

NTU 李宏毅 DRL Q-learning
这节讲Q-learning。
其实就是介绍了一些Critic,也就是value-based方法的基本思想,首先是MC和TD,我懒得再说一遍了。
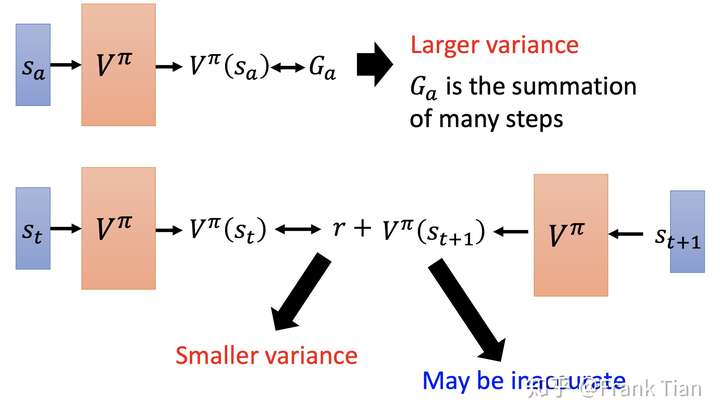
这张图介绍了一下MC和TD的差别,MC的步子比较大,而TD则相对更稳健。但是TD作出了一些假设,它信任了之前的值函数,在上一次评估的值函数的基础之上调整,这可能会导致评估上的不准确。
另一个问题是MC和TD看待采样的角度不同,他们做出了不同的假设,这些某些情况下会出现不同的结果:

当然当采样次数足够多的时候这些问题就不存在了。
上面的Critic是基于state的,也就是对每一个state进行评价。
还有另一种critic是基于state-action对的,它评价了每一个state-action对。
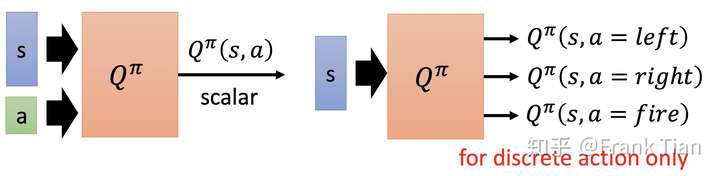
以上的过程都是策略评估,而我们可以在此之上直接改进策略。
实际上,我们只需要找到策略满足 ,就一定可以让策略得到改进。
现在,对于每一个state,有 。
我们用Q函数作为建立偏序关系的桥梁(实际上全概率展开也可以):
有
那么:
这里没有写出折扣,但是也没差啦。
然后是评估中Target Network的概念。
因为我们的目标只是让
理论上左式和右式都是可以调整的(你可以更改 的值函数,也可以更改
的值函数),但是这样不好操作。
现在我们把 固定住,也就是用
去回归,回归的目标就是
。
因此我们也把后面的这个网络称为Target Network。
然后是探索,常用的方法就是Epsilon Greedy和Boltzmann Exploration。
Epsilon Greedy是:
Boltzmann Exploration是:
其实这个Boltzmann Exploration写的不对, 中的值应该是偏好函数,也不是值函数,但是用值函数也work,我就不管了。
(记得西瓜书上的式子好像和上面的一样,但是sutton的书上用的是偏好函数)
然后是Replay Buffer,它把每一个 四元组存在了一个大的Buffer中:
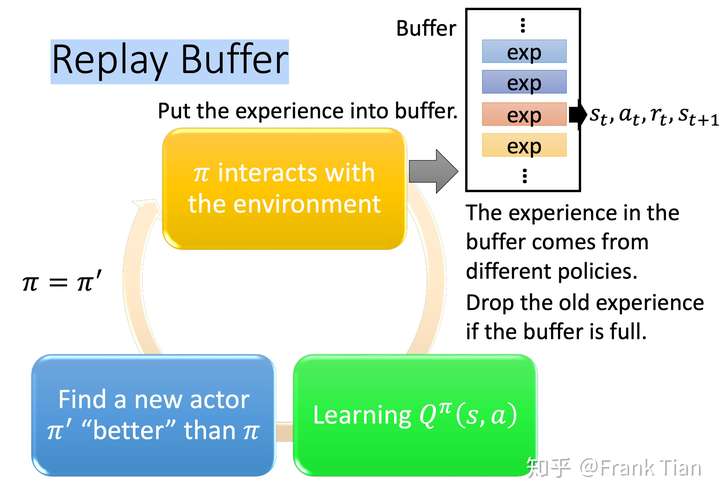
在学习Q函数的时候,则从Buffer中取一个batch-size的data。
这里面有一个关键点值得注意, 四元组并不都来自于同一个幕(也就是一次采样)中,但是我们依旧可以直接拿来训练。
这是因为Q值函数的更新方式是接近TD的,它只用到了下一个state带来的reward,而无论哪次采样, 的值都不会改变,因为它由环境决定。
当然这个是off-policy的。
最后是整体的算法:

