剑指Java面试-Offer直通车 百度资深面试官授课1
第2章 计算机网络面试核心
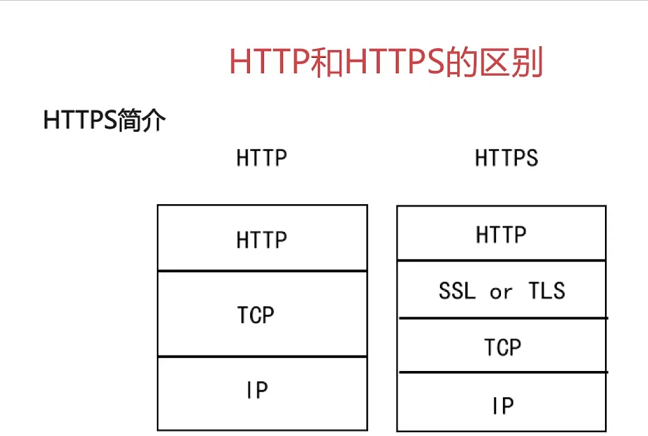
http 超文本传输协议是应用层协议无状态的
1.0版本 主流是1.1版本相对于1.0版本的主要区别是持续链接机制是connection:keepalive 应用较少的2.0
输入url 后续流程
Dns解析->tcp连接->发送http请求->服务器处理请求并返回http报文->浏览器解析并渲染页面—>连接结束
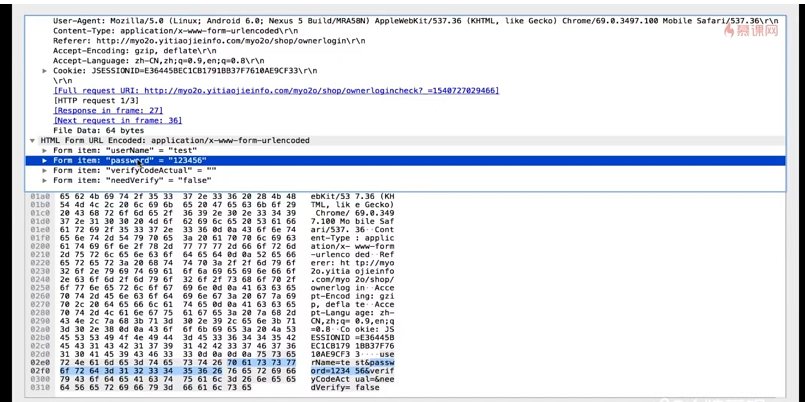
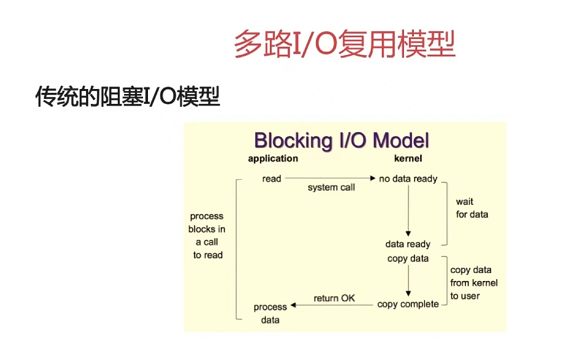
tcpdump+wireshark抓包”骚”操作



http并没有规定url的长度是各大浏览器厂商规定的长度






第3章 数据库
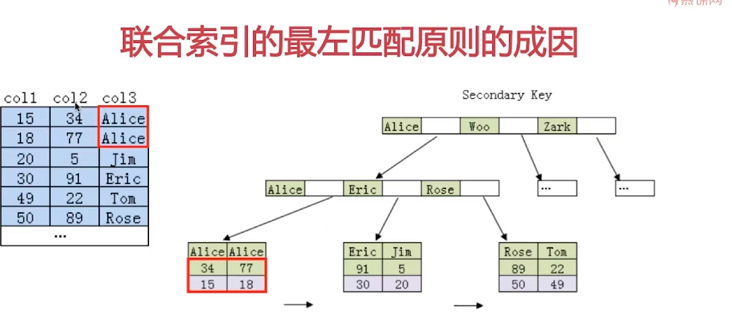
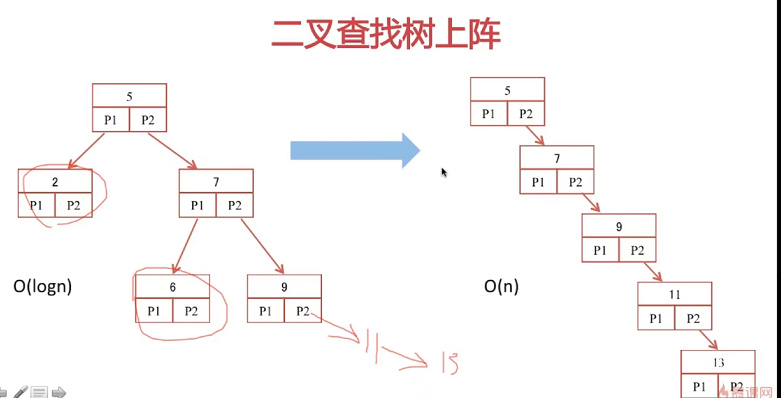 极端情况下退化为右边的结构
极端情况下退化为右边的结构

