
第一次个人编程作业
1.Github链接
https://github.com/AZhu-ys/031702103
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 90 |
| Estimate | 估计这个任务需要多少时间 | 25 | 30 |
| Development | 开发 | 500 | 640 |
| Analysis | 需求分析 (包括学习新技术) | 1000 | 1800 |
| Design Spec | 生成设计文档 | 60 | 50 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 35 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 500 | 650 |
| Code Review | 代码复审 | 30 | 70 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 240 |
| Reporting | 报告 | 50 | 40 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 2515 | 3775 |
3.计算模块接口的设计与实现过程
3.1解题思路
(1)首先判断是哪种难度等级的地址信息,提取前面两位字符,判断是”1!","2!",还是“3!”,从而选择划分为五级或七级地址,又或者是需要补全为七级地址的,判断完之后把难度级别标识符删除。
(2)由于所有数据中,逗号前面都是名字且11位连续的数字必是手机号码,所以利用“,”分割,获取名字,再用正则表达式提取11位手机号码。将姓名和手机号码提取后,剩下就是进行地址的划分。
(3)在进行详细地址更具体划分时,一开始选择的是匹配‘省’、‘市’、‘县’等关键字,但是在代码实现后发现正确率很低,有一部分原因就是有的地址信息省略了‘省’、‘市’,当然另外一部分也是我考虑的不够全面。后来请教了K班的同学后,得知利用cpca可以十分方便地提取省市县三级行政地址。于是又中途花了一天时间学习cpca等用法。此时需要再对直辖市北京,天津,上海,重庆4个直辖市进行特殊处理。
(4)以“街道”,“镇”,“城”,“乡”等为关键字,利用正则表达式划分出第四级地址,若难度等级为1!,加上余下信息,五级地址划分完成。
