













这次作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822
一、中文词频统计
1. 下载一长篇中文小说。
2. 从文件读取待分析文本。
3. 安装并使用jieba进行中文分词。
pip install jieba
import jieba
jieba.lcut(text)
4. 更新词库,加入所分析对象的专业词汇。
jieba.add_word('天罡北斗阵') #逐个添加
jieba.load_userdict(word_dict) #词库文本文件
参考词库下载地址:https://pinyin.sogou.com/dict/
转换代码:scel_to_text
5. 生成词频统计
6. 排序
7. 排除语法型词汇,代词、冠词、连词等停用词。
8. 输出词频最大TOP20,把结果存放到文件里
9. 生成词云。
二、实现
1.用到的小说为《西游记》,路径为C:\Users\ASUS\PycharmProjects\untitled1\xiyouji.txt.

2.读取小说文件
with open(r'xiyouji.txt', 'r', encoding='utf8') as f: book = f.read()
3.安装jieba,在pycharm中查看
进行中文分词:
book=jieba.lcut(book)
4.更新词库,jieba.add_word('') 逐个添加,jieba.load_userdict('.txt') 从词库文本文件导入,用到的专业词汇文本为西游记官方推荐.scel,转换scel格式文本为西游记.txt
jieba.add_word('义结孔怀') jieba.load_userdict(r'西游记.txt')



# -*- coding: utf-8 -*- import struct import os # 拼音表偏移, startPy = 0x1540; # 汉语词组表偏移 startChinese = 0x2628; # 全局拼音表 GPy_Table = {} # 解析结果 # 元组(词频,拼音,中文词组)的列表 # 原始字节码转为字符串 def byte2str(data): pos = 0 str = '' while pos < len(data): c = chr(struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0]) if c != chr(0): str += c pos += 2 return str # 获取拼音表 def getPyTable(data): data = data[4:] pos = 0 while pos < len(data): index = struct.unpack('H', bytes([data[pos],data[pos + 1]]))[0] pos += 2 lenPy = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] pos += 2 py = byte2str(data[pos:pos + lenPy]) GPy_Table[index] = py pos += lenPy # 获取一个词组的拼音 def getWordPy(data): pos = 0 ret = '' while pos < len(data): index = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] ret += GPy_Table[index] pos += 2 return ret # 读取中文表 def getChinese(data): GTable = [] pos = 0 while pos < len(data): # 同音词数量 same = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 拼音索引表长度 pos += 2 py_table_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 拼音索引表 pos += 2 py = getWordPy(data[pos: pos + py_table_len]) # 中文词组 pos += py_table_len for i in range(same): # 中文词组长度 c_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 中文词组 pos += 2 word = byte2str(data[pos: pos + c_len]) # 扩展数据长度 pos += c_len ext_len = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 词频 pos += 2 count = struct.unpack('H', bytes([data[pos], data[pos + 1]]))[0] # 保存 GTable.append((count, py, word)) # 到下个词的偏移位置 pos += ext_len return GTable def scel2txt(file_name): print('-' * 60) with open(file_name, 'rb') as f: data = f.read() print("词库名:", byte2str(data[0x130:0x338])) # .encode('GB18030') print("词库类型:", byte2str(data[0x338:0x540])) print("描述信息:", byte2str(data[0x540:0xd40])) print("词库示例:", byte2str(data[0xd40:startPy])) getPyTable(data[startPy:startChinese]) getChinese(data[startChinese:]) return getChinese(data[startChinese:]) if __name__ == '__main__': # scel所在文件夹路径 in_path = r"西游记官方推荐.scel" #修改为你的词库文件存放文件夹 # 输出词典所在文件夹路径 out_path = r"西游记.txt" # 转换之后文件存放文件夹 fin = [fname for fname in os.listdir(in_path) if fname[-5:] == ".scel"] for f in fin: try: for word in scel2txt(os.path.join(in_path, f)): file_path=(os.path.join(out_path, str(f).split('.')[0] + '.txt')) # 保存结果 with open(file_path,'a+',encoding='utf-8')as file: file.write(word[2] + '\n') os.remove(os.path.join(in_path, f)) except Exception as e: print(e) pass
5.词频统计
bookdict={} for i in tokens: bookdict[i]=tokens.count(i)
6.排序
booksort = list(bookdict.items()) booksort.sort(key=lambda x: x[1], reverse=True)
7.排除停用词,用到的文本为stops_chinese.txt
with open(r'stops_chinese.txt', 'r', encoding='utf8') as f: stop=f.read() tokens=[token for token in book if token not in stop]
! " # $ % & ' ( ) * + , - -- . .. ... ...... ................... ./ .一 .数 .日 / // 0 1 2 3 4 5 6 7 8 9 : :// :: ; < = > >> ? @ A Lex [ \ ] ^ _ ` exp sub sup | } ~ ~~~~ · × ××× Δ Ψ γ μ φ φ. В — —— ——— ‘ ’ ’‘ “ ” ”, … …… …………………………………………………③ ′∈ ′| ℃ Ⅲ ↑ → ∈[ ∪φ∈ ≈ ① ② ②c ③ ③] ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ── ■ ▲ 、 。 〈 〉 《 》 》), 」 『 』 【 】 〔 〕 〕〔 ㈧ 一 一. 一一 一下 一个 一些 一何 一切 一则 一则通过 一天 一定 一方面 一旦 一时 一来 一样 一次 一片 一番 一直 一致 一般 一起 一转眼 一边 一面 七 万一 三 三天两头 三番两次 三番五次 上 上下 上升 上去 上来 上述 上面 下 下列 下去 下来 下面 不 不一 不下 不久 不了 不亦乐乎 不仅 不仅...而且 不仅仅 不仅仅是 不会 不但 不但...而且 不光 不免 不再 不力 不单 不变 不只 不可 不可开交 不可抗拒 不同 不外 不外乎 不够 不大 不如 不妨 不定 不对 不少 不尽 不尽然 不巧 不已 不常 不得 不得不 不得了 不得已 不必 不怎么 不怕 不惟 不成 不拘 不择手段 不敢 不料 不断 不日 不时 不是 不曾 不止 不止一次 不比 不消 不满 不然 不然的话 不特 不独 不由得 不知不觉 不管 不管怎样 不经意 不胜 不能 不能不 不至于 不若 不要 不论 不起 不足 不过 不迭 不问 不限 与 与其 与其说 与否 与此同时 专门 且 且不说 且说 两者 严格 严重 个 个人 个别 中小 中间 丰富 串行 临 临到 为 为主 为了 为什么 为什麽 为何 为止 为此 为着 主张 主要 举凡 举行 乃 乃至 乃至于 么 之 之一 之前 之后 之後 之所以 之类 乌乎 乎 乒 乘 乘势 乘机 乘胜 乘虚 乘隙 九 也 也好 也就是说 也是 也罢 了 了解 争取 二 二来 二话不说 二话没说 于 于是 于是乎 云云 云尔 互 互相 五 些 交口 亦 产生 亲口 亲手 亲眼 亲自 亲身 人 人人 人们 人家 人民 什么 什么样 什麽 仅 仅仅 今 今后 今天 今年 今後 介于 仍 仍旧 仍然 从 从不 从严 从中 从事 从今以后 从优 从古到今 从古至今 从头 从宽 从小 从新 从无到有 从早到晚 从未 从来 从此 从此以后 从而 从轻 从速 从重 他 他人 他们 他是 他的 代替 以 以上 以下 以为 以便 以免 以前 以及 以后 以外 以後 以故 以期 以来 以至 以至于 以致 们 任 任何 任凭 任务 企图 伙同 会 伟大 传 传说 传闻 似乎 似的 但 但凡 但愿 但是 何 何乐而不为 何以 何况 何处 何妨 何尝 何必 何时 何止 何苦 何须 余外 作为 你 你们 你是 你的 使 使得 使用 例如 依 依据 依照 依靠 便 便于 促进 保持 保管 保险 俺 俺们 倍加 倍感 倒不如 倒不如说 倒是 倘 倘使 倘或 倘然 倘若 借 借以 借此 假使 假如 假若 偏偏 做到 偶尔 偶而 傥然 像 儿 允许 元/吨 充其极 充其量 充分 先不先 先后 先後 先生 光 光是 全体 全力 全年 全然 全身心 全部 全都 全面 八 八成 公然 六 兮 共 共同 共总 关于 其 其一 其中 其二 其他 其余 其后 其它 其实 其次 具体 具体地说 具体来说 具体说来 具有 兼之 内 再 再其次 再则 再有 再次 再者 再者说 再说 冒 冲 决不 决定 决非 况且 准备 凑巧 凝神 几 几乎 几度 几时 几番 几经 凡 凡是 凭 凭借 出 出于 出去 出来 出现 分别 分头 分期 分期分批 切 切不可 切切 切勿 切莫 则 则甚 刚 刚好 刚巧 刚才 初 别 别人 别处 别是 别的 别管 别说 到 到了儿 到处 到头 到头来 到底 到目前为止 前后 前此 前者 前进 前面 加上 加之 加以 加入 加强 动不动 动辄 勃然 匆匆 十分 千 千万 千万千万 半 单 单单 单纯 即 即令 即使 即便 即刻 即如 即将 即或 即是说 即若 却 却不 历 原来 去 又 又及 及 及其 及时 及至 双方 反之 反之亦然 反之则 反倒 反倒是 反应 反手 反映 反而 反过来 反过来说 取得 取道 受到 变成 古来 另 另一个 另一方面 另外 另悉 另方面 另行 只 只当 只怕 只是 只有 只消 只要 只限 叫 叫做 召开 叮咚 叮当 可 可以 可好 可是 可能 可见 