













本次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
一.把爬取的内容保存到数据库sqlite3
import sqlite3 import pandas as pd def createsql(contentsort): wcdf = pd.DataFrame(contentsort) with sqlite3.connect('wechat.sqlite')as db: wcdf.to_sql('wc', con=db) def readsql(): with sqlite3.connect('wechat.sqlite')as db: df = pd.read_sql_query('SELECT * FROM wc', con=db) print(df)
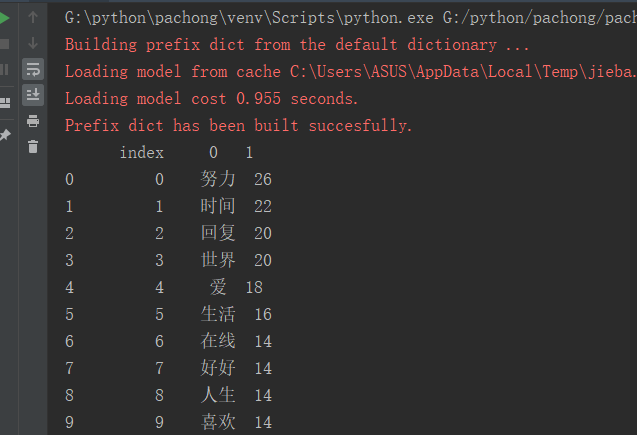
把爬取的内容保存到MySQL数据库
from sqlalchemy import create_engine import pandas as pd def createsql(contentsort): wcdf = pd.DataFrame(contentsort) coninfo = "mysql+pymysql://root:ROOT@localhost:3306/wechat?charset=utf8" engine = create_engine(coninfo, encoding="utf-8") wcdf.to_sql(name='news22', con=engine, if_exists='append', index=False, index_label='id')
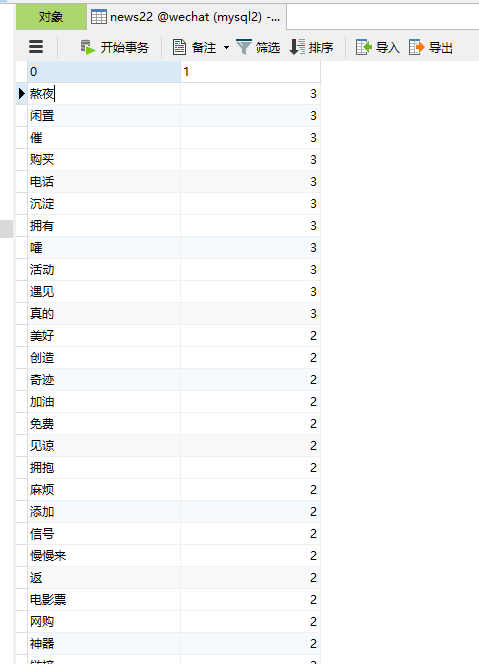
二.爬虫综合大作业
- 爬取说明
我爬取的目标是微信,获取微信中的好友男女数量,省份分布数量,个性签名,这些数据能让我们更加了解自己微信好友的情况。
微信自2011年1月21日问世以来,得到了很多好评,给工作、学习、生活都带来很多便利,尤其是它的聊天、分享信息功能强大到无人不用。用了微信几年了,微信好友有也不少了,但是真正了解自己的好友吗?好友最多的城市是哪个?好友男女比例是多少?好友个性签名都是什么?相信各位对这样的问题,都有或多或少的好奇心,这让我有了下笔的冲动,下面一起来看数据吧!
