

hurst代码 python_浅谈Hurst指数
背景
有效市场假说和分形市场假说是资本市场两个重要的理论,有效市场假说建立在正态性的假说上,但大量证据表明,金融数据具有尖峰厚尾的特性,这也是分形市场假说的出发点。
在有效市场假说下,资产的价格具有长程相关性和标度不变性的特点,可以通过分数布朗运动对资产价格进行刻画,其他背景介绍请参考[1]。
通俗来讲,一个简单的问题是:股票市场会不会历史重演?如果会重演,就可以用历史规律的统计结果来对未来投资做指导。比如大量统计发现,历史上只要短均线上穿长均线,未来价格会上涨,那就可以在下一次再出现这一现象时候做多。
当然这个统计中一方面要统计每次出现短均线上穿长均线后上涨的次数,也就是上涨的概率(胜率),另一方面还要统计上涨的幅度和亏损幅度(盈亏比),如果总是小涨,但一跌就大跌,那盈利的概率也很小。
从量化角度可以用一些指标来刻画股票市场是不是会重演,比如相关性/周期性,当市场的相关性很高时,相似市场状态下出现相似行情的概率会很高。以最简单的自相关性为例,如果收益率的正相关性很高,会有很强的动量效应,如果负相关性很高,会有很强的反转效应。
这部分跟前面那两段的联系在于,有效市场假说下,如果市场是有效的,价格是随机游走的序列,没有相关性,但如果是分形市场假说,会认为市场存在长期的相关性/记忆性。
刚才说的自相关系数一般用来衡量时间序列的短期自相关性,而Hurst指数则是用来衡量时间序列的长期相关性。
Hurst公式
根据百度百科的说明,Hurst指数以英国水文学家哈罗德·赫斯特命名,起初被用来分析水库与河流之间的进出流量,后来被广泛用于各行各业的分形分析。
Hurst指数H位于0和1之间,当H = 0.5时,认为序列没有自相关性,H>0.5时,序列有很强的正相关性,当H<0.5时,序列有很强的负相关性。
Hurst指数的计算有多种方法,这里以最常用的重标极差法为例来说明,引自[1]。

实际计算时,还有一些细节需要考虑,比如用多长的时间段去算Hurst指数,一般是取不同长度的序列,看R/S的突变点,以此为依据估计序列的平均循环周期,在平均循环周期周围取值,或者看V统计量的突变点,这里V统计量定义为:
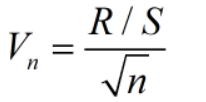
其中,R/S为平均重标极差值,n为序列长度,两种方法的理论依据可以参考[1]。
Hurst指数实例
为了说明Hurst指数刻画相关性/周期性的效果,这里做一个简单的测试,对于函数
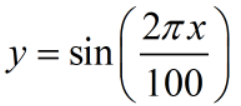
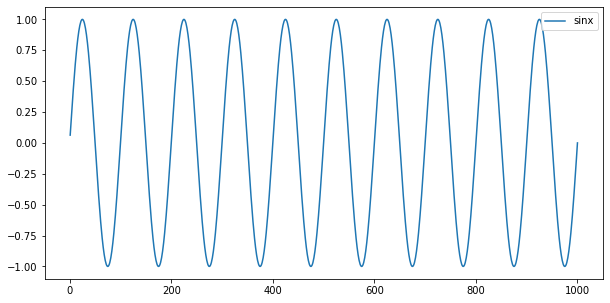
计算它的Hurst指数序列,首先估计它的平均循环周期,函数图像如下,显然周期为100。
log10(N)和log(R/S)示意图、V统计量的示意图如下
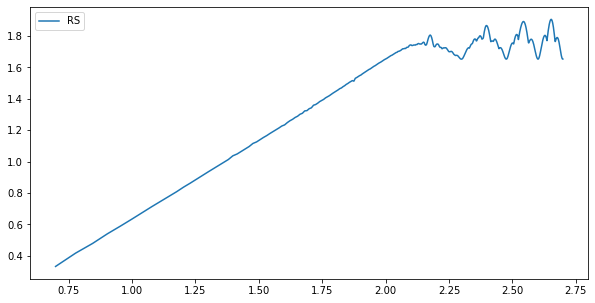
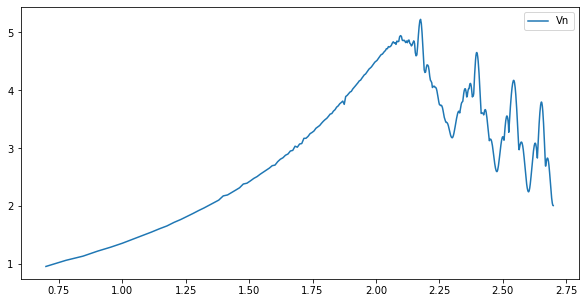
横轴都是以10为底的N的对数,可以看出,两个图都是在2附近出现了突变,表明函数的平均循环周期为100。
这里再给函数加一个标准正态的噪声
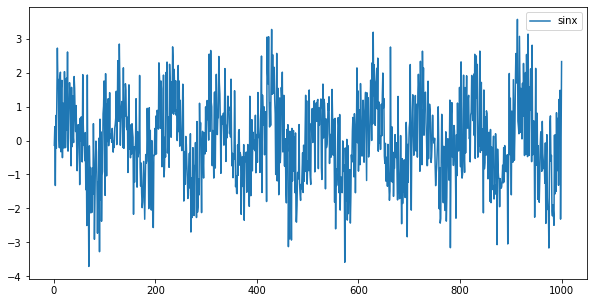
计算加噪声后的序列的平均循环周期
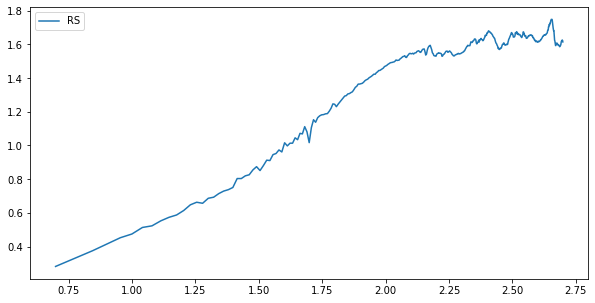
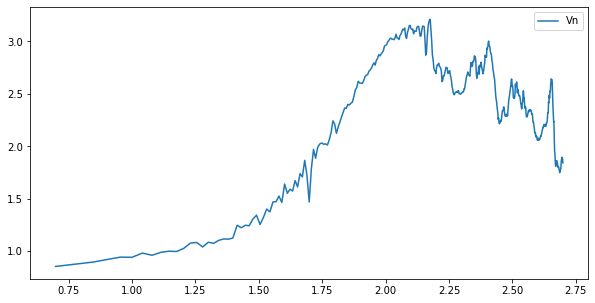
统计量会有一些波动,但结果是一致的。
分别取序列长度为50,100,150,滚动计算y = sinx的Hurst指数,Hurst指数和函数对比如下
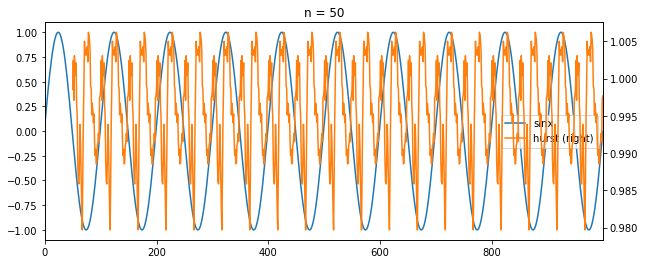
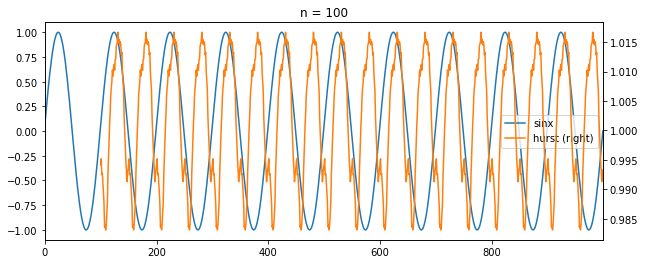
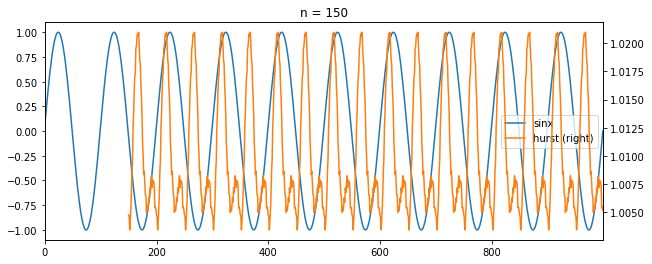
可以看出,n取的太短,小于平均循环周期,hust指数频繁波动,n取的太长,大于平均循环周期,hurst指数的趋势和函数差异比较大,hurst指数明显滞后。取100时,当sinx下降或者上升时,保持趋势性时,hurst指数会走高,sinx由升转降或由降转升时,hurst指数会下降,二者基本上是一致的。此外,hurst指数都在0.5以上,说明长记忆性很好。