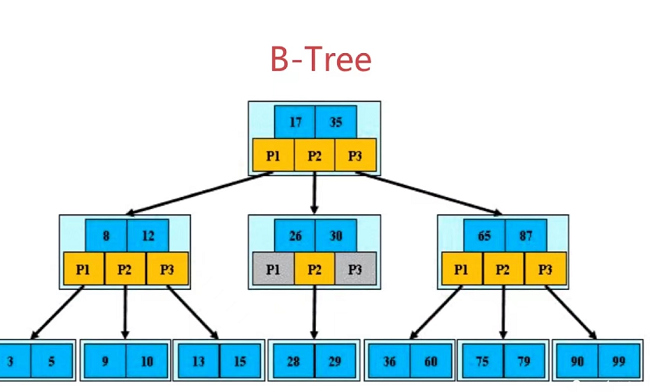

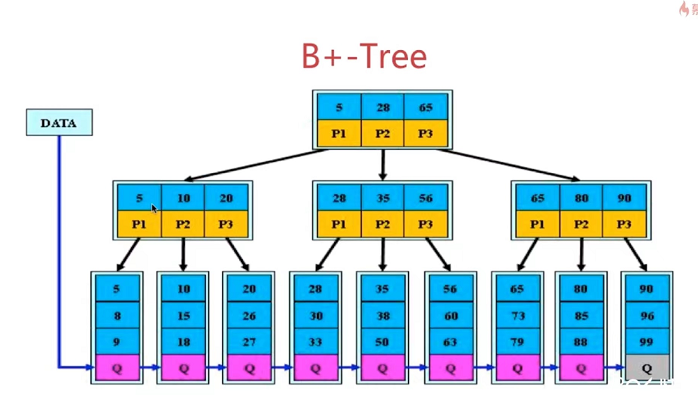




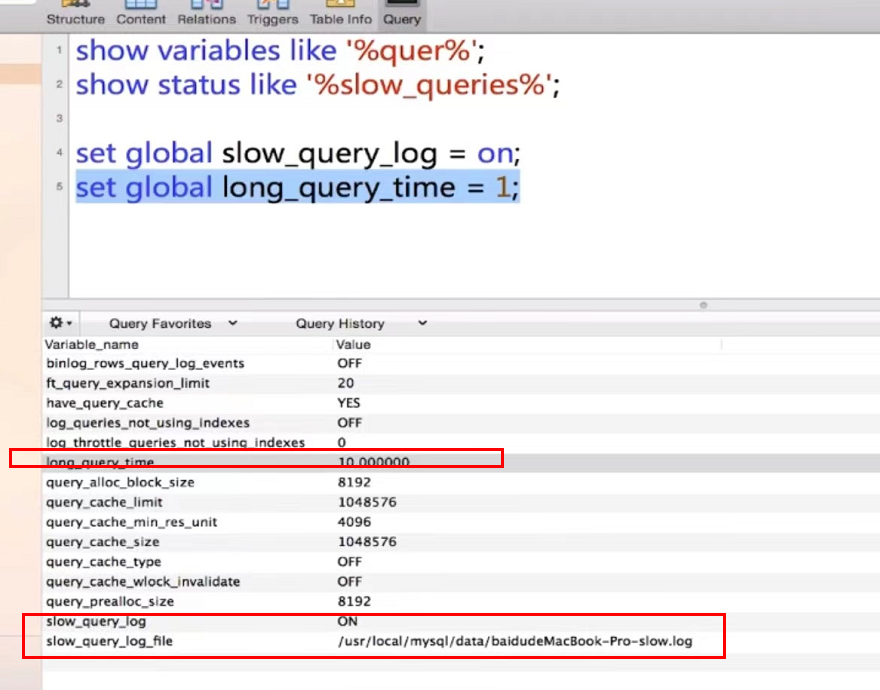





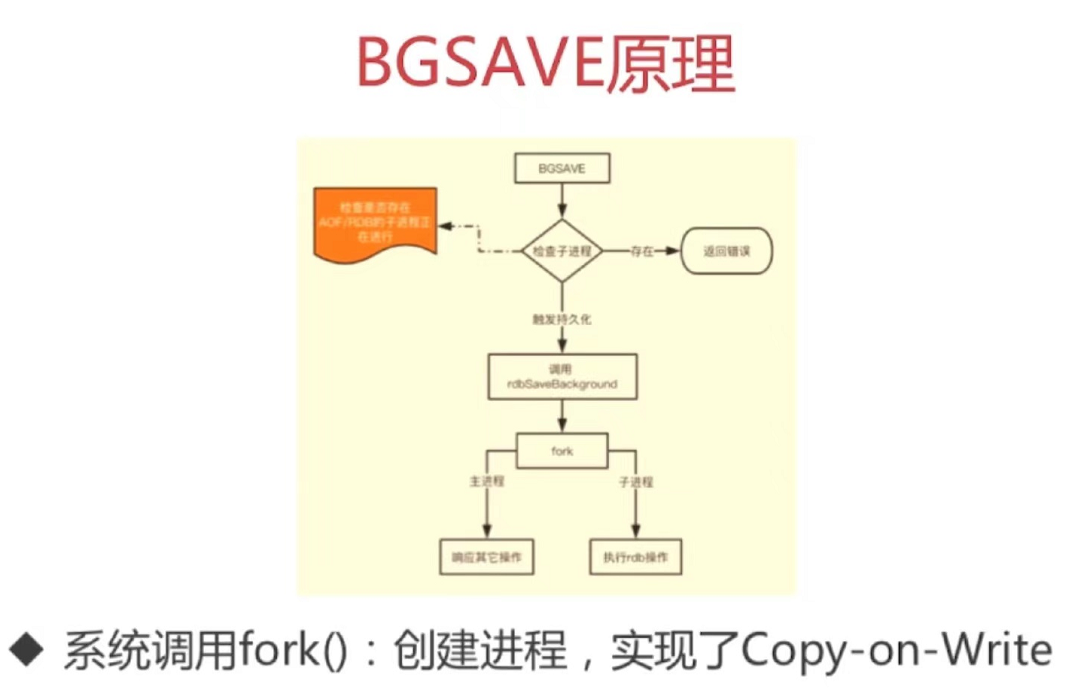
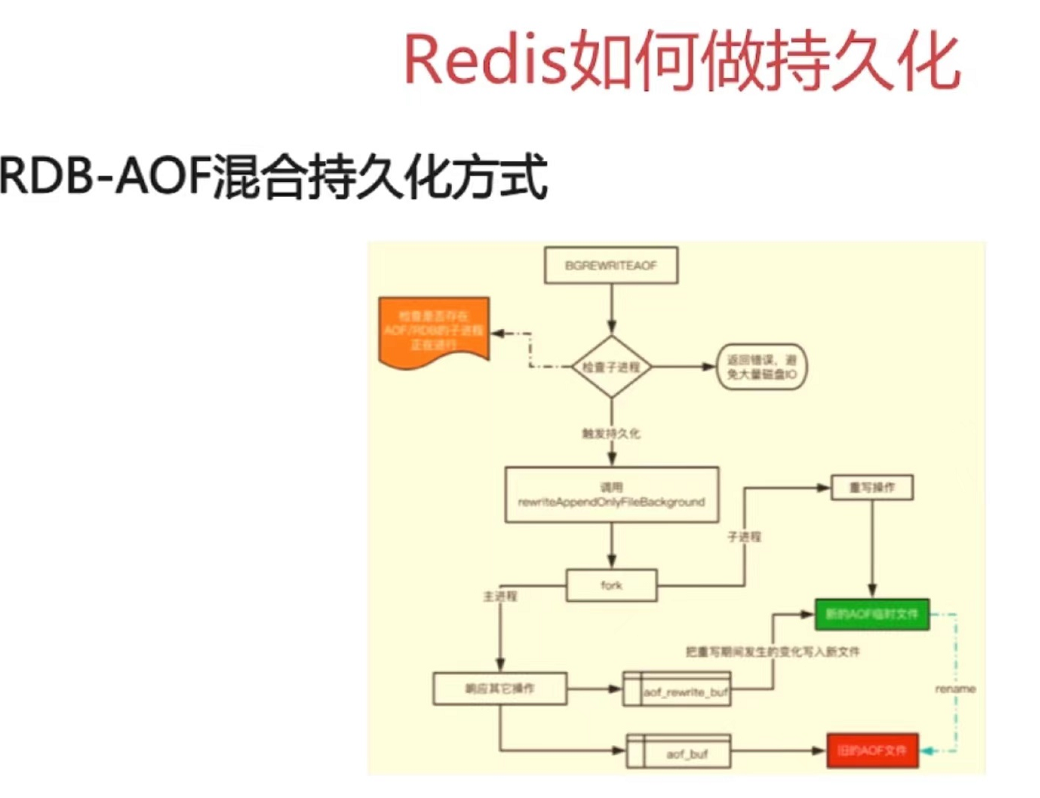
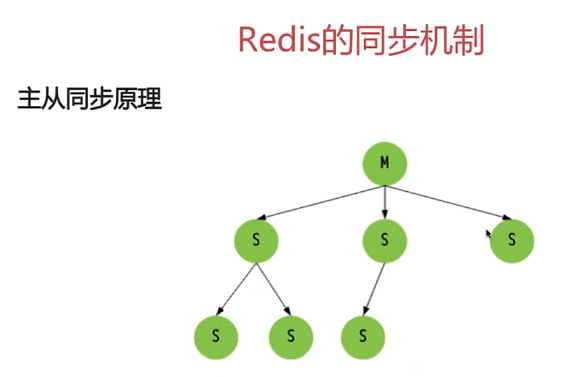
4章 Redis







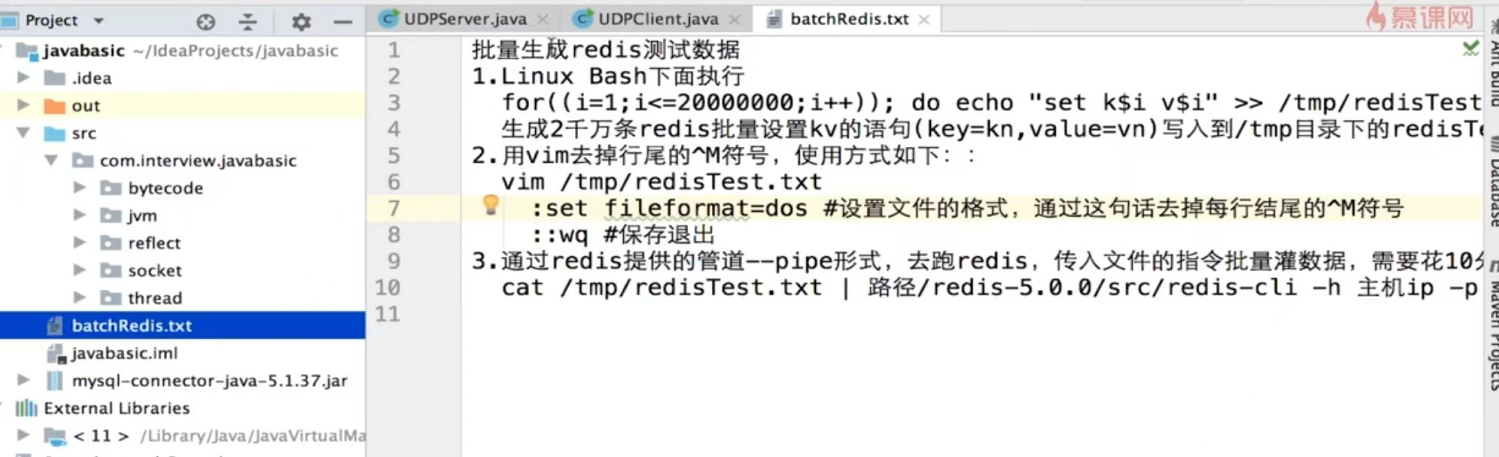
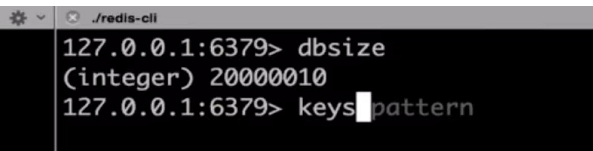
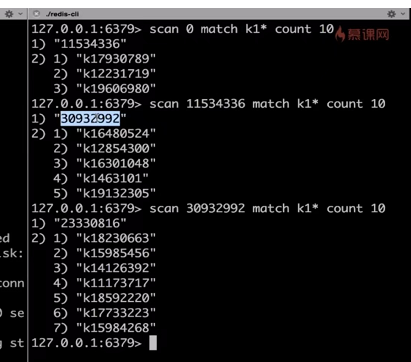
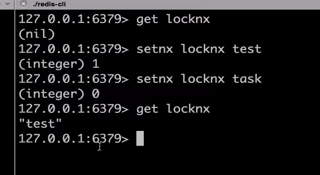
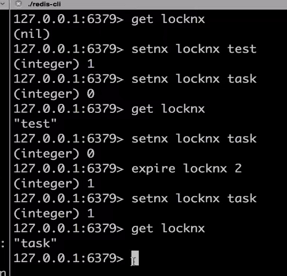
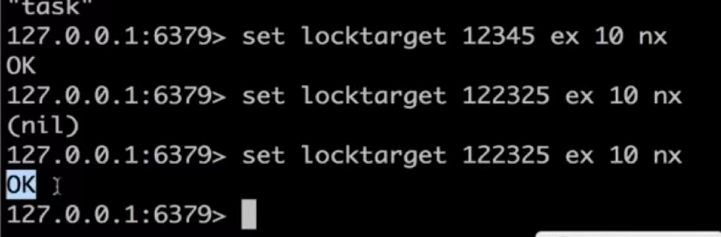
造测试数据





















1:Java特性
(1)平台无关性
一次编译到处运行
(2)GC
垃圾回收机制
(3)语言特性
泛型-反射机制-lambda表达式
(4)面向对象
面向对象语言-三大特性(封装,继承,多态)
(5)类库
集合库,并发库,网络,
(6)异常处理
自定义异常
2:
javac 编译源代码为字节码
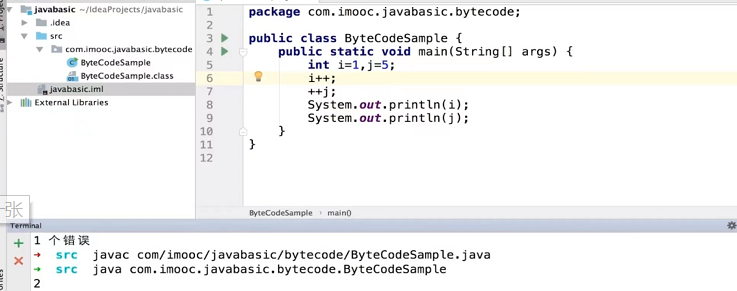
javap 反编译字节码
二、Java怎样实现一次编译到处运行(平台无关性)
1.java平台无关性原理
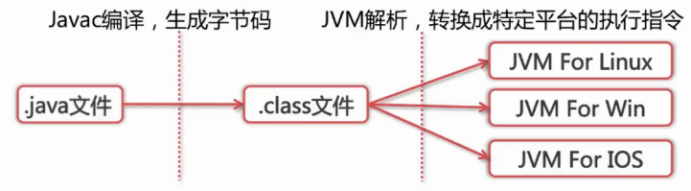
Java源码首先被编译成字节码,再由不同平台的JVM进行解析,JAVA语言在不同的平台上运行时不需要进行重新编译,Java虚拟机在执行字节码的时候,把字节码转换成具体平台上的机器指令。
2.为什么JVM不直接将源码进行编译成机器码去执行
(1)准备工作太过繁琐
JVM每次进行编译的时候都会对源代码进行各种检查,纠错
(2)兼容性
JVM不仅仅可以给java语言编译成的class文件进行解释,还可以对任何语言,只要是解释为.class字节码都可以解释
3.查看(.class)字节码
(1)准备一个简单的java文件

package com.interview.javabasic.bytecode;
public class ByteCodeSample {
public static void main(String[] args) {
int i=1,j=5;
i++;
++j;
System.out.println(i);
System.out.println(j);
}
}
(2)javac进行编译成.class文件
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.interview.javabasic.bytecode;
public class ByteCodeSample {
public ByteCodeSample() {
}
public static void main(String[] var0) {
byte var1 = 1;
byte var2 = 5;
int var3 = var1 + 1;
int var4 = var2 + 1;
System.out.println(var3);
System.out.println(var4);
}
}
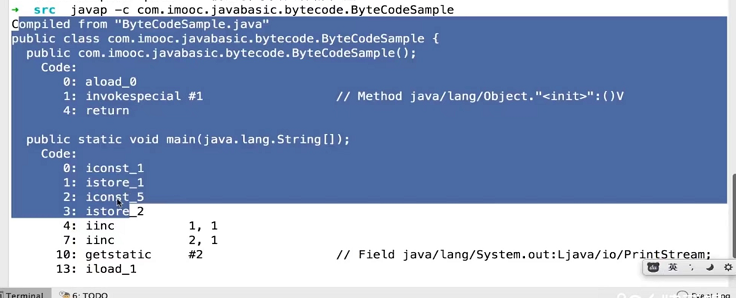
(3)通过javap指令查看.class文件反编译代码

