

算法排序
排序
序
本篇包含以下内容:
- 选择排序
- 插入排序
- 希尔排序
- 归并排序
- 快速排序
- 堆排序
包含相应算法的核心思想, 代码实现, 以及部分算法的基础版改进版代码。
正文
排序是算法中最为基础的部分, 但重要性却不必多说, 种种数据结构, B树, 二叉树, 等等各种数据结构的起始点, 首先是必须解决排序的问题.
在看过算法中排序的这一章节后, 对于各种各样的论证, 概率统计等方面 是我目前所不能及的 部分, 而我所能做的, 无非是相信所给出的结论, 并在已给出的论证中, 再度添加进去自己的想法.
而目前来说,
个人理解中, 越是快速, 优越的算法 对数据 本身的特性利用的越多.
这并不是说这种算法无法解决不具备对应数据特性的 数据排序, 而是对于不具备特性的数据, 算法并不占据优越性, 仅此而已.
在本章所对应的所有代码在:
https://github.com/zyzdisciple/algorithms4th/tree/master/src/zyx/algorithms4th/unittwo
目录下, 并不需要任何特殊的jar包, 仅仅基础的 JDK即可, 个人使用 1.8.
而本文的主要内容也是对各种排序算法的, 核心, 场景, 思考做以总结. 仅此而已.
在这里贴出来几个关键类, 所有的 sort都继承自 AbstractSort, 简化代码;
public abstract class AbstractSort<T> {
protected Comparable<T>[] array;
public abstract void sort();
@SuppressWarnings("unchecked")
public boolean less(int q, int p) {
return array[q].compareTo((T)array[p]) < 0;
}
@SuppressWarnings("unchecked")
public boolean less(Comparable<T> q, Comparable<T> p) {
return q.compareTo((T)p) < 0;
}
public void exchange(int q, int p) {
Comparable<T> temp = array[q];
array[q] = array[p];
array[p] = temp;
}
public void show() {
System.out.println("****************************");
for (int i = 0, length = array.length; i < length; i++) {
System.out.print(array[i] + " ");
if ((i + 1) % 4 == 0) {
System.out.println();
}
}
System.out.println();
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
}
public boolean isSorted() {
for (int i = 0, length = array.length; i < length - 1; i++) {
if (!less(i, i + 1)) {
return false;
}
}
return true;
}
public void setArray(Comparable<T>[] array) {
this.array = array;
}
}
核心测试类:
public class SortCompare {
private Comparable<Double>[] array;
private final int N;
public SortCompare(int length) {
N = length;
generateArray();
}
public double time(AbstractSort<Double> sort) {
sort.setArray(array);
long start = new Date().getTime();
sort.sort();
long end = new Date().getTime();
sort.show();
return end - start;
}
private void generateArray() {
array = new Double[N];
for (int i = 0; i < N; i++) {
array[i] = (Comparable<Double>) Math.random();
}
}
}
1.基础排序算法
1.1选择排序
选择排序实在是一种基础的排序, 但同样有它的优越性所在:
在所有的算法中, 需要交换元素的次数是最少的:
在这里仅仅贴出核心代码:
public void sort() {
for (int i = 0, length = array.length; i < length; i++) {
for (int min = i, j = i; j < length; j++) {
if (less(array[j], array[min]))
min = j;
}
exchange(min, j);
}
}
选择排序核心: 在每一次遍历数组中, 找到最小的元素的下标, 在遍历一次之后, 将最小的元素向前移动.
不难看出, 交换元素 最多是 N - 1 次, 每个元素 至多也只需要移动一次.
1.2插入排序
在插入排序之前, 需要说明的是, 算法之间的性能对比还是挺有必要的一件事, 需要一点点直观的感受.
同样仅贴出核心代码:
public void sort() {
for (int i = 0, length = array.length; i < length; i++) {
for (int j = i; j > 0 && less(array[j], array[j - 1]); j--) {
exchange(j, j - 1);
}
}
}
插入排序核心: 在每插入一个元素的时候, 都假定左侧的数组为已经有序的, 而外循环的作用, 则是从 第一个元素开始 进行插入排序, 这样下一个元素左侧的数组都是已经排序好的.
插入排序更适用于 局部有序的数组, 或是向 已经有序的数组中,插入元素.
