

梯度下降算法原理讲解——机器学习
博文目录
1. 概述
梯度下降(gradient descent)在机器学习中应用十分的广泛,不论是在线性回归还是Logistic回归中,它的主要目的是通过迭代找到目标函数的最小值,或者收敛到最小值。
本文将从一个下山的场景开始,先提出梯度下降算法的基本思想,进而从数学上解释梯度下降算法的原理,解释为什么要用梯度,最后实现一个简单的梯度下降算法的实例!
2. 梯度下降算法
2.1 场景假设
梯度下降法的基本思想可以类比为一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低;因此,下山的路径就无法确定,必须利用自己周围的信息一步一步地找到下山的路。这个时候,便可利用梯度下降算法来帮助自己下山。怎么做呢,首先以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着下降方向走一步,然后又继续以当前位置为基准,再找最陡峭的地方,再走直到最后到达最低处;同理上山也是如此,只是这时候就变成梯度上升算法了
2.2 梯度下降
梯度下降的基本过程就和下山的场景很类似。
首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向(在后面会详细解释)
所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。而求取梯度就确定了最陡峭的方向,也就是场景中测量方向的手段。那么为什么梯度的方向就是最陡峭的方向呢?接下来,我们从微分开始讲起:
2.2.1 微分
看待微分的意义,可以有不同的角度,最常用的两种是:
- 函数图像中,某点的切线的斜率
- 函数的变化率
几个微分的例子:
1.单变量的微分,函数只有一个变量时
d ( x 2 ) d x = 2 x \frac{d(x^2)}{dx}=2xdxd(x2)=2x
d ( − 2 y 5 ) d y = − 10 y 4 \frac{d(-2y^5)}{dy}=-10y^4dyd(−2y5)=−10y4
d ( 5 − θ ) 2 d θ = − 2 ( 5 − θ ) \frac{d(5-\theta )^2}{d\theta}=-2(5-\theta)dθd(5−θ)2=−2(5−θ)
2.多变量的微分,当函数有多个变量的时候,即分别对每个变量进行求微分
∂ ∂ x ( x 2 y 2 ) = 2 x y 2 \frac{\partial}{\partial x}(x^2y^2) = 2xy^2∂x∂(x2y2)=2xy2
∂ ∂ y ( − 2 y 5 + z 2 ) = − 10 y 4 \frac{\partial}{\partial y}(-2y^5+z^2) = -10y^4∂y∂(−2y5+z2)=−10y4
∂ ∂ θ 2 ( 5 θ 1 + 2 θ 2 − 12 θ 3 ) = 2 \frac{\partial}{\partial \theta_{2}}(5\theta_{1} + 2\theta_{2} - 12\theta_{3}) = 2∂θ2∂(5θ1+2θ2−12θ3)=2
∂ ∂ θ 2 ( 0.55 − ( 5 θ 1 + 2 θ 2 − 12 θ 3 ) ) = − 2 \frac{\partial}{\partial \theta_{2}}(0.55 - (5\theta_{1} + 2\theta_{2} - 12\theta_{3})) = -2∂θ2∂(0.55−(5θ1+2θ2−12θ3))=−2
2.2.2 梯度
梯度实际上就是多变量微分的一般化。
下面这个例子:
J ( Θ ) = 0.55 − ( 5 θ 1 + 2 θ 2 − 12 θ 3 ) J(\Theta ) = 0.55 - (5\theta_{1} + 2\theta_{2} - 12\theta_{3})J(Θ)=0.55−(5θ1+2θ2−12θ3)
▽ J ( Θ ) = < ∂ J ∂ θ 1 , ∂ J ∂ θ 2 , ∂ J ∂ θ 3 > = ( − 5 , − 2 , 12 ) \triangledown J(\Theta ) = \left < \frac{\partial J}{\partial \theta_{1}}, \frac{\partial J}{\partial \theta_{2}},\frac{\partial J}{\partial \theta_{3}} \right > =(-5,-2,12)▽J(Θ)=⟨∂θ1∂J,∂θ2∂J,∂θ3∂J⟩=(−5,−2,12)
我们可以看到,梯度就是分别对每个变量进行微分,然后用逗号分割开,梯度是用<>包括起来,说明梯度其实一个向量。
梯度是微积分中一个很重要的概念,之前提到过梯度的意义
- 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率
- 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
这也就说明了为什么我们需要千方百计的求取梯度!我们需要到达山底,就需要在每一步观测到此时最陡峭的地方,梯度就恰巧告诉了我们这个方向。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,这正是我们所需要的。所以我们只要沿着梯度的方向一直走,就能走到局部的最低点!
