线性回归案例
城市气候与海洋的关系研究
导入包
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
1.导入数据各个海滨城市数据
ferrara1 = pd.read_csv('./ferrara_150715.csv')
ferrara2 = pd.read_csv('./ferrara_250715.csv')
ferrara3 = pd.read_csv('./ferrara_270615.csv')
ferrara=pd.concat([ferrara1,ferrara2,ferrara3],ignore_index=True)
# ignore_index是否忽略行索引(显式索引)
torino1 = pd.read_csv('./torino_150715.csv')
torino2 = pd.read_csv('./torino_250715.csv')
torino3 = pd.read_csv('./torino_270615.csv')
torino = pd.concat([torino1,torino2,torino3],ignore_index=True)
mantova1 = pd.read_csv('./mantova_150715.csv')
mantova2 = pd.read_csv('./mantova_250715.csv')
mantova3 = pd.read_csv('./mantova_270615.csv')
mantova = pd.concat([mantova1,mantova2,mantova3],ignore_index=True)
milano1 = pd.read_csv('./milano_150715.csv')
milano2 = pd.read_csv('./milano_250715.csv')
milano3 = pd.read_csv('./milano_270615.csv')
milano = pd.concat([milano1,milano2,milano3],ignore_index=True)
ravenna1 = pd.read_csv('./ravenna_150715.csv')
ravenna2 = pd.read_csv('./ravenna_250715.csv')
ravenna3 = pd.read_csv('./ravenna_270615.csv')
ravenna = pd.concat([ravenna1,ravenna2,ravenna3],ignore_index=True)
asti1 = pd.read_csv('./asti_150715.csv')
asti2 = pd.read_csv('./asti_250715.csv')
asti3 = pd.read_csv('./asti_270615.csv')
asti = pd.concat([asti1,asti2,asti3],ignore_index=True)
bologna1 = pd.read_csv('./bologna_150715.csv')
bologna2 = pd.read_csv('./bologna_250715.csv')
bologna3 = pd.read_csv('./bologna_270615.csv')
bologna = pd.concat([bologna1,bologna2,bologna3],ignore_index=True)
piacenza1 = pd.read_csv('./piacenza_150715.csv')
piacenza2 = pd.read_csv('./piacenza_250715.csv')
piacenza3 = pd.read_csv('./piacenza_270615.csv')
piacenza = pd.concat([piacenza1,piacenza2,piacenza3],ignore_index=True)
cesena1 = pd.read_csv('./cesena_150715.csv')
cesena2 = pd.read_csv('./cesena_250715.csv')
cesena3 = pd.read_csv('./cesena_270615.csv')
cesena = pd.concat([cesena1,cesena2,cesena3],ignore_index=True)
faenza1 = pd.read_csv('./faenza_150715.csv')
faenza2 = pd.read_csv('./faenza_250715.csv')
faenza3 = pd.read_csv('./faenza_270615.csv')
faenza = pd.concat([faenza1,faenza2,faenza3],ignore_index=True)
2.去除没用的列
faenza.head()
| Unnamed: 0 | temp | humidity | pressure | description | dt | wind_speed | wind_deg | city | day | dist | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 29.40 | 83 | 1015 | moderate rain | 1436863177 | 3.62 | 94.001 | Faenza | 2015-07-14 10:39:37 | 37 |
| 1 | 1 | 30.12 | 78 | 1015 | moderate rain | 1436866759 | 3.10 | 80.000 | Faenza | 2015-07-14 11:39:19 | 37 |
| 2 | 2 | 30.10 | 78 | 1015 | moderate rain | 1436870510 | 3.60 | 70.000 | Faenza | 2015-07-14 12:41:50 | 37 |
| 3 | 3 | 30.75 | 74 | 1015 | moderate rain | 1436874099 | 4.60 | 90.000 | Faenza | 2015-07-14 13:41:39 | 37 |
| 4 | 4 | 30.71 | 66 | 1015 | moderate rain | 1436877646 | 5.10 | 100.000 | Faenza | 2015-07-14 14:40:46 | 37 |
city_list = [ferrara,torino,mantova,milano,ravenna,asti,bologna,piacenza,cesena,faenza]
for city in city_list:
city.drop(labels='Unnamed: 0',axis=1,inplace=True)
3.显示最高温度于离海远近的关系(观察多个城市)
max_temp = [] # 10个城市的最高温度
cities_dist = [] # 10个城市距离海洋的距离
for city in city_list:
max_temp.append(city['temp'].max())
cities_dist.append(city['dist'].max())
max_temp
[33.43000000000001,
34.69,
34.18000000000001,
34.81,
32.79000000000002,
34.31,
33.850000000000016,
33.920000000000016,
32.81,
32.74000000000001]
cities_dist
[47, 357, 121, 250, 8, 315, 71, 200, 14, 37]
- 在方程式中:
- x:自变量
- y:因变量
- y = 5x + 4
- 自变量的变化会导致因变量的变化
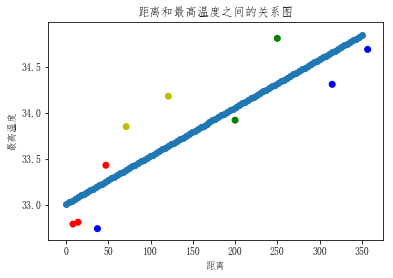
plt.scatter(cities_dist,max_temp,c='rbyg')
plt.xlabel('距离')
plt.ylabel('最高温度')
plt.title('距离和最高温度之间的关系图')
Text(0.5,1,'距离和最高温度之间的关系图')

- 基于当前的关系模式将某一个未知最高温度的城市的最高温度进行预测
机器学习
-
机器学习(ML)和人工智能之间的关系是什么?
