

Ceph集群维护
通过套接字进行单机管理
node节点
root@node1:~# ll /var/run/ceph/
total 0
drwxrwx--- 2 ceph ceph 100 Sep 7 10:15 ./
drwxr-xr-x 30 root root 1200 Sep 7 14:04 ../
srwxr-xr-x 1 ceph ceph 0 Sep 7 10:15 ceph-osd.0.asok=
srwxr-xr-x 1 ceph ceph 0 Sep 7 10:15 ceph-osd.1.asok=
srwxr-xr-x 1 ceph ceph 0 Sep 7 10:15 ceph-osd.2.asok=mon节点
root@mon3:~# ll /var/run/ceph/
total 0
drwxrwx--- 2 ceph ceph 60 Sep 7 10:21 ./
drwxr-xr-x 30 root root 1180 Sep 7 14:04 ../
srwxr-xr-x 1 ceph ceph 0 Sep 7 10:21 ceph-mon.mon3.asok=将ceph.client.admin.keyring拷贝到mon和node节点,这样就可以执行一些查看状态的命令
root@mon3:/etc/ceph# ceph --admin-socket /var/run/ceph/ceph-mon.mon3.asok --help
ceph集群的停止或重启
重启之前,要提前设置ceph集群不要将OSD标记为out,避免node节点关闭服务后被踢出ceph集群外:
cephadmin@deploy:~$ ceph osd set noout #关闭服务前设置noout
noout is set
cephadmin@deploy:~$ ceph osd unset noout #启动服务后取消noout
noout is unset关闭顺序:
关闭服务前设置noout
关闭存储客户端停止读写数据
如果使用了RGW,关闭RGW
关闭cephfs元数据服务
关闭cephOSD
关闭ceph manager
关闭cephmonitor
启动顺序
启动ceph monitor
启动ceph manager
启动ceph OSD
启动cephfs元数据服务
启动RGW
启动存储客户端
启动服务后取消noout --》 ceph osd unset noout
添加服务器
ceph-deploy install --release pacific node5 #在node5安装组件
ceph-deploy disk zap node5 /dev/sdx #擦出磁盘sdx
sudo ceph-deploy osd create ceph-node5 --data /dev/sdx #添加osd
删除OSD或服务器
把故障的OSD从ceph集群中删除
ceph osd out 1 #把osd提出集群
#等一段时间
#停止osd.x进程
ceph osd rm 1 #删除osd删除服务器
停止服务器之前要把服务器的OSD先停止并从ceph集群删除
ceph osd out 1 #把osd提出集群
#等一段时间
#停止osd.x进程
ceph osd rm 1 #删除osd
当前主机的其他磁盘重复以上操作
OSD全部操作完成后下限主机
ceph osd crush rm ceph-node1 #从crush删除ceph-node1
创建纠删码池,默认两份数据两份备份
k=2 如果10kb对象则分割成两个5kb的对象
m=2 2个额外的备份,最多可以down两个osd
cephadmin@deploy:~$ ceph osd pool create erasure-testpool 16 16 erasure
pool 'erasure-testpool' created
cephadmin@deploy:~$ ceph osd erasure-code-profile get default
k=2
m=2
plugin=jerasure
technique=reed_sol_van可以看到4个盘
cephadmin@deploy:~$ ceph pg ls-by-pool erasure-testpool | awk '{print $1,$2,$15}'
PG OBJECTS ACTING
10.0 0 [10,8,2,4]p10
10.1 0 [9,6,4,0]p9
10.2 0 [1,10,4,6]p1
10.3 0 [7,3,11,2]p7
10.4 0 [8,1,10,3]p8
10.5 0 [9,1,4,8]p9
10.6 0 [5,10,1,8]p5
10.7 0 [11,0,4,6]p11
10.8 0 [11,7,3,0]p11
10.9 0 [3,0,10,7]p3
10.a 0 [11,7,4,1]p11
10.b 0 [5,0,10,8]p5
10.c 0 [4,7,10,0]p4
10.d 0 [4,7,9,2]p4
10.e 0 [4,9,8,0]p4
10.f 0 [11,4,7,2]p11
* NOTE: afterwards写入数据和验证数据
cephadmin@deploy:~$ sudo rados put -p erasure-testpool testfile1 /var/log/syslog
cephadmin@deploy:~$ ceph osd map erasure-testpool testfile1
osdmap e235 pool 'erasure-testpool' (10) object 'testfile1' -> pg 10.3a643fcb (10.b) -> up ([5,0,10,8], p5) acting ([5,0,10,8], p5)
cephadmin@deploy:~$ 测试获取数据在终端显示,并把数据存入到/tmp/testfile1中
cephadmin@deploy:~$ rados --pool erasure-testpool get testfile1 -
cephadmin@deploy:~$ sudo rados get -p erasure-testpool testfile1 /tmp/testfile1
cephadmin@deploy:~$ tail /tmp/testfile1
Sep 7 15:10:01 deploy CRON[25976]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:10:42 deploy systemd[1]: Started Session 518 of user ubuntu.