- 获取数据部分
只有登录微信才能获取到微信好友的信息,本文采用wxpy该第三方库进行微信的登录以及信息的获取。
wxpy中有一个机器人对象,机器人 Bot 对象可被理解为一个 Web 微信客户端。Bot在初始化时便会执行登陆操作,需要手机扫描登陆。
通过机器人对象 Bot 的 chats(), friends(),groups(), mps() 方法, 可分别获取到当前机器人的 所有聊天对象、好友、群聊,以及公众号列表。本文主要通过friends()获取到所有好友信息,然后进行数据的处理。
def login(): # 初始化机器人,扫码登陆 bot=Bot() # 获取所有好友信息 my_friends=bot.friends() return my_friends

wxpy.api.chats.chats.Chats对象是多个聊天对象的合集,可用于搜索或统计,可以搜索和统计的信息包括sex(性别)、province(省份)、city(城市)和signature(个性签名)等。
使用一个字典统计好友男性和女性的数量,用bot的friends()方法对每个微信好友进行遍历,对男女数量进行加一操作。
def show_sex_ratio(my_friends): # 使用一个字典统计好友男性和女性的数量 sex_dict={'male':0,'female':0} for friend in my_friends: if friend.sex==1: sex_dict['male']+=1 elif friend.sex==2: sex_dict['female'] += 1 print(sex_dict)
使用一个字典统计各省好友数量,用bot的friends()方法对每个微信好友进行遍历,对所属省份进行加一操作,最后用列表存储字典,形成json数据。
def show_area_distribution(my_friends): # 使用一个字典统计各省好友数量 province_dict = {'北京': 0, '上海': 0, '天津': 0, '重庆': 0, '河北': 0, '山西': 0, '吉林': 0, '辽宁': 0, '黑龙江': 0, '陕西': 0, '甘肃': 0, '青海': 0, '山东': 0, '福建': 0, '浙江': 0, '台湾': 0, '河南': 0, '湖北': 0, '湖南': 0, '江西': 0, '江苏': 0, '安徽': 0, '广东': 0, '海南': 0, '四川': 0, '贵州': 0, '云南': 0, '内蒙古': 0, '新疆': 0, '宁夏': 0, '广西': 0, '西藏': 0, '香港': 0, '澳门': 0} # 统计省份 for friend in my_friends: if friend.province in province_dict.keys(): province_dict[friend.province] += 1 # 为了方便数据的呈现,生成JSON Array格式数据 data = [] for key, value in province_dict.items(): data.append({'name': key, 'value': value}) print(data)
首先对friends()方法的signature属性进行清洗以及保存,然后对微信好友个性签名全部内容signatures.txt文件jieba处理、停用词处理、关键词前20排序、词云化展示。
def show_signature(friends): # 统计签名 for friend in friends: # 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除 pattern = re.compile(r'[一-龥]+') filterdata = re.findall(pattern, friend.signature) #设置合理的爬取间隔 # time.sleep(random.random() * 3) write_txt_file('signatures.txt', ''.join(filterdata)) content = read_txt_file('signatures.txt') content=jieba.lcut(content) with open('stops_chinese.txt', 'r', encoding='utf8') as f: stop = f.read() tokens = [token for token in content if token not in stop] contentdict = {} #对内容进行排序 for i in tokens: contentdict[i] = tokens.count(i) contentsort = list(contentdict.items()) contentsort.sort(key=lambda x: x[1], reverse=True) #把内容数量保存csv文件 # pandas.DataFrame(data=contentsort).to_csv('F:\\zyx\\wechat.csv', encoding='utf-8') # 显示词云 content = " ".join(tokens) mywc = WordCloud().generate(content) plt.imshow(mywc) plt.axis("off") plt.show() # mywc.to_file(r'C:\Users\ASUS\Desktop\\zyx.png') print(contentsort) return contentsort