各 各个 各人 各位 各地 各式 各种 各级 各自 合理 同 同一 同时 同样 后 后来 后者 后面 向 向使 向着 吓 吗 否则 吧 吧哒 吱 呀 呃 呆呆地 呐 呕 呗 呜 呜呼 呢 周围 呵 呵呵 呸 呼哧 呼啦 咋 和 咚 咦 咧 咱 咱们 咳 哇 哈 哈哈 哉 哎 哎呀 哎哟 哗 哗啦 哟 哦 哩 哪 哪个 哪些 哪儿 哪天 哪年 哪怕 哪样 哪边 哪里 哼 哼唷 唉 唯有 啊 啊呀 啊哈 啊哟 啐 啥 啦 啪达 啷当 喀 喂 喏 喔唷 喽 嗡 嗡嗡 嗬 嗯 嗳 嘎 嘎嘎 嘎登 嘘 嘛 嘻 嘿 嘿嘿 四 因 因为 因了 因此 因着 因而 固 固然 在 在下 在于 地 均 坚决 坚持 基于 基本 基本上 处在 处处 处理 复杂 多 多么 多亏 多多 多多少少 多多益善 多少 多年前 多年来 多数 多次 够瞧的 大 大不了 大举 大事 大体 大体上 大凡 大力 大多 大多数 大大 大家 大张旗鼓 大批 大抵 大概 大略 大约 大致 大都 大量 大面儿上 失去 奇 奈 奋勇 她 她们 她是 她的 好 好在 好的 好象 如 如上 如上所述 如下 如今 如何 如其 如前所述 如同 如常 如是 如期 如果 如次 如此 如此等等 如若 始而 姑且 存在 存心 孰料 孰知 宁 宁可 宁愿 宁肯 它 它们 它们的 它是 它的 安全 完全 完成 定 实现 实际 宣布 容易 密切 对 对于 对应 对待 对方 对比 将 将才 将要 将近 小 少数 尔 尔后 尔尔 尔等 尚且 尤其 就 就地 就是 就是了 就是说 就此 就算 就要 尽 尽可能 尽如人意 尽心尽力 尽心竭力 尽快 尽早 尽然 尽管 尽管如此 尽量 局外 居然 届时 属于 屡 屡屡 屡次 屡次三番 岂 岂但 岂止 岂非 川流不息 左右 巨大 巩固 差一点 差不多 己 已 已矣 已经 巴 巴巴 带 帮助 常 常常 常言说 常言说得好 常言道 平素 年复一年 并 并不 并不是 并且 并排 并无 并没 并没有 并肩 并非 广大 广泛 应当 应用 应该 庶乎 庶几 开外 开始 开展 引起 弗 弹指之间 强烈 强调 归 归根到底 归根结底 归齐 当 当下 当中 当儿 当前 当即 当口儿 当地 当场 当头 当庭 当时 当然 当真 当着 形成 彻夜 彻底 彼 彼时 彼此 往 往往 待 待到 很 很多 很少 後来 後面 得 得了 得出 得到 得天独厚 得起 心里 必 必定 必将 必然 必要 必须 快 快要 忽地 忽然 怎 怎么 怎么办 怎么样 怎奈 怎样 怎麽 怕 急匆匆 怪 怪不得 总之 总是 总的来看 总的来说 总的说来 总结 总而言之 恍然 恐怕 恰似 恰好 恰如 恰巧 恰恰 恰恰相反 恰逢 您 您们 您是 惟其 惯常 意思 愤然 愿意 慢说 成为 成年 成年累月 成心 我 我们 我是 我的 或 或则 或多或少 或是 或曰 或者 或许 战斗 截然 截至 所 所以 所在 所幸 所有 所谓 才 才能 扑通 打 打从 打开天窗说亮话 扩大 把 抑或 抽冷子 拦腰 拿 按 按时 按期 按照 按理 按说 挨个 挨家挨户 挨次 挨着 挨门挨户 挨门逐户 换句话说 换言之 据 据实 据悉 据我所知 据此 据称 据说 掌握 接下来 接着 接著 接连不断 放量 故 故意 故此 故而 敞开儿 敢 敢于 敢情 数/ 整个 断然 方 方便 方才 方能 方面 旁人 无 无宁 无法 无论 既 既...又 既往 既是 既然 日复一日 日渐 日益 日臻 日见 时候 昂然 明显 明确 是 是不是 是以 是否 是的 显然 显著 普通 普遍 暗中 暗地里 暗自 更 更为 更加 更进一步 曾 曾经 替 替代 最 最后 最大 最好 最後 最近 最高 有 有些 有关 有利 有力 有及 有所 有效 有时 有点 有的 有的是 有着 有著 望 朝 朝着 末##末 本 本人 本地 本着 本身 权时 来 来不及 来得及 来看 来着 来自 来讲 来说 极 极为 极了 极其 极力 极大 极度 极端 构成 果然 果真 某 某个 某些 某某 根据 根本 格外 梆 概 次第 欢迎 欤 正值 正在 正如 正巧 正常 正是 此 此中 此后 此地 此处 此外 此时 此次 此间 殆 毋宁 每 每个 每天 每年 每当 每时每刻 每每 每逢 比 比及 比如 比如说 比方 比照 比起 比较 毕竟 毫不 毫无 毫无例外 毫无保留地 汝 沙沙 没 没奈何 没有 沿 