
sklearn中的数据预处理
一、数据挖掘的五大流程:
1、获取数据 2、数据预处理 3、特征工程 4、建模,测试模型并预测结果 5、 上线,验证模型效果
二、数据预处理
Ⅰ、 数据无量纲化
定义:
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布
的需求,这种需求统称为将数据“无量纲化”。
sklearn中的函数:
1、preprocessing.MinMaxScaler(x)
数据归一化,一般成为Normalization,又称Min-Max Scaling。公式如下:
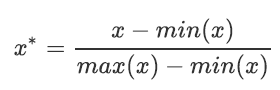
重要参数:
feature_range, 这个参数控制着我们希望把数据压缩到的范围,默认为[0,1], 也可改为其他范围,比如[10,15]。
实例:

1 from sklearn.preprocessing import MinMaxScaler 2 data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] 3 #将数据转化为二维的DataFrame,更容易查看 4 #如果换成表是什么样子? 5 import pandas as pd 6 pd.DataFrame(data) 7 #实现归一化 8 scaler = MinMaxScaler() #实例化 9 scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x) 10 result = scaler.transform(data) #通过接口导出结果 11 result 12 result_ = scaler.fit_transform(data) #训练和导出结果一步达成 13 scaler.inverse_transform(result) #将归一化后的结果逆转 14 #使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外#的范围中 15 data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] 16 scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化 17 result = scaler.fit_transform(data) #fit_transform一步导出结果 18 result 19 #当X中的特征数量非常多的时候,fit会报错并表示,数据量太大了我计算不了 20 #此时使用partial_fit作为训练接口 21 #scaler = scaler.partial_fit(data)
2、preprocessing.StandardScaler(x)
定义:
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分
布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
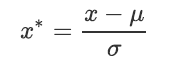
实例:
1 from sklearn.preprocessing import StandardScaler 2 data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
3 scaler = StandardScaler() #实例化
4 scaler.fit(data) #fit,本质是生成均值和方差 5 scaler.mean_ #查看均值的属性mean_ 6 scaler.var_ #查看方差的属性var_ 7 x_std = scaler.transform(data) #通过接口导出结果 8 x_std.mean() #导出的结果是一个数组,用mean()查看均值 9 x_std.std() #用std()查看方差
