

美团DB数据同步到数据仓库的架构与实践
整体架构图
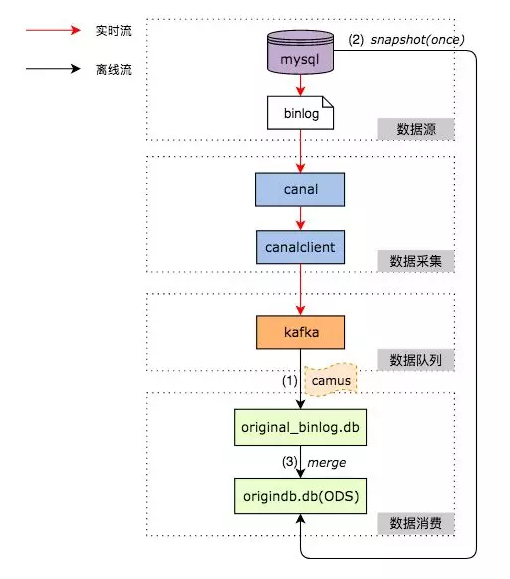
在Binlog实时采集方面,我们采用了阿里巴巴的开源项目Canal,负责从MySQL实时拉取Binlog并完成适当解析。Binlog采集后会暂存到Kafka上供下游消费。整体实时采集部分如图中红色箭头所示。
离线处理Binlog的部分,如图中黑色箭头所示,通过下面的步骤在Hive上还原一张MySQL表:
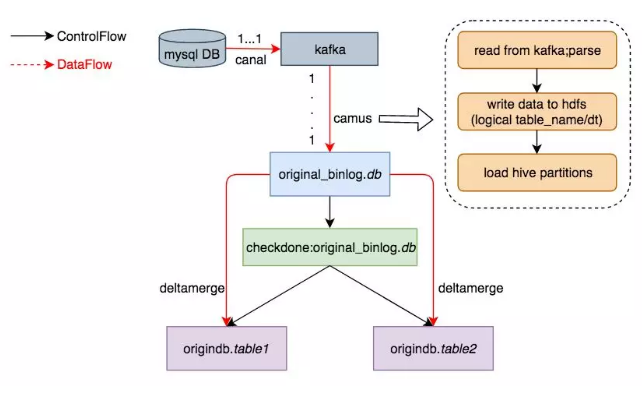
采用Linkedin的开源项目Camus,负责每小时把Kafka上的Binlog数据拉取到Hive上。
对每张ODS表,首先需要一次性制作快照(Snapshot),把MySQL里的存量数据读取到Hive上,这一过程底层采用直连MySQL去Select数据的方式。
对每张ODS表,每天基于存量数据和当天增量产生的Binlog做Merge,从而还原出业务数据。
Binlog实时采集
对Binlog的实时采集包含两个主要模块:一是CanalManager,主要负责采集任务的分配、监控报警、元数据管理以及和外部依赖系统的对接;二是真正执行采集任务的Canal和CanalClient。

当用户提交某个DB的Binlog采集请求时,CanalManager首先会调用DBA平台的相关接口,获取这一DB所在MySQL实例的相关信息,目的是从中选出最适合Binlog采集的机器。然后把采集实例(Canal Instance)分发到合适的Canal服务器上,即CanalServer上。在选择具体的CanalServer时,CanalManager会考虑负载均衡、跨机房传输等因素,优先选择负载较低且同地域传输的机器。
CanalServer收到采集请求后,会在ZooKeeper上对收集信息进行注册。注册的内容包括:
-
以Instance名称命名的永久节点。
-
在该永久节点下注册以自身ip:port命名的临时节点。
这样做的目的有两个:
-
高可用:CanalManager对Instance进行分发时,会选择两台CanalServer,一台是Running节点,另一台作为Standby节点。Standby节点会对该Instance进行监听,当Running节点出现故障后,临时节点消失,然后Standby节点进行抢占。这样就达到了容灾的目的。
-
与CanalClient交互:CanalClient检测到自己负责的Instance所在的Running CanalServer后,便会进行连接,从而接收到CanalServer发来的Binlog数据。
对Binlog的订阅以MySQL的DB为粒度,一个DB的Binlog对应了一个Kafka Topic。底层实现时,一个MySQL实例下所有订阅的DB,都由同一个Canal Instance进行处理。这是因为Binlog的产生是以MySQL实例为粒度的。CanalServer会抛弃掉未订阅的Binlog数据,然后CanalClient将接收到的Binlog按DB粒度分发到Kafka上。
离线还原MySQL数据
参考博客:https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749639&idx=2&sn=5e4242c0053fcd2bb3dea3689484d6f0&chksm=bd12a44a8a652d5c88569d09d76160281c26fce07213633803785941f17f50d7973d48b23187&scene=21#wechat_redirect
