数据结构与算法(第一篇)——基础知识
1、基础结构概述
数据结构:是指相互之间存在一种或多种特定关系的数据元素的集合用计算机存储、组织数据的方式。数据结构分别为逻辑结构、(存储)物理结构和数据的运算三个部分。

1.1 概念术语
(1)数据(data)是能被计算机处理的符号或符号集合,含义广泛,可理解为“原材料”。如字符、图片、音视频等。
(2)数据元素(data element)是数据的基本单位。例如一张学生统计表。
(3)数据项(data item)组成数据元素的最小单位。例如一张学生统计表,有编号、姓名、性别、籍贯等数据项。
(4)数据对象(data object)是性质相同的数据元素的集合,是数据的一个子集。例如正整数N={1,2,3,····}。
(5)数据结构(data structure)是数据的组织形式,数据元素之间存在的一种或多种特定关系的数据元素集合。
(6)数据类型(data type)是按照数据值的不同进行划分的可操作性。在C语言中还可以分为原子类型和结构类型。原字类型是不可以再分解的基本类型,包括整型、实型、字符型等。结构类型是由若干个类型组合而成,是可以再分解的。
1.2 数据的逻辑结构
逻辑结构(logical structure)是指在数据中数据元素之间的相互关系。数据元素之间存在不同的逻辑关系构成了以下4种结构类型。
(1)集合结构:集合的数据元素没有其他关系,仅仅是因为他们挤在一个被称作“集合”的盒子里。
(2)线性结构:线性的数据元素结构关系是一对一的,并且是一种先后的次序,就像 a-b-c-d-e··· 被一根线穿连起来。
(3)树形结构:树形的数据元素结构关系是一对多的,这就像文件系统目录,根目录下有每一级目录,每一级目录下面都有多个子目录。
(4)图结构:图的数据元素结构关系是多对多的。就是我们常见的各大城市的铁路图,一个城市有很多线路连接不同城市。
1.3 数据的存储(物理)结构
存储结构(storage structure)也称为物理结构(physical structure),指的是数据的逻辑结构在计算机中的存储形式。数据的存储结构一般可以反映数据元素之间的逻辑关系。分为顺序存储结构和链式存储结构。
(1)顺序存储结构:是把数据元素存放在一组存储地址连续的存储单元里,其数据元素间的逻辑关系和物理关系是一致的。
(2)链式存储结构:是把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的,数据元素的存储关系并不能反映其逻辑关系,因此需要借助指针来表示数据元素之间的逻辑关系。
小结:数据的逻辑结构和物理结构是密切相关的,在学习数据的过程中会发现,任何一个算法的设计取决于选定的数据逻辑结构,而算法的实现依赖于所采用的存储结构。
1.4 抽象数据类型
抽象数据类型(abstract data type,ADT)是描述具有某种逻辑关系的数据模型,并对在数学模型上进行的一组操作。抽象数据类型描述的是一组逻辑上的特性,与在计算机内部表示无关,计算机中的整数数据类型是一个抽象数据类型,不同处理器可能实现方法不同,但其逻辑特性相同,即加、减、乘、除等运算是一致的。“抽象”的意思是数据类型的数学抽象特性而不是指它们的实现方法。抽象数据类型体现了程序设计中的问题分解、抽象、信息隐藏等特性,可以把现实中的大问题分解为多个规模小且容易处理的小问题,然后建立起一个能被计算机处理的数据,并把每个功能模块的实现细节作为一个独立的单元,从而使具体实现过程隐藏起来。就类似建一栋房子,分成若干个小任务,如地皮规划、图纸设计、施工、装修等,整个过程与抽象数据类型中的问题分解类似。而搬砖人不需要了解图纸设计如何,设计图纸人员不需要了解施工的地基、砌墙的具体细节,装修工人不用关系图纸和搬砖过程,这就是抽象类型中的信息隐藏。
1.5 算法
算法(algorithm)是解决特定问题求解步骤的描述,在计算机中表现为有限的操作序列。在数据类型建立起来之后,就要对这些数据类型进行操作,建立起运算的集合即程序。运算的建立、方法好坏直接决定着计算机程序原型效率的高低。
(1)数据结构和算法的关系
两者既有联系又有区别。联系是程序=算法+数据结构。数据结构是算法实现的基础,算法总是要依赖某种数据结构来实现的。算法的操作对象是数据结构。区别是数据结构关注的是数据的逻辑结构、存储结构有一基本操作,而算法更多的是关注如何在数据结构的基本上解决实际问题。算法是编程思想,数据结构则是这些思想的基础。
