
redis读书笔记
1、redis两种存储机制(持久化)
Redis的存储机制分为:Snapshot和AOF 都先将内存存储在内存中。
(1)Snapshot当数据累计到一定的阈值,就会触发dump将数据一次性写入到数据文件RDB文件。批量数据存储,写入频率低,效率也高。但是安全性小,redis宕机,没有写入的数据会造成丢失。
(2)AOF采用日志追加的方式来持久化数据,调用fsync来完成对本次写操作的日志记录。调用fsync追加日志文件的频率可以更改,always每次记录都添加进来,everysecond每秒添加一次。rewrite这个日志的概念:根据合理的配置触发rewrite操作,将日志文件中所有数据都重新写在新的文件中,对于同个key的多次操作,保留最终的值得那次操作在日志文件中。缩小了日志文件大小。
2、redis的内存优化
(1)string和数字,redis能识别出一个数字,并按数字存储,节省存储空间。redis内部有一个数字池,默认10000,数字在这个池中就只需要一个简单的索引引用进来就可以,不需要把重复的数字分开存。
(2)复杂类型的存储优化,map,list,set这些大小不固定的集合类。redis会判断这里存储的entry数量,不多则采用紧凑格式来存储数据,这里不做解释。
3、讲讲redis中的hash数据类型
比起String数据类型,这个更适合存储对象,避免了序列化和反序列化
hash是一个string 类型的field和value的映射表。
hash特别适合存储对象。相对于将对象的每个字段存成单个string 类型。一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象。
Redis的Hash数据类型的value内部是一个HashMap,如果该Map的成员比较少,则会采用一维数组的方式来紧凑存储该MAP,省去了大量指针的内存开销。
采用key—field—value的方式。一个key可对应多个field,一个field对应一个value。这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而令其它客户端的请求完全不响应,这点需要格外注意
建议使用对象类别和ID构成键名,使用字段表示对象属性,字段值存储属性值。
4、redis集群
如果redis只是单例的话,万一挂了,数据丢失。而且当数据量很大的时候,集群可以保证高可用。它可以把多个redis实例整合在一起,形成一个集群,也就是将数据分散到集群的多台机器上。但是该怎么分散呢,一个Key只能被分配到一台机器上,集群是如何实现把数据分配到不同的节点呢?我们在查询数据时,数据在任意一个节点中,我们如何保证成功存取呢?
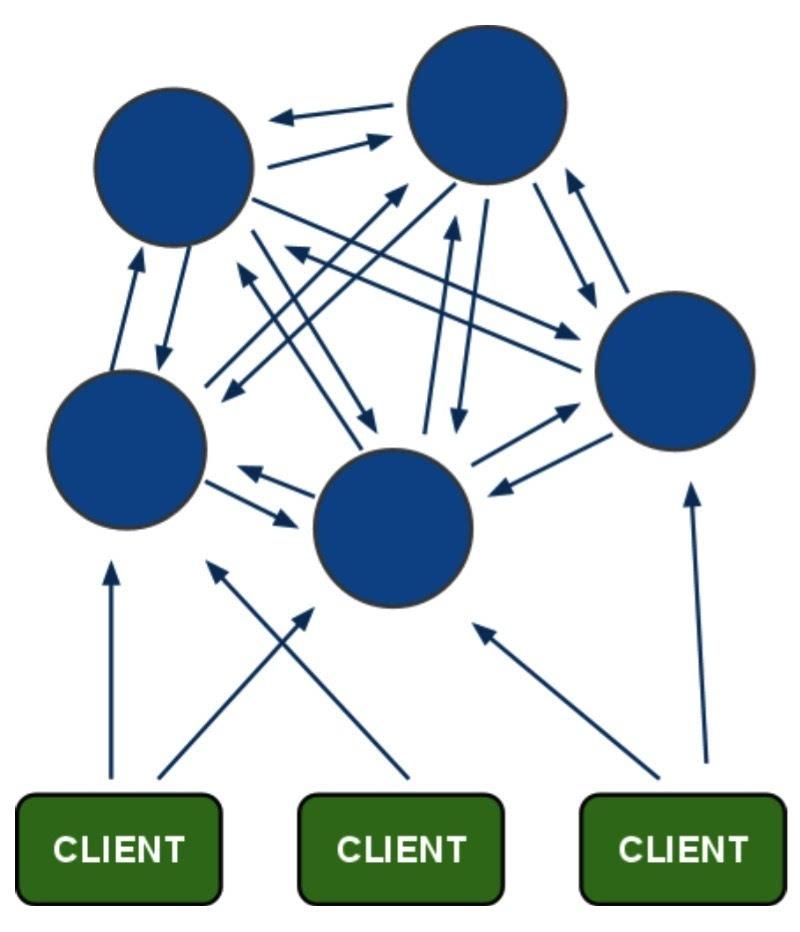
如图是redis集群架构图,蓝色的是redis服务器节点,绿色的是客户端。每个节点通过二进制协议进行通信,每个节点也保存着所有集群的信息。节点之间相互ping对方,如果ping不通,说明对方节点挂了,由于每个节点会有一个副本slave,主从备份保证了后台的稳定性。
客户端可以与任何一个节点通信,对其存取和其他操作。由于数据被分配在不同的节点中,集群是如何找到数据在哪儿呢?redis 集群有一个16384长度的插槽。slot。编号分别是0,1,2,……16383,16384.每个节点都会负责一些插槽。集群维护这节点到插槽的映射。是由长度为16384,类型为节点的数组实现的。槽编码就是数组的下标。数组的内容就是节点。所以这样很快的能知道哪些槽是由哪些节点负责的。对于master节点来说,维护一个16384/8字节的位序列,比如对于编号为1的槽,Master只要判断序列的第二位(索引从0开始)是不是为1即可。
redis的数据是key-value存储的。不同的key的数据如何对应到slot呢。有一个键空间分布的算法 HASH_SLOT=CRC16(key)mod16384 这样就可以算出当前key被存在哪个slot里。
5、分片
分片不变的是键对于槽的映射,改变的是槽对于节点的映射。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号