

大数据平台消息流系统Kafka
Kafka前世今生
随着大数据时代的到来,数据中蕴含的价值日益得到展现,仿佛一座待人挖掘的金矿,引来无数的掘金者。但随着数据量越来越大,如何实时准确地收集并分析如此大的数据成为摆在所有从业人员面前的难题。
为了解决大数据流式处理中面临的巨大数据吞吐量的难题,LinkedIn公司开发了Kafka作为其活动流和运营数据处理的消息管道。作为全球最大的职业社交网站,LinkedIn会员人数在世界范围内已超过3亿,Kafka作为一款消息服务,为其系统数据的稳定运行做出了巨大的贡献,因此Kafka的性能和可靠性也得以验证。
LinkedIn与2011将其开源并捐献给Apache基金会,并与2012年正式成为Apache的顶级项目,目前官方最新版本为2.0。
初识Kafka
首先,Kafka作为一个分布式的流平台,具有三个关键能力:
1. 发布和订阅消息(流),在这方面,它类似于一个消息队列或企业消息系统。
2. 以容错的方式存储消息(流)。
3. 在消息流发生时处理它们。
kafka在很多大数据量的应用场景下能更好的替换传统的消息系统,消息系统被用于各种场景(解耦数据生产者,缓存未处理的消息等),与大多数消息系统比较,kafka有更好的吞吐量,内置分区,副本和故障转移,这有利于处理大规模的消息。
Kafka对比主流MQ
这里主要与ActiveMQ和RabbitMQ做对比。
-
TPS比较:
Kafka最高,RabbitMq 次之, ActiveMq最差。 -
吞吐量对比:
kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。 -
在架构模型方面:
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。 -
在可用性方面:
rabbitMQ支持miror的queue,主queue失效,miror queue接管。
kafka的broker支持主备模式。
activeMq也支持主备模式。 -
在集群负载均衡方面:
kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
rabbitMQ的负载均衡需要单独的loadbalancer进行支持。
下图展示Kafka与主流MQ的同步发送(注:Kafka还支持异步发送模式,性能比同步发送高的多)性能对比:

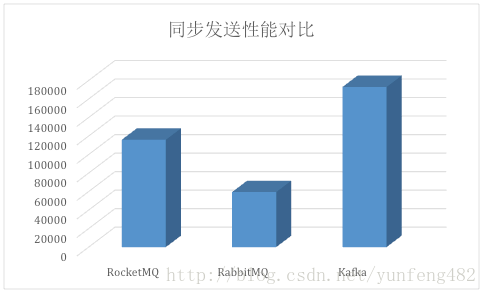
结语
可以看出Kafka在处理大数据的消息流方面,在高性能、高吞吐量和高系统可靠性上较传统MQ具有很大的优势,从设计上处处能看出kafka在这方面的野心,这也是如今在大数据消息流处理中,Kafka如此火热的主要原因。
但是,不得不说,Kafka也有很多不尽人意的地方。比如:
1. Kafka并不保证每条消息的精确处理(不丢失且不重复消费)。Kafka消息丢失主要在两个地方存在可能性:a) Producer端重试次数用完后放弃该批次消息,b) Broker端Partition的leader副本崩溃,其他副本与leader的数据不是完全一致的。Kafka消息产生重复消息也主要在两个地方会出现:a) Producer端发送完批次消息,消息写入成功,但响应超时,造成该批次消息被重发;b) Consumer端对消息偏移量的维护与实际消息消费进度不一致。
2. 0.11(这其实是一个较新的版本,只是Kafka最近的版本号跨度很大)之前的版本不支持事务消息。
3. 只能保证消息的分区有序性(如果在Producer端buffer中的批次是异步发送,在遇到超时和重试的时候,也会乱序),如果需要保证特定类型消息的有序性,需要开发自定义的分区器,将特定类型消息分布到同一个分区(Partition)。
4. 在 2.0 以前,Kafka 自身的访问控制机制还是粗粒度的。比如对“创建Topic”这一权限的控制,只有“全集群”这一种范围。也就是说,对于任何一个用户来说,我们只能给或者不给这种权限。而且Kafka对消息访问的权限控制也不够好,在数据安全性方面有待提升。
