微服务的链路追踪
微服务盛行,链路追踪也随之火了起来,起初是google的这篇论文,网上找到一个比较好的翻译版本,这篇论文比较系统性的介绍了何为分布式链路追踪系统,借助spring-cloud-sleuth的总结,在一次RPC调用中,通常有四个Event:
-
cs: Client Sent. The client has made a request. This annotation indicates the start of the span.
-
sr: Server Received: The server side got the request and started processing it. Subtracting the
cstimestamp from this timestamp reveals the network latency. -
ss: Server Sent. Annotated upon completion of request processing (when the response got sent back to the client). Subtracting the
srtimestamp from this timestamp reveals the time needed by the server side to process the request. -
cr: Client Received. Signifies the end of the span. The client has successfully received the response from the server side. Subtracting the
cstimestamp from this timestamp reveals the whole time needed by the client to receive the response from the server.
使用链路日志具体化描述的话,假设从前端发起一次HTTP调用,服务A接收到请求之后,会再进行一次远程HTTP调用,B服务会接收这次调用并且返回,服务A拿到结果之后再返回给前端,那么这里一共涉及到2个服务(除去前端),服务A是作为这次链路的root span,生成一个全局唯一的traceId,命名此span为Span1,接着他会进行服务B的调用,此时又会生成一个span:Span2,对应的spanId会被填充到header(header里还会包含traceId,以及服务A本身的spanId作为服务B的parentSpanId)传递给服务B,服务B接收到请求之后,生成本地的span:Span3,该span的spanId以及parentSpanId是已经生成了的=>来自header,也就是由上一跳生成,服务A收到服务B的响应之后再进行Span2的数据填充,例如本次调用的耗时,响应结果等,拿到响应结果之后可能再进行一些逻辑处理,最后要返回给前端,返回之前会接着Span1进行数据的填充,同样也是进行耗时等数据的填充,最后返回给前端。
所以,这次调用一共会产生3个Span,但是Span的深度可以理解为2。其中Span2和Span3是同一个spanId&parentSpanId,分别隶属于服务A和服务B,代表的是一次HTTP调用的客户端和服务端(对于这次调用,服务A为客户端,B为服务端),前端展示的话可能通常只展示2个层级关系,例如zipkin的ui(注意,这里按照常规理解,span总数应该是3,链路原始报文也是3个span):