(5)若难度级别为2!,此时则要对剩余地址信息用“街”、“路”、“道”、“胡同”等关键字利用正则表达式继续划分出第五级地址。
(6)在进行第六级、第七级地址划分时,以"号“,”弄“,”乡道“等关键词,将剩下的地址分割为两级。
(7)难度等级为3!的附加题据说需要用到高德地图之类的,实在太难了,我放弃了。
3.2关键函数和类
(1)虽然之前选修过Python,但是当时在划水没有认真学,这次算是第一次真正用Python编程,暂时还没有办法能够用类实现,只能直接对每个输入的地址信息进行处理。
(2)本次作业的关键在于地址的划分,手机号码和姓名的提取容易实现,而在地址划分时,我主要使用正则表达式匹配关键字逐级划分的方式。
ADDRESS = ADDRESS.strip('.')
TOWN = re.compile(r'(.?)镇')
town = TOWN.findall(ADDRESS)
STREET = re.compile(r'(.?)街道')
street = STREET.findall(ADDRESS)
XIANG = re.compile(r'(.*?)乡')
xiang = XIANG.findall(ADDRESS)
\\
(3)不知道使用cpca算不算独到之处,确实像同学说的那样划分省市县三级时非常方便,但是也有不足之处。jieba分词并不能百分之百保证分词的正确性,在分词错误的情况下会造成奇怪的结果,故引入了全文模式,不进行分词,直接全文匹配,使用方法如下.不过全文匹配模式会造成匹配效率低一些,追求正确率因此选择了cut=False。设置了cpca搜索字段的比较长的长度,以防止遇到那种很长的少数民族的自治县,虽然不知道数据中会不会出现。
df = cpca.transform(address1, cut = False, lookahead = 13) #DataFrame
4.计算模块接口部分的性能改进
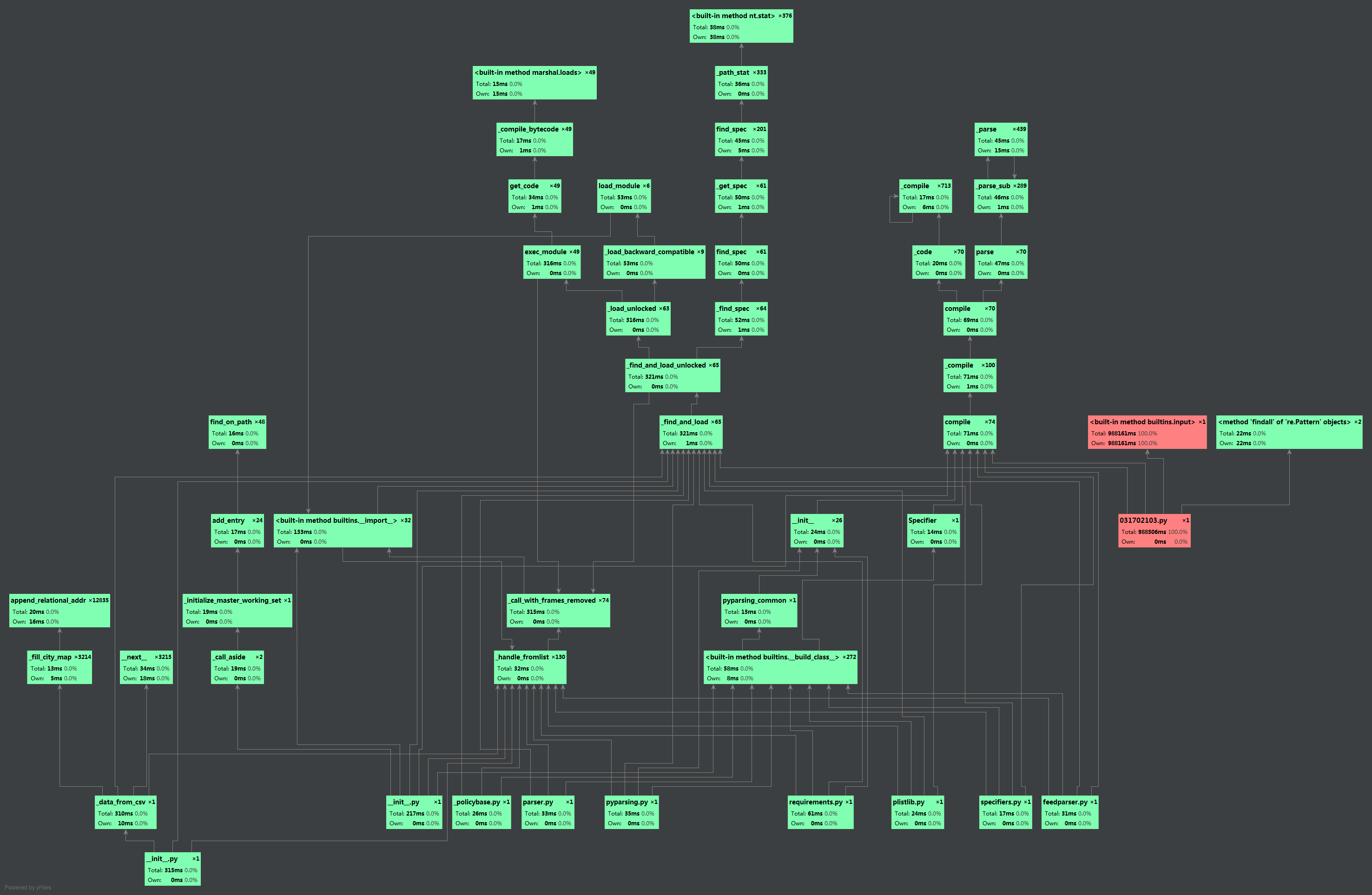
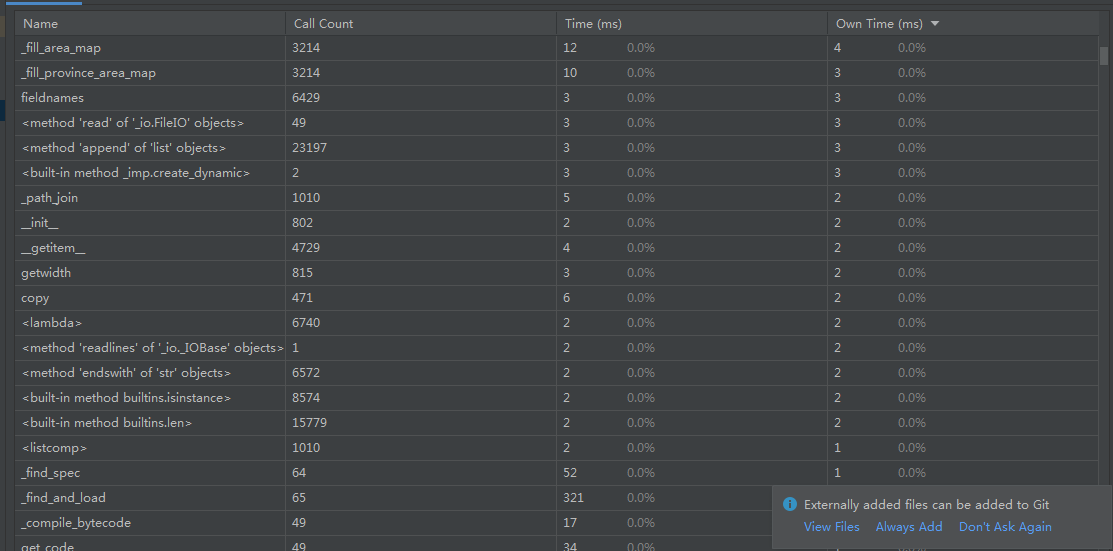
利用pycharm得到的,看不大懂,也来不及进行性能改善了。只能看得出程序中消耗最大的函数就是input(),可能是数据多且我简单粗暴对数据处理没有精巧的处理方式?唉,太菜了实在看不明白。
5.计算模块部分单元测试展示
1!乔哥踢,山东省13761422352枣庄市薛城区南安阳村民委员会.