2.3 数学解释
首先给出数学公式:
Θ 1 = Θ 0 + α ▽ J ( Θ ) → e v a l u a t e d a t Θ 0 {\color{Red} \Theta^1} = {\color{Blue} \Theta^0} + {\color{Green} \alpha} {\color{Purple} \triangledown J(\Theta)}\rightarrow evaluated at \Theta^0Θ1=Θ0+α▽J(Θ)→evaluatedatΘ0
此公式的意义是:J是关于Θ的一个函数,我们当前所处的位置为Θ0点,要从这个点走到J的最小值点,也就是山底。首先我们先确定前进的方向,也就是梯度的反向,然后走一段距离的步长,也就是α,走完这个段步长,就到达了Θ1这个点!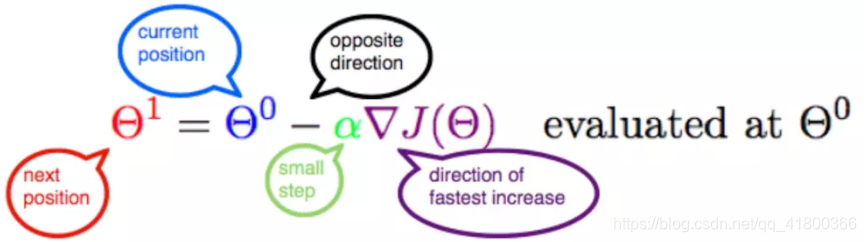
2.3.1 α
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步子跨的太大扯着蛋,哈哈,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以α的选择在梯度下降法中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!
2.3.2 梯度要乘以一个负号
梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们在前文提到,梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号;那么如果时上坡,也就是梯度上升算法,当然就不需要添加负号了。
3. 实例
我们已经基本了解了梯度下降算法的计算过程,那么我们就来看几个梯度下降算法的小实例,首先从单变量的函数开始,然后介绍多变量的函数。
3.1 单变量函数的梯度下降
我们假设有一个单变量的函数
J ( θ ) = θ 2 J(\theta) = \theta^2J(θ)=θ2
函数的微分,直接求导就可以得到
J ′ ( θ ) = 2 θ J'(\theta) = 2\thetaJ′(θ)=2θ
初始化,也就是起点,起点可以随意的设置,这里设置为1
θ 0 = 1 \theta^0 = 1θ0=1
学习率也可以随意的设置,这里设置为0.4
α = 0.4 \alpha = 0.4α=0.4
根据梯度下降的计算公式
Θ 1 = Θ 0 + α ▽ J ( Θ ) → e v a l u a t e d a t Θ 0 {\color{Red} \Theta^1} = {\color{Blue} \Theta^0} + {\color{Green} \alpha} {\color{Purple} \triangledown J(\Theta)}\rightarrow evaluated at \Theta^0Θ1=Θ0+α▽J(Θ)→evaluatedatΘ0
我们开始进行梯度下降的迭代计算过程:
θ 0 = 1 \theta^0 = 1θ0=1
θ 1 = θ 0 − α ∗ J ′ ( θ 0 ) = 1 − 0.4 ∗ 2 = 0.2 \theta^1 = \theta^0 - \alpha*J'(\theta^0)=1 - 0.4*2 = 0.2θ1=θ0−α∗J′(θ0)=1−0.4∗2=0.2
θ 2 = θ 1 − α ∗ J ′ ( θ 1 ) = 0.2 − 0.4 ∗ 0.4 = 0.04 \theta^2 = \theta^1 - \alpha*J'(\theta^1)= 0.2 - 0.4*0.4=0.04θ2=θ1−α∗J′(θ1)=0.2−0.4∗0.4=0.04