Sep 7 15:11:01 deploy CRON[26265]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:12:01 deploy CRON[26452]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:13:01 deploy CRON[26592]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:14:01 deploy CRON[26737]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:15:01 deploy CRON[26879]: (root) CMD (/usr/local/qcloud/YunJing/clearRules.sh > /dev/null 2>&1)
Sep 7 15:15:01 deploy CRON[26880]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:15:01 deploy CRON[26882]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
Sep 7 15:16:01 deploy CRON[27063]: (root) CMD (flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &')
cephadmin@deploy:~$
PG与PGP
PG = Placement Group #归置组,默认每个PG三个OSD(数据三个副本)
PGP = Placement Group for Pkacement purpose #归置组的组合,pgp相当于是pg对应osd的一种逻辑排列组合关系(在不同的PG内使用不同组合关系的OSD)
osd的一种逻辑排列组合关系(在不同的PG内使用不同组合关系的OSD)
假如PG=32,PGP=32,那么数据最多被拆分成32份(PG),写入到又32种组合关系(PGP)的OSD上
PG分配计算
归置组(PG)的数量是由管理员在创建存储池的时候指定的,然后由CRUSH负载创建盒使用,PG的数量是2的N次方倍数,每个OSD的PG不要超过250个PG,官方是每个OSD100个左右
存储池管理常用命令
创建存储池
ceph osd pool create <poolname> pg_num pgp_num {replicated|erasure} #默认是replicated列出存储池
ceph osd pool ls [detail]
ceph osd lspools获取存储池的事件信息
ceph osd pool stats mypool重命名存储池
ceph osd pool rename pld-name new-name
ceph osd pool rename myrbd1 myrbd2显示存储池的用量信息
rados df存储池的删除
nodelete为false可以删除,为true不可以删除
cephadmin@deploy:~$ ceph osd pool create mypool2 32 32
pool 'mypool2' created
cephadmin@deploy:~$ ceph osd pool get mypool2 nodelete
nodelete: false
cephadmin@deploy:~$ ceph osd pool set mypool2 nodelete true
set pool 11 nodelete to true
cephadmin@deploy:~$ ceph osd pool get mypool2 nodelete
nodelete: true第二种删除方法,--mon-allow-pool-delete=false时可以删除,删除完后将参数改为true
cephadmin@deploy:~$ ceph osd pool rm mypool2 mypool2 --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
cephadmin@deploy:~$ ceph tell mon.* injectargs --mon-allow-pool-delete=true
mon.mon1: {}
mon.mon1: mon_allow_pool_delete = 'true'
mon.mon2: {}
mon.mon2: mon_allow_pool_delete = 'true'
mon.mon3: {}
mon.mon3: mon_allow_pool_delete = 'true'
cephadmin@deploy:~$ ceph osd pool rm mypool2 mypool2 --yes-i-really-really-mean-it