1!宓蔫久,山西省晋城市城13719021976区西街街道苗孟庄社区泰丰小区网格2号楼.
1!伍莫珍,广西壮族自治区钦州13175764582钦南区黄屋屯镇屯兴街1号黄屋屯中学.
1!涂晓蹂,吉林省长春市长春高新技术产业开发区高新开发区102国道以北规划富裕河14781957580以南长春恒大名都131号香得益彰麻辣居.
1!佴赴,浙江省舟山市岱山县高亭镇13943898664银厦路88号南峰海鲜面馆.
1!怀喷,甘肃省天水15618942866市清水县草川铺镇449县道腰林秦惠琴希望小学.
1!幸晴,贵州省黔东南苗族侗族自治州岑巩县思13377199751旸镇磨寨村磨寨小学.
2!满茧腌,湖北省鄂州市涂家垴镇发13387889865展路9号鄂州市涂家垴派出所.
2!夹谷抡枯,18795320124甘肃省兰州城关区皋兰路街道皋兰路210号郑家台小区.
2!柏雅蚜,上海市长宁区周家桥街道武夷路718号武夷花园722号13757741271楼.
{"姓名": "乔哥踢", "手机": "13761422352", "地址": ["山东省", "枣庄市", "薛城区", "", "南安阳村民委员会"]}
{"姓名": "宓蔫久", "手机": "13719021976", "地址": ["山西省", "晋城市", "城区", "西街街道", "苗孟庄社区泰丰小区网格2号楼"]}
{"姓名": "伍莫珍", "手机": "13175764582", "地址": ["广西壮族自治区", "钦州市", "钦南区", "黄屋屯镇", "屯兴街1号黄屋屯中学"]}
{"姓名": "涂晓蹂", "手机": "14781957580", "地址": ["吉林省", "长春市", "", "", "长春高新技术产业开发区高新开发区102国道以北规划富裕河以南长春恒大名都131号香得益彰麻辣居"]}
{"姓名": "佴赴", "手机": "13943898664", "地址": ["浙江省", "舟山市", "岱山县", "高亭镇", "银厦路88号南峰海鲜面馆"]}
{"姓名": "怀喷", "手机": "15618942866", "地址": ["甘肃省", "天水市", "清水县", "草川铺镇", "449县道腰林秦惠琴希望小学"]}
{"姓名": "幸晴", "手机": "13377199751", "地址": ["贵州省", "黔东南苗族侗族自治州", "岑巩县", "思旸镇", "磨寨村磨寨小学"]}
{"姓名": "满茧腌", "手机": "13387889865", "地址": ["湖北省", "鄂州市", "", "涂家垴镇", "发展路", "9号", "鄂州市涂家垴派出所"]}
{"姓名": "夹谷抡枯", "手机": "18795320124", "地址": ["甘肃省", "兰州市", "城关区", "皋兰路街道", "皋兰路", "210号", "郑家台小区"]}
代码覆盖率
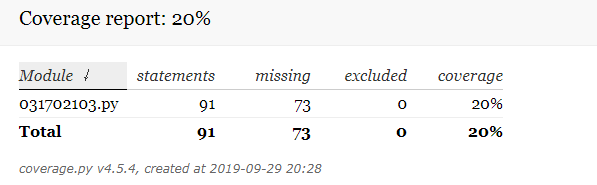
不知道是什么原因,覆盖率会低成这样,可能是我操作不当又或者考虑的情况太多?
6.计算模块部分异常处理说明
时间比较赶,没有测试特别多的样例,异常处理这块没有做好,争取下次早点开始做题,不要像这次这样这么匆忙。
3!巢盒,河北省衡水市13287435790桃城区永兴西路122号赵家庄居民1区.
{"姓名": "巢盒", "手机": "13287435790", "地址": ["河北省", "衡水市", "桃城区", "", "永兴西路122号赵家庄居民1区"]}
这是我没有对第三难度等级处理,所以生成5级地址,不符合要求。
7.个人小结
http://www.360doc.com/content/11/0711/02/3002779_132809249.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号