对2014年和2015选择合适的时序模型和合适的预测方法
目录
一、数据分析
1.读取数据
2.描述性统计分析
3.相关性分析
二、数据预处理
三.建立灰色预测模型
四.建立向量机回归模型(SVR)
五、ARIMA模型
六、总结
下图为待分析数据:
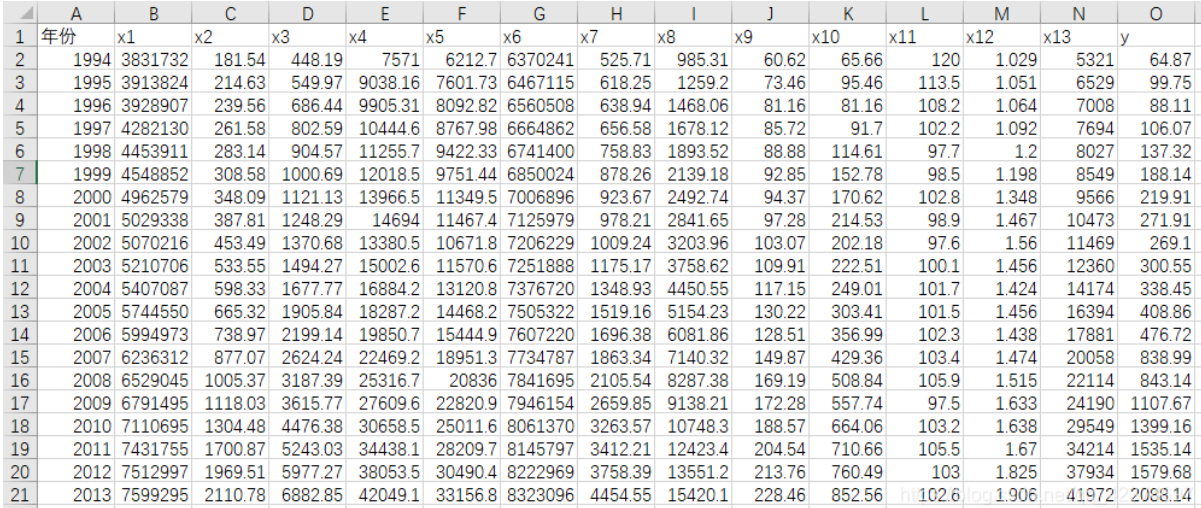
数据说明:
社会从业人数x1 、 在岗职工工资总额x2、社会消费品零售总额x3、城镇居民人均可支配收人x4、 城镇居民人均消费性支出x5、年末总人口x6、全社会固定资产投资额x7、地区生产总值x8、第一产业产值x9、税收x10、居民消费价格指数x11、第三产业与第二产业产值比x12、地区生产总值x8、和居民消费水平x13,y为财政收入
一、数据分析
1.读取数据
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from pylab import mpl # 正常显示中文标签 mpl.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示负号 mpl.rcParams['axes.unicode_minus'] = False # 禁用科学计数法 pd.set_option('display.float_format', lambda x: '%.2f' % x) # 读入数据 data = pd.read_excel('data1.xlsx',index_col=0)
2.描述性统计分析
r = [data.min(), data.max(), data.mean(), data.std()] r = pd.DataFrame(r, index=['Min', 'Max', 'Mean', 'STD']).T r = np.round(r, 2) r
分析结果如下:
Min Max Mean STD
x1 3831732.00 7599295.00 5579519.95 1262194.72
x2 181.54 2110.78 765.04 595.70
x3 448.19 6882.85 2370.83 1919.17
x4 7571.00 42049.14 19644.69 10203.02
x5 6212.70 33156.83 15870.95 8199.77
x6 6370241.00 8323096.00 7350513.60 621341.85
x7 525.71 4454.55 1712.24 1184.71
x8 985.31 15420.14 5705.80 4478.40
x9 60.62 228.46 129.49 50.51
x10 65.66 852.56 340.22 251.58
x11 97.50 120.00 103.31 5.51
x12 1.03 1.91 1.42 0.25
x13 5321.00 41972.00 17273.80 11109.19
y 64.87 2088.14 618.08 609.25
3.相关性分析
写出相关矩阵
pear = np.round(data.corr(method = 'pearson'), 2)
pear
plt.figure(figsize=(12,12)) sns.heatmap(data.corr(), center=0, square=True, linewidths=.5, cbar_kws={"shrink": .5},annot=True, fmt='.1f') #设置x轴 plt.xticks(fontsize=15) #设置y轴 plt.yticks(fontsize=15) plt.tight_layout() plt.savefig('a.png')
绘制热力图为:
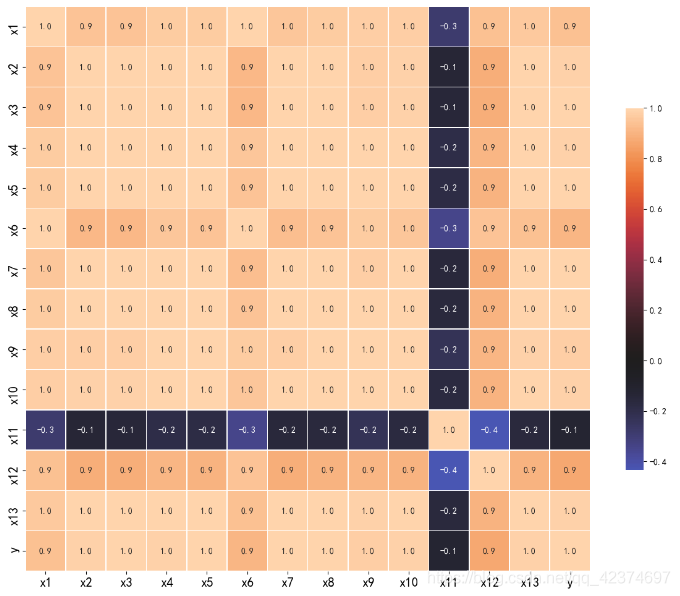
由图可知,居民消费价格指数(x11)与财政收入的线性关系不显著,而且呈现负相关。其余变量均与财政收入呈现高度的正相关关系。
二、数据预处理
1.利用Lasso特征选择,对数据进行预处理,去除特征间的多重共线性:
import pandas as pd import numpy as np from sklearn.linear_model import Lasso data = pd.read_csv('data/data.csv', header=0) x, y = data.iloc[:, :-1], data.iloc[:, -1] # 取alpha=1000进行特征提取 lasso = Lasso(alpha=1000, random_state=1) lasso.fit(x, y) # 相关系数 print('相关系数为', np.round(lasso.coef_, 5)) coef = pd.DataFrame(lasso.coef_, index=x.columns) print('相关系数数组为\n', coef) # 返回相关系数是否为0的布尔数组 mask = lasso.coef_ != 0.0 # 对特征进行选择 x = x.loc[:, mask] new_reg_data = pd.concat([x, y], axis=1) new_reg_data.to_csv('new_reg_data.csv')
三.建立灰色预测模型
# 自定义灰色预测函数 def GM11(x0): # 数据处理 x1 = x0.cumsum() # 1-AGO序列 z1 = (x1[:len(x1) - 1] + x1[1:]) / 2.0 # 紧邻均值(MEAN)生成序列 z1 = z1.reshape((len(z1), 1)) # 计算参数 B = np.append(-z1, np.ones_like(z1), axis=1) Yn = x0[1:].reshape((len(x0) - 1, 1)) [[a], [b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) # 还原值 f = lambda k: (x0[0] - b / a) * np.exp(-a * (k - 1)) - (x0[0] - b / a) * np.exp(-a * (k - 2)) # 后验差检验 delta = np.abs(x0 - np.array([f(i) for i in range(1, len(x0) + 1)])) C = delta.std() / x0.std() P = 1.0 * (np.abs(delta - delta.mean()) < 0.6745 * x0.std()).sum() / len(x0) return f, a, b, x0[0], C, P # 返回灰色预测函数、a、b、首项、方差比、小残差概率 new_reg_data = pd.read_csv('new_reg_data.csv', header=0, index_col=0) # 读取经过特征选择后的数据 data = pd.read_csv('data/data.csv', header=0) # 读取总的数据 new_reg_data.index = range(1994, 2014) new_reg_data.loc[2014] = None new_reg_data.loc[2015] = None cols = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] for i in cols: f = GM11(new_reg_data.loc[range(1994, 2014), i].values)[0] new_reg_data.loc[2014, i] = f(len(new_reg_data) - 1) # 2014年预测结果 new_reg_data.loc[2015, i] = f(len(new_reg_data)) # 2015年预测结果 new_reg_data[i] = new_reg_data[i].round(2) # 保留两位小数 y = list(data['y'].values) # 提取财政收入列,合并至新数据框中 y.extend([np.nan, np.nan]) new_reg_data['y'] = y new_reg_data.to_excel('new_reg_data_GM11.xls') # 结果输出 print('预测结果为:\n', new_reg_data.loc[2014:2015, :]) # 预测结果展示
四.建立向量机回归模型(SVR)
