic<SEL> _sel; explicit_atomic<uintptr_t> _imp; #endif // 省略了部分方法。。。 }
_mask : 有2个作用,① 作为当前可存储的最大容量;② 作为掩码,取已缓存方法在 _buckets 中的下标。
_occupied _buckets 中 已缓存的方法数量
3:探究缓存机制
我们来探索cache的缓存机制,定义一个类
@interface HTPerson : NSObject @property (nonatomic, copy) NSString *name; @property (nonatomic, strong) NSString *nickName; - (void)sayHello; - (void)sayCode; - (void)sayMaster; - (void)sayNB; + (void)sayHappy; @end @implementation HTPerson - (void)sayHello{ NSLog(@"%s",__func__); } - (void)sayCode{ NSLog(@" %s",__func__); } - (void)sayDevelop{ NSLog(@"%s",__func__); } - (void)sayMaster{ NSLog(@"%s",__func__); } - (void)sayNB{ NSLog(@"%s",__func__); } + (void)sayHappy{ NSLog(@"%s",__func__); } @end int main(int argc, const char * argv[]) { @autoreleasepool { HTPerson *p = [HTPerson alloc]; Class pClass = [HTPerson class]; // 记录类,便于后面使用 //p.name = @"mark"; //p.nickName = @"哈哈"; [p sayHello]; [p sayCode]; //[p sayDevelop]; //[p sayMaster]; //[p sayNB]; NSLog(@"%@",pClass); } return 0; }
2.1:找到HTPerson的cache的内存地址:
在[p sayHello]一行加入断点,运行函数。
得到cache_t的地址:HTPerson类的首地址-->>向右偏移16个字节

cache属性的获取,需要通过pclass的首地址平移16字节,即首地址+0x10获取cache的地址
从源码的分析中,我们知道sel-imp是在cache_t的_buckets属性中(目前处于macOS环境),而在cache_t结构体中提供了获取_buckets属性的方法buckets()
获取了_buckets属性,就可以获取sel-imp了,这两个的获取在bucket_t结构体中同样提供了相应的获取方法sel()以及 imp(pClass)
由上图可知,在没有执行方法调用时,此时的cache是没有缓存的,执行了一次方法调用,cache中就有了一个缓存,即调用一次方法就会缓存一次方法。
2.2:我们只拿到数组地址,如何读取数组所有元素呢
方法一:既然拿到了数组首地址,而数组的元素类型都是一致的,我们可以通过内存偏移读取元素。

方法二:既然是数组,就可以直接使用数组下标进行读取。

3:cache原理分析
1:cache_t
struct cache_t { #if CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_OUTLINED//macOS、模拟器 -- 主要是架构区分 // explicit_atomic 显示原子性,目的是为了能够 保证 增删改查时 线程的安全性 //等价于 struct bucket_t * _buckets; //_buckets 中放的是 sel imp //_buckets的读取 有提供相应名称的方法 buckets() explicit_atomic<struct bucket_t *> _buckets; //最小的buckets大小是 4(为了支持扩容算法需要) explicit_atomic<mask_t> _mask; //散列表长度 - 1 #elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_HIGH_16 //64位真机 explicit_atomic<uintptr_t> _maskAndBuckets;//写在一起的目的是为了优化 mask_t _mask_unused; public: //对外公开可以调用的方法 static bucket_t *emptyBuckets(); // 清空buckets struct bucket_t *buckets(); //这个方法的实现很简单就是_buckets对外的一个获取函数 mask_t mask(); //获取缓存容量_mask mask_t occupied(); //获取已经占用的缓存个数_occupied void incrementOccupied(); //增加缓存,_occupied自++ void setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask); //这个函数是设置一个新的Buckets void initializeToEmpty(); unsigned capacity(); bool isConstantEmptyCache(); bool canBeFreed(); ...... }