Compiled from "ByteCodeSample.java"
public class com.interview.javabasic.bytecode.ByteCodeSample {
public com.interview.javabasic.bytecode.ByteCodeSample();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: iconst_1
1: istore_1
2: iconst_5
3: istore_2
4: iinc 1, 1
7: iinc 2, 1
10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
13: iload_1
14: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
17: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
20: iload_2
21: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
24: return
}
3:
三、JVM如何加载.class文件
1.Java虚拟机的四个部分

2.通过类加载器(ClassLoader)加载.class

4:
四、什么是反射
1.反射理论

2.反射实践
(1)创建Robot类
public class Robot {
private String name;
public void sayHi(String helloSentence){
System.out.println(helloSentence + " " + name);
}
private String throwHello(String tag){
return "Hello " + tag;
}
static {
System.out.println("Hello Robot");
}
}

(2)各种操作
public class ReflectSample {
public static void main(String[] args) throws Exception{
Class rc = Class.forName("com.interview.javabasic.reflect.Robot");
Robot r = (Robot) rc.newInstance();
System.out.println("Class name is " + rc.getName());
//调用私有方法rc.getDeclaredMethod
Method getHello = rc.getDeclaredMethod("throwHello", String.class);
getHello.setAccessible(true);
Object str = getHello.invoke(r, "Bob");
System.out.println("getHello result is " + str);
//调用PUBLIC方法rc.getMethod
Method sayHi = rc.getMethod("sayHi", String.class);
sayHi.invoke(r, "Welcome");
//设置私有属性
Field name = rc.getDeclaredField("name");
name.setAccessible(true);
name.set(r, "Alice");
sayHi.invoke(r, "Welcome");
}
}
5:ClassLoader

1.什么是ClassLoader

2.四种ClassLoader

3.自定义CLassLoader

(1)MyClassLoader
public class MyClassLoader extends ClassLoader {
private String path;
private String classLoaderName;
public MyClassLoader(String path, String classLoaderName) {
this.path = path;
this.classLoaderName = classLoaderName;
}
//用于寻找类文件
@Override
public Class findClass(String name) {
byte[] b = loadClassData(name);
return defineClass(name, b, 0, b.length);
}
//用于加载类文件
private byte[] loadClassData(String name) {
name = path + name + ".class";
InputStream in = null;
ByteArrayOutputStream out = null;
try {
in = new FileInputStream(new File(name));
out = new ByteArrayOutputStream();
int i = 0;
while ((i = in.read()) != -1) {
out.write(i);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return out.toByteArray();
}
}
原理还是通过ClassLoader中的deFineClass方法来获取Class类型对象,自定义的是路径
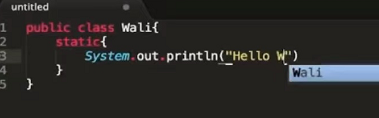

(2)实现ClassLoaderChecker
public class ClassLoaderChecker {
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
MyClassLoader m = new MyClassLoader("/Users/baidu/Desktop/", "myClassLoader");
Class c = m.loadClass("Wali");
c.newInstance();
}
}
(3)实现效果

4.类加载器的双亲委派机制
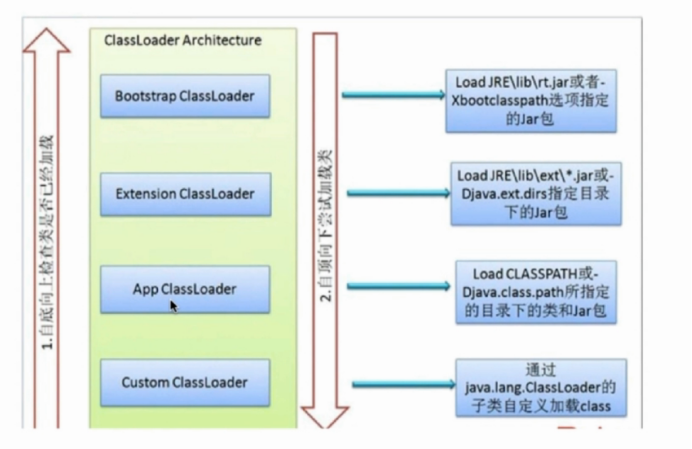
为什么要使用双亲委派机制来加载class文件-避免多份同样的字节码的加载
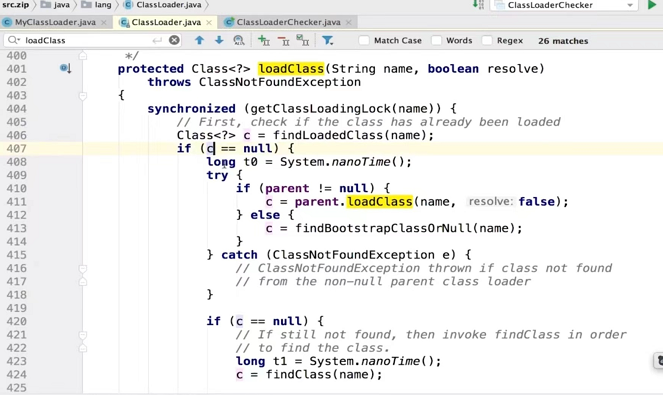
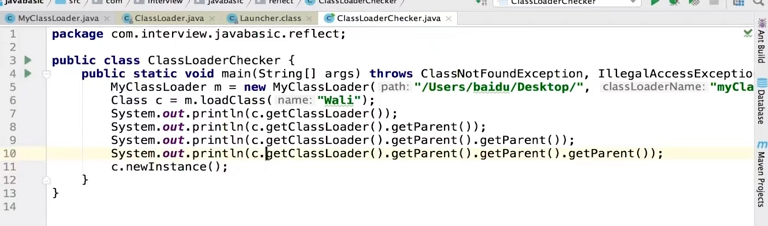

5.类的加载方式
隐式加载:new
显示加载:loadClass,formName
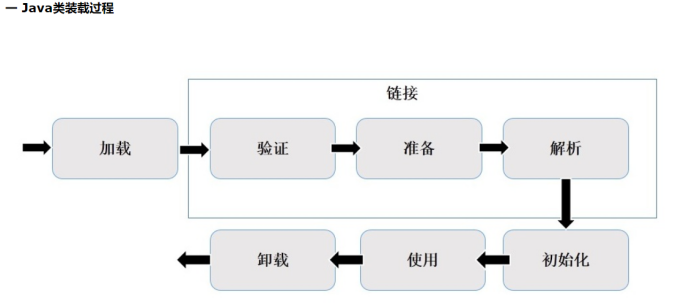
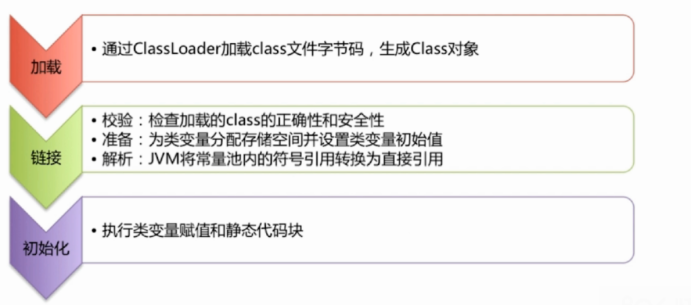
(1)类装载过程
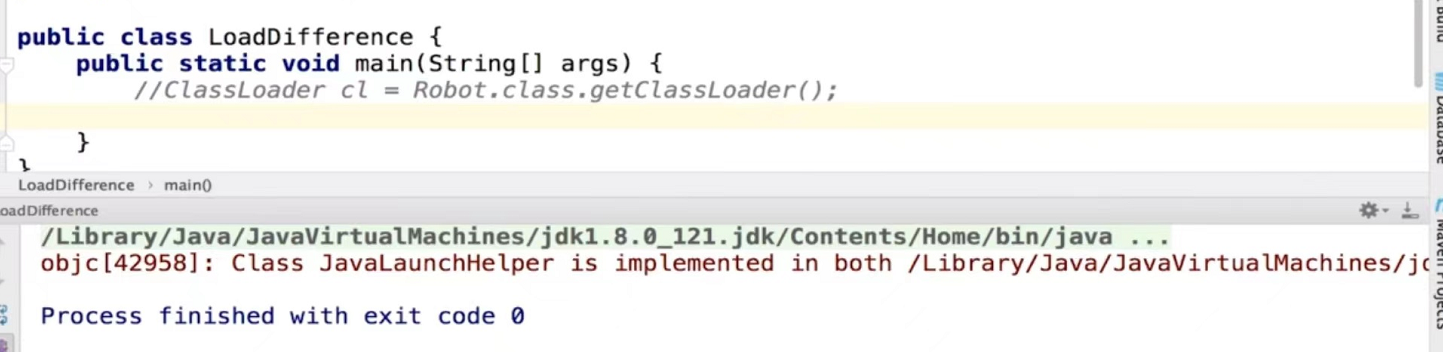
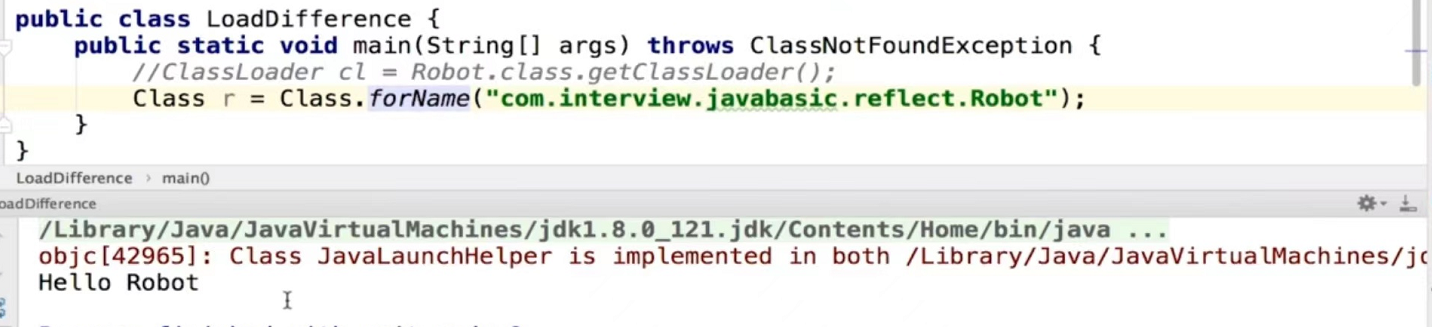
(2)代码实例区别
public class LoadDifference {
public static void main(String[] args) throws Exception {
//loadClass加载类,需要调用c.newInstance()才会加载类
ClassLoader cl = Robot.class.getClassLoader();
Class c = cl.loadClass("com.interview.javabasic.reflect.Robot");
c.newInstance();
//forName加载类,在加载类的时候会将Static静态代码块的代码实现出来
Class r = Class.forName("com.interview.javabasic.reflect.Robot");
}
}
使用Class.forName(classname)才能在反射回去类的时候执行static块。(3)数据库链接为什么使用Class.forName(className)
Class.forName得到的class是已经初始化完成的
classloder.loadclass得到的class是还没有链接的 主要可以用在ioc spring对象依赖注入 懒加载机制





6:

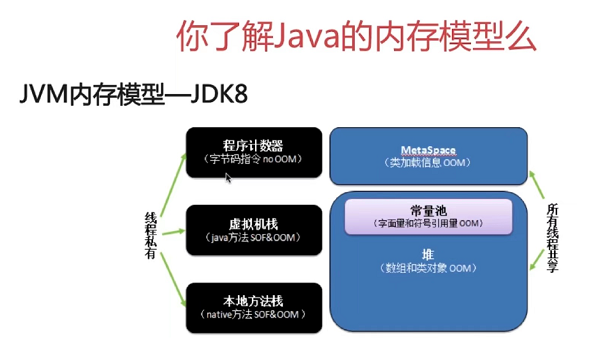
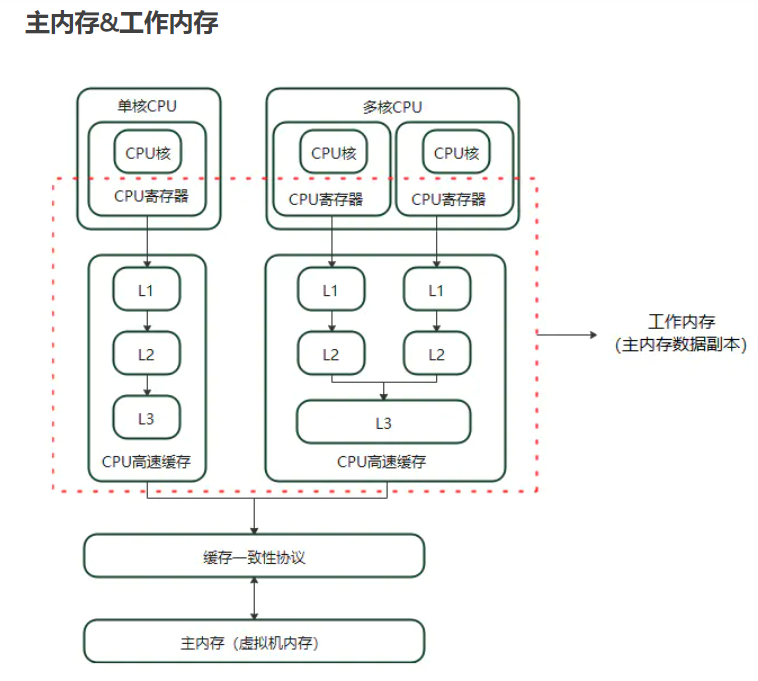
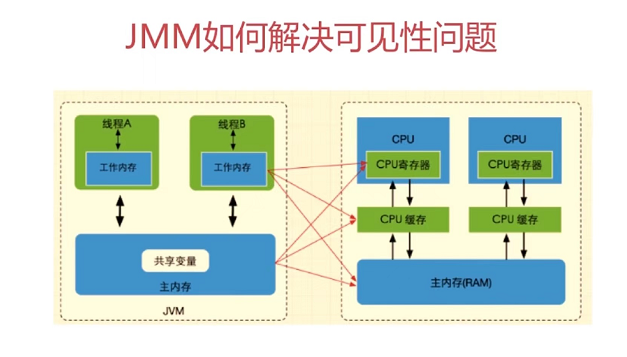
六、java内存模型
1.线程独占部分
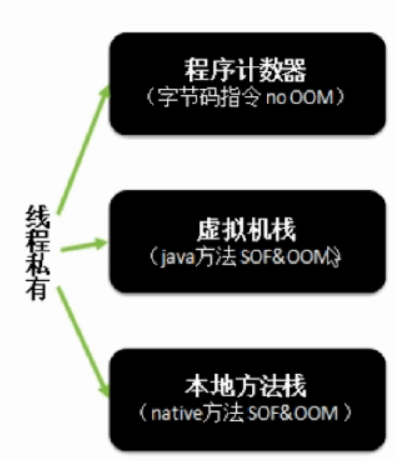
(1)程序计数器

(2)Java虚拟机栈
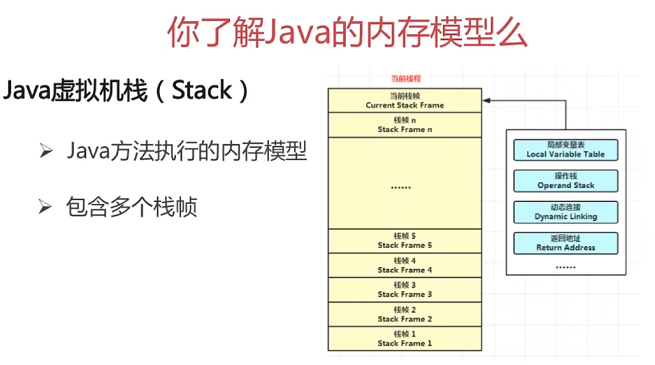

Java 虚拟机栈的定义
Java 虚拟机栈是描述 Java 方法运行过程的内存模型。
Java 虚拟机栈会为每一个即将运行的 Java 方法创建一块叫做“栈帧”的区域,用于存放该方法运行过程中的一些信息,如:
- 局部变量表
- 操作数栈
- 动态链接
- 方法出口信息
- ......

压栈出栈过程
当方法运行过程中需要创建局部变量时,就将局部变量的值存入栈帧中的局部变量表中。
Java 虚拟机栈的栈顶的栈帧是当前正在执行的活动栈,也就是当前正在执行的方法,PC 寄存器也会指向这个地址。只有这个活动的栈帧的本地变量可以被操作数栈使用,当在这个栈帧中调用另一个方法,与之对应的栈帧又会被创建,新创建的栈帧压入栈顶,变为当前的活动栈帧。
方法结束后,当前栈帧被移出,栈帧的返回值变成新的活动栈帧中操作数栈的一个操作数。如果没有返回值,那么新的活动栈帧中操作数栈的操作数没有变化。
由于Java 虚拟机栈是与线程对应的,数据不是线程共享的,因此不用关心数据一致性问题,也不会存在同步锁的问题。
Java 虚拟机栈的特点

- 局部变量表随着栈帧的创建而创建,它的大小在编译时确定,创建时只需分配事先规定的大小即可。在方法运行过程中,局部变量表的大小不会发生改变。
-
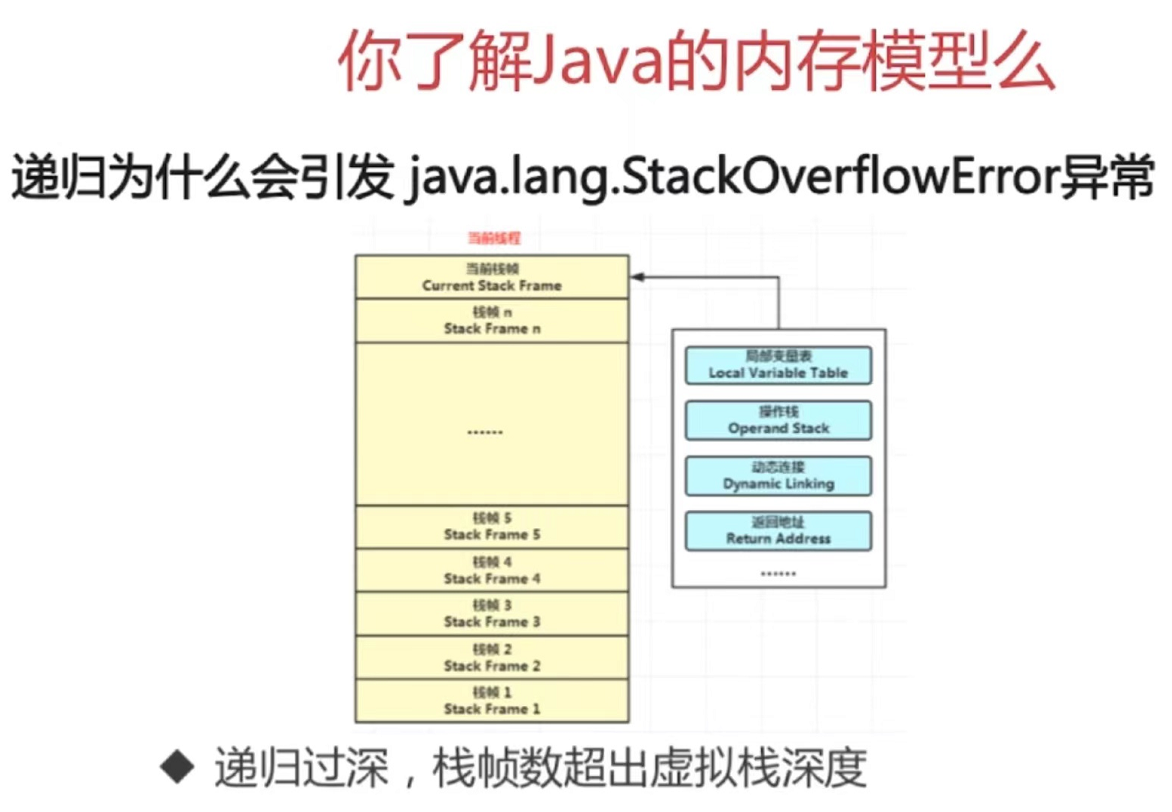
Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError。
- StackOverFlowError
当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度时,抛出 StackOverFlowError 异常。递归调用的时候可能会出现,递归调用过深,栈帧数超过虚拟机栈最大深度
- OutOfMemoryError
当线程请求栈时内存用完了,无法再动态扩展时,抛出 OutOfMemoryError 异常。
- Java 虚拟机栈也是线程私有,随着线程创建而创建,随着线程的结束而销毁。
出现 StackOverFlowError 时,内存空间可能还有很多。
(3)本地方法栈

(4)递归为什么会引发java.lang.StackOverFlowError异常吗

2.线程共享部分
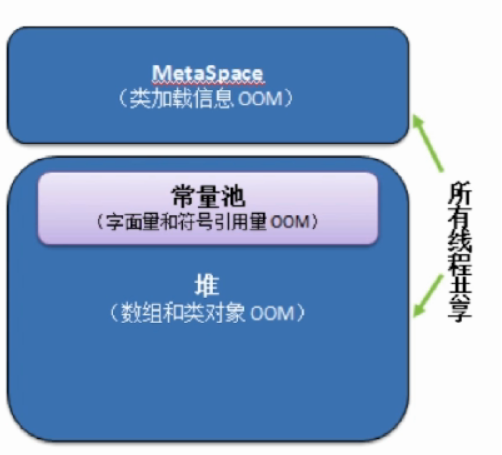
(1)MetaSpace和PermGen本质区别


(2)java堆
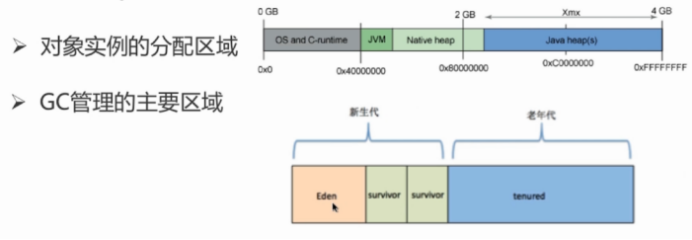
jvm 三大性能调优参数
-Xss规定了每个线程虚拟机栈(堆栈)的大小。一般情况下256K是足够了。影响了此进程中并发线程数大小。
-Xms初始的Heap的大小。
-Xmx最大Heap的大小。
在很多情况下,-Xms和-Xmx设置成一样的。这么设置,是因为当Heap不够用时,会发生内存抖动,影响程序运行稳定性。