上证指数Hurst指数
这里计算上证指数的日度Hurst指数,看看A股市场的长期相关性。首先分析两个统计量
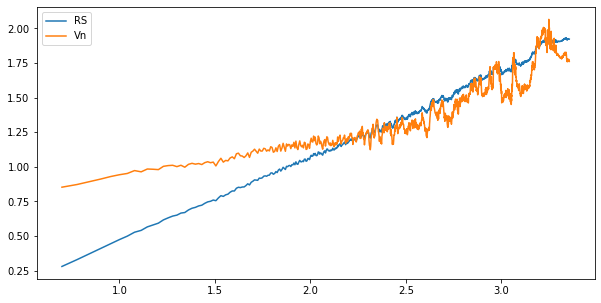
实际数据不会有sinx这么好的性质了,但也能明显看出,Vn在2之后波动率加剧,因此n至少为200,这里取n=240,结果如下,roll为hurst指数的50日移动平均。
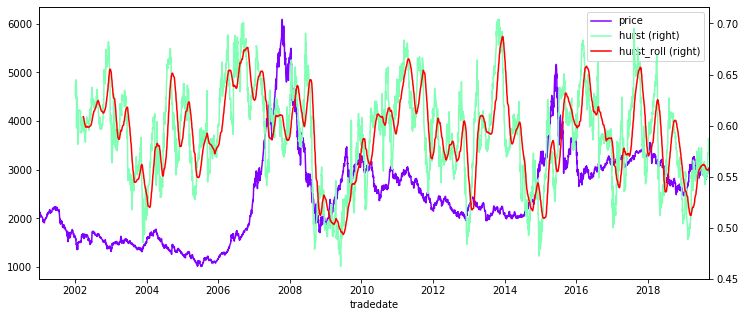
a股大部分时间的Hurst指数都是在0.5以上的,平均hurst指数为0.59,表明A股有很强的记忆性。
Hurst指数模拟
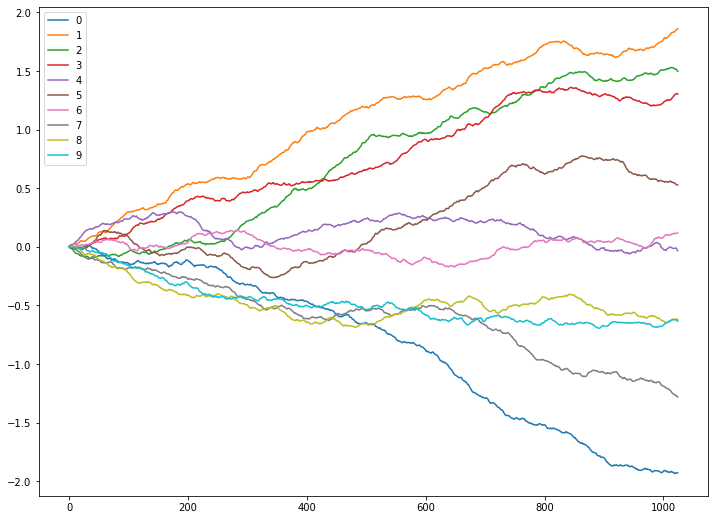
这里为了更直观的说明,不同Hurst指数下序列的性质,我们用python中的fbm包模拟不同Hurst指数下的序列,每个取值下模拟若干次,结果如下
Hurst = 0.2,一片混沌,涨了跌,跌了涨
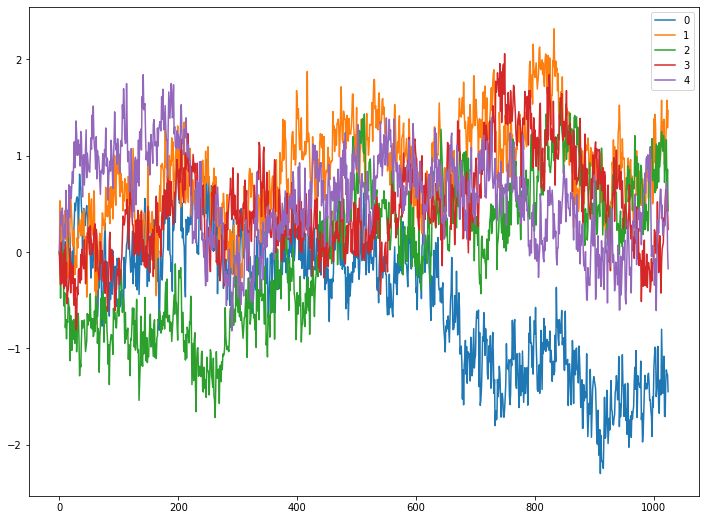
Hurst = 0.4
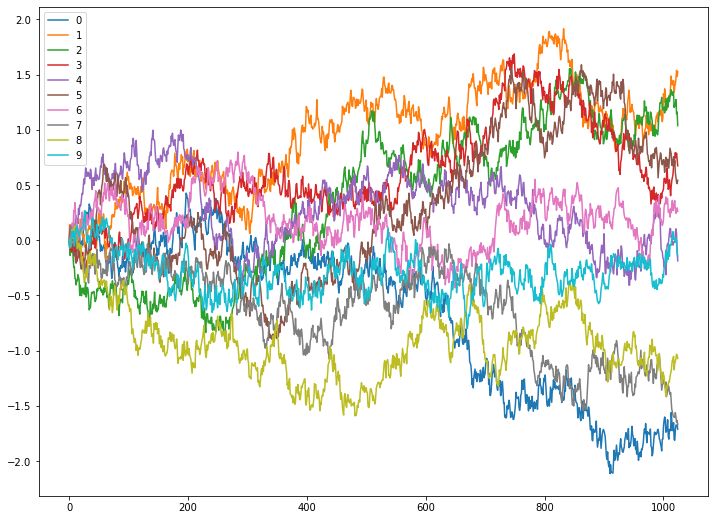
Hurst = 0.5
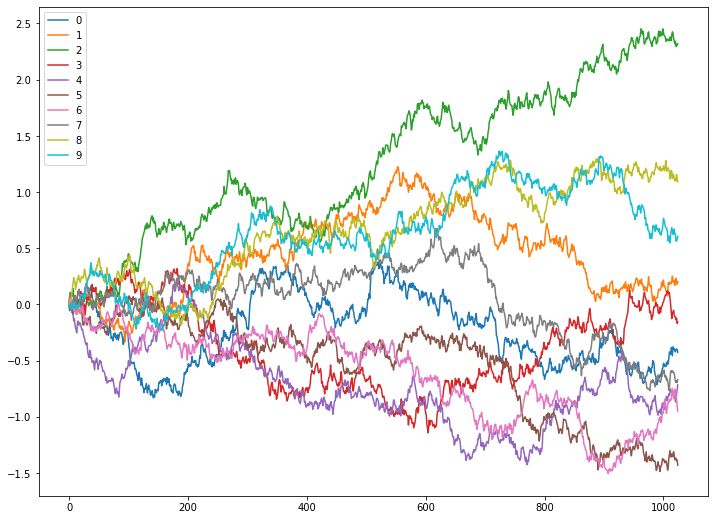
Hurst = 0.6
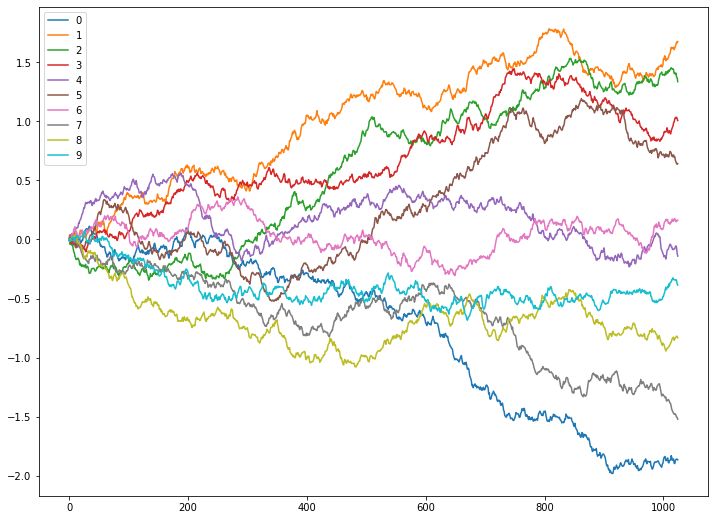
Hurst = 0.8
代码
hurst指数计算
# -*- coding: utf-8 -*-import numpy as npimport pandas as pddef hurst(ts,if_detail = False): N = len(ts) if N < 20: raise ValueError("Time series is too short! input series