10 scaler.fit_transform(data) #使用fit_transform(data)一步达成结果 11 scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化
3、processing.MinMaxScaler()和processing.StandardScaler()
3.1、两种方法对空值NaN的处理
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候
保持缺失NaN的状态显示。并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数
组,一维数组导入会报错。通常来说,我们输入的X会是我们的特征矩阵,现实案例中特征矩阵不太可能是一维所
以不会存在这个问题。
3.2、StandardScaler()和MinMaxScaler()选哪个?
(1)看情况。大多数机器学习算法中,会选择StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏
感。在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择。
(2)MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像
处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中。
(3)建议先试试看StandardScaler,效果不好换MinMaxScaler。
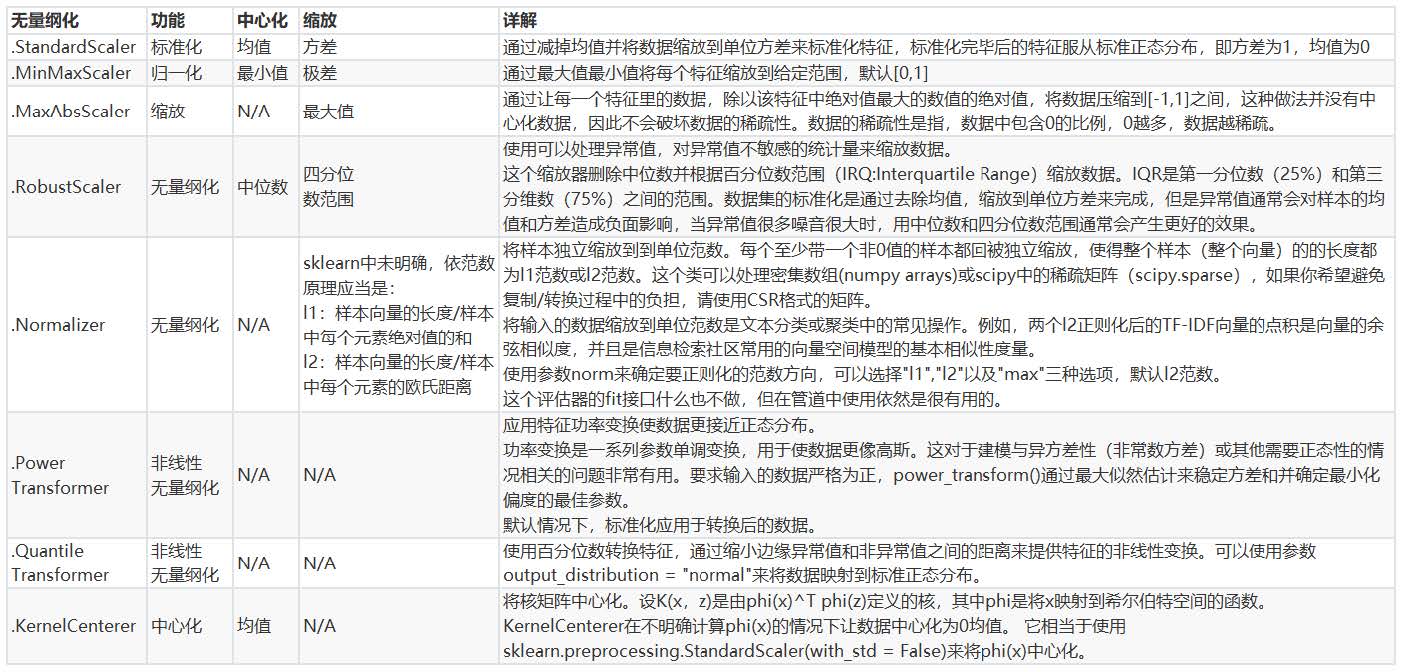
(4)除了StandardScaler和MinMaxScaler之外,sklearn中也提供了各种其他缩放处理(中心化只需要一个pandas广
播一下减去某个数就好了,因此sklearn不提供任何中心化功能)。比如,在希望压缩数据,却不影响数据的稀疏
性时(不影响矩阵中取值为0的个数时),我们会使用MaxAbsScaler;在异常值多,噪声非常大时,我们可能会选
用分位数来无量纲化,此时使用RobustScaler。更多详情请参考以下列表。
Ⅱ、 缺失值的处理
1、为什么要处理缺失值?
机器学习中数据永远不可能是完美的,在不舍弃该特征的情况下,处理缺失值是数据预处理过程中非常重要的一项。
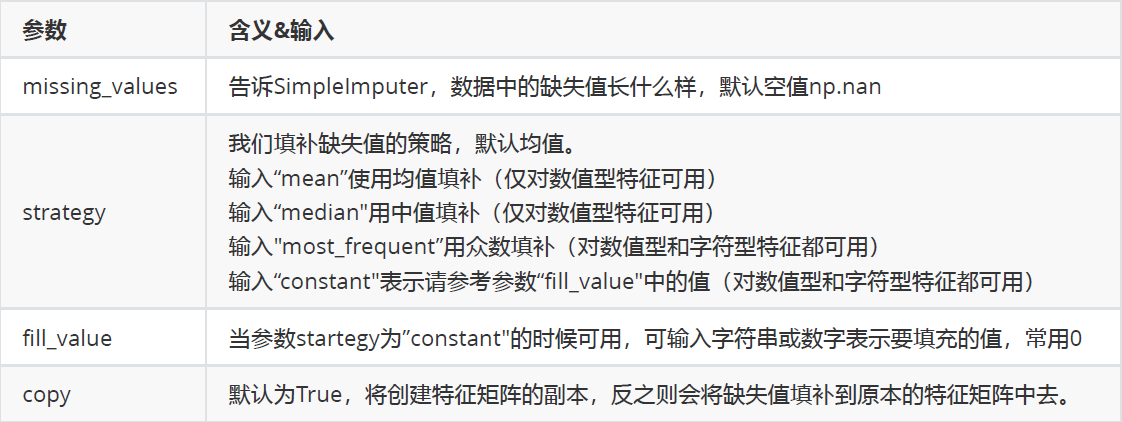
2、sklearn中用到的函数:impute.SimpleImputer()
详解:
class sklearn.impute.SimpleImputer (missing_values=nan, strategy=’mean’, fill_value=None, verbose=0,copy=True)
参数:
3、处理缺失值也可以用Pandas和Numpy进行填补
1 import pandas as pd 2 data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 3 3 Preprocessing\Narrativedata.csv",index_col=0) 4 data.head() 5 data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median()) 6 #.fillna 在DataFrame里面直接进行填补 7 data.dropna(axis=0,inplace=True) 8 #.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列 9 #参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False
Ⅲ、处理分类型特征:编码与哑变量
1、为什么要处理分类型特征?