对于完全由随机数生成的数组, 在我的测试中, 仅仅10000个数组的排序, 插入排序的速度要比 选择排序快 20%~30%.
在我理解来, 插入排序的速度之所以快, 是因为在一定程度上利用了 有序这个特点, 在选择排序中, 对于有序 和 完全乱序的数组, 是相同的. 但插入排序则是巧妙的利用了部分有序这个特点.
1.2.1 插入排序的哨兵
核心代码:
public void sort() {
int min = 0;
int length = array.length;
for (int i = 0; i < length; i++) {
if (less(i, min)) {
min = i;
}
}
exchange(0, min);
if(length < 3)
return;
for (int i = 2; i < length; i++) {
for (int j = i; less(j, j - 1); j--) {
exchange(j, j - 1);
}
}
}
算法核心: 在插入排序中, 首先找出来最小元素, 这样在内循环中就去掉了一个判断即 j > 0; 算法效率有所提升;
2.排序算法进阶
2.1希尔排序
希尔排序是插入排序的进阶:
核心代码:
public void sort() {
int h = 1, length = array.length;
while(h < length / 3) {
h = h * 3 + 1;
}
while(h >= 1) {
for (int i = h; i < length; i++) {
for (int j = h; j > h && less(array[j], array[j - h]); j -= h) {
exchange(j, j - h)
}
}
h /= 3;
}
}
希尔排序核心:
插入排序的核心, 是假定排序元素的左侧已经有序, 右侧无序, 而希尔排序则是假定了为 h 有序, 对数据的特性预测与把握 较之于 插入排序更为精准. 因此效率得以提高.
那么h有序是什么呢?是指在数组中间隔 H个数值,其元素为有序的, 也就是对于数组元素 0 6 12 18 24...这几个元素本身已经有序,在循环中,不断调整H减小间距, 即可排序。即在下一次排序中,用插入排序的方式使得 0 3 6 9 12...有序即可。
且在 希尔排序中, H 也就是递增序列的选择也尤为重要, 如果觉得时间不够理想, 不妨换个 H 试试.
在相同环境下测试 , 10000数据的排序, 希尔排序比插入排序快 10倍左右.
而这在数据上来说是一个怎样的概念呢?
在我的电脑上来测试, 对10w数据排序:
-
选择排序: 15s以上
-
插入排序: 25s左右
-
插入排序的哨兵: 17s
-
希尔排序: 仅仅 78ms
算法, 正是 化不可能为可能.
2.2归并排序
归并排序的核心是 分治思想, 是将一个大问题 分解为K个小问题, 且子问题与原问题性质相同, 求出子问题的解, 原问题也会迎刃而解.有一个特别经典的算法: 动态规划.
核心代码:
private Comparable<T> temp;
//这个方法是为了统一接口调用, 初始化 sort方法.
@SuppressWarnings("unchecked")
public void sort() {
temp = new Comparable[array.length];
sort(0, array.length - 1);
}
public void sort(int lo, int hi) {
if (lo >= hi)
return;
int mid = (lo + hi) / 2;
sort(lo, mid);
sort(mid + 1, hi);
merge(lo, mid, hi);
}
public void merge(int lo, int mid, int hi) {
//左右数组的指针.
int lf = lo, rg = hi;
//这里之所以不在初始化时 copy数组, 在每完成一次合并之后,
//数组的元素顺序事实上已经发生变化了.
for (int i = lo; i <= hi; i++) {
temp[i] = array[i];
}
//这里的i 表示源数组的指针, 在遍历过程中,填充每一个元素
for (int i = lo; i <= hi; i++) {
if (lf > mid) {
array[i] = temp[rg++];
} else if (rg > hi) {
array[i] = temp[lf++];
} else if (less(temp[lf], temp[hi])) {
array[i] = temp[lf++]
} else {
array[i] = temp[rg++];
}
}
}
归并核心:
将两个已经有序的数组合并是一件比较简单的事,在递归中将数组不断分组, 直到两个数组长度各为1,而后不断进行合并。即完成排序。
2.2.1 归并排序改进一
在这段代码里进行了一定程度的修改, 优化, 速度有所提升.
1: 将 temp 数组的作用域放在了方法内, 通过参数来传递值.