(2)算法的五大特性
有穷性,是指算法在执行有限的步骤之后,自动结束而不是出现无限循环,并且每一个步骤在可接受的时间内完成。
确定性,是指算法执行的每一步骤在一定条件下只有一条执行路径,也就是相同输入只能有一个唯一的输出结果。
可行性,是指算法每一步骤都必须可行,能够通过有限的执行次数完成。
输入,是指算法具有零个或多个输入。
输出,是指算法至少有一个或多个输出。
1.6 时间复杂度
在进行算法分析时,语句总是执行次数 T(n) 是关于问题规模 n 的函数。进而分析次数 T(n) 随规模 n 的变化情况并确定 T(n) 的数量级。算法的时间复杂度就是算法的时间度量,记作 T(n) = O(f(n))。它表示随问题规模 n 的增大,算法的执行时间的增长率和 f(n)的增长率相同,称作算法的渐进时间复杂度,简称为时间复杂度。其中,f(n)是问题规模 n 的某个函数。
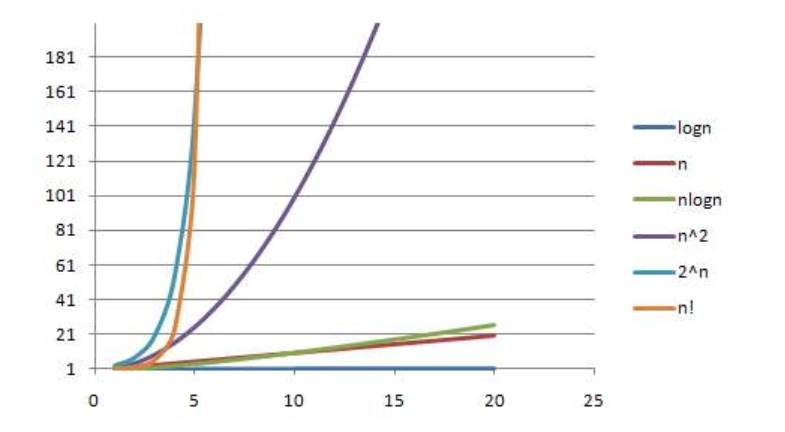
算法的时间复杂度是衡量一个算法好坏的重要指标。一般情况下,随着规模 n 的增大,次数 T(n) 的增长较慢的算法为最优算法。常见时间复杂度从小到大依次排列:O(1) < O(log2n) < O(n) < O(n²)<O(n³) ····<O(n!)
1.7 空间复杂度
空间复杂度(space complexity)作为算法所需存储空间的量度,记做 S(n) = O (f(n))。其中,n 为问题的规模;f(n)为语句关于 n 的所占存储空间的函数。
一般情况下,一个程序在机器上运行时,除了需要存储程序本身的指令、常数、变量和输入数据外,还需要存储对数据操作的存储单位。若输入数据所占空间只取决于问题本身,和算法无关,这样只需要分析该算法在实现时所需的辅助单元即可。若算法执行时所需的辅助空间相对于输入数据量而言是个常量,则称此算法为原地工作,空间复杂度为 O(1)。
2、C语言基础
2.1 开发环境
C语言常见的开发环境有很多种,如 LCC、Turbo C2.0、Visual C++、Borland C++,本章主要介绍使用最多的 Turbo C 2.0 和 Visual C++ 6.0。
(1)Turbo C 2.0 :1989年,美国 Borland 公司推出,简称 TC。它集编辑、编译、连接和运行一体的C程序集成开发环境。界面简单、上手容易、使用方便,通过一个简单的主界面可以很容易编辑、编译和链接程序,也是初学者广发使用的开发工具。
(2)Visual C++6.0:是强大的C/C++软件开发工具,使用非常广泛,已经成为首选的开发工具。利用它可以开发 Windows SDK、MFC 等应用程序。
2.2 递归与非递归***
在数据结构与算法实践过程中,经常会遇到利用递归实现算法的情况。递归是一种分而治之、将复杂问题转换成简单问题的求解方法。使用递归可以使编写的程序简洁、结构清晰,程序的正确性很容易证明,不需要了解递归调用的具体细节。
(1)函数的递归:就是函数自己调用自己,即一个函数在调用其他函数的过程中,又出现对自身的调用,这种函数称为递归函数。函数的递归调用就是自己调用自己,可以直接调用自己也可以间接调用。其中,在函数中直接调用自己称为函数的直接递归调用;如果函数 f1 调用了函数 f2 又再次调用了函数 f1,这种调用的方式我们称之为间接递归调用。
例1:利用递归求 n!:有两种情况,当 n=0 递归结束,返回值为 1;当 n!=0 时,继续递归。
//递归求n!函数实现 int factorial (int n){ if(n ==0 ) return 1; else return n*factorial(n-1); }
例2:已知有数组a[] ,要求利用递归实现求n个数中的最大值。
a[] ={0,···,n-1};
int findMax(int a[] ,int n){
int m ;
if (n<=1)
return a[0];
else
{
m = findMax(a,n-1);
return a[n-1] >= m ?a[n-1] : m ; //找到最大值
}
}
(2)迭代与递归
迭代与递归是程序设计中最常用的两种结构。任何能使用递归解决的问题都能使用迭代的方法解决。迭代和递归的区别是,迭代使用的是循环结构,递归使用的是选择结构。大量的递归会耗费大量的时间和内存,每次递归调用都会建立函数的一个备份,会占用大量的内存空间。迭代则不需要反复调用函数和占用额外的内存。对于较为简单的递归问题,可以利用简单的迭代将其转化为非递归。而对于较为复杂的递归问题,需要通过利用数据结构中的栈来消除递归。