借助一张图理解整个机制:
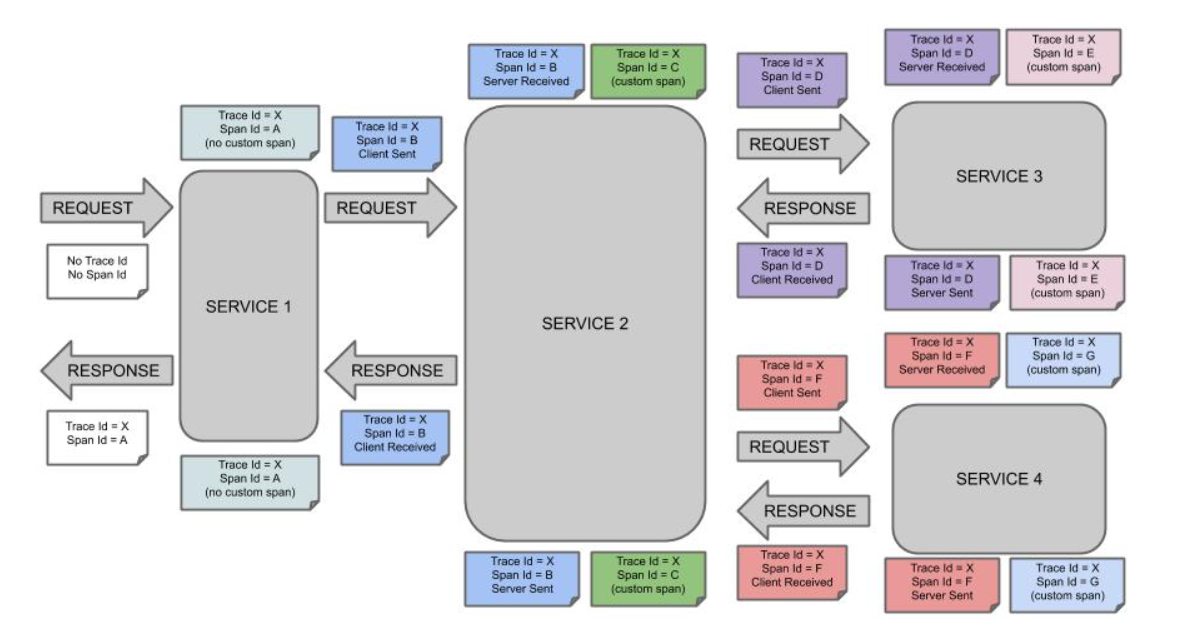
还需要提到一点的是,上面的模型通常是同步调用,假如涉及到MQ,那么MQ是作为一个真实节点存在的,服务A发送一个消息,服务B收到,那么请注意此时服务A对应发送消息的SpanId是服务B收到消息之后产生的span的parentSpanId,而这个span的spanId需要服务本身生成,并非从header里提取,这里很容易理解:你将MQ想象为中间的同步调用服务,A 同步调用 MQ, MQ再同步调用B,只是MQ不生成Span,所以服务B的spanId需要自己生成,但是他的parentSpanId就是A那边的spanId。这里的Span深度就是3。基于Zipkin的UI做一个简单的测试,这里我前端发起一个请求,服务A收到之后发送一个RabbitMQ消息,同样是服务A会进行消息的消费:

注意,这里显示成4跳是因为brave对收消息进行了拆分,其实就是一个动作,硬抽成了2跳,所以产生了4个span,将后两跳作为一跳理解,next-message这一跳的parentSpanId就是第二个BACKEND的spanId。
接下来探讨几个问题
1.怎么做链路追踪
上文已经看到,其实追踪的本质就是打出一条条日志,这样通过日志就可以将一整条链路关联起来,首先一条链路下的所有span的traceId是一致的,然后通过parentSpanId进行父子的关联,根span的parentSpanId为0。
2.怎么打日志?打了日志之后做什么?
通常来说,常见的库,框架都会提供类似于interceptor的机制,所以最简单的办法就是加一层用于链路日志打印的拦截器,在动作执行前,后进行日志的操作,通常来说,动作执行前,start一个span,结束后,finish这个span即可,或者说,不通过这种,直接通过类似于bytebuddy的框架,字节码织入(skywalking),这种一般比较强大,而前者可能都会有一些限制,比如不支持拦截器,或是其他,但是,大多数成熟的框架肯定是支持的,总会提供出来某些机制让你切进去进行日志的打印,甚至来说,如果这个工具不支持,你可以提issue让他支持,可以专门适配:因为现在链路追踪是趋势,微服务下链路追踪是必须存在的。
对于前者,brave框架就是干这件事的,他的角色是提供了一整套trace机制,以及常见框架的织入,但是如果你想要无感知接入,肯定是不行的,所以通常在Spring环境下,直接使用spring-cloud-sleuth的比较多,这个框架底层使用的是brave作为追踪器,而它干的事主要就是进行各种Bean的无感知织入,某种程度上有充当了点springboot-starter的角色,何谓无感知?首先需要有概念的是,如果你想让别人接入你的追踪库,最好的方式是,别人引入一个JAR包,然后不做任何配置,就可以生效,因为这跟他们的业务无关,这也不是他们需要使用的工具,他们甚至不需要感知到这个库的存在,所以0配置,无感知是比较重要的,常见的方式就是借助Spring的BeanPostProcessor,如果某个Bean是需要织入的类型,那么进行织入,这也是spring-cloud-sleuth的做法,
还有一点很重要的是,span-finish之后,做什么?比较常见的,往某个地方上送这些日志,或者借助于MDC,将traceId,spanId等打到日志里,或者二者都做,对于前者,通常分为两种方式,直接服务内部上送,不论是通过http,或者是消息队列,直接上送到某个日志收集服务,或者是服务所在的环境有一个专门的agent负责上送。
3.日志收集到之后做什么?