2: 对于被排序数组/ 子数组长度小于等于 2 的, 采用直接排序, 而非使用merge方法
3: 对于已经有序的数组, 不再度进行排序;
核心代码:
public void sort() {
// TODO Auto-generated method stub
Comparable<T>[] temp = new Comparable[array.length];
//改进一
sort(0, array.length - 1, temp);
}
private void sort(int lo, int hi, Comparable<T>[] temp) {
//改进二
if (hi - lo <= 1) {
sort(lo, hi);
return;
}
int mid = (lo + hi) / 2;
sort(lo, mid, temp);
sort(mid + 1, hi, temp);
//改进三
if (!less(mid, mid + 1)) {
merge(lo, mid, hi, temp);
}
}
//改进二
private void sort(int lo, int hi) {
if (less(lo, hi))
return;
else
exchange(lo, hi);
}
private void merge(int lo, int mid, int hi, Comparable<T>[] temp) {}
//这里不直接使用lo hi 做变量的原因之一是:
//为了代码清晰, 为以后修改留下一定空间.
//lf 和 rg 永远指向下一个需要被比较的元素;
int lf = lo, rg = mid + 1;
//复制数组, 这里之所以不在初始化时 copy数组, 在每完成一次合并之后, 数组的元素顺序事实上已经发生变化了.
for (int i = lo; i <= hi; i++) {
temp[i] = array[i];
}
//在遍历过程中, 向原数组的相应位置填充数值, 所以这里的 i 主要表示当前要填充的位置.
//维护一个 lf 和 rg 分别是遍历两个被合并数组的指针
for (int i = lo; i <= hi; i++) {
if (lf > mid) {
array[i] = temp[rg++];
} else if (rg > hi) {
array[i] = temp[lf++];
} else if (less(temp[lf], temp[rg])) {
array[i] = temp[lf++];
} else {
array[i] = temp[rg++];
}
}
}
2.2.2归并排序改进版二
这个版本改动就比较大, 也是实现了一个较为关键的变动, 即:
不需要在每次的merge将数组单独复制一遍, 而是将数组直接排序到 temp数组, 和直接排序到 src数组, 同时也吸收了 改进版一 中的部分优点.
核心代码:
public void sort() {
// TODO Auto-generated method stub
Comparable<T>[] temp = new Comparable[array.length];
sort(0, array.length - 1, array, temp);
}
private void sort(int lo, int hi, Comparable<T>[] src, Comparable<T>[] temp) {
if (hi - lo <= 1) {
sort(lo, hi, src);
return;
}
int mid = (lo + hi) / 2;
//在这里每次顺序, 使得 src->temp, temp->src
sort(lo, mid, temp, src);
sort(mid + 1, hi, temp, src);
merge(lo, mid, hi, temp, src);
}
private void merge(int lo, int mid, int hi, Comparable<T>[] src, Comparable<T>[] dest) {
// lf 和 rg 永远指向下一个需要被比较的元素;
int lf = lo, rg = mid + 1;
// 在遍历过程中, 向目标数组的相应位置填充数值
for (int i = lo; i <= hi; i++) {
if (lf > mid) {
dest[i] = src[rg++];
} else if (rg > hi) {
dest[i] = src[lf++];
} else if (less(src[lf], src[rg])) {
dest[i] = src[lf++];
} else {
dest[i] = src[rg++];
}
}
}
private void sort(int lo, int hi, Comparable<T>[] src) {
if (src == array) {
if (less(lo, hi))
return;
else
exchange(lo, hi);
} else {
if (less(lo, hi)) {
src[lo] = array[lo];
src[hi] = array[hi];
} else {
src[lo] = array[hi];
src[hi] = array[lo];
}
}
}
2.2.3归并排序再改进
在这个版本中, 将之前的 插入排序界限 改为可选择的界限:
private void sort(int lo, int hi, Comparable<T>[] temp) {
//具体的需要自己选择, 在快速排序章节, 推荐5-15 不等
if (hi - lo <= 3) {
sort(lo, hi);
return;
}
int mid = (lo + hi) / 2;
sort(lo, mid, temp);
sort(mid + 1, hi, temp);
if (!less(mid, mid + 1)) {
merge(lo, mid, hi, temp);
}
}
private void sort(int lo, int hi) {
//if (less(lo, hi))
// return;
//else
// exchange(lo, hi);
//改进后代码
InsertSort.sort(array, lo, hi);
}
//class InsertSort
public static void sort(Comparable[] src, int lo, int hi) {
for (int i = lo + 1, length = src.length; i <= hi && i < length; i++) {
for (int j = i; j > lo && less(src[j], src[j - 1]); j--) {
exchange(src, j, j - 1);
}
}
}
其他代码更改可以看一看代码, github上都有.
效率确实有一定提示 20%~30%的提升, 至于更具体的也没有做估算.
2.2.4归并排序的自然 归并排序
自然归并排序, 即 自底向上的归并排序:
优点是对内存空间的占用要比自顶向下的归并排序小很多, 但在10w数量级以下时, 速度不及自顶向下的归并排序, 在百万数量级以上两者相差无几.
核心思路则是从前向后,按次序归并。
核心代码:
public void sortn2o(Comparable<T>[] temp) {
for (int size = 1, length = array.length; size < length; size = size + size) {
for (int i = 0; i < length - size; i += size + size) {
merge(i, i + size - 1, Math.min(i + (size << 1) - 1, length - 1), temp);
}
}
}
2.2.4总结
在我的测试中, 对比了改进版二 归并排序和希尔排序;
在50w数量级以下的时候, 两者效率相差无几, 但希尔排序所需的内存是小于归并排序的.
在50w以上, 甚至是百万数量级的时候, 这时候归并排序要比希尔排序的速度高两倍以上, 希尔排序测试需 1800ms, 而归并排序仅需700ms左右.
所以在50w以下且无序的数据中, 采取希尔排序, 在更大的数据量的情况下, 视情况采取归并排序.
2.3快速排序
快速排序是一种更好的算法, 无需额外的空间, 循环代码相当简洁, 其速度在重复数值较多的情况下优于 归并排序. 在大多情况下, 速度比归并排序快一点.
核心代码:
public void sort() {
Collections.shuffle(Arrays.asList(array));
sort(0, array.length - 1);
}
private void sort(int lo, int hi) {
if (lo >= hi)
return;
int mid = partition(lo, hi);
sort(lo, mid - 1);
sort(mid + 1, hi);
}
private int partition(int lo, int hi) {
int lf = lo, rg = hi + 1;
while (true) {
//因为在这里交换的是 lf 和 rg 的当前位置.
//所以两者必须表示比较完成后的值,因为同样的原因, rg 的起始值为 hi + 1;
while (less(++lf, lo) && lf < hi)
;
while (less(lo, --rg))
;
if (lf >= rg)
break;
exchange(lo, rg);
}
return rg;
}
这种方法的优点,在开始已经介绍过了, 就不再多说.
算法核心:
同样采取的是分治, 将数组分成两部分, 比中间值大 和 比中间值小, 将大的放在一边,小的放在一边, 不断切分数组, 实现排序. 它无需额外的空间, 及其简洁的循环, 简洁清晰的思想.
而数组本身的数据特性, 以及 选择的 被比较的元素是否合适, 对算法性能的影响实在不小.
在这里给出一个仅含两种元素的数组排序:
public void sort() {
// TODO Auto-generated method stub
T v = (T) array[0];
int lo = 0, rg = array.length;
//通过这种方式不需要判断界限
while(array[++lo].compareTo(v) == 0 && lo < rg)
;
int cmp = array[lo--].compareTo(v);
if (lo >= rg) {
return;
}
if (cmp > 0) {
while (true) {
while(array[++lo].compareTo(v) == 0)
;
while (array[--rg].compareTo(v) != 0)
;
if (lo >= rg)
break;
exchange(lo, rg);
}
} else {
lo = -1;
while (true) {
while (array[++lo].compareTo(v) != 0)
;
while (array[--rg].compareTo(v) == 0)
;
if (lo >= rg)
break;
exchange(lo, rg);
}
}
}
方法的核心就是归并排序的思想, 对待 百万级的数组, 排序仅需十几毫秒.