沿着 注意 活 深入 清楚 满 满足 漫说 焉 然 然则 然后 然後 然而 照 照着 牢牢 特别是 特殊 特点 犹且 犹自 独 独自 猛然 猛然间 率尔 率然 现代 现在 理应 理当 理该 瑟瑟 甚且 甚么 甚或 甚而 甚至 甚至于 用 用来 甫 甭 由 由于 由是 由此 由此可见 略 略为 略加 略微 白 白白 的 的确 的话 皆可 目前 直到 直接 相似 相信 相反 相同 相对 相对而言 相应 相当 相等 省得 看 看上去 看出 看到 看来 看样子 看看 看见 看起来 真是 真正 眨眼 着 着呢 矣 矣乎 矣哉 知道 砰 确定 碰巧 社会主义 离 种 积极 移动 究竟 穷年累月 突出 突然 窃 立 立刻 立即 立地 立时 立马 竟 竟然 竟而 第 第二 等 等到 等等 策略地 简直 简而言之 简言之 管 类如 粗 精光 紧接着 累年 累次 纯 纯粹 纵 纵令 纵使 纵然 练习 组成 经 经常 经过 结合 结果 给 绝 绝不 绝对 绝非 绝顶 继之 继后 继续 继而 维持 综上所述 缕缕 罢了 老 老大 老是 老老实实 考虑 者 而 而且 而况 而又 而后 而外 而已 而是 而言 而论 联系 联袂 背地里 背靠背 能 能否 能够 腾 自 自个儿 自从 自各儿 自后 自家 自己 自打 自身 臭 至 至于 至今 至若 致 般的 良好 若 若夫 若是 若果 若非 范围 莫 莫不 莫不然 莫如 莫若 莫非 获得 藉以 虽 虽则 虽然 虽说 蛮 行为 行动 表明 表示 被 要 要不 要不是 要不然 要么 要是 要求 见 规定 觉得 譬喻 譬如 认为 认真 认识 让 许多 论 论说 设使 设或 设若 诚如 诚然 话说 该 该当 说明 说来 说说 请勿 诸 诸位 诸如 谁 谁人 谁料 谁知 谨 豁然 贼死 赖以 赶 赶快 赶早不赶晚 起 起先 起初 起头 起来 起见 起首 趁 趁便 趁势 趁早 趁机 趁热 趁着 越是 距 跟 路经 转动 转变 转贴 轰然 较 较为 较之 较比 边 达到 达旦 迄 迅速 过 过于 过去 过来 运用 近 近几年来 近年来 近来 还 还是 还有 还要 这 这一来 这个 这么 这么些 这么样 这么点儿 这些 这会儿 这儿 这就是说 这时 这样 这次 这点 这种 这般 这边 这里 这麽 进入 进去 进来 进步 进而 进行 连 连同 连声 连日 连日来 连袂 连连 迟早 迫于 适应 适当 适用 逐步 逐渐 通常 通过 造成 逢 遇到 遭到 遵循 遵照 避免 那 那个 那么 那么些 那么样 那些 那会儿 那儿 那时 那末 那样 那般 那边 那里 那麽 部分 都 鄙人 采取 里面 重大 重新 重要 鉴于 针对 长期以来 长此下去 长线 长话短说 问题 间或 防止 阿 附近 陈年 限制 陡然 除 除了 除却 除去 除外 除开 除此 除此之外 除此以外 除此而外 除非 随 随后 随时 随着 随著 隔夜 隔日 难得 难怪 难说 难道 难道说 集中 零 需要 非但 非常 非徒 非得 非特 非独 靠 顶多 顷 顷刻 顷刻之间 顷刻间 顺 顺着 顿时 颇 风雨无阻 饱 首先 马上 高低 高兴 默然 默默地 齐 ︿ ! # $ % & ' ( ) )÷(1- )、 * + +ξ ++ , ,也 - -β -- -[*]- . / 0 0:2 1 1. 12% 2 2.3% 3 4 5 5:0 6 7 8 9 : ; < <± <Δ <λ <φ << = =″ =☆ =( =- =[ ={ > >λ ? @ A LI R.L. ZXFITL [ [①①] [①②] [①③] [①④] [①⑤] [①⑥] [①⑦] [①⑧] [①⑨] [①A] [①B] [①C] [①D] [①E] [①] [①a] [①c] [①d] [①e] [①f] [①g] [①h] [①i] [①o] [② [②①] [②②] [②③] [②④ [②⑤] [②⑥] [②⑦] [②⑧] [②⑩] [②B] [②G] [②] [②a] [②b] [②c] [②d] [②e] [②f] [②g] [②h] [②i] [②j] [③①] [③⑩] [③F] [③] [③a] [③b] [③c] [③d] [③e] [③g] [③h] [④] [④a] [④b] [④c] [④d] [④e] [⑤] [⑤]] [⑤a] [⑤b] [⑤d] [⑤e] [⑤f] [⑥] [⑦] [⑧] [⑨] [⑩] [*] [- [] ] ]∧′=[ ][ _ a] b] c] e] f] ng昉 { {- | } }> ~ ~± ~+ ¥