1.静态 Static
指在编译时就能确定的每个数据目标在运行时刻需要的存储空间需求。因而在编译的时候就可以给他们分配固定的存储空间。 这种数据目标在编译时就为他们分配固定的内存。
限制:
- 代码中不能有可变数据结构,如数组。
- 代码中不允许有递归或嵌套结构的出现。
public class EaseConstant {
public static final String MESSAGE_ATTR_IS_VOICE_CALL = "is_voice_call";
public static final String MESSAGE_ATTR_IS_VIDEO_CALL = "is_video_call";
public static final String MESSAGE_ATTR_IS_BIG_EXPRESSION = "em_is_big_expression";
public static final String MESSAGE_ATTR_EXPRESSION_ID = "em_expression_id";
public static final String MESSAGE_ATTR_AT_MSG = "em_at_list";
public static final String MESSAGE_ATTR_VALUE_AT_MSG_ALL = "ALL";
public static final int CHATTYPE_SINGLE = 1;
public static final int CHATTYPE_GROUP = 2;
public static final int CHATTYPE_CHATROOM = 3;
public static final String EXTRA_CHAT_TYPE = "chatType";
public static final String EXTRA_USER_ID = "userId";
}
2.栈式 Stack
栈式存储分配可称为动态存储分配,是由一个类似于堆栈的运行栈来实现的,和静态存储分配相反,在栈式存储方案中,程序对数据区的需求在编译时是完全未知的,只有到运行的时候才能知道。
指在编译时不能确定大小,但在运行的时候能够确定,且规定在运行中进入一个程序模块时,就必须知道该模块所需要的数据区大小,才能为其分配内存,和我们在数据结构中所知道的栈一样,内存分配为e栈原则,先进后出的原则进行分配。
分配是在运行时执行的,但是大小是在编译时确定的;
特点:
在C/C++中,所有的方法调用都是通过栈来进行的,所有局部变量,形式参数都是从栈中分配内存空间的。
栈的分配和回收:
栈分配内存空间:从栈低向栈顶,依次存储;
栈回收内存空间:修改栈顶指针的位置,完成栈中内容销毁,这样的模式速度很快。
3.堆式 Heap
指编译时,运行时模块入口都不能确定存储要求的数据结构的内存分配。
比如可变长度的串和对象实例。
堆由大片的可利用的块或空闲组成,堆中的内存可以按照任意顺序分配和释放。
堆是在运行的时候,请求操作系统分配给自己内存,由于从操作系统管理的内存分配,所以在分配和销毁的时候都要占用时间,因此对的效率低下。

4. 堆和栈的比较
| 比较方面 | 堆 | 栈 |
|---|---|---|
| 功能的比较 | 存放对象 | 执行程序 |
| 存储内容 | new关键字创建的内容 | 局部变量,形式参数 |
| 存储速度 | 慢 | 快(所以用来执行程序) |
5.JVM中的堆栈
JVM是基于堆栈的虚拟机,JVM中的堆栈是两块不同的存储区域。
JVM为每个线程程都分配了一个堆和栈,所以对于java程序来说,程序的运行是通过对堆栈的操作来完成的。
| JVM 堆 | JVM 栈 |
|---|---|
| 是存储的单位 | 是运行时的单位 |
| JVM堆解决的是数据存储的问题,即数据怎么放、放在哪儿。 | JVM栈解决程序的运行问题,即程序如何执行,或者说如何处理数据; |
| JVM堆中存的是对象。 | JVM栈中存的是基本数据类型和JVM堆中对象的引用 |
一个对象的大小是不可估计的,或者说是可以动态变化的,但是在JVM栈中,一个对象只对应了一个4btye的引用(JVM堆JVM栈分离的好处:))。
可以看看下图,简单的程序,对应着元空间,堆,线程独占的联系:



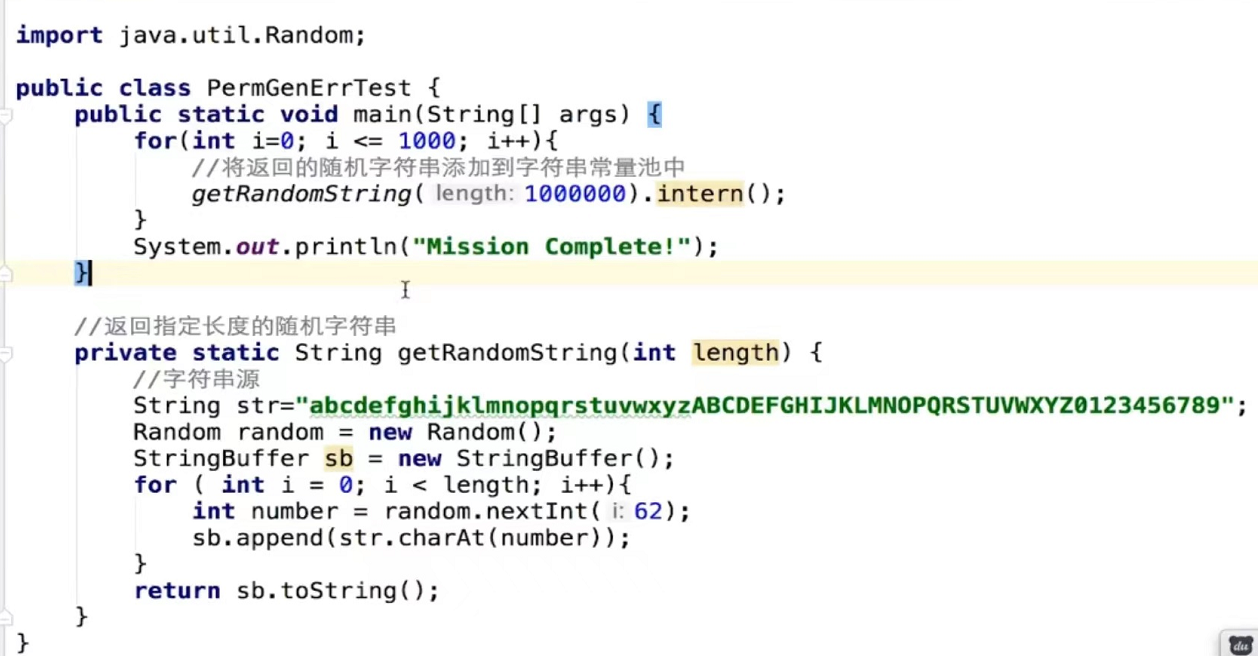

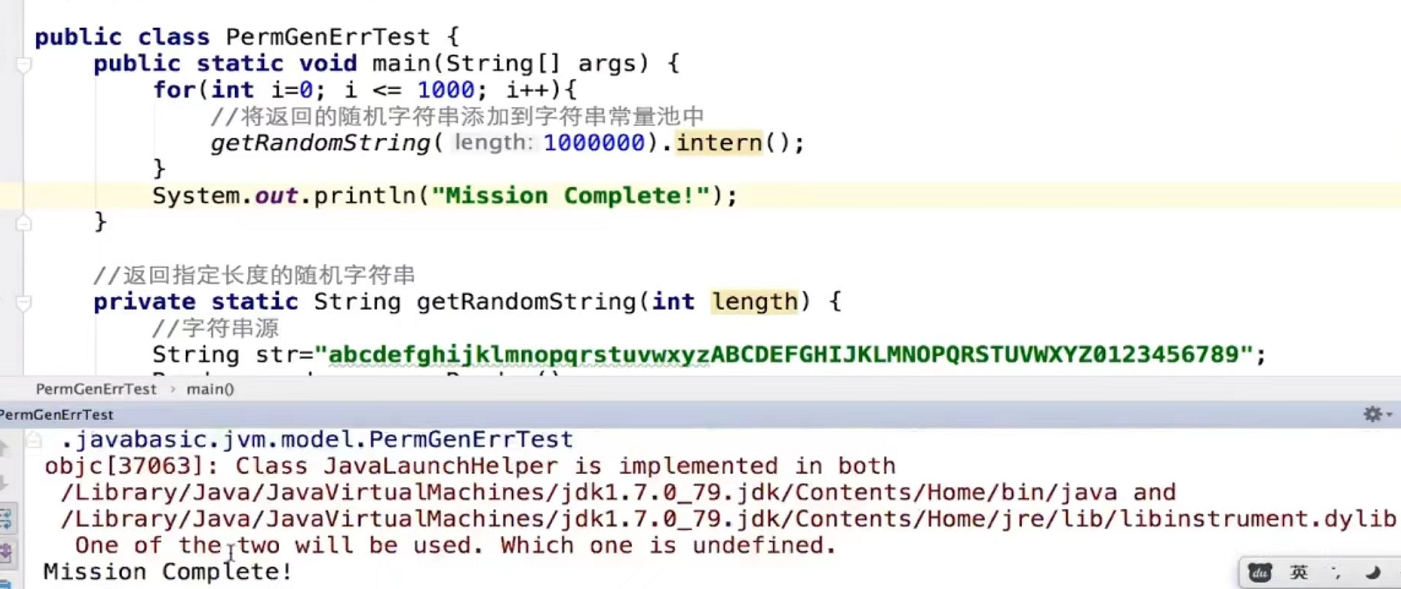
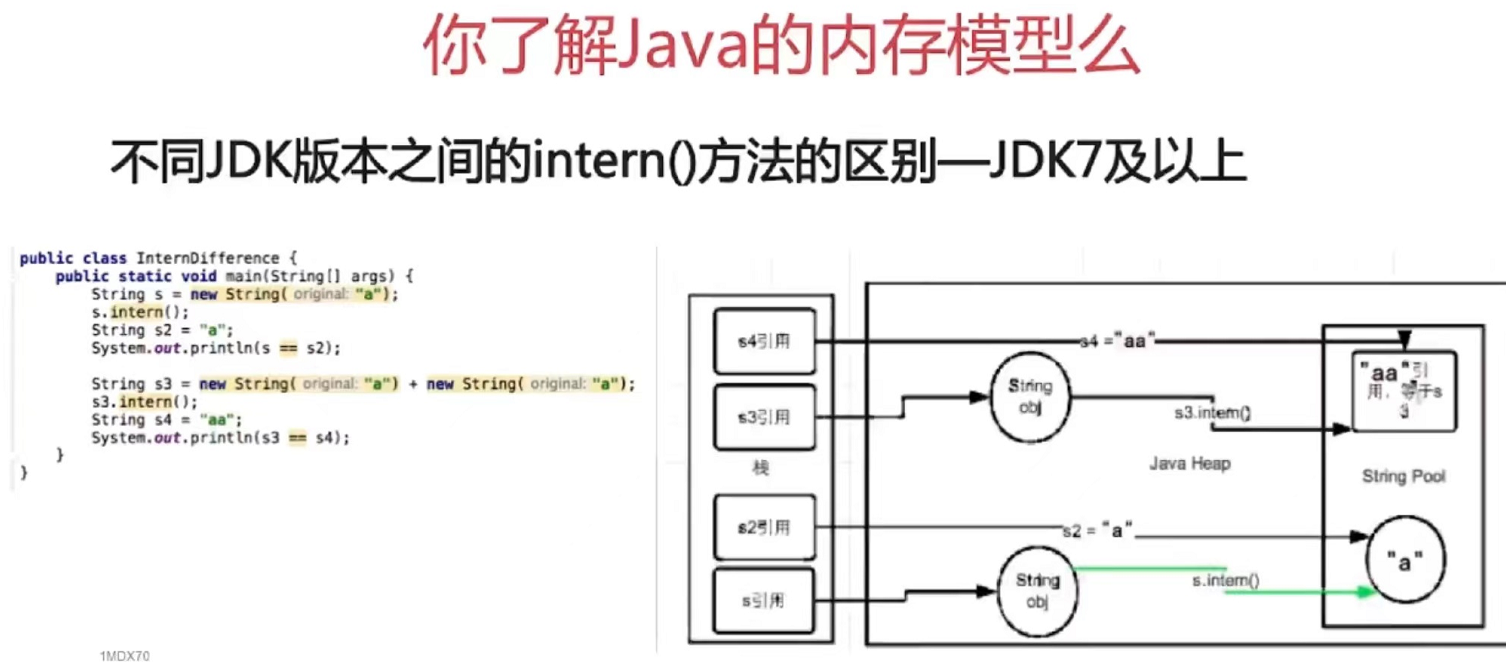
1.7的话就不会报错
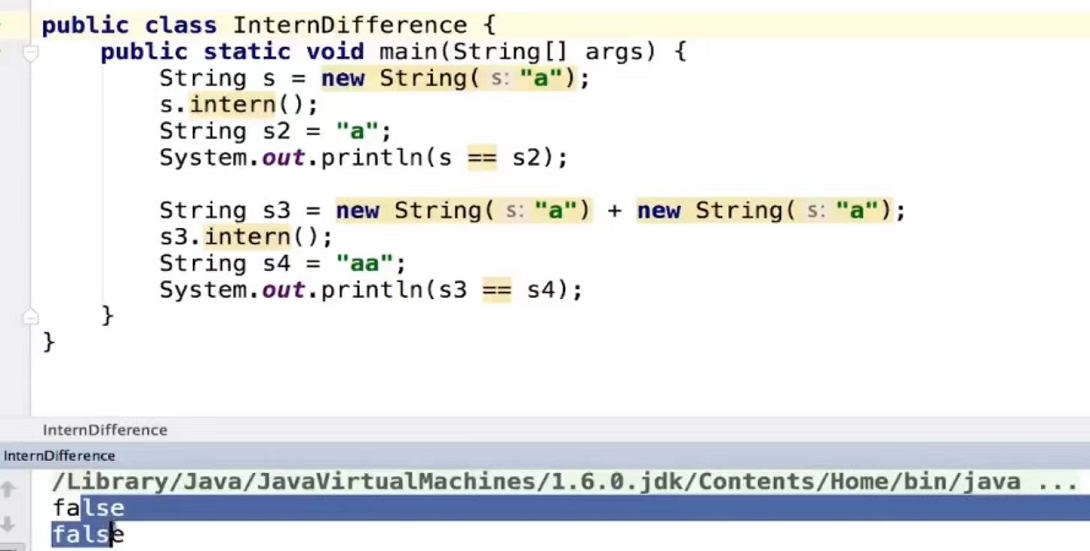
1.8版本已经移除


