014 Ceph管理和自定义CRUSHMAP
一、概念
1.1 Ceph集群写操作流程
client首先访问ceph monitor获取cluster map的一个副本,知晓集群的状态和配置
数据被转化为一个或多个对象,每个对象都具有对象名称和存储池名称
以PG数为基数做hash,将对象映射到一个PG
根据计算出的PG,再通过CRUSH算法得到存放数据的一组OSD位置(副本个数),第一个是主,后面是从
客户端获得OSD ID,直接和这些OSD通信并存放数据
注: 以上所有操作都是在客户端完成 的,不会影响ceph集群服务端性能
1.2 Crush和对象放置策略
Ceph使用CRUSH算法(Controlled Replication Under Scalable Hashing 可扩展哈希下的受控复制)来计算哪些OSD存放哪些对象
对象分配到PG中,CRUSH决定这些PG使用哪些OSD来存储对象。理想情况下,CRUSH会将数据均匀的分布到存储中
当添加新OSD或者现有的OSD出现故障时,Ceph使用CRUSH在活跃的OSD上重平衡数据
CRUSH map是CRUSH算法的中央配置机制,可通过调整CRUSH map来优化数据存放位置
默认情况下,CRUSH将对象放置到不同主机上的OSD中。可以配置CRUSH map和CRUSH rules,使对象放置到不同房间或者不同机柜的主机上的OSD中。也可以将SSD磁盘分配给需要高速存储的池
1.3 Crush map的组成部分
CRUSH hierarchy(层次结构):一个树型结构,通常用于代表OSD所处的位置。默认情况下,有一个根bucket,它包含所有的主机bucket,而OSD则是主机bucket的树叶。这个层次结构允许我们自定义,对它重新排列或添加更多的层次,如将OSD主机分组到不同的机柜或者不同的房间
CRUSH rule(规则):CRUSH rule决定如何从bucket中分配OSD pg。每个池必须要有一条CRUSH rule,不同的池可map不同的CRUSH rule
二、crushmap的解译编译和更新
[root@ceph2 ceph]# ceph osd getcrushmap -o ./crushmap.bin
[root@ceph2 ceph]# file ./crushmap.bin
./crushmap.bin: MS Windows icon resource - 8 icons, 2-colors
[root@ceph2 ceph]# crushtool -d crushmap.bin -o ./crushmap.txt
[root@ceph2 ceph]# vim ./crushmap.txt
[root@ceph2 ceph]# crushtool -c crushmap.txt -o crushmap.-new.bin
[root@ceph2 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.13129 root default
-3 0.04376 host ceph2
0 hdd 0.01459 osd.0 up 1.00000 1.00000
3 hdd 0.01459 osd.3 up 1.00000 1.00000
6 hdd 0.01459 osd.6 up 1.00000 1.00000
-7 0.04376 host ceph3
2 hdd 0.01459 osd.2 up 1.00000 1.00000
5 hdd 0.01459 osd.5 up 1.00000 1.00000
8 hdd 0.01459 osd.8 up 1.00000 1.00000
-5 0.04376 host ceph4
1 hdd 0.01459 osd.1 up 1.00000 1.00000
4 hdd 0.01459 osd.4 up 1.00000 1.00000
7 hdd 0.01459 osd.7 up 1.00000 1.00000
[root@ceph2 ceph]# vim ./crushmap.txt
 crushmap.txt
crushmap.txt配置项
host ceph3 {
id -7 # do not change unnecessarily ,一个负整数,以便与存储设备id区分
id -8 class hdd # do not change unnecessarily
# weight 0.044
alg straw2 #将pg map到osd时的算法,默认使用straw2
hash 0 # rjenkins1 #每个bucket都有一个hash算法,目前Ceph支持rjenkins1算法,设为0即使用该算法
item osd.2 weight 0.015 #一个bucket包含的其他bucket或者叶子
item osd.5 weight 0.015
item osd.8 weight 0.015
}
CRUSH map包含数据放置规则,默认有两个规则: replicated_rule和erasure-code
通过ceph osd crush rule ls可列出现有规则,也可以使用ceph osd crush rule dump打印规则详细详细
[root@ceph2 ceph]# ceph osd crush rule ls