θ 3 = 0.008 \theta^3 = 0.008θ3=0.008
θ 4 = 0.0016 \theta^4 = 0.0016θ4=0.0016
如图,经过四次的运算,也就是走了四步,基本就抵达了函数的最低点,也就是山底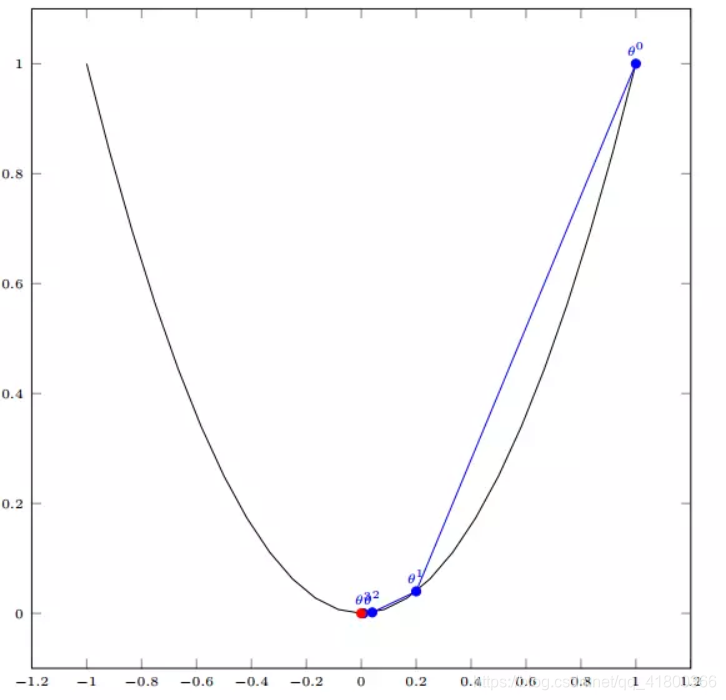
3.2 多变量函数的梯度下降
我们假设有一个目标函数
J ( Θ ) = θ 1 2 + θ 2 2 J(\Theta) = \theta_{1}^2 + \theta_{2}^2J(Θ)=θ12+θ22
现在要通过梯度下降法计算这个函数的最小值。我们通过观察就能发现最小值其实就是 (0,0)点。但是接下来,我们会从梯度下降算法开始一步步计算到这个最小值!
我们假设初始的起点为:
Θ 0 = ( 1 , 3 ) \Theta^0 = (1, 3)Θ0=(1,3)
初始的学习率为:
α = 0.1 \alpha = 0.1α=0.1
函数的梯度为:
▽ J ( Θ ) = < 2 θ 1 , 2 θ 2 > \triangledown J(\Theta ) = \left < 2\theta_{1},2\theta_{2} \right >▽J(Θ)=⟨2θ1,2θ2⟩
进行多次迭代:
Θ 0 = ( 1 , 3 ) \Theta^0 = (1, 3)Θ0=(1,3)
Θ 1 = Θ 0 − α ▽ J ( Θ ) = ( 1 , 3 ) − 0.1 ∗ ( 2 , 6 ) = ( 0.8 , 2.4 ) \Theta^1 = \Theta^0 - \alpha\triangledown J(\Theta ) = (1,3) - 0.1*(2, 6)=(0.8, 2.4)Θ1=Θ0−α▽J(Θ)=(1,3)−0.1∗(2,6)=(0.8,2.4)
Θ 2 = ( 0.8 , 2.4 ) − 0.1 ∗ ( 1.6 , 4.8 ) = ( 0.64 , 1.92 ) \Theta^2 = (0.8, 2.4) - 0.1*(1.6, 4.8)=(0.64, 1.92)Θ2=(0.8,2.4)−0.1∗(1.6,4.8)=(0.64,1.92)
Θ 3 = ( 0.5124 , 1.536 ) \Theta^3 =(0.5124, 1.536)Θ3=(0.5124,1.536)
Θ 4 = ( 0.4096 , 1.228800000000001 ) \Theta^4 =(0.4096, 1.228800000000001)Θ4=(0.4096,1.228800000000001)
⋮ \vdots⋮
Θ 10 = ( 0.1073741824000003 , 0.32212254720000005 ) \Theta^{10} =(0.1073741824000003, 0.32212254720000005)Θ10=(0.1073741824000003,0.32212254720000005)
⋮ \vdots⋮
Θ 50 = ( 1.141798154164342 e − 05 , 3.42539442494306 e − 05 ) \Theta^{50} =(1.141798154164342e^{-05}, 3.42539442494306e^{-05})Θ50=(1.141798154164342e−05,3.42539442494306e−05)
⋮ \vdots⋮
Θ 100 = ( 1.6296287810675902 e − 10 , 4.8888886343202771 e − 10 ) \Theta^{100} =(1.6296287810675902e^{-10}, 4.8888886343202771e^{-10})Θ100