python——bytes、bytearray
1、python3引入两个新类型
1>bytes:
在内存中连续存放的不可变字节序列
2>bytearray:
字节数组、可变
3>字符串与bytes
字符串是字符组成的有序序列,字符可以使用编码来理解
bytes是字节组成的有序的不可变序列
bytearray是字节组成的有序的可变序列
4>编码与解码
字符串按照不同的字符集编码encode返回字节序列bytes
encode(encoding='utf-8', errors='strict') → bytes
# -*- coding:utf-8 -*- # version:python3.7 s1 = '啊'.encode(encoding='gbk') #按gbk编码 s2 = s1.decode(encoding='gbk') #按gbk解码,编码解码得对应,要不然会出错 print(s1,s2) 执行结果: b'\xb0\xa1' 啊
字节序列按照不同的字符集解码decode返回字符串
bytes.decode(encoding="utf-8", errors= "strict") → str
bytearray.decode(encoding="utf-8", errors="strict") → str
# -*- coding:utf-8 -*- # version:python3.7 s1 = 'abc' b1 = s1.encode() print(s1,b1) s2 = b1.decode() print(s2) b2 = bytearray(b1) print(b2) 执行结果: abc b'abc' abc bytearray(b'abc')
2、ASCII
ASCII (American Standard Code for Information Interchange,美国信息交换标准代码) 是基于拉丁字母的一套单字节编码系统
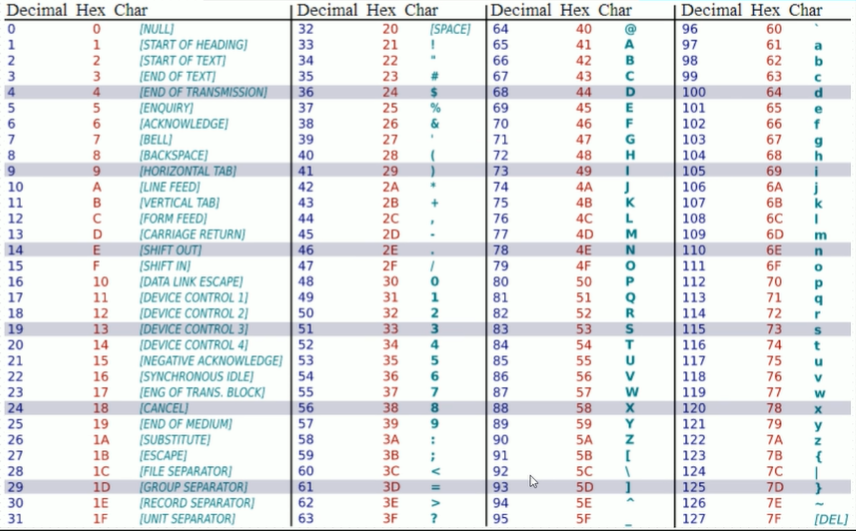
熟记:
Tab、回车、换行 对应ASCII表10进制数 \t 9 \r 13 \n 10
数值、字母 对应ASCII表16进制数
0~9 1:31(16进制) → 3*16+1=49(10进制) A-Z A:41(16进制) → 4*16+1=65(10进制) a-z a:61(16进制) → 6*16+1=97(10进制)
编码表:
ASCII: 0-127
Unicode: 全球统一编码(双字节表达,中英都是)
GBK: 英文用单字节,中文用双字节
UTF-8: 中文三字节,英文单字节
3、bytes定义
bytes() 空bytes
# -*- coding:utf-8 -*- # version:python3.7 b1 = bytes() b2 = b'' print(b1,b2) 执行结果: b'' b''
bytes(int) 指定字节的bytes,被0填充
# -*- coding:utf-8 -*-
# version:python3.7
print(bytes(3)) 执行结果: b'\x00\x00\x00'
bytes(iterable_of_ints) → bytes [0,255] 的int组成的可迭代对象
# -*- coding:utf-8 -*- # version:python3.7 print(bytes([61,62])) #ASCII:十进制61,62 -> '=>' print(bytes([0x61,0x62])) #ASCII:十六进制61,62 -> 'ab' print(bytes([97,98])) #ASCII:十六进制97,98 -> 'ab' 执行结果: b'=>' b'ab' b'ab'
bytes(string, encoding[ errors]) → bytes 等价于string.encode()
# -*- coding:utf-8 -*-
# version:python3.7
print(bytes('abc','utf8')) print('abc'.encode()) 执行结果: b'abc' b'abc'
bytes(bytes_or_buffer) → immutable copy of bytes_or_buffer 从一个字节序列或者buffer复制出一个新的不可变的bytes对象
# -*- coding:utf-8 -*-
# version:python3.7
b1 = bytes([0x61,0x62]) b2 = b1 #认为重新包装成字节序列 print(b1,b2) print(id(b1),id(b2)) #python对某些常量进行了优化,bytes和str一样属于字面常量 执行结果: b'ab' b'ab' 1777529096928 1777529096928
使用b前缀定义
只允许基本ASCII使用字符形式b'abc9'
使用16进制表示b"\x41\x61"
4、bytes操作
和str类型类似,都是不可变类型,所以方法很多都一样,只不过bytes的方法,输入是bytes,输出是bytes
# -*- coding:utf-8 -*- # version:python3.7 print(b'abcdef'.replace(b'f',b'k')) #replace:替换 print(b'abcdef'.find(b'c')) #find:查找,返回索引 执行结果: b'abcdek' 2
类方法bytes.fromhex(string)