[root@ceph2 ceph]# ceph osd crush rule dump
[
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
},
{
"rule_id": 1,
"rule_name": "EC-pool",
"ruleset": 1,
"type": 3,
"min_size": 3,
"max_size": 5,
"steps": [
{
"op": "set_chooseleaf_tries",
"num": 5
},
{
"op": "set_choose_tries",
"num": 100
},
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_indep",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
]
和配置文件crushmap一样
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule <rulename> {
id <id > [整数,规则id]
type [replicated|erasure] [规则类型,用于复制池还是纠删码池]
min_size <min-size> [如果池的最小副本数小于该值,则不会为当前池应用这条规则]
max_size <max-size>[如果创建的池的最大副本大于该值,则不会为当前池应用这条规则]
step take <bucket type> [这条规则作用的bucket,默认为default]
step [chooseleaf|choose] [firstn] <num> type <bucket-type>
# num == 0 选择N(池的副本数)个bucket
# num > 0且num < N 选择num个bucket
# num < 0 选择N-num(绝对值)个bucket
step emit
}
创建一个复制池:
[root@ceph2 ceph]# ceph osd pool create testpool 32 32
pool 'testpool' already exists
[root@ceph2 ceph]# ceph osd pool set tetspool size 11
Error ENOENT: unrecognized pool 'tetspool' #crush规则最大为10 修改crushrule
[root@ceph2 ceph]# vim crushmap.txt
rule replicated1_rule {
id 2
type replicated
min_size 1
max_size 11
step take default
step chooseleaf firstn 0 type host
step emit
}
[root@ceph2 ceph]# vim crushmap.txt
[root@ceph2 ceph]# crushtool -c crushmap.txt -o crushmap-new.bin
[root@ceph2 ceph]# ceph osd setcrushmap -i crushmap-new.bin

[root@ceph2 ceph]# ceph osd crush rule ls

[root@ceph2 ceph]# ceph osd pool get testpool all
size: 3
min_size: 2
crash_replay_interval: 0
pg_num: 128
pgp_num: 128
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
auid: 0
fast_read: 0
三、从命令行更新Crush map参数
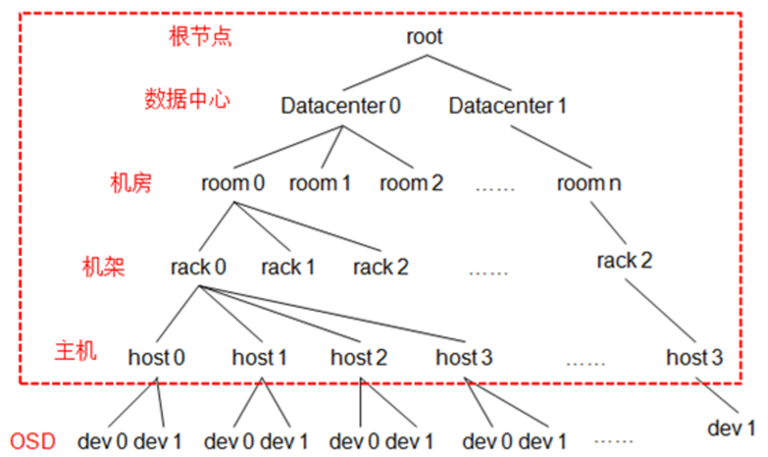
3.1 默认bucket类型
type 0 osd,type 1 host,type 2 chassis,type 3 rack,type 4 row,type 5 pdu
type 6 pod,type 7 room,type 8 datacenter,type 9 region,type 10 root
图解
四、从命令行更新CRUSH map的 层次结构
4.1 创建bucket
[root@ceph2 ceph]# ceph osd crush add-bucket DC1 datacenter
added bucket DC1 type datacenter to crush map
4.2 检查
[root@ceph2 ceph]# ceph osd getcrushmap -o crushmap.bin
[root@ceph2 ceph]# crushtool -d crushmap.bin -o crushmap.txt
[root@ceph2 ceph]# vim crushmap.txt
datacenter DC1 {
id -9 # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
[root@ceph2 ceph]# ceph osd tree

4.3 删除
[root@ceph2 ceph]# vim crushmap.txt
这一段删除
datacenter DC1 {
id -9 # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
4.4 编译导入
[root@ceph2 ceph]# crushtool -c crushmap.txt -o crushmap-new.bin
[root@ceph2 ceph]# ceph osd setcrushmap -i crushmap-new.bin