2:void incrementOccupied(); 这个方法就开始激动了,打开源码:
void cache_t::incrementOccupied() { _occupied++; //已占用的 递增 }
3:看到这个方法: void cache_t::insert(Class cls, SEL sel, IMP imp, id receiver) 只有这个方法中调用void incrementOccupied(); 方法
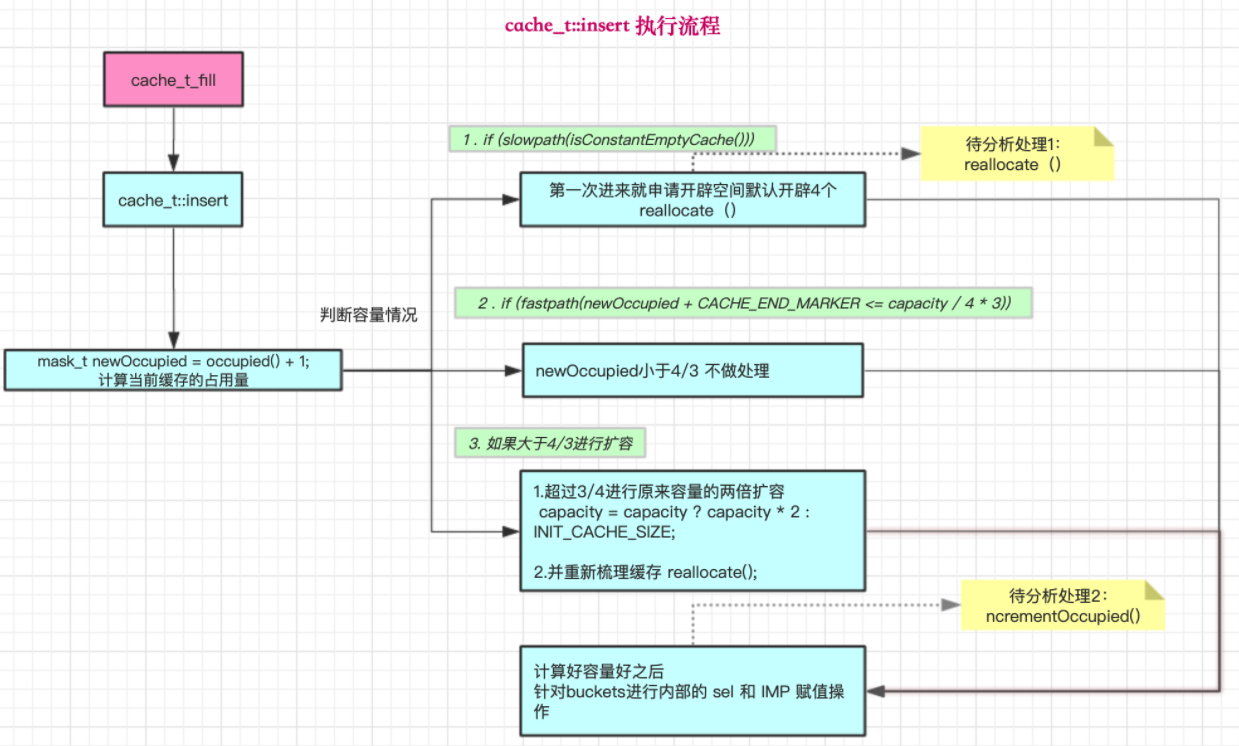
void cache_t::insert(Class cls, SEL sel, IMP imp, id receiver) { #if CONFIG_USE_CACHE_LOCK cacheUpdateLock.assertLocked(); #else runtimeLock.assertLocked(); #endif ASSERT(sel != 0 && cls->isInitialized()); // 原occupied计数+1 mask_t newOccupied = occupied() + 1; // 进入查看: return mask() ? mask()+1 : 0; // 就是当前mask有值就+1,否则设置初始值0 unsigned oldCapacity = capacity(), capacity = oldCapacity; // 当前缓存是否为空 if (slowpath(isConstantEmptyCache())) { // Cache is read-only. Replace it. // 如果为空,就给空间设置初始值4 // (进入INIT_CACHE_SIZE查看,可以发现就是1<<2,就是二进制100,十进制为4) if (!capacity) capacity = INIT_CACHE_SIZE; // 1:创建新空间(第三个入参为false,表示不需要释放旧空间) reallocate(oldCapacity, capacity, /* freeOld */false); } // CACHE_END_MARKER 就是 1 // 如果当前计数+1 < 空间的 3/4。 就不用处理 // 表示空间够用。 不需要空间扩容 else if (fastpath(newOccupied + CACHE_END_MARKER <= capacity / 4 * 3)) { // Cache is less than 3/4 full. Use it as-is. } // 如果计数大于3/4, 就需要进行扩容操作 else { // 如果空间存在,就2倍扩容。 如果不存在,就设为初始值4 capacity = capacity ? capacity * 2 : INIT_CACHE_SIZE; // 防止超出最大空间值(2^16 - 1) if (capacity > MAX_CACHE_SIZE) { capacity = MAX_CACHE_SIZE; } // 创建新空间(第三个入参为true,表示需要释放旧空间) reallocate(oldCapacity, capacity, true); } // 读取现在的buckets数组 bucket_t *b = buckets(); // 新的mask值(当前空间最大存储大小) mask_t m = capacity - 1; // 使用hash计算当前函数的位置(内部就是sel & m, 就是取余操作,保障begin值在m当前可用空间内) mask_t begin = cache_hash(sel, m); mask_t i = begin; do { // 如果当前位置为空(空间位置没被占用) if (fastpath(b[i].sel() == 0)) { // Occupied计数+1 incrementOccupied(); // 将sel和imp与cls关联起来并写入内存中 b[i].set<Atomic, Encoded>(sel, imp, cls); return; } // 如果当前位置有值(位置被占用) if (b[i].sel() == sel) { // The entry was added to the cache by some other thread // before we grabbed the cacheUpdateLock. // 直接返回 return; } // 如果位置有值,再次使用哈希算法找下一个空位置去写入 // 需要注意的是,cache_next内部有分支: // 如果是arm64真机环境: 从最大空间位置开始,依次-1往回找空位 // 如果是arm旧版真机、x86_64电脑、i386模拟器: 从当前位置开始,依次+1往后找空位。不能超过最大空间。 // 因为当前空间是没超出mask最大空间的,所以一定有空位置可以放置的。 } while (fastpath((i = cache_next(i, m)) != begin)); // 各种错误处理 cache_t::bad_cache(receiver, (SEL)sel, cls); }