from sklearn.svm import LinearSVR import matplotlib.pyplot as plt data = pd.read_excel('new_reg_data_GM11.xls',index_col=0,header=0) # 读取数据 feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] # 属性所在列 data_train = data.loc[range(1994, 2014)].copy() # 取2014年前的数据建模 # 数据标准化 data_mean = data_train.mean() data_std = data_train.std() data_train = (data_train - data_mean) / data_std x_train = data_train[feature].values # 属性数据 y_train = data_train['y'].values # 标签数据 # 调用LinearSVR()函数 linearsvr = LinearSVR() linearsvr.fit(x_train, y_train) x = ((data[feature] - data_mean[feature]) / data_std[feature]).values # 预测,并还原结果。 data[u'y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y'] # SVR预测后保存的结果 data.to_excel('new_reg_data_GM11_revenue.xls') print('真实值与预测值分别为:\n', data[['y', 'y_pred']]) fig = data[['y', 'y_pred']].plot(subplots=True, style=['b-o', 'r-*']) # 画出预测结果图 plt.show()
最后得到真实值与预测值分别为:
y y_pred
1994 64.87 39.178714
1995 99.75 85.572845
1996 88.11 96.280182
1997 106.07 107.925220
1998 137.32 152.320388
1999 188.14 189.199850
2000 219.91 220.381728
2001 271.91 231.055736
2002 269.10 220.501519
2003 300.55 301.152180
2004 338.45 383.844627
2005 408.86 463.423139
2006 476.72 554.914429
2007 838.99 691.053569
2008 843.14 842.424578
2009 1107.67 1086.676160
2010 1399.16 1377.737429
2011 1535.14 1535.140000
2012 1579.68 1737.264098
2013 2088.14 2083.231695
2014 NaN 2185.297088
2015 NaN 2535.939620
4.预测结果绘制为图片如下
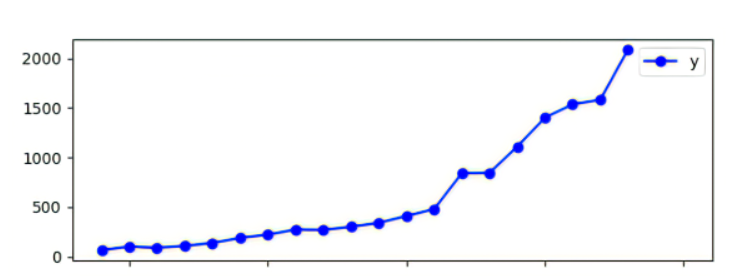
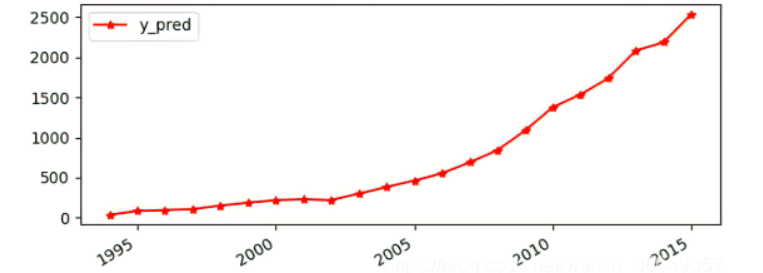
进行对比得下图
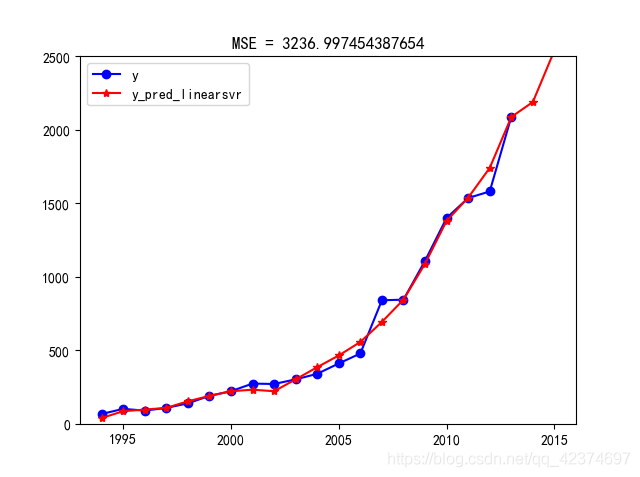
由图可知,两个折线较吻合,模型的效果不错。
预测2014和2015财政收入的预测值为:
2014 NaN 2185.297088
2015 NaN 2535.939620
五、ARIMA模型