(3)指针
是C语言中一个重要概念,也是最不容易掌握的内容。指针常常用在函数的参数传递和动态内存分配中。指针与数组相结合,使引用数组成分的形式更加多样化,访问数组元素的手段更加灵活;指针与结构体结合,利用系统提供的动态存储手段,能构造出各种复杂的动态数据结构;利用指针形参,使函数能实现传递地址形参和函数形参的要求。接下里会介绍指针变量的概念、指针与数组、函数指针与指针函数。
指针是一种变量,也称之为指针变量,它的值不少整数、浮点数和字符,而是内存地址。指针的值就是变量的地址,而变量又拥有一个具体的值。因此,可以理解为变量名直接引用了一个值,指针间接地引用了一个值。
指针可以与变量结合,也可以与数组结合使用。指针数组是一种存放一组变量的地址。数组指针是一个指针,表示该指针指向数组的指针。数组指针可以进行自增或自减运算,但是数组名则不能进行自增或自减运算,这是因为数组名是一个常量指针,它是一个常量,常量值是不能改变的。函数指针与指针函数同理。
2.3 参数传递
(1)传值调用:分为实际参数和形式参数。例如:
int GCD(int m ,int n); void main(){ int a,b,v, v = GCD(a,b); //实际参数 } int GCD(int m ,int n){ //形式参数 int r; r = m; do{ m=n; n=r; r=m&n; }while(r); return n; }
上面的函数参数传递属于参数的单向传递,即 a 和 b 可以把值传递给 m 和 n,而不是可以把 m 和 n 传递给 a 和 b。实际参数和形式参数的值的改变都不会互相收到影响。
2.4 结构体和联合体
结构体也称共用体,是自定义的数据类型,用于构造非数值数据类型,在处理实际问题中应用非常广泛。数据结构中的链表、队列、树、图等结构都需要用到结构体。教师表结构体如下所示。
//结构体类型 struct teacher{ //数据项 int no; char name[20]; char sex[4]; char headship[8]; char degree[6]; long int phone; }
与结构体一样,联合体也是一种派生的数据类型。但是与结构体不同的是,联合体的成员共享同一个存储空间。定义联合体一般形式如下所示。
union 共用体名{ 成员列表; } 变量列表; —————————————————————————— union data{ int a ; float b; char c; double d; }abc; //或写成 union data{ int a; float b; char c; double d; }; union data abc;
2.5 链表
在C语言中,处理已知数据可以使用数组。如果事先并不知道要处理的数据的个数,则需要使用链表结构。链表需要动态分配内存,链表的长度随时可以发生变化。链表有一个指针类型的成员指向自身,该指针指向与结构体一样的类型。例如如下语句:
struct node{ int data; struct data *next; }
自引用结构体类型为 struct node,该结构体类型有两个成员:整数成员 data,指针成员 next。成员 next 是指向结构体为struct node 类型的指针。通过这种形式定义的结构体通过 next 指针把两个结构体变量连在一起。这种自引用结构体单元称为结点,结点之间通过箭头连接起来,构成一张表,称为链表。
链表中第一个结点的指针称为头指针且可以访问链表的每一个结点。为了方便操作,在链表的第一个结点之前增加一个头结点。
2.6 内存的分配与释放
(1)malloc 函数主要作用是分配一块长度为 size 的内存空间。void *malloc(unsigned int size); 其中,size 就是要分配的内存空间大小字节。使用时最好先检查一下是否分配成功,否则返回 null,可以保证程序的正确运行。使用完分配后的空间要利用free 函数及时释放。
(2)free 函数主要作用是将内存空间释放。void free (void *p); 其中,参数 p 指向要释放的内存空间。不能使用已经被 free 函数释放的内存空间。