4:cache_fill执行
cache->insert(cls, sel, imp, receiver);
void cache_fill(Class cls, SEL sel, IMP imp, id receiver) { runtimeLock.assertLocked(); // runtime锁 assert断言 #if !DEBUG_TASK_THREADS // Never cache before +initialize is done if (cls->isInitialized()) { cache_t *cache = getCache(cls); #if CONFIG_USE_CACHE_LOCK mutex_locker_t lock(cacheUpdateLock); #endif cache->insert(cls, sel, imp, receiver); } #else _collecting_in_critical(); #endif }
5:以上总共分为三步:
1计算当前bucket占用量;2根据bucket在buckets中的占用比,开辟空间3根据cache_hash方法,计算sel-imp存储的哈希下标,存入sel, imp, cls
6:reallocate()源码
ALWAYS_INLINE void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity, bool freeOld) { //取到老的缓存池 bucket_t *oldBuckets = buckets(); //建立新容量的缓存池 bucket_t *newBuckets = allocateBuckets(newCapacity); ASSERT(newCapacity > 0); ASSERT((uintptr_t)(mask_t)(newCapacity-1) == newCapacity-1); //初始化缓存池,缓存池的可缓存数比缓存池的r总容量要小1 setBucketsAndMask(newBuckets, newCapacity - 1); /* 释放老的缓存池,因为读和写是非常耗时的操作, 缓存的目的是为了节省时间, 所以在创建新的缓存池时候没有将老缓存池的内存copy过来 而且这种操作也会清理掉缓存中长时间没调用的方法 */ if (freeOld) { cache_collect_free(oldBuckets, oldCapacity); } }
7:如果有旧的buckets,需要清理之前的缓存,即调用cache_collect_free方法
static void cache_collect_free(bucket_t *data, mask_t capacity) { #if CONFIG_USE_CACHE_LOCK cacheUpdateLock.assertLocked(); #else runtimeLock.assertLocked(); #endif if (PrintCaches) recordDeadCache(capacity); _garbage_make_room ();// 创建 垃圾回收空间 garbage_byte_size += cache_t::bytesForCapacity(capacity); garbage_refs[garbage_count++] = data;//存bucket_t *data cache_collect(false); // 清理旧bucket_t 垃圾回收 }
8:_garbage_make_room 源码解析
static void _garbage_make_room(void) { static int first = 1; // Create the collection table the first time it is needed //在第一次需要集合表时创建它 if (first) { first = 0; garbage_refs = (bucket_t**) malloc(INIT_GARBAGE_COUNT * sizeof(void *)); garbage_max = INIT_GARBAGE_COUNT; } // Double the table if it is full 如果表已满,则加倍 else if (garbage_count == garbage_max) { garbage_refs = (bucket_t**) realloc(garbage_refs, garbage_max * 2 * sizeof(void *)); garbage_max *= 2; //扩容 } }
为什么要创建新的新的buckets来替换原有的buckets并抹掉原有的buckets的方案,而不是在在原有buckets的基础上进行扩容?