import pandas as pd # 参数初始化 discfile = 'C:/Users/86136/Desktop/python数据挖掘/课本源代码及数据/chapter6/demo/data/data.csv' forecastnum = 5 # 读取数据,指定日期列为指标,pandas自动将“日期”列识别为Datetime格式 data = pd.read_csv(discfile) x = 'y' data = data[[x]] # 时序图 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 data.plot() plt.show() # 自相关图 from statsmodels.graphics.tsaplots import plot_acf plot_acf(data).show() # 平稳性检测 from statsmodels.tsa.stattools import adfuller as ADF print('原始序列的ADF检验结果为:', ADF(data['y'])) # 返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore # 差分后的结果 D_data = data.diff().dropna() D_data.columns = ['收入差分'] D_data.plot() # 时序图 plt.show() plot_acf(D_data).show() # 自相关图 from statsmodels.graphics.tsaplots import plot_pacf plot_pacf(D_data).show() # 偏自相关图 print('差分序列的ADF检验结果为:', ADF(D_data['收入差分'])) # 平稳性检测 # 白噪声检验 from statsmodels.stats.diagnostic import acorr_ljungbox print('差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) # 返回统计量和p值 from statsmodels.tsa.arima_model import ARIMA # 定阶 data['y'] = data['y'].astype(float) pmax = int(len(D_data)/10) # 一般阶数不超过length/10 qmax = int(len(D_data)/10) # 一般阶数不超过length/10 bic_matrix = [] # BIC矩阵 for p in range(pmax+1): tmp = [] for q in range(qmax+1): try: # 存在部分报错,所以用try来跳过报错。 tmp.append(ARIMA(data, (p,1,q)).fit().bic) except: tmp.append(None) bic_matrix.append(tmp) bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找出最小值 p,q = bic_matrix.stack().idxmin() # 先用stack展平,然后用idxmin找出最小值位置。 print('BIC最小的p值和q值为:%s、%s' %(p,q)) model = ARIMA(data, (p,1,q)).fit() # 建立ARIMA(0, 1, 1)模型 print('模型报告为:\n', model.summary2()) print('预测未来5天,其预测结果、标准误差、置信区间如下:\n', model.forecast(5))
得到ARIMA模型的预测结果如下:
预测未来2年,其预测结果、标准误差、置信区间如下:
(array([2194.62789474,2301.11578947]),array([139.67908462,197.53605585]) array([[1920.86191949,2468.39386998],
[1913.95223437,2688.27934458]1))
六、总结
由于ARIMA模型的标准误差比较大,所以灰度预测模型GM11的预测结果更加准确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号