- 主要代码
import re import sqlite3 import pymysql from sqlalchemy import create_engine import jieba import pandas from wxpy import * import pandas as pd import matplotlib.pyplot as plt from wordcloud import WordCloud import time import random #使用sqlite数据库保存数据 def createsql(contentsort): #创建二维表 wcdf = pd.DataFrame(contentsort) #连接数据库,没有就创建 with sqlite3.connect('wechat.sqlite')as db: wcdf.to_sql('wc', con=db) #使用mysql数据库保存数据 def createsql1(contentsort): wcdf = pd.DataFrame(contentsort) coninfo = "mysql+pymysql://root:ROOT@localhost:3306/wechat?charset=utf8" #连接数据库 engine = create_engine(coninfo, encoding="utf-8") wcdf.to_sql(name='news22', con=engine, if_exists='append', index=False, index_label='id') #读取数据库 def readsql(): with sqlite3.connect('wechat.sqlite')as db: df = pd.read_sql_query('SELECT * FROM wc', con=db) print(df) #写入txt文本,path为输出路径,txt为个性签名内容 def write_txt_file(path, txt): with open(path, 'a', encoding='utf8', newline='') as f: f.write(txt) #读取txt文本 def read_txt_file(path): with open(path, 'r', encoding='utf8', newline='') as f: return f.read() #扫码登录 def login(): # 初始化机器人,扫码登陆 bot=Bot() # 获取所有好友信息 my_friends=bot.friends() return my_friends #统计性别数量 def show_sex_ratio(my_friends): # 使用一个字典统计好友男性和女性的数量 sex_dict={'male':0,'female':0} for friend in my_friends: if friend.sex==1: sex_dict['male']+=1 elif friend.sex==2: sex_dict['female'] += 1 print(sex_dict) #统计省份数量 def show_area_distribution(my_friends): # 使用一个字典统计各省好友数量 province_dict = {'北京': 0, '上海': 0, '天津': 0, '重庆': 0, '河北': 0, '山西': 0, '吉林': 0, '辽宁': 0, '黑龙江': 0, '陕西': 0, '甘肃': 0, '青海': 0, '山东': 0, '福建': 0, '浙江': 0, '台湾': 0, '河南': 0, '湖北': 0, '湖南': 0, '江西': 0, '江苏': 0, '安徽': 0, '广东': 0, '海南': 0, '四川': 0, '贵州': 0, '云南': 0, '内蒙古': 0, '新疆': 0, '宁夏': 0, '广西': 0, '西藏': 0, '香港': 0, '澳门': 0} # 统计省份 for friend in my_friends: if friend.province in province_dict.keys(): province_dict[friend.province] += 1 # 为了方便数据的呈现,生成JSON Array格式数据 data = [] for key, value in province_dict.items(): data.append({'name': key, 'value': value}) print(data) #统计个性签名内容 def show_signature(friends): # 统计签名 for friend in friends: # 对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除 pattern = re.compile(r'[一-龥]+') filterdata = re.findall(pattern, friend.signature) #设置合理的爬取间隔 time.sleep(random.random() * 3) write_txt_file('signatures.txt', ''.join(filterdata)) content = read_txt_file('signatures.txt') content=jieba.lcut(content) with open('stops_chinese.txt', 'r', encoding='utf8') as f: stop = f.read() tokens = [token for token in content if token not in stop] contentdict = {} #对内容进行排序 for i in tokens: contentdict[i] = tokens.count(i) contentsort = list(contentdict.items()) contentsort.sort(key=lambda x: x[1], reverse=True) #把内容数量保存csv文件 pandas.DataFrame(data=contentsort).to_csv('F:\\zyx\\wechat.csv', encoding='utf-8') # 显示词云 content = " ".join(tokens) mywc = WordCloud().generate(content) plt.imshow(mywc) plt.axis("off") plt.show() mywc.to_file(r'C:\Users\ASUS\Desktop\\zyx.png') print(contentsort) return contentsort if __name__ == '__main__': friends = login() show_sex_ratio(friends) show_area_distribution(friends) sign=show_signature(friends) cs = createsql(sign)
- 可视化处理
性别数量

采用 ECharts饼图进行数据的呈现,下面是微信好友性别比例数据和数据图。


option = { title : { text: '微信好友性别比例', subtext: '真实数据', x:'center' }, tooltip : { trigger: 'item', formatter: "{a} <br/>{b} : {c} ({d}%)" }, legend: { orient : 'vertical', x : 'left', data:['男性','女性'] }, toolbox: { show : true, feature : { mark : {show: true}, dataView : {show: true, readOnly: false}, magicType : { show: true, type: ['pie', 'funnel'], option: { funnel: { x: '25%', width: '50%', funnelAlign: 'left', max: 1548 } } }, restore : {show: true}, saveAsImage : {show: true} } }, calculable : true, series : [ { name:'访问来源', type:'pie', radius : '55%', center: ['50%', '60%'], data:[ {value:320, name:'男性'}, {value:274, name:'女性'} ] } ] };
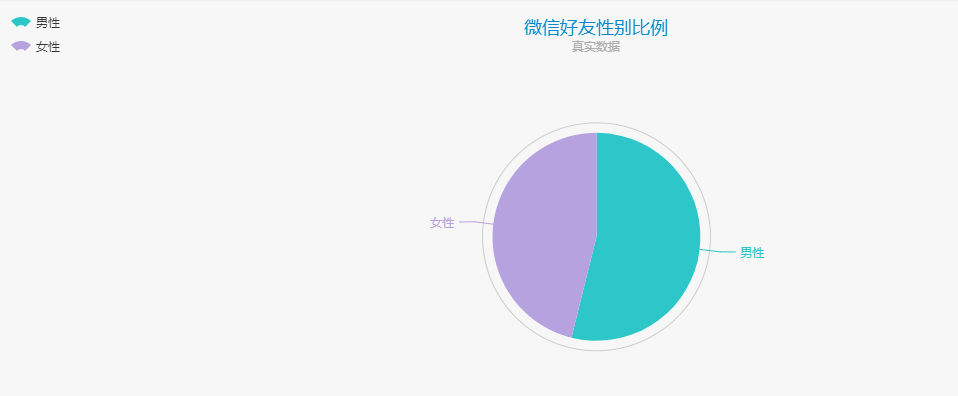
由图可知,我的微信好友中男性的数量大于女性的数量,当然这个局限于我,我没有爬取所有用户进行统计,这个与自己的性别、交友兴趣和生活圈等有关。
省份数量分布
采用 ECharts饼图进行数据的呈现,下面是微信好友全国分布数据和数据图,从图中可以看出我的好友主要分布在广东。可以看出,一个人的交际圈与所在地域有关,因为当地主要是当地人的生活地,大多数人留在自己的出生地,这就影响了自己认识的地域好友。
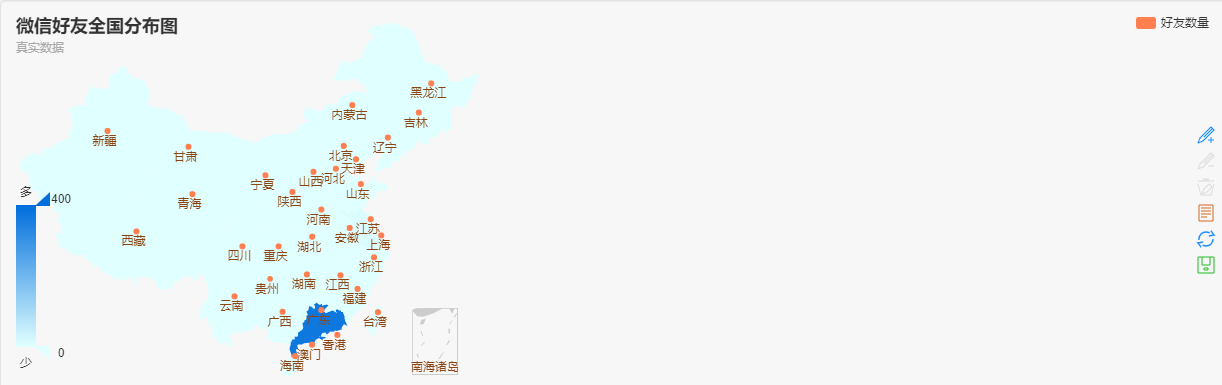
个性签名
个性签名词云生成图
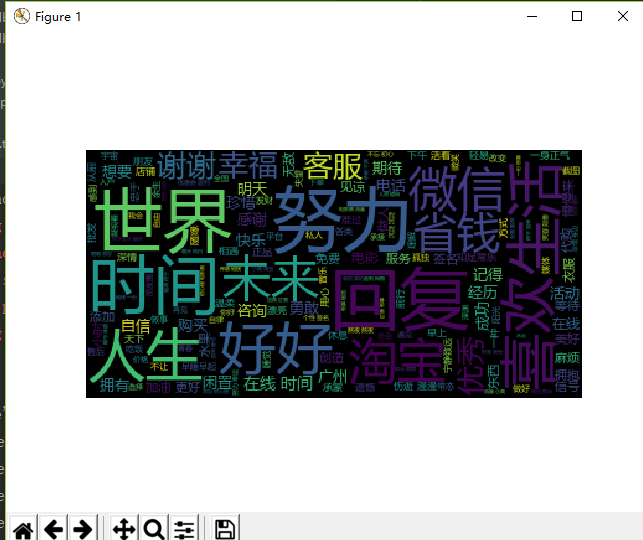
从词云图可以分析好友特点:
-
世界--------------------理想派
-
时间--------------------珍惜当下
-
人生--------------------奋斗
-
努力--------------------上进心
-
未来--------------------有目标
-
淘宝--------------------购物族
-
喜欢--------------------爱好
个性签名top20csv文件
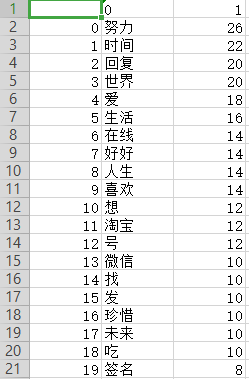
三、总结
1.wxpy的功能:登录、获取好友信息、发送消息、回复好友消息、聊天、查看公众号信息等等,wxpy还是挺好玩的,微信里面还有很多资源值得我们去获取。
2.通过对微信中的好友男女数量,省份分布数量,个性签名进行爬取,我知道了具体的情况,这让我对自己的微信好友总体情况加深了了解,后续会对qq群、微博评论进行爬虫学习,以达到巩固知识的效果。
3.在这次作业的过程中,我遇到了保存到mysql数据库表没有内容的问题,后面发现是数据库软件的问题,也遇到了不能解决的问题,例如词云定义背景图片scipy版本不支持的问题,但是这锻炼了我寻找办法、解决问题的能力。