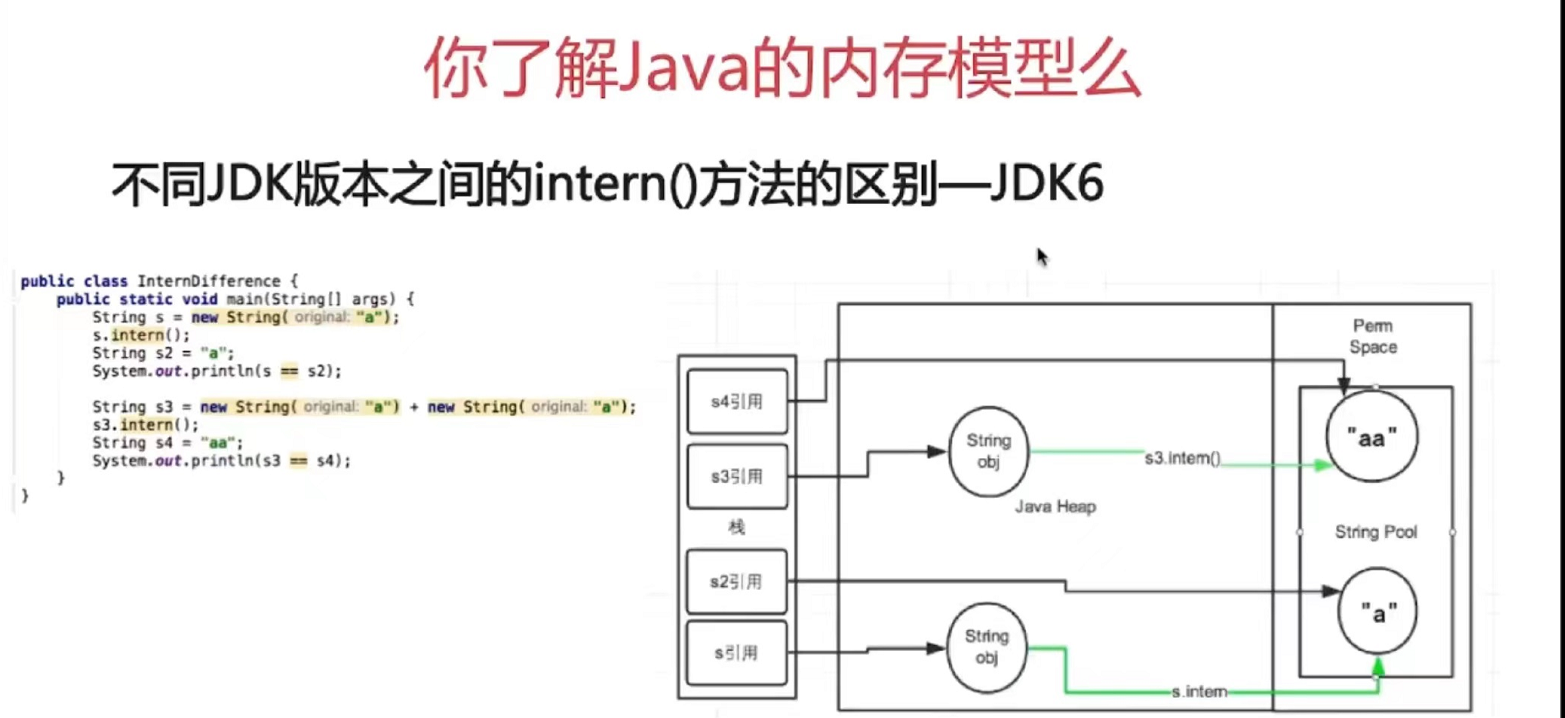
-Java多线程与并发
- 进程是资源分配的最小单位,线程是CPU调度的最小单位。