已经删除
[root@ceph2 ceph]# ceph osd tree

4.5 重新创建bucket
[root@serverc ~]# ceph osd crush add-bucket dc1 root
added bucket dc1 type root to crush map
五、规划新的bucket
5.1 定义三个rack
[root@ceph2 ceph]# ceph osd crush add-bucket rack1 rack
added bucket rack1 type rack to crush map
[root@ceph2 ceph]# ceph osd crush add-bucket rack2 rack
added bucket rack2 type rack to crush map
[root@ceph2 ceph]# ceph osd crush add-bucket rack3 rack
added bucket rack3 type rack to crush map
5.2 把三个rack加入到dc1
[root@ceph2 ceph]# ceph osd crush move rack1 root=dc1
moved item id -10 name 'rack1' to location {root=dc1} in crush map
[root@ceph2 ceph]# ceph osd crush move rack2 root=dc1
moved item id -11 name 'rack2' to location {root=dc1} in crush map
[root@ceph2 ceph]# ceph osd crush move rack3 root=dc1
moved item id -12 name 'rack3' to location {root=dc1} in crush map
5.3 把三个主机移动到rack中
由于move过去,默认就没有主机了,可以只用link连接过去
[root@ceph2 ceph]# ceph osd crush link ceph2 rack=rack1
linked item id -3 name 'ceph2' to location {rack=rack1} in crush map
[root@ceph2 ceph]# ceph osd crush link ceph2 rack=rack2
linked item id -3 name 'ceph2' to location {rack=rack2} in crush map
[root@ceph2 ceph]# ceph osd crush link ceph3 rack=rack2
linked item id -7 name 'ceph3' to location {rack=rack2} in crush map
[root@ceph2 ceph]# ceph osd crush link ceph4 rack=rack2
linked item id -5 name 'ceph4' to location {rack=rack2} in crush map
[root@ceph2 ceph]# ceph osd tree
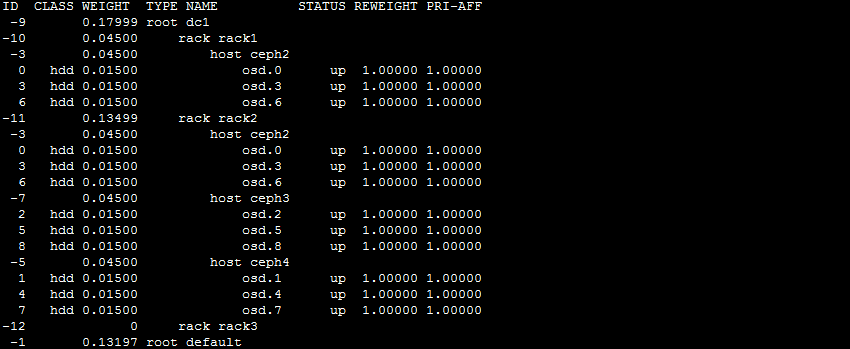
5.4 修改
发现命令行配置错误,修改crushmap规则
原配置
rack rack1 {
id -10 # do not change unnecessarily
id -15 class hdd # do not change unnecessarily
# weight 0.045
alg straw2
hash 0 # rjenkins1
item ceph2 weight 0.045
}
rack rack2 {
id -11 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
# weight 0.135
alg straw2
hash 0 # rjenkins1
item ceph2 weight 0.045
item ceph3 weight 0.045
item ceph4 weight 0.045
}
rack rack3 {
id -12 # do not change unnecessarily
id -13 class hdd # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
修改
rack rack1 {
id -10 # do not change unnecessarily
id -15 class hdd # do not change unnecessarily
# weight 0.045
alg straw2
hash 0 # rjenkins1
item ceph2 weight 0.045
}
rack rack2 {
id -11 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
# weight 0.135
alg straw2
hash 0 # rjenkins1
item ceph3 weight 0.045
}
rack rack3 {
id -12 # do not change unnecessarily
id -13 class hdd # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
item ceph4 weight 0.045
}
5.5 编译导入
[root@ceph2 ceph]# crushtool -c crushmap.txt -o crushmap-new.bin
[root@ceph2 ceph]# ceph osd setcrushmap -i crushmap-new.bin
29
[root@ceph2 ceph]# ceph osd tree
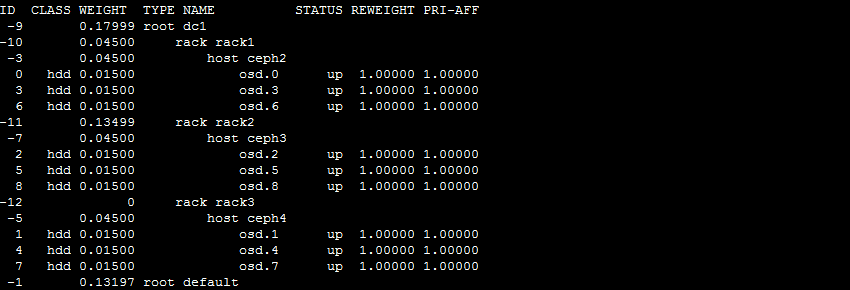
5.6 创建一个故障域为rack级别的rule
[root@ceph2 ceph]# ceph osd crush rule create-replicated indc1 dc1 rack
[root@ceph2 ceph]# ceph osd getcrushmap -o ./crushmap.bin
[root@ceph2 ceph]# crushtool -d ./crushmap.bin -o ./crushmap.txt
[root@ceph2 ceph]# vim ./crushmap.txt
rule indc1 {
id 3
type replicated
min_size 1
max_size 10
step take dc1
step chooseleaf firstn 0 type rack
step emit
}
5.7 创建一个池检测
[root@ceph2 ceph]# ceph osd pool create test 32 32
pool 'test' created
[root@ceph2 ceph]# ceph osd pool application enable test rbd
enabled application 'rbd' on pool 'test'
[root@ceph2 ceph]# ceph osd pool get test all
size: 3
min_size: 2
crash_replay_interval: 0
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
auid: 0
fast_read: 0
5.8 修改crushmap规则
[root@ceph2 ceph]# ceph osd pool set test crush_rule indc1
set pool 16 crush_rule to indc1
[root@ceph2 ceph]# ceph osd pool get test all
size: 3
min_size: 2
crash_replay_interval: 0
pg_num: 32
pgp_num: 32
crush_rule: indc1
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
auid: 0
fast_read: 0
5.9 创建一个对象测试
[root@ceph2 ceph]# rados -p test put test /etc/ceph/ceph.conf
[root@ceph2 ceph]# rados -p test ls
test
[root@ceph2 ceph]# ceph osd map test test
osdmap e239 pool 'test' (16) object 'test' -> pg 16.40e8aab5 (16.15) -> up ([5,6], p5) acting ([5,6,0], p5)
[root@ceph2 ceph]# cd /var/lib/ceph/osd/ceph-0/current/
[root@ceph2 current]# ls
10.0_head 1.1f_head 13.5_head 14.20_head 1.48_head 15.26_head 1.53_head 15.5c_head 15.79_head 16.11_head 1.66_TEMP 1.79_head 5.2_head 6.5_head
六、 实现指定ssd的存储池
每一个主机上选择一块磁盘作为ssd
ceph2:osd.0 ceph3:osd.2 ceph4:osd.1
6.1 创建基于这些主机的bucket
[root@ceph2 current]# ceph osd crush add-bucket ceph2-ssd host
added bucket ceph2-ssd type host to crush map
[root@ceph2 current]# ceph osd crush add-bucket ceph3-ssd host
added bucket ceph3-ssd type host to crush map
[root@ceph2 current]# ceph osd crush add-bucket ceph4-ssd host
added bucket ceph4-ssd type host to crush map
[root@ceph2 current]# ceph osd tree