2.3.1快速排序改进版
与归并排序类似, 在数组拆分中同样的可以将数组长度不大的进行插入排序. 同时对于 被排序元素的选择也可以做一定程度的改进.
public void sort(int lo, int hi) {
if (hi <= lo + 4) {
InsertSort.sort(array, lo, hi);
return;
}
int mid = partition(lo, hi);
sort(lo, mid - 1);
sort(mid + 1, hi);
}
private int partition(int lo, int hi) {
int lf = lo, rg = hi + 1;
int mid = getMid(lo);
exchange(lo, mid);
while (true) {
while (less(++lf, lo) && lf < hi)
;
while (less(lo, --rg))
;
if (lf >= rg)
break;
exchange(lf, rg);
}
exchange(rg, lo);
return rg;
}
@SuppressWarnings("unchecked")
private int getMid(int lo) {
//第一种实现方式
if (array[lo].compareTo((T) array[lo + 1]) >=0) {
if (array[lo].compareTo((T) array[lo + 2]) <= 0) {
return lo;
}
if (array[lo + 1].compareTo((T) array[lo + 2]) >= 0) {
return lo + 1;
}
return lo + 2;
} else {
if (array[lo].compareTo((T) array[lo + 2]) >= 0) {
return lo;
}
if (array[lo + 1].compareTo((T) array[lo + 2]) >= 0) {
return lo + 2;
}
return lo + 1;
}
/*
//第二种实现方式
InsertSort.sort(array, lo, lo + 4);
return lo + 2;
*/
}
2.3.2三向快速排序
这种方式的核心思想与基础版的快速排序有所不同, 它将结果分为三部分:
[array[lo], array[lf - 1]] 为小于 array[mid]的
[array[lf], array[mid - 1]] 等于 array[mid]
[array[mid], array[rg]] 未未排序的
[array[rg + 1], array[hi]] 大于array[mid]
核心代码:
public void sort() {
Collections.shuffle(Arrays.asList(array));
sort(0, array.length - );
}
public void sort(int lo, int hi) {
if (lo >= hi)
return;
int lf = lo, rg = hi, mid = lo + 1;
int cmp;
T v = (T) array[lo];
//这里的mid 始终指向未排序首元素
while (mid <= rg) {
cmp = array[mid].compareTo(v);
if (cmp < 0) {
exchange(lf++, mid++);
} else if (cmp > 0) {
exchange(mid, rg--);
} else {
mid++;
}
}
sort(lo, mid - 1);
sort(rg + 1, hi);
}
适用情况, 对于重复元素越多的情况, 排序越快, 性能相比更优越;
2.4 堆排序
堆排序, 这是本章的最后一种算法, 虽然我并没有从这种算法中看出太多的性能上的优越性, 但是是一种全新的思路, 其核心概念:
堆, 就是一种完全二叉树, 一种在我看来相当有趣的数据结构, 至于这种数据结构, 暂时就先跳过, 不去介绍, 接下来的数据结构篇章, 会用相当长的时间, 汇总多种数据结构.
我本以为会将堆用链表来表达, 然而用数组就可以表述这种完全二叉树, 多叉树.
在二叉堆中, 用 k 表示当前节点, k/2表示父节点, 2k 和 2k + 1 表示子节点,其中 子节点小于等于父节点. 其余就不再详述, 且听下回分解.
核心代码:
public void sort() {
int length = array.length;
for(int i = length / 2; i >= 1; i--) {
sink(i, length);
}
while(length > 1) {
exchange(1, length--);
sink(1, length);
}
}
private void sink(int k, int hi) {
int i;
while (2k <= hi) {
i = k * 2;
if (less(i, i + 1)) {
i++;
}
if (less(k, i)) {
exchange(i, k);
k = i;
} else {
break;
}
}
}
@Override
public boolean less(int q, int p) {
return super.less(q - 1, p - 1);
}
@Override
public void exchange(int q, int p) {
super.exchange(q - 1, p - 1);
}
核心思想:
这种方法的核心思想在以下几点:
-
每一个元素都可以被看做一个子堆, 如果一个节点的两个子节点 即 2k 和 2k+1 都已经是 堆了, 那么对当前节点调用 sink() 则可以将它们变成一个堆.
-
所以在第一个循环中, 就是将整个数组变成一个 堆.
-
堆的一大特点是 根节点 一定是 最大元素, 因此将最大元素移动到最后一位, 同时将末尾元素放置顶端, 不断下沉. 实现排序.
-
在堆中的元素排序一般从数组的 1 ~ N位排序, 所以重写 less() exchange() 对应常规数组的 0 ~ N-1;
总结
至此,算法 排序的基础版, 告一段落.