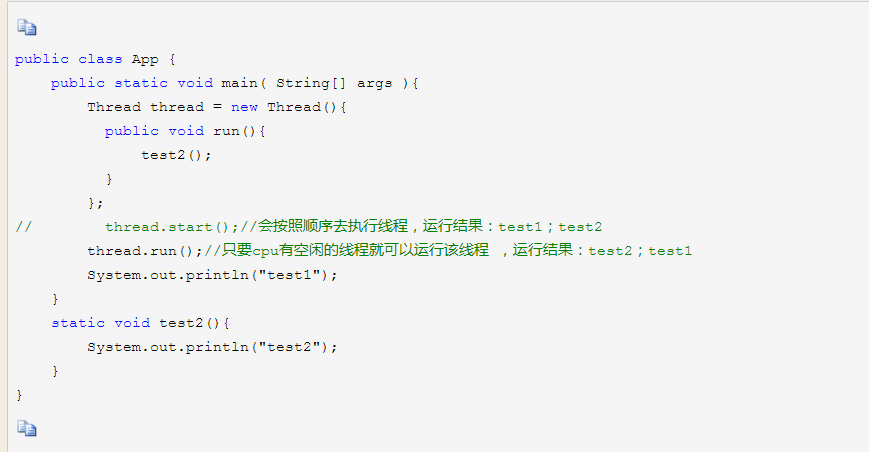
Thread中的start和run方法的区别
run()方法:
是在主线程中执行方法,和调用普通方法一样;(按顺序执行,同步执行)
start()方法:
是创建了新的线程,在新的线程中执行;(异步执行)
如何给run()方法传参
通过构造方法传递数据
通过成员变量和方法传递数据
通过回调函数传递数据
如何实现处理线程的返回值
- 主线程等待法;
- 使用Thread类的join方法阻塞当前线程以等待子线程处理完毕;
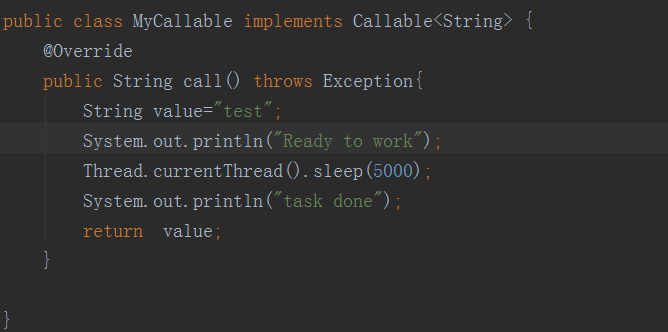
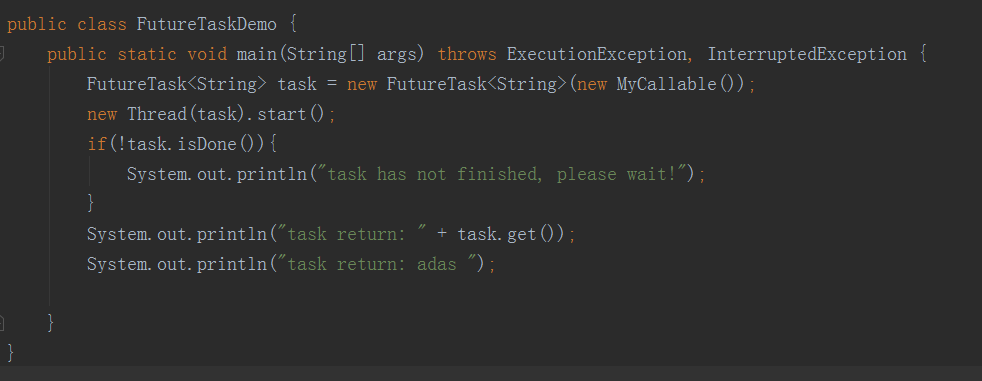
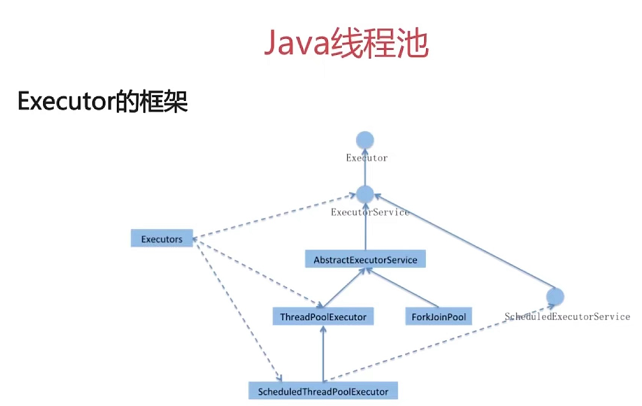
- 通过Callable接口实现,通过FutureTask 或者线程池;
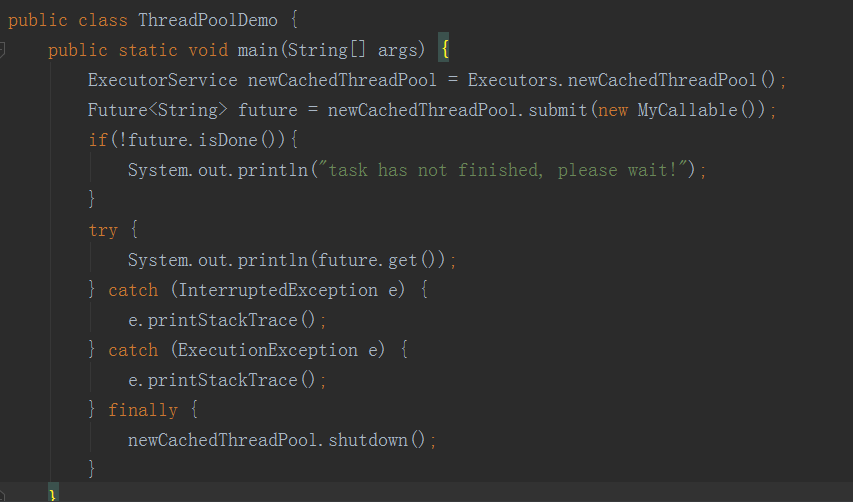
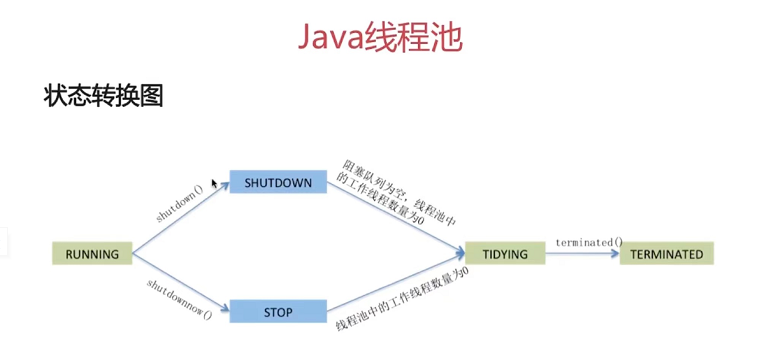
(一)线程的六种状态
1,sleep方法是Thread类的静态方法,wait()是Object超类的成员方法
2,sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。在调用sleep()方法的过程中,线程不会释放对象锁。
而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备
3,sleep方法需要抛异常,wait方法不需要
为什么sleep方法需要抛异常,别问我为什么,因为:
Thread类中sleep方法就已经进行了抛异常处理
public static native void sleep(long millis) throws InterruptedException;
4,sleep方法可以在任何地方使用,wait方法只能在同步方法和同步代码块中使用
---------------------
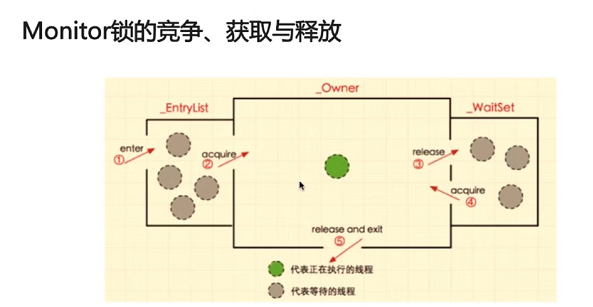
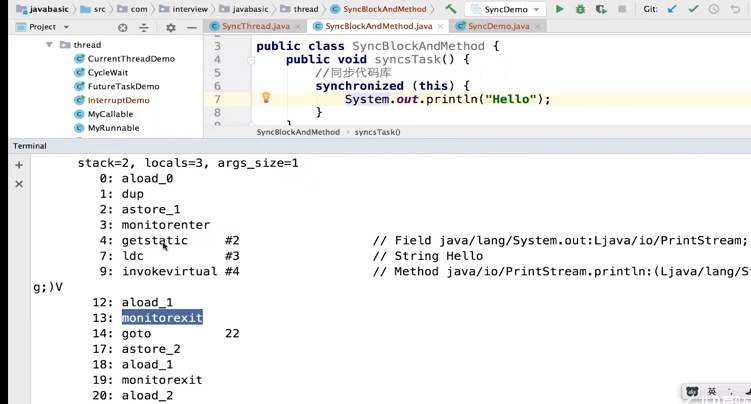
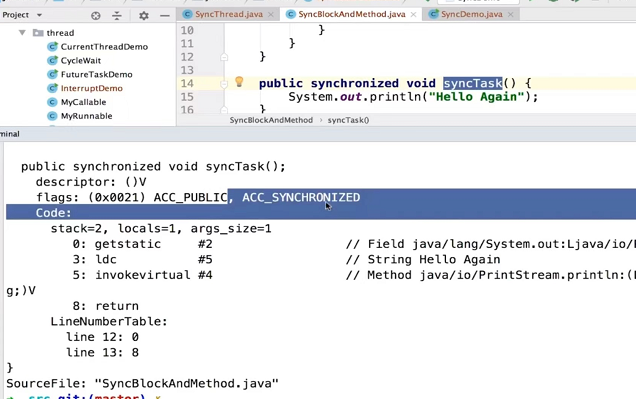
在Java中,每个对象都有两个池,锁(monitor)池和等待池
锁池:假设线程A已经拥有了某个对象(注意:不是类)的锁,而其它的线程想要调用这个对象的某个synchronized方法(或者synchronized块),由于这些线程在进入对象的synchronized方法之前必须先获得该对象的锁的拥有权,但是该对象的锁目前正被线程A拥有,所以这些线程就进入了该对象的锁池中。
等待池:假设一个线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁(因为wait()方法必须出现在synchronized中,这样自然在执行wait()方法之前线程A就已经拥有了该对象的锁),同时线程A就进入到了该对象的等待池中。如果另外的一个线程调用了相同对象的notifyAll()方法,那么处于该对象的等待池中的线程就会全部进入该对象的锁池中,准备争夺锁的拥有权。如果另外的一个线程调用了相同对象的notify()方法,那么仅仅有一个处于该对象的等待池中的线程(随机)会进入该对象的锁池.
---------------------
调用interrupt 通知该线程应该中断了
如果线程处于被阻塞状态,那么线程将立即退出被阻塞的状态,并抛出一个interruptedexception异常
如果线程处于正常活动状态,那么会将该线程的中断标志位设置为true,被设置中断标志的线程将继续正常运行,不受影响
当调用Thread.yield( )方法时 会给线程调度器一个当前线程愿意让出cpu的暗示,但线程调度器可以忽略这个暗示
第九章







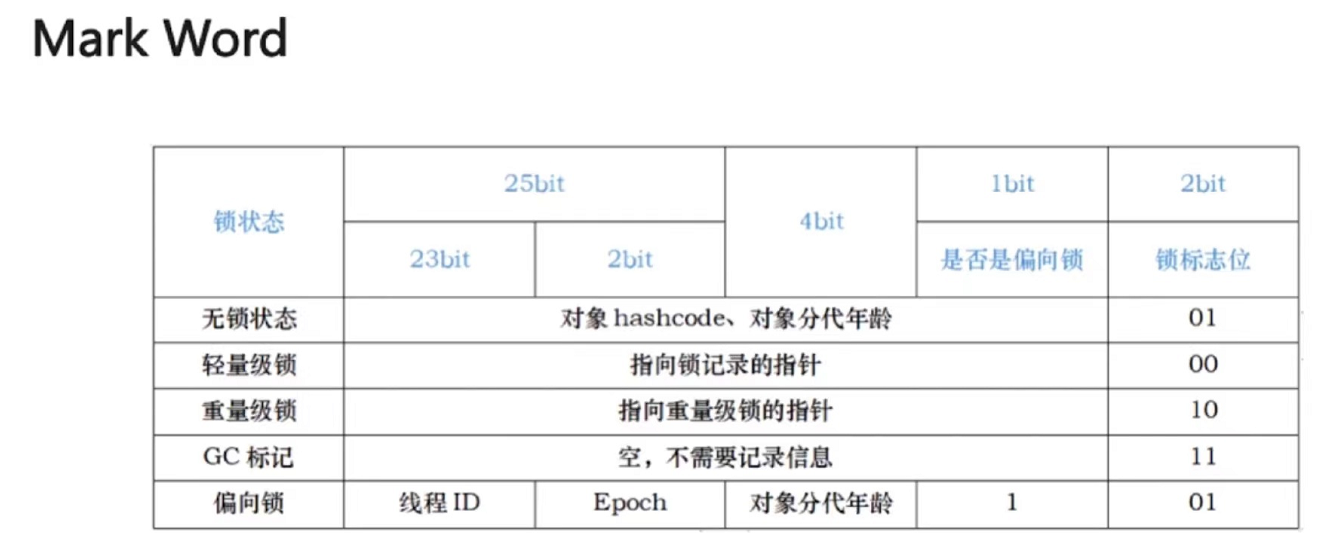









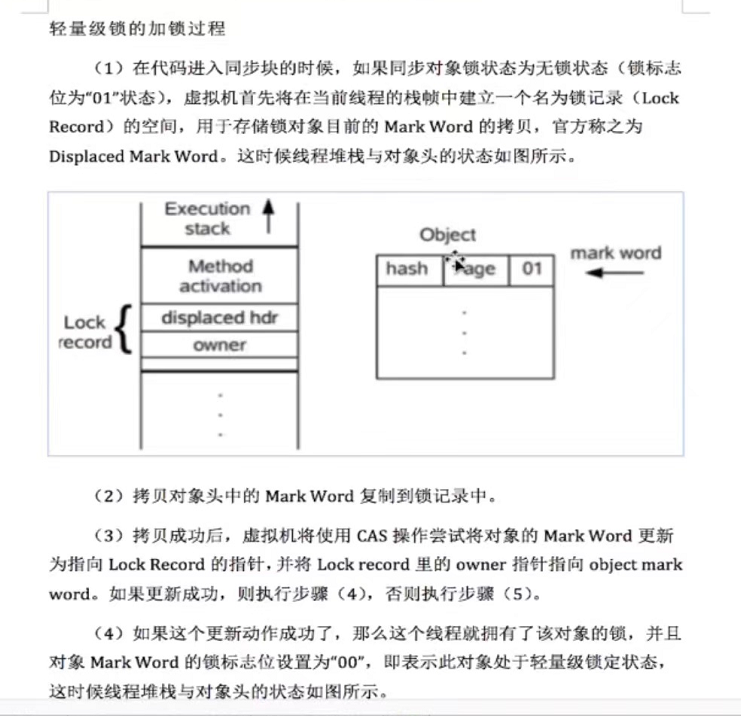
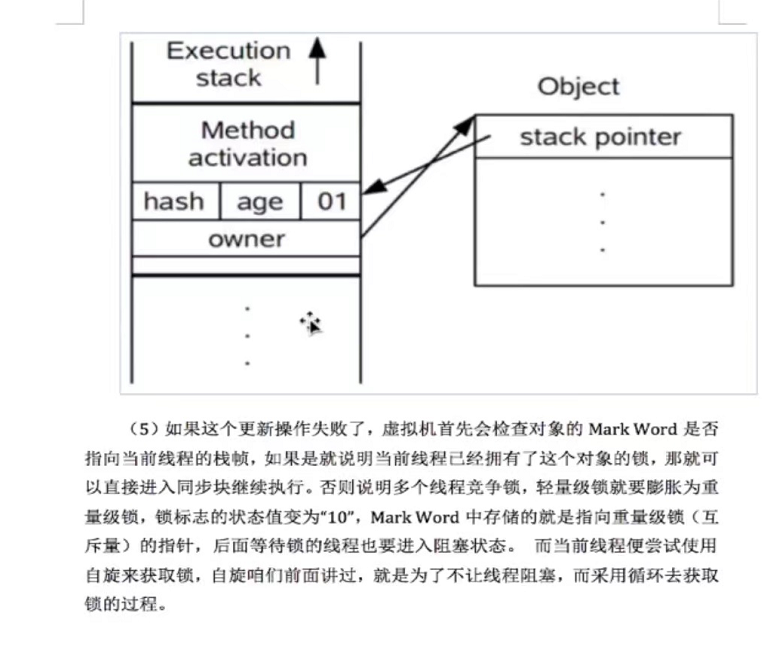