这里涉及到一个问题,链路追踪是做什么的?
1.分析问题,某次调用失败,哪一个环节出问题了,或者某次调用耗时很久,卡在哪个服务了。
2.某个接口的分析,这里的分析指的是整体的分析,例如某个接口的整体成功响应率,平均响应时间,这些指标需要依托于一定量的数据。
所以,收集之后可以进行一些指标的计算,作为Metrics,当然链路日志本身也需要记录,以便重现链路调用图。
4.额外的日志打印消耗性能吗?
肯定是消耗的,正如google论文中提到的,生成一个span,以及生成一个traceId,都会带来一定的延迟,特别是后者,还有一点就是日志的上送,当然这个通常来说是异步化上送。
抛开性能消耗,还有一点很重要的是,日志的保存,常见的,日志存在es里,如果服务流量很大,那么日志存储肯定需要大量空间。所以,通常会存在采样策略,比如1分钟最多采100条,注意,采用策略通常是第一跳就决定的(head-based),会将这个字段一路透传下去(sampled)。
带来的问题是可能错过某条异常链路,但是正如google论文里所说的,如果出现了一次异常,那么肯定会继续出现被采样到。除了head-based,也有tail-based,或者是动态采样,但是我了解的不多。(可以参考一下相关issue的讨论(来自jaeger):issue-425, issue-1729)
5.哪个框架,库好?
zipkin&brave现在的维护力度不大,社区主要维护者2021年已经退出了。 但是,基于语言层面的追踪库,貌似只有brave做的比较好,还有一个opentracing-contrib,后者是符合open-tracing规范的日志。 spring-cloud-sleuth直接使用brave库进行追踪,但是3.0他已经做了一层自己Tracer的抽象,Brave作为一个可选的追踪库,目前正在孵化spring-cloud-sleuth-opentelemetry
现在opentelemetry似乎越来越流行了,这不是一个具体的追踪库,和zipkin不冲突,jaeger最近就选择不维护自己的client了,因为前者发展的越来越好,所以他推荐大家使用前者。
另外,因为我刚开始接触spring-cloud-sleuth的时候,也有点乱,感觉各种东西揉在一起,各种starter,所以现在整理一下:
1.zipkin不是追踪库,这是一个支持日志收集,存储,以及提供了一个UI展示链路。日志收集(collector)支持http,mq等方式,日志存储支持数据库,es等方式。所以zipkin运行起来本质还是一个web-application,暴露在9411端口,提供日志上传的http端点,以及作为UI页面的后端服务。
2.brave是追踪库,他是需要集成在应用端的。
3.应用端的日志上送到zipkin的collector也是需要库的,也就是reporter,也是集成在应用端,通常常见的例如:zipkin-reporter-java
4.上面三个库的都属属于openzipkin这个组织的开源项目,好像还基本都是一个人写的(Adrian Cole),但是他2021年暂时退出了,所以你可以看到2021年commit很少了。也确实感叹一个人的高产和牛逼,以及对开源的奉献。他有一些公开演讲视频。
5.spring-cloud-sleuth是spring-cloud的开源项目,会使用了brave这个追踪库(3.0之后是可选的,但是也没别的可以选了),做了一系列bean的自动注入,当然还有其他,并且3.0之后,引用作者的话:The spring-cloud-starter-zipkin dependency is removed. You need to add spring-cloud-starter-sleuth and the spring-cloud-sleuth-zipkin dependency.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号