
Deep Learning Computed Tomography【论文简单翻译+理解】
abstract
证明了图像重建能用神经网络表示,具体地说,filtered back-projection(就是CT那个)能够被映射到深度神经网络结构。迭代重建直接用矩阵相乘效果不好,把back-projection层当作fixed function并把梯度当作投影操作更有效。这样就可以找到一个数据驱动的方式在投影域和图像域做joint optimization of correction steps。证明了能够学习weightings和additional filter layers来不断减少重建误差(在一个有限的重建角度by a factor of two【自由度2?】),此时计算复杂度和filtered back projection是相同的。
introduction
提出back-projection layer for parallel-beam and fan-beam projection as well as a weighting layer(然后就能端到端训练)能够学习back projection之前的project domain的heuristic。因此可以把启发式的修正方法替换为学习得到的优化策略,还能同时用其他的修正策略。
methodology
离散FBP:
1D插值:
设置bias=0且激活函数是$ f(x)=x\(时,常见的神经元是\)f\left(y_{i}\right)=\sum_{j=1}^{N} w_{i j} x_{j}$,改一下未知数的含义,把f(y)变成f(x,y)代表pixel(x,y),得到:
同样做插值(the interpolation size big enough to cover the length of the detector by zero-padding the signal as needed):
线性插值->will yield only up to two non-zero coefficients for every M interpolation coefficients resulting in an extremely sparse matrix.
最终得到的是:
把FBP的每一步都对应到网络中的一层:
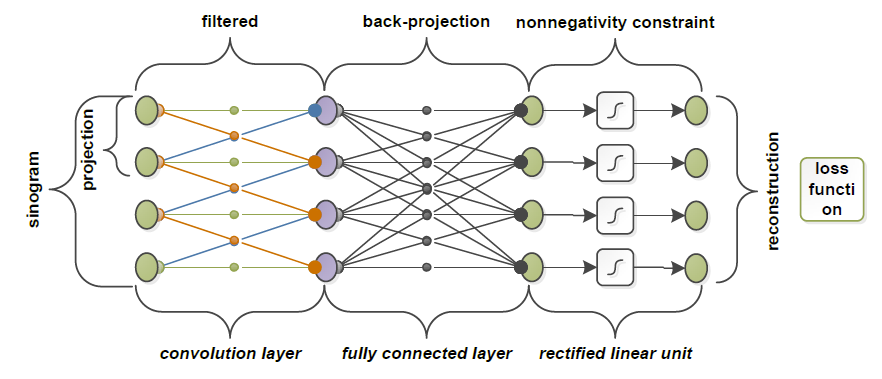
Parallel-Beam Back-Projection Layer(平行光束)
全连接层:This layer has no adjustable parameters.在forward pass中系数被计算出来,\(\mathbf{y}_{l}=\mathbf{W}_{l} \mathbf{y}_{l-1}\),反向传播时\(\mathbf{E}_{l-1}=\mathbf{W}_{l}^{T} \mathbf{E}_{l}\)。【那么,训练的对象其实是“filtered”的部分吗】
the back-projection operator is the transpose(转置) of the projection operator.【从公式也许可以看出】
Extension to Fan-Beam Reconstruction(扇形波束)
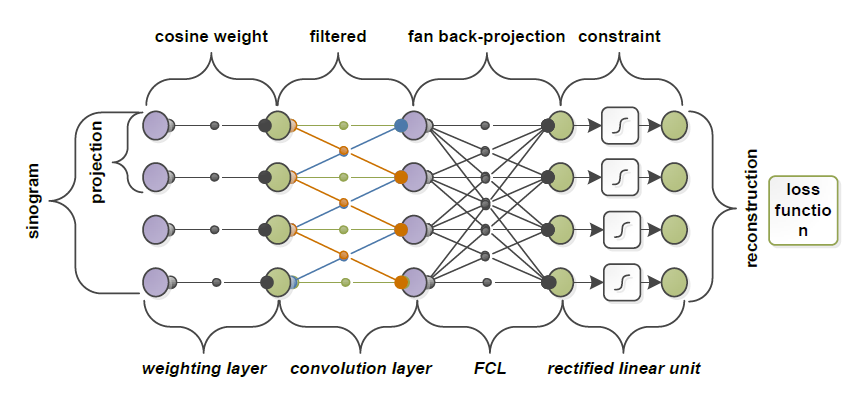
Weighting Layer 非常稀疏【对角阵?】
Fan-Beam Back-Projection Layer 【一小段话,但是没看懂】
Convergence and Overfitting
the convolutional layer uses the ramp filter, and the weighting layer accounts for cosine-weighting or redundancy weighting.
These initializations can be used for a very effective pre-training.
experiment & conclusion
没什么有意思的。
个人理解:其实是在train滤波的kernel,其他部分基本上都是fixed。不一定对。关于CT的基础知识可以看上一篇随笔。对于第二个扇形光束的情况,其实对应weighting layer对应的就是从扇形->平行的过程,convolution layer对应的filter,然后FCL对应backprojection。最后那个线性整形没理解,是为了去除小于0的值吗?