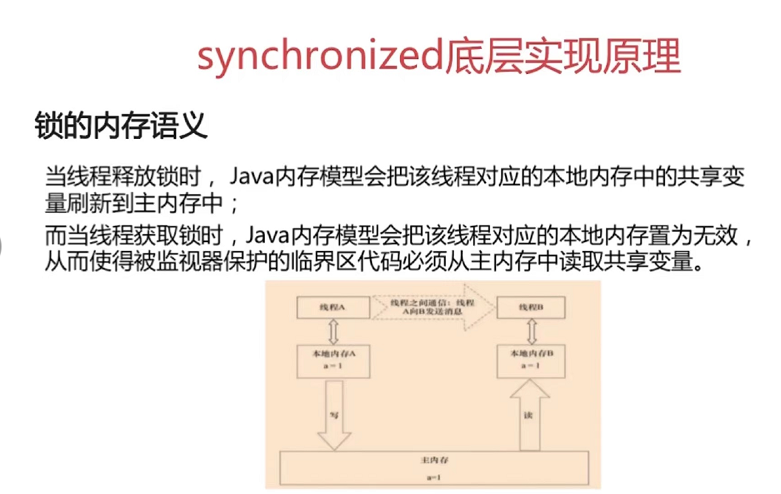






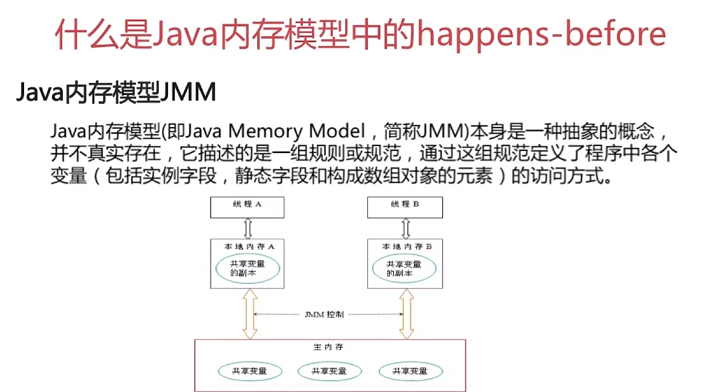























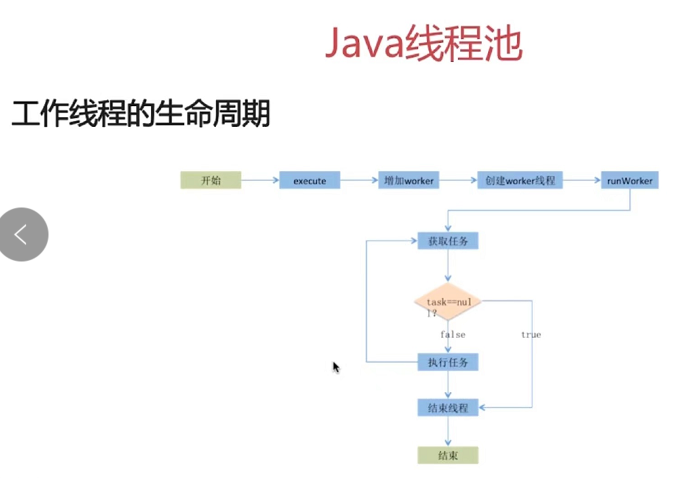

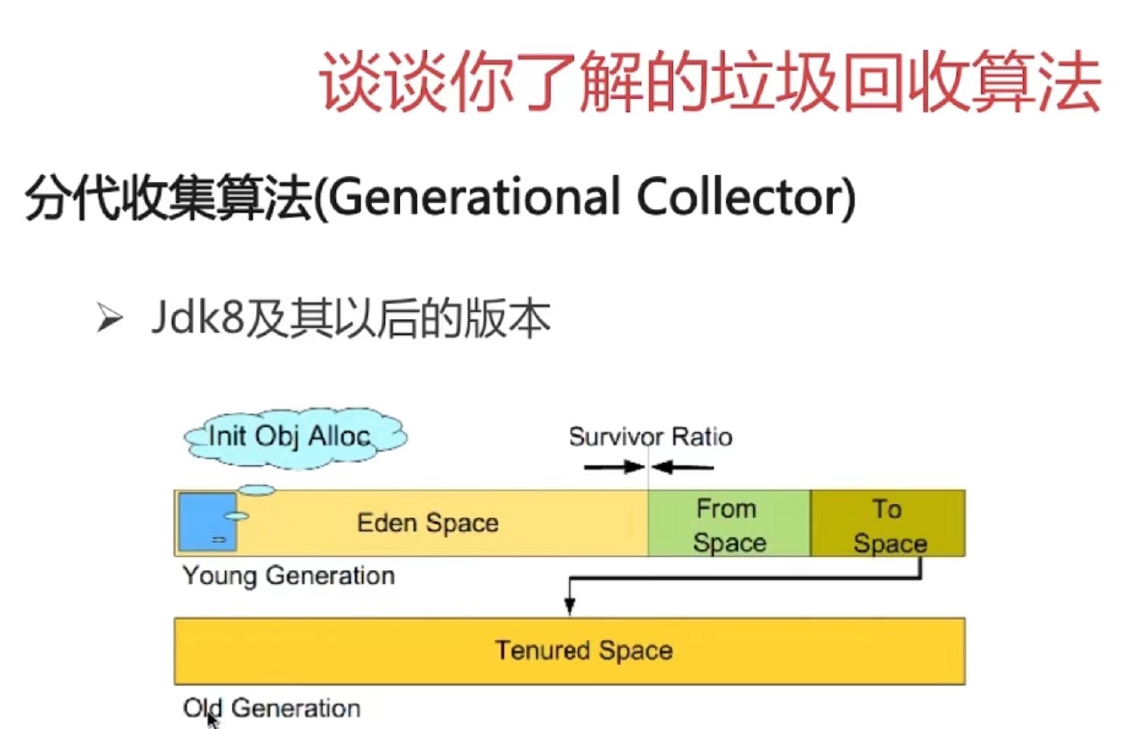
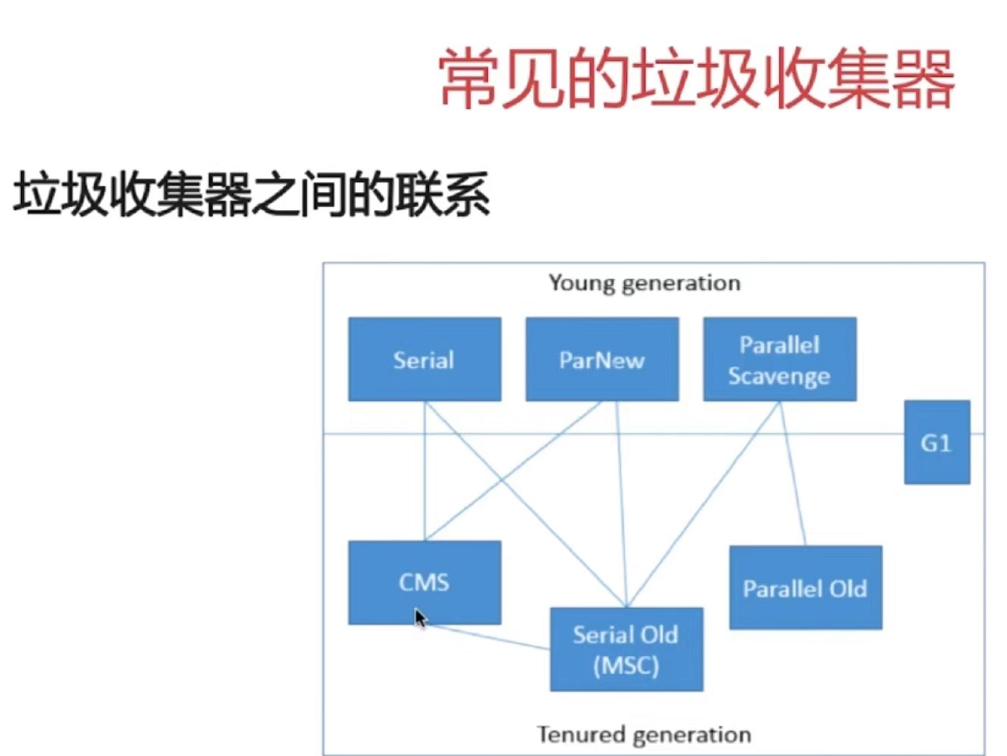
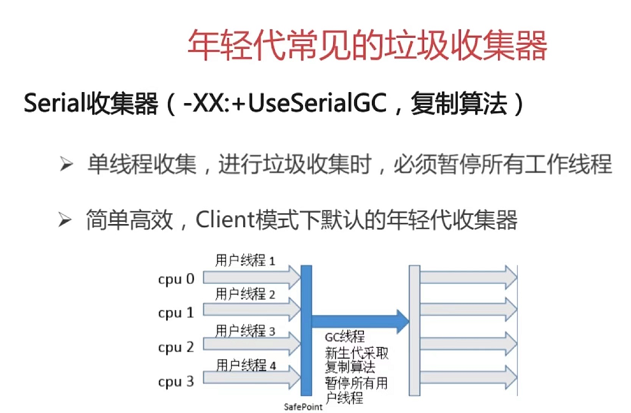
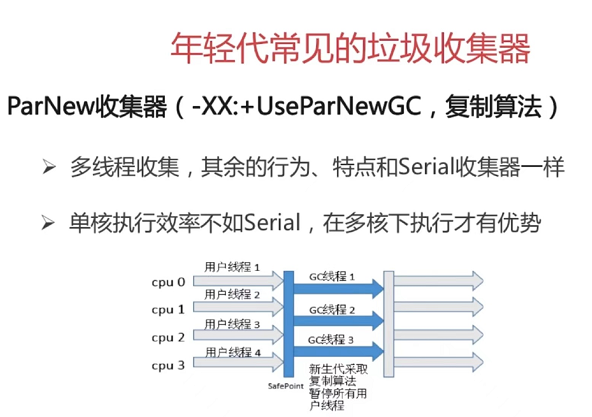
第7章 Java底层知识:GC相关