string必须是2个字符的16进制的形式,'61 62 6a 6b',空格将被忽略
hex()
返回16进制表示的字符串
例:'abc'.encode().hex()
# -*- coding:utf-8 -*- # version:python3.7 b1 = bytes.fromhex('6162 09 6a 6b00') print(b1) b2 = b1.hex() print(b2) 执行结果: b'ab\tjk\x00' 6162096a6b00
索引
例:b'abcdef'[2] 返回该字节对应的十进制数,int类型
# -*- coding:utf-8 -*- # version:python3.7 print(b'abcdef'[2]) 执行结果: 99
5、bytearray定义
bytearray() 空bytearray
bytearray(int) 指定字节的bytearray,被0填充
bytearray(iterable_of_ints) → bytearray [0,255]的int组成的可迭代对象
bytearray(string, encoding[, errors]) → bytearray近似string.encode(),不过返回可变对象
bytearray(bytes_or_buffer) 从一个字节序列或者buffer复制出一个新的可变的bytearray对象
注意,b前缀定义的类型是bytes类型
6、bytearray操作
和bytes类型的方法相同
# -*- coding:utf-8 -*- # version:python3.7 print(bytearray(b'abcdef').replace(b'f',b'k')) print(bytearray(b'abc').find(b'b')) 执行结果: bytearray(b'abcdek') 1
类方法bytearray.fromhex(string)
string必须是2个字符的16进制的形式,'61 62 6a 6b',空格将被忽略
hex()
返回16进制表示的字符串
# -*- coding:utf-8 -*- # version:python3.7 b1 = bytearray.fromhex('6162 09 6a 6b00') print(b1) print(b1.hex()) 执行结果: bytearray(b'ab\tjk\x00') 6162096a6b00
索引
例:bytearray(b'abcdef')[2] 返回该字节对应的数,int类型
# -*- coding:utf-8 -*- # version:python3.7 print(bytearray(b'abcdef')[2]) 执行结果: 99
append(int) 尾部追加一个元素
insert(index, int) 在指定索引位置插入元素
extend(iterable_of_ints) 将一个可迭代的整数集合追加到当前
pop(index=-1) 从指定索引上移除元素,默认从尾部移除
remove(value) 找到第一个value移除, 找不到抛ValueError异常
# -*- coding:utf-8 -*- # version:python3.7 b = bytearray(b'abcd') print(b) b.append(101) print(b) b.insert(0,65) print(b) b.extend(range(102,106)) print(b) b.pop(0) print(b) b.remove(105) print(b) 执行结果: bytearray(b'abcd') bytearray(b'abcde') bytearray(b'Aabcde') bytearray(b'Aabcdefghi') bytearray(b'abcdefghi') bytearray(b'abcdefgh')
注意:上述方法若需要使用int类型,值在[0, 255]
clear() 清空bytearray
reverse() 翻转bytearray,就地修改
7、字节序:
大端模式,big-endian;小端模式,little-endian
Intel X86 CPU使用小端模式
网络传输更多使用大端模式
Windows、Linux使用小端模式
Mac OS使用大端模式
Java虚拟机是大端模式

8、int和bytes
int.from_bytes(bytes, byteorder)
将一个字节数组表示成整数
int.to_bytes(length, byteorder)
byteorder字节序
将一个整数表达成一个指定长度的字节数组
# -*- coding:utf-8 -*- # version:python3.7 i = int.from_bytes(b'abcd','big') #大端模式将 bytes -> int print(i,hex(i)) print(i.to_bytes(4,'big')) #使用大端模式将 int -> bytes (给定四字节) b1 = 97 print(b1.to_bytes(3,'big')) 执行结果: 1633837924 0x61626364 b'abcd' b'\x00\x00a'