- 减少对方法快速查找流程的影响:调用objc_msgSend时会触发方法快速查找,如果进行扩容需要做一些读写操作,对快速查找影响比较大。
- 对性能要求比较高:开辟新的buckets空间并抹掉原有buckets的消耗比在原有buckets上进行扩展更加高效
bucket_t *b = buckets(); mask_t m = capacity - 1; mask_t begin = cache_hash(sel, m); //求cache的hash ,通过计算得到sel存储的下标 mask_t i = begin; //遍历操作 do { // 如果sel 不存在就将sel存进去 if (fastpath(b[i].sel() == 0)) { incrementOccupied(); //Occupied ++ b[i].set<Atomic, Encoded>(sel, imp, cls); //存入 sel imp cls return; } // 如果sel 存在就返回 if (b[i].sel() == sel) { return; } } while (fastpath((i = cache_next(i, m)) != begin)); cache_t::bad_cache(receiver, (SEL)sel, cls);
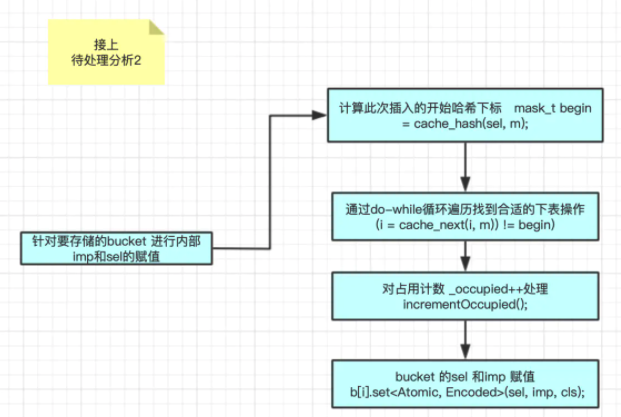