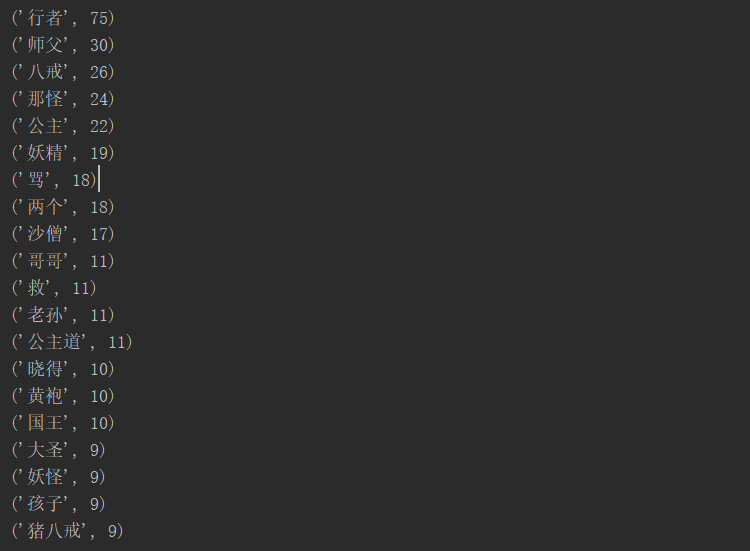
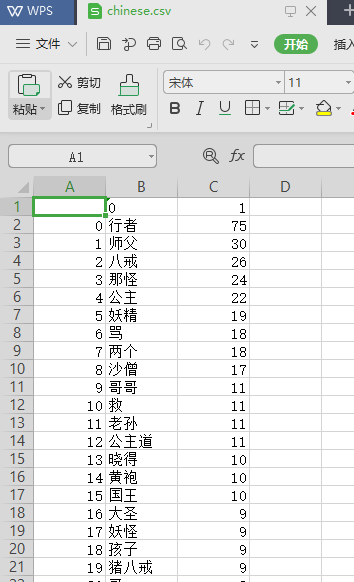
8.词频最大TOP20,输出文件为
chinese.csv
for q in range(20): print(booksort[q]) import pandas pandas.DataFrame(data=booksort).to_csv('F:\\zyx\\chinese.csv', encoding='utf-8')
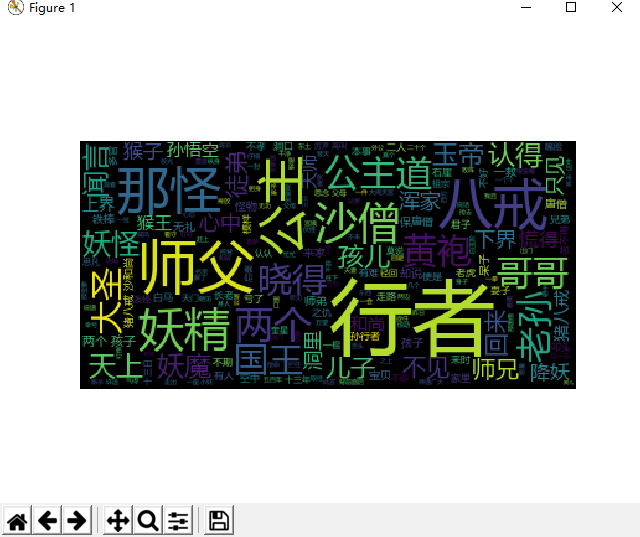
9.生成词云
(1)生成和显示词云
from wordcloud import WordCloud mywc = WordCloud().generate(cutbook) import matplotlib.pyplot as plt plt.imshow(mywc) plt.axis("off") plt.show()
(2)修改词云的显示
import imageio im = imageio.imread(r'2.png') mywc1 = WordCloud(mask=im,margin=1).generate(cutbook) import matplotlib.pyplot as plt plt.imshow(mywc1) plt.axis("off") plt.show() mywc1.to_file(r'G:\大三下学期\python\zyx1.png')

10.整体设计
import jieba with open(r'xiyouji.txt', 'r', encoding='utf8') as f: book = f.read() jieba.add_word('义结孔怀') jieba.load_userdict(r'西游记.txt') book=jieba.lcut(book) with open(r'stops_chinese.txt', 'r', encoding='utf8') as f: stop=f.read() tokens=[token for token in book if token not in stop] jieba.add_word('义结孔怀') bookdict={} for i in tokens: bookdict[i]=tokens.count(i) booksort = list(bookdict.items()) booksort.sort(key=lambda x: x[1], reverse=True) for q in range(20): print(booksort[q]) import pandas pandas.DataFrame(data=booksort).to_csv('F:\\zyx\\chinese.csv', encoding='utf-8') cutbook=" ".join(tokens) from wordcloud import WordCloud mywc = WordCloud().generate(cutbook) import matplotlib.pyplot as plt plt.imshow(mywc) plt.axis("off") plt.show() mywc.to_file(r'G:\大三下学期\python\zyx.png') from scipy.misc import imread import imageio im = imageio.imread(r'2.png') mywc1 = WordCloud(background_color='red',width=500,mask=im,margin=1).generate(cutbook) import matplotlib.pyplot as plt plt.imshow(mywc1) plt.axis("off") plt.show() mywc1.to_file(r'G:\大三下学期\python\zyx1.png')