6.2 创建root,并把三台主机添加进去
[root@ceph2 current]# ceph osd crush add-bucket ssd-root root
added bucket ssd-root type root to crush map
[root@ceph2 current]# ceph osd crush move ceph2-ssd root=ssd-root
moved item id -17 name 'ceph2-ssd' to location {root=ssd-root} in crush map
[root@ceph2 current]# ceph osd crush move ceph3-ssd root=ssd-root
moved item id -18 name 'ceph3-ssd' to location {root=ssd-root} in crush map
[root@ceph2 current]# ceph osd crush move ceph4-ssd root=ssd-root
moved item id -19 name 'ceph4-ssd' to location {root=ssd-root} in crush map
[root@ceph2 current]# ceph osd tree

6.3 在这些主机上只添加指定的ssd盘的osd
[root@ceph2 current]# ceph osd crush add osd.0 0.01500 root=ssd-root host=ceph2-ssd
add item id 0 name 'osd.0' weight 0.015 at location {host=ceph2-ssd,root=ssd-root} to crush map
[root@ceph2 current]# ceph osd crush add osd.2 0.01500 root=ssd-root host=ceph3-ssd
add item id 2 name 'osd.2' weight 0.015 at location {host=ceph3-ssd,root=ssd-root} to crush map
[root@ceph2 current]# ceph osd crush add osd.1 0.01500 root=ssd-root host=ceph4-ssd
add item id 1 name 'osd.1' weight 0.015 at location {host=ceph4-ssd,root=ssd-root} to crush map
[root@ceph2 current]# ceph osd tree