pool 'mypool2' removed
cephadmin@deploy:~$ ceph tell mon.* injectargs --mon-allow-pool-delete=false存储池配额,默认不限制
cephadmin@deploy:~$ ceph osd pool get-quota mypool
quotas for pool 'mypool':
max objects: N/A
max bytes : N/A默认将最大对象数量设置为1000,最大空间为512M
cephadmin@deploy:~$ ceph osd pool set-quota mypool max_objects 1000
set-quota max_objects = 1000 for pool mypool
cephadmin@deploy:~$ ceph osd pool set-quota mypool max_bytes 537395200
set-quota max_bytes = 537395200 for pool mypool
cephadmin@deploy:~$ ceph osd pool get-quota mypool
quotas for pool 'mypool':
max objects: 1k objects (current num objects: 0 objects)
max bytes : 512 MiB (current num bytes: 0 bytes)设置副本熟,默认为3,改为4
cephadmin@deploy:~$ ceph osd pool get mypool size
size: 3
cephadmin@deploy:~$ ceph osd pool set mypool size 4
set pool 2 size to 4
cephadmin@deploy:~$ ceph osd pool get mypool size
size: 4最小副本数
cephadmin@deploy:~$ ceph osd pool get mypool min_size
min_size: 2
cephadmin@deploy:~$ ceph osd pool set mypool min_size 1
set pool 2 min_size to 1
cephadmin@deploy:~$ ceph osd pool get mypool min_size
min_size: 1修改PG
cephadmin@deploy:~$ ceph osd pool get mypool pg_num
pg_num: 32
cephadmin@deploy:~$ ceph osd pool set mypool pg_num 64
set pool 2 pg_num to 64修改PGP
cephadmin@deploy:~$ ceph osd pool set mypool pgp_num 64
set pool 2 pgp_num to 64
cephadmin@deploy:~$ ceph osd pool get mypool pgp_num
pgp_num: 64设置crush算法规则
crush_rule: replicated_rule 默认为副本池
ceph osd pool get mypool crush_rule控制是否可更改存储池的pg num和pgp num
ceph osd pool get mypool nopgchangenosizechange: 控制是否可以更改存储池的大小
nosizechange: false 默认允许修改存储池的大小
ceph osd pool get mypool nosizechange
noscrub和nodeep-scrub:控制是否不进行轻量扫描或是否深层扫描存储池,可临时解决高I/O问题
noscrub: false 查看当前是否关闭轻量扫描数据,默认为不关闭,即开启
set pool 1 noscrub to true 可以修改某个指定的pool的轻量级扫描测量为true,即不执行轻量级扫描
noscrub: true再次查看就不进行轻量级扫描了
ceph osd pool get mypool noscrub
ceph osd pool set mypool noscrub true
ceph osd pool get mypool noscrub
nodeep-scrub:false 查看当前是否关闭深度扫描数据,默认为不关闭,即开启
set pool 1 nodeep-scrub to true 可以修改某个指定的pool的深度扫描测量为true,即不执行深度扫描
nodeep-scrub: true再次查看就不进行轻量级扫描了
ceph osd pool get mypool nodeep-scrub
ceph osd pool set mypool nodeep-scrub true
ceph osd pool get mypool nodeep-scrub
查看深度扫描和轻量扫描参数,如果修改的话直接在deploy set
root@node2:~# ceph daemon osd.3 config show | grep scrub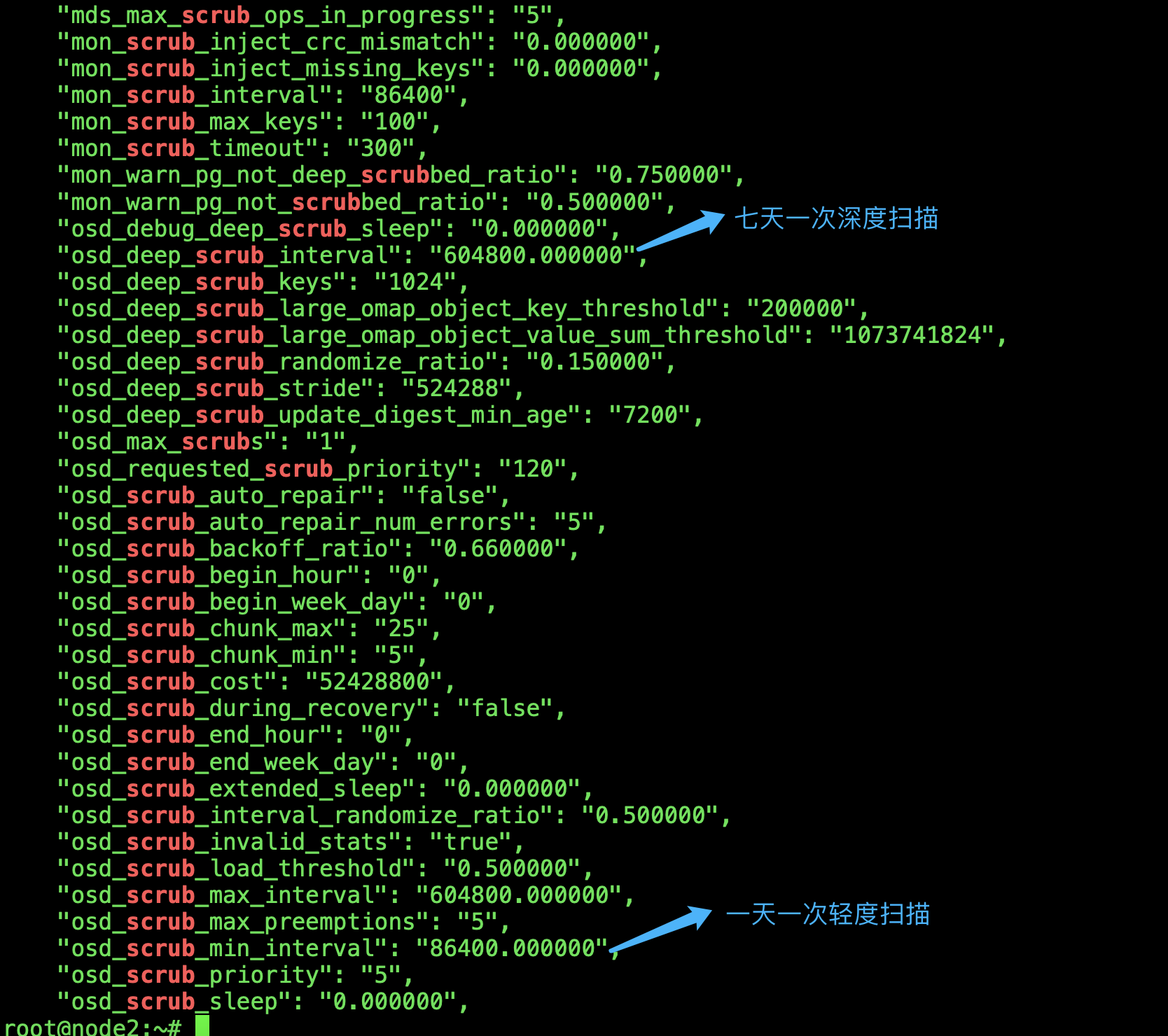
存储池快照
创建快照两种办法 ceph和rados
cephadmin@deploy:~$ ceph osd pool ls
device_health_metrics
mypool
myrbd1
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta
cephfs-metadata
cephfs-data
erasure-testpool
cephadmin@deploy:~$ ceph osd pool mksnap mypool mypool-snap
created pool mypool snap mypool-snap
cephadmin@deploy:~$ rados -p mypool mksnap mypool-snap2
created pool mypool snap mypool-snap2验证快照
cephadmin@deploy:~$ rados lssnap -p mypool
1 mypool-snap 2022.09.07 18:05:08
2 mypool-snap2 2022.09.07 18:05:34
2 snaps回滚快照
cephadmin@deploy:~$ rados -p mypool put testfile /etc/hosts #上传一个文件
cephadmin@deploy:~$ rados -p mypool ls
testfile
cephadmin@deploy:~$ ceph osd pool mksnap mypool mypool-snapshot001 #制作快照
created pool mypool snap mypool-snapshot001
cephadmin@deploy:~$ rados lssnap -p mypool #查看快照
1 mypool-snap 2022.09.07 18:05:08
2 mypool-snap2 2022.09.07 18:05:34
3 mypool-snapshot001 2022.09.07 18:09:29
3 snaps
cephadmin@deploy:~$ rados -p mypool rm testfile #删除上传的文件
cephadmin@deploy:~$ rados -p mypool rm testfile #再次删除
error removing mypool>testfile: (2) No such file or directory
cephadmin@deploy:~$ rados rollback -p mypool testfile mypool-snapshot001 #恢复快照
rolled back pool mypool to snapshot mypool-snapshot001
cephadmin@deploy:~$ rados -p mypool rm testfile #再次删除就可以删了删除快照
cephadmin@deploy:~$ ceph osd pool rmsnap mypool mypool-snap
removed pool mypool snap mypool-snap
数据压缩(不建议开启)影响cpu速率
aggressive: 压缩的模式,有none、aggressive、passive 和 force, 默认 none。
none:从不压缩数据。
passive:除非写操作具有可压缩的提示集
否则不要压缩数据
aggressive: 压缩数据,除非写操作具有不可压缩的提示集。
force:无论如何都尝试压缩数据,即使客户端暗示数据不可压缩也会压缩,也就是在所有
情况下都使用压缩。

修改压缩模式
cephadmin@deploy:~$ ceph osd pool set mypool compression_mode passive
set pool 2 compression_mode to passive
cephadmin@deploy:~$ ceph osd pool get mypool compression_mode
compression_mode: passive修改压缩算法
cephadmin@deploy:~$ ceph osd pool set mypool compression_algorithm snappy
set pool 2 compression_algorithm to snappy
cephadmin@deploy:~$ ceph osd pool get mypool compression_algorithm
compression_algorithm: snappy