- 机器学习是实现人工智能的一种技术手段
-
什么是算法模型(model或者m)?
- 特殊的对象。特殊之处就在于该对象内部集成了某一种还没有求出解的方程。
-
算法模型的作用?
- 实现预测:预测出一个未知的结果
- 实现分类:将一个未知分类的事务归类到已知的类群中
- 重点:算法模型中的方程的解就是预测或者分类的结果
-
样本数据
- 作用:将样本数据带入到算法模型中让其内部的方程有解。至此算法模型就可以实现分类或者预测的功能。
- 训练模型:将样本数据带入到算法模型中让其内部的方程有解。只有训练好的算法模型才可以实现分类或者预测的功能!
- 组成部分:
- 特征数据:自变量
- 目标数据:因变量
-
sk-learn库:封装了大量的算法模型
-
模型的分类:
- 有监督学习:如果模型需要的样本数据必须包含特征数据和目标数据
- 无监督学习:如果模型需要的样本只需要有特征数据
-
导入sklearn,建立线性回归算法模型对象
- 该模型内部封装的是一个线性方程:y = wx + b
# 0.提取样本数据(特征数据,目标数据)
feature = np.array(cities_dist) # 特征数据
feature = feature.reshape(-1, 1) # 二维形式的特征数据
target = np.array(max_temp) # 目标数据
- 训练模型调用的方法是fit(X,y),y任意形式(维度)的目标数据,X表示的必须是二维的特征数据
# 1.选择一个模型对象进行实例化
from sklearn.linear_model import LinearRegression
linner = LinearRegression()
# 2.训练模型
linner.fit(feature,target) #X,y
# 3.使用相关的评价指标来评价模型
linner.score(feature,target)
# 4.实现预测
linner.predict([[222],[333]]) #调用方程:y = 3x + 6
array([34.17277041, 34.75520186])
# 画出回归曲线
x = np.linspace(0,350,num=100)
y = linner.predict(x.reshape(-1,1))
plt.scatter(cities_dist,max_temp,c='rbyg')
plt.xlabel('距离')
plt.ylabel('最高温度')
plt.title('距离和最高温度之间的关系图')
plt.scatter(x,y)
<matplotlib.collections.PathCollection at 0xd0014e0>
查看最低温度与海洋距离的关系
min_temp = []
for city in city_list:
min_temp.append(city['temp'].min())
# 0.提取样本数据(特征数据,目标数据)
feature = np.array(cities_dist) # 特征数据
feature = feature.reshape(-1, 1) # 二维形式的特征数据
target = np.array(min_temp) # 目标数据
# 1.选择一个模型对象进行实例化
from sklearn.linear_model import LinearRegression
linner = LinearRegression()
# 2.训练模型
linner.fit(feature,target) #X,y
# 3.使用相关的评价指标来评价模型
linner.score(feature,target)
# 4.实现预测
linner.predict([[222],[333]])
# 画出回归曲线
x = np.linspace(0,350,num=100)
y = linner.predict(x.reshape(-1,1))
plt.scatter(cities_dist,min_temp,c='rbyg')
plt.xlabel('距离')
plt.ylabel('最低温度')
plt.title('距离和最低温度之间的关系图')
plt.scatter(x,y)
<matplotlib.collections.PathCollection at 0x16129f776d8>