现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是["小
学",“初中”,“高中”,"大学"],付费方式可能包含["支付宝",“现金”,“微信”]等等。在这种情况下,为了让数据适
应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
sklearn中规定必须导入数值型。
2、preprocessing.LabelEncoder: 标签专用,能够将分类转换为分类数值。
1 from sklearn.preprocessing import LabelEncoder 2 y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维 3 le = LabelEncoder() #实例化 4 le = le.fit(y) #导入数据 5 label = le.transform(y) #transform接口调取结果 6 le.classes_ #属性.classes_查看标签中究竟有多少类别 7 label #查看获取的结果label
8 le.fit_transform(y) #也可以直接fit_transform一步到位 9 le.inverse_transform(label) #使用inverse_transform可以逆转
10 data.iloc[:,-1] = label #让标签等于我们运行出来的结果 11 data.head()
12 #如果不需要教学展示的话我会这么写: 13 from sklearn.preprocessing import LabelEncoder 14 data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
3、preprocessing.OrdinalEncoder : 特征专用,能够将分类特征转换为分类数值。
1 from sklearn.preprocessing import OrdinalEncoder 2 #接口categories_对应LabelEncoder的接口classes_,一模一样的功能 3 data_ = data.copy() 4 data_.head() 5 OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_ 6 data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1]) 7 data_.head()
4、preprocessing.OneHotEncoder : 独热编码,创建哑变量
4.1、创建哑变量的原因:
在对特征进行编码的时候,这三种分类数据都会被我们转换为[0,1,2],这三个数字在算法看来,是连续且可以
计算的,这三个数字相互不等,有大小,并且有着可以相加相乘的联系。所以算法会把舱门,学历这样的分类特
征,都误会成是体重这样的分类特征。这是说,我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所
以给算法传达了一些不准确的信息,而这会影响我们的建模。
类别OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量
向算法传达最准确的信息:(见下图)
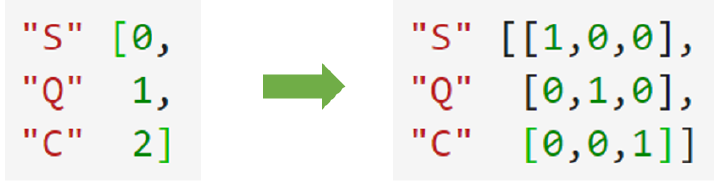
4.2、实例