ought to have at least 20 samples!") max_k = int(np.floor(N/2)) n_all = [] RS_all = [] # k是子区间长度 for k in range(5,max_k+1): subset_list = np.array(ts[:N - N%k]).reshape(-1,k).T # 累积极差 cumsum_list = (subset_list - subset_list.mean(axis = 0)).cumsum(axis = 0) R = cumsum_list.max(axis =0) - cumsum_list.min(axis = 0) S = (((subset_list - subset_list.mean(axis = 0))**2).mean(axis = 0))**0.5 RS = (R/S).mean() n_all.append(k) RS_all.append(RS)# print(k)# R_S_all = pd.DataFrame(R_S_all)## R_S_all['logN'] = np.log10(R_S_all.n)# R_S_all['logRS'] = np.log10(R_S_all.RS) Hurst_exponent = np.polyfit(np.log10(n_all),np.log10(RS_all),1)[0] if if_detail: n_all = np.array(n_all) RS_all = np.array(RS_all) Vn = RS_all/np.sqrt(n_all) res = pd.DataFrame([n_all,RS_all,Vn]).T res.columns = ['n','RS','Vn'] return res,Hurst_exponent# plt.plot(R_S_all.logN,R_S_all.logRS) else: return Hurst_exponent
sinx模拟
flags = 0x = np.arange(1,1001)/100sinx = np.sin(2*np.pi*x) + np.random.normal(0,1,(1000))*flagsres,Hurst_exponent = hurst(sinx,if_detail = True)plt.figure(figsize = (10,5))plt.plot(np.arange(1,1001),sinx,label = 'sinx')plt.legend()plt.figure(figsize = (10,5))plt.plot(np.log10(res.n),np.log10(res.RS),label = 'RS')plt.legend()plt.figure(figsize = (10,5))plt.plot(np.log10(res.n),res.Vn,label = 'Vn')plt.legend()#allhurst_vol = np.zeros(ret.shape[0])*np.nann = 100sinx1 = sinxallhurst = np.zeros(sinx1.shape[0])*np.nanfor k in range(n,allhurst.shape[0]): allhurst[k] = hurst(sinx[k - n :k],False)allres = pd.DataFrame()allres['sinx'] = sinx1allres['hurst'] = allhurstallres.plot(secondary_y = ['hurst'],figsize = (10,4))plt.title('n = 100')
参考文献
[1]20170802-中信建投-中信建投金融工程研究:深度解析Hurst模型的打开方式
————————————————
版权声明:本文为CSDN博主「砺石商业评论」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42394780/article/details/112090639