6.4 创建一个crush rule,故障域基于主机级别
[root@ceph2 current]# ceph osd crush rule create-replicated ssdrule ssd-root host
6.5 创建一个池检测
[root@ceph2 current]# ceph osd pool create ssdpool 32 32 replicated ssdrule
pool 'ssdpool' created
[root@ceph2 current]# ceph osd pool get ssdpool all
size: 3
min_size: 2
crash_replay_interval: 0
pg_num: 32
pgp_num: 32
crush_rule: ssdrule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
auid: 0
fast_read: 0
[root@ceph2 current]# rados -p ssdpool put test /etc/ceph/ceph.conf
[root@ceph2 current]# rados -p ssdpool ls
test
[root@ceph2 current]# ceph osd map ssdpool test
osdmap e255 pool 'ssdpool' (17) object 'test' -> pg 17.40e8aab5 (17.15) -> up ([2,1,0], p2) acting ([2,1,0], p2)
6.6 保证两个root不冲突
可以把指定的ssd从dc1的root中去掉,保证两个root各用个的磁盘
[root@ceph2 current]# cd /etc/ceph/
[root@ceph2 ceph]# ceph osd getcrushmap -o crushmap.bin
41
[root@ceph2 ceph]# crushtool -d crushmap.bin -o crushmap.txt
[root@ceph2 ceph]# vim crushmap.txt
host ceph2 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.045
alg straw2
hash 0 # rjenkins1
#item osd.0 weight 0.015
item osd.3 weight 0.015
item osd.6 weight 0.015
}
host ceph4 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.045
alg straw2
hash 0 # rjenkins1
#item osd.1 weight 0.015
item osd.4 weight 0.015
item osd.7 weight 0.015
}
host ceph3 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.045
alg straw2
hash 0 # rjenkins1
#item osd.2 weight 0.015
item osd.5 weight 0.015
item osd.8 weight 0.015
}
[root@ceph2 ceph]# crushtool -c crushmap.txt -o crushmap-new.bin
[root@ceph2 ceph]# ceph osd setcrushmap -i crushmap-new.bin
42
[root@ceph2 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-20 0.04500 root ssd-root
-17 0.01500 host ceph2-ssd
0 hdd 0.01500 osd.0 up 1.00000 1.00000
-18 0.01500 host ceph3-ssd
2 hdd 0.01500 osd.2 up 1.00000 1.00000
-19 0.01500 host ceph4-ssd
1 hdd 0.01500 osd.1 up 1.00000 1.00000
-9 0.17999 root dc1
-10 0.04500 rack rack1
-3 0.04500 host ceph2
3 hdd 0.01500 osd.3 up 1.00000 1.00000
6 hdd 0.01500 osd.6 up 1.00000 1.00000
-11 0.13499 rack rack2
-7 0.04500 host ceph3
5 hdd 0.01500 osd.5 up 1.00000 1.00000
8 hdd 0.01500 osd.8 up 1.00000 1.00000
-12 0 rack rack3
-5 0.04500 host ceph4
4 hdd 0.01500 osd.4 up 1.00000 1.00000
7 hdd 0.01500 osd.7 up 1.00000 1.00000
-1 0.13197 root default
-3 0.04399 host ceph2
3 hdd 0.01500 osd.3 up 1.00000 1.00000
6 hdd 0.01500 osd.6 up 1.00000 1.00000
-7 0.04399 host ceph3
5 hdd 0.01500 osd.5 up 1.00000 1.00000
8 hdd 0.01500 osd.8 up 1.00000 1.00000
-5 0.04399 host ceph4
4 hdd 0.01500 osd.4 up 1.00000 1.00000
7 hdd 0.01500 osd.7 up 1.00000 1.00000
各个的osd位于不同的root中,实验完成!!!
博主声明:本文的内容来源主要来自誉天教育晏威老师,由本人实验完成操作验证,需要的博友请联系誉天教育(http://www.yutianedu.com/),获得官方同意或者晏老师(https://www.cnblogs.com/breezey/)本人同意即可转载,谢谢!
---------------------------------------------------------------------------
个性签名:我以为我很颓废,今天我才知道,原来我早报废了。
如果觉得本篇文章最您有帮助,欢迎转载,且在文章页面明显位置给出原文链接!记得在右下角点个“推荐”,博主在此感谢!