1 data.head() 2 from sklearn.preprocessing import OneHotEncoder 3 X = data.iloc[:,1:-1] 4 enc = OneHotEncoder(categories='auto').fit(X) 5 result = enc.transform(X).toarray() 6 result 7 #依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步 8 OneHotEncoder(categories='auto').fit_transform(X).toarray() 9 #依然可以还原 10 pd.DataFrame(enc.inverse_transform(result)) 11 enc.get_feature_names() 12 result 13 result.shape 14 #axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连 15 newdata = pd.concat([data,pd.DataFrame(result)],axis=1) 16 newdata.head() 17 newdata.drop(["Sex","Embarked"],axis=1,inplace=True) 18 newdata.columns = 19 ["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"] 20 newdata.head()
4.3、标签也可以做哑变量
使用类sklearn.preprocessing.LabelBinarizer可以对做哑变量,许多算法都可以
处理多标签问题(比如说决策树),但是这样的做法在现实中不常见。
4.4、总结
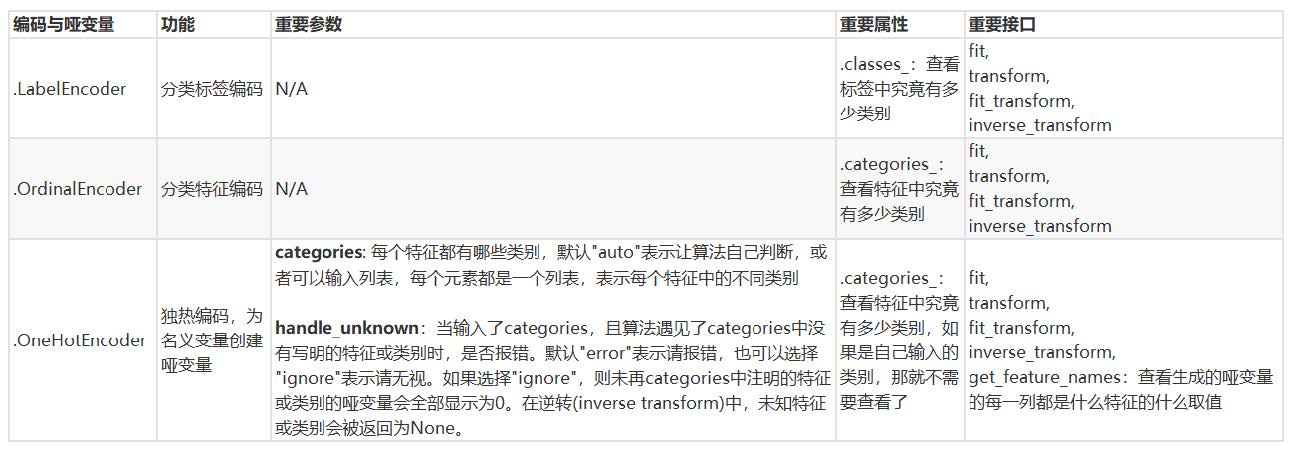
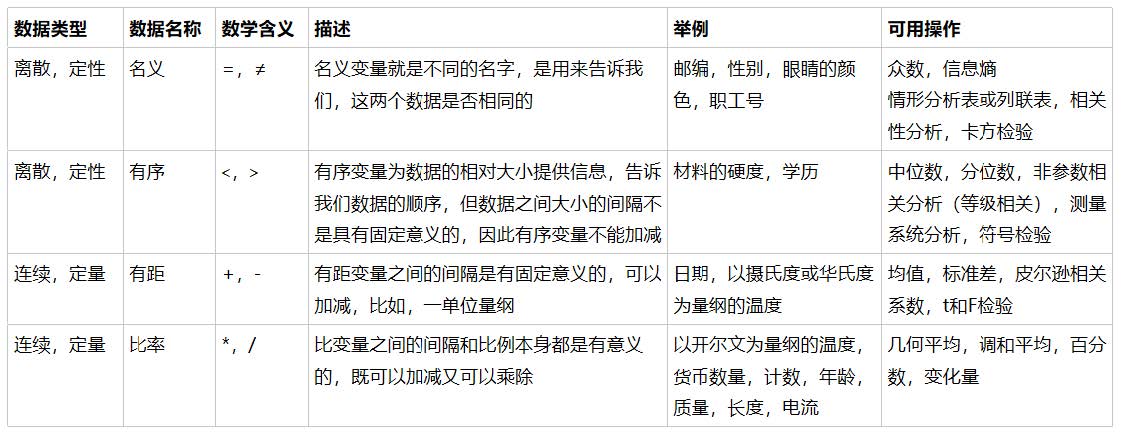
附:数据类型以及常用的统计量
Ⅳ、处理连续型特征:二值化与分段
1、sklearn.preprocessing.Binarizer ()
解释:
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈
值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。二值化是对文本计数数据的常见操作,分析人员
可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯
设置中的伯努利分布建模)。
实例:
1 #将年龄二值化 2 data_2 = data.copy() 3 from sklearn.preprocessing import Binarizer 4 X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组 5 transformer = Binarizer(threshold=30).fit_transform(X) 6 transformer
2、preprocessing.KBinsDiscretizer ()
解释:
这是将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。总共包含三个重要参数:

实例:
1 from sklearn.preprocessing import KBinsDiscretizer 2 X = data.iloc[:,0].values.reshape(-1,1) 3 est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform') 4 est.fit_transform(X) 5 #查看转换后分的箱:变成了一列中的三箱 6 set(est.fit_transform(X).ravel()) 7 est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform') 8 #查看转换后分的箱:变成了哑变量 9 est.fit_transform(X).toarray()
本节结束!