mask_t begin = cache_hash(sel, m); static inline mask_t cache_hash(SEL sel, mask_t mask) { //求cache的hash ,通过计算得到sel存储的下标 return (mask_t)(uintptr_t)sel & mask; }
key 就是 SEL
映射关系其实就是 sel & mask = index
mask = 散列表长度 - 1
所以 index 一定是 <= mask
4:cache_t的原理图
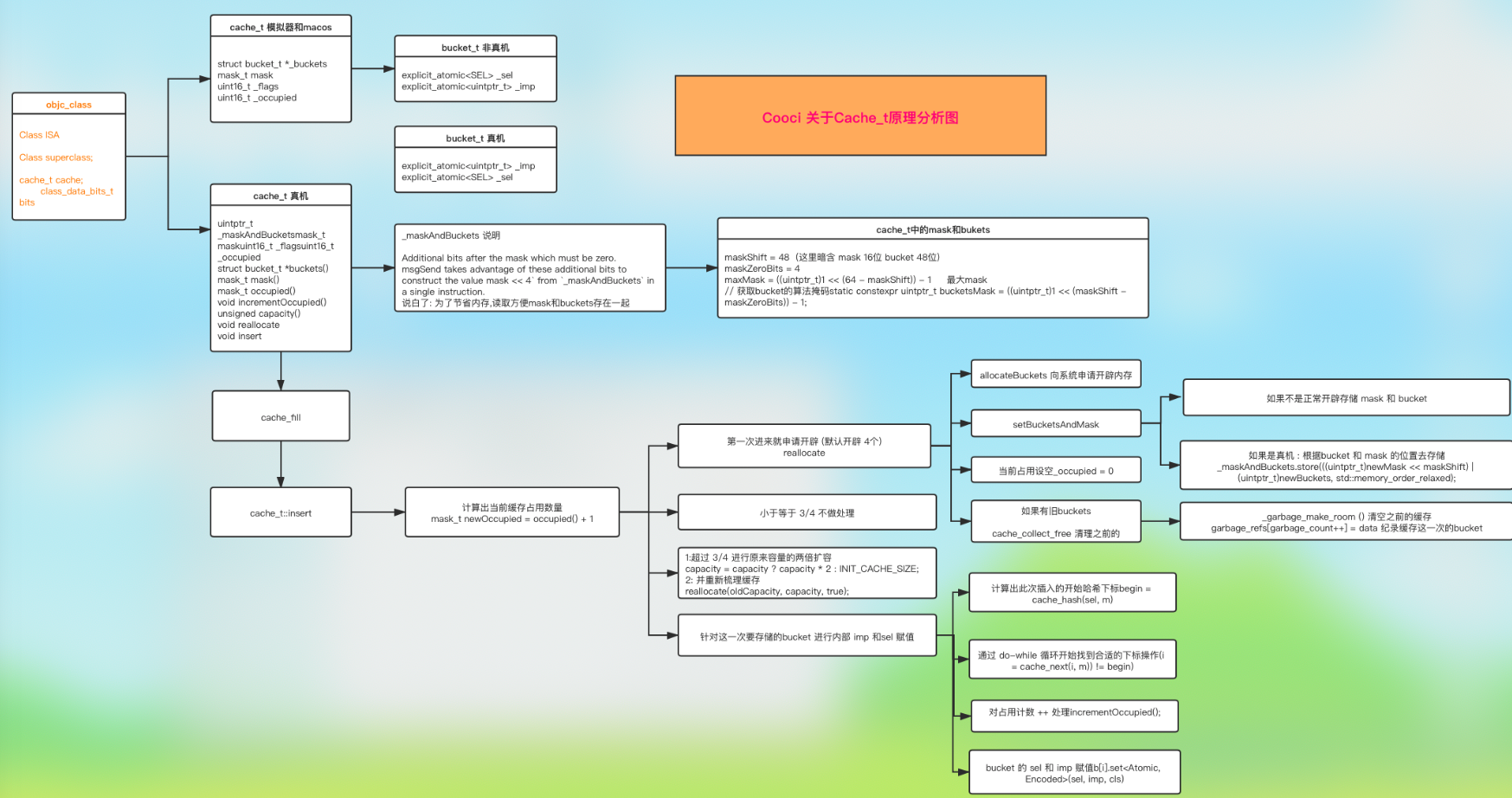
5:主要问题
- 1 .什么时候存储到cache中?
objc_msgSend第一次发送消息会触发方法查找,找到方法后会调用cache_fill()方法把方法缓存到cache中,这个在后面分析方法的本质的时候会提到。
- 2 .哪几种情况下会调用insert?
a.
init初始化对象的时候;
b. 属性赋值,调用了set方法;
c. 方法调用;
- 3.bucket数据为什么会有丢失的情况?
原因是在扩容时,是将原有的内存全部清除了,再重新申请了内存导致的
- 4 .方法缓存cache_t的方法?
散列表技术 key-value, 用散列表来缓存曾经调用过的方法,可以提高方法的查找速度
- 5.散列表的数据储存位置:
_mask( 散列表的长度-1 ) = 这个数据缓存的位置的下标,也就是缓存方法的索引,这个下标经过位运算之后,一定会小于或者等于散列表的长度-1 ,就不会出现数组越界的情况了
引用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号