在这里顺便提到以下几个点:
-
比较方法的选取:
-
在原始数据类型, 包括 Double, Integer等封装类型, 一般选取 Comparable接口即可, 因为这种往往只有单一的比较方式.
-
在需要多样化的比较方式时, 选取 Comparator接口, 代码示例:
import java.util.Comparator;
public class User{
private int age; private String name; public static final UserNameComparator USER_NAME_COMPARATOR = new UserNameComparator(); public static final AgeComparator AGE_COMPARATOR = new AgeComparator(); private static class UserNameComparator implements Comparator<User> { @Override public int compare(User o1, User o2) { // TODO Auto-generated method stub return o1.name.compareTo(o2.name); } } private static class AgeComparator implements Comparator<User> { @Override public int compare(User o1, User o2) { // TODO Auto-generated method stub return o1.age - o2.age; } }}
这样, 分别调用 AGE_COMPARATOR, USER_NAME_COMPARATOR, 则分别采取两种不同的比较方式.
-
-
数据的稳定性
能够保留数组中重复元素相对位置的则可以被称为是稳定的. 举个例子: 某时某地发生某事, 初始按照时间排序, 在按时间排序之后, 再度按照地点排序, 则时间的有序性又被彻底打乱. 则数组为不稳定的.
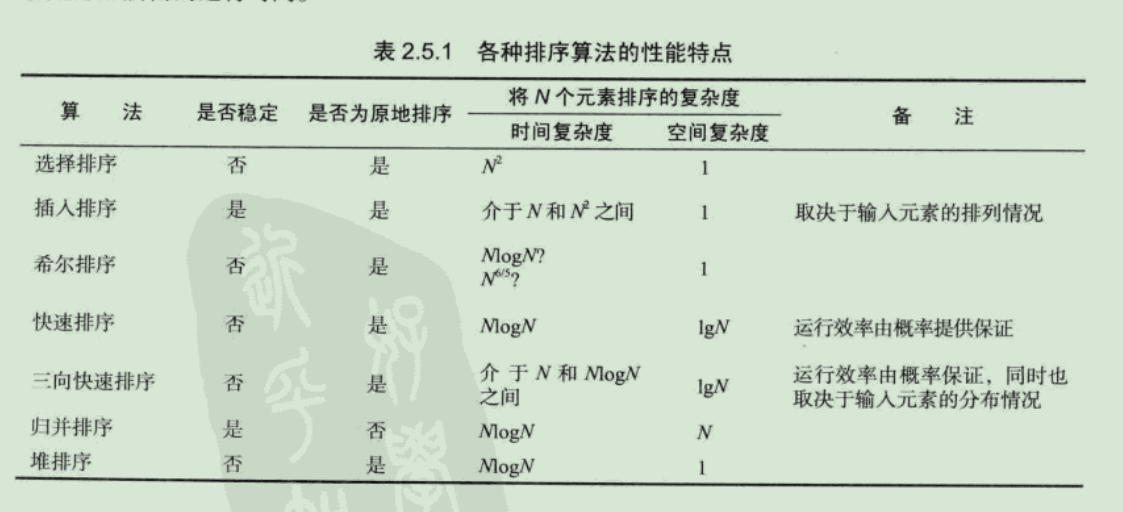
在大多情况下, 选取快速排序即可, 在含有重复元素较多的情况下, 三向快速排序也是不错的选择, 如果需要稳定性, 就得选择归并排序了, 另一方面,如果数组不大, 插入排序我觉得会是更好的选择.
最后
算法, 没有更好的算法, 唯有更适合的算法, 对待不同的情境采取不同的算法, 这里, 或者说任何地方所学到的算法都是基石, 拓宽你的思维, 开阔你的视野, 能够在不同的时候选择不同的算法. 仅此而已.
就像在求取中位数的时候, 仅仅是快速排序代码的变形, 思维方式关注目标的稍稍转变, 即可达到自己的目的.
public static Comparable select (Comparable a, int k) {
Collections.shuffle(Arrays.asList(a));
int lo = 0, hi = a.length - 1;
while(hi > lo) {
int j = partition(a, lo, hi);
if (j == k) {
return;
} else if (j > k) {
hi = j - 1;
} else {
lo = j + 1;
}
}
}
令 k = array.length / 2; 即可实现中位数的目的.
路漫漫, 不用问太多为什么做, 觉得值得, 